








json数据的读取:
import json
#待读取json文件路径
path = 'xxx'
#records为json数组
records = [json.loads(line) for line in open(path)]用字典计数(两种方式):
#纯手写的方式
def get_counts(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts
#使用defaultdict
from collections import defaultdict
def get_counts2(sequence):
#所有的值均初始化为0
counts = defaultdict(int)
for x in sequence:
counts[x] += 1
return counts字典计数后,取前n位(两种方式):
def top_counts(count_dict,n = 10):
#count_dict为之前求的计数字典
value_key_pairs = [(count,tz) for tz,count in count_dict.items()]
#即将字典转化为元组数组后排序,注意元组的第0项为技术值
value_key_pairs.sort()
取倒数n项
return value_key_pairs[-n:]
#第二种方式,使用collections.Counter
from collections import Counter
#time_zone为希望计数和求前n项的数组
counts = Counter(time_zone)
counts.mostCommon(10)将数据转化为DataFrame:
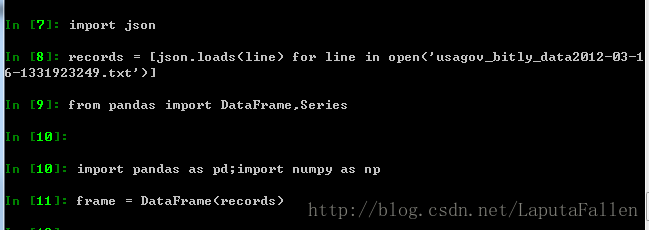
利用frame的value_counts()方法轻松对tz进行计数并且返回前n项:
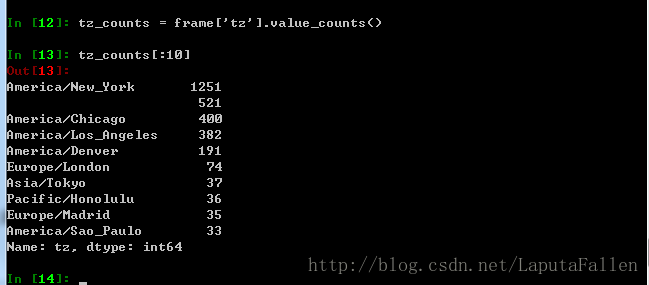
为tz(时区)绘图,替换了缺失值和空字符串:
移除某列为空值的数据:
#a为空,则移除
cframe = frame[frame.a.notnull()]调用np.where对a进行转换:
operating_system = np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows')对frame进行分组:
operating_system = np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows')
#cframe通过tz列和operating_system进行分组
by_tz_os = cframe.groupby(['tz',operating_system])
#分组后的处理
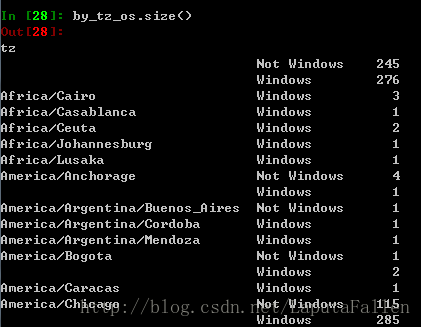
agg_counts = by_tz_os.size().unstack().fillna(0)效果截图:
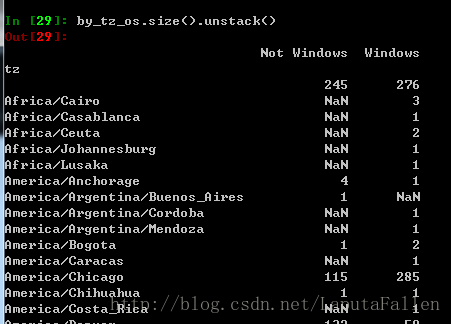
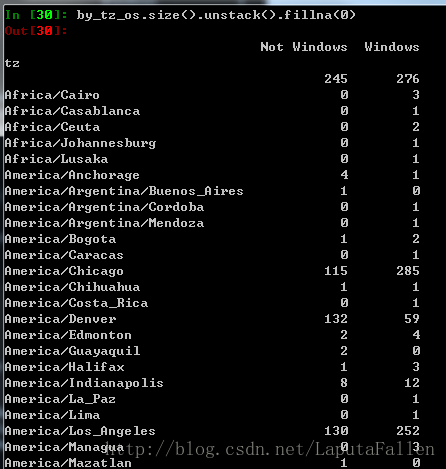
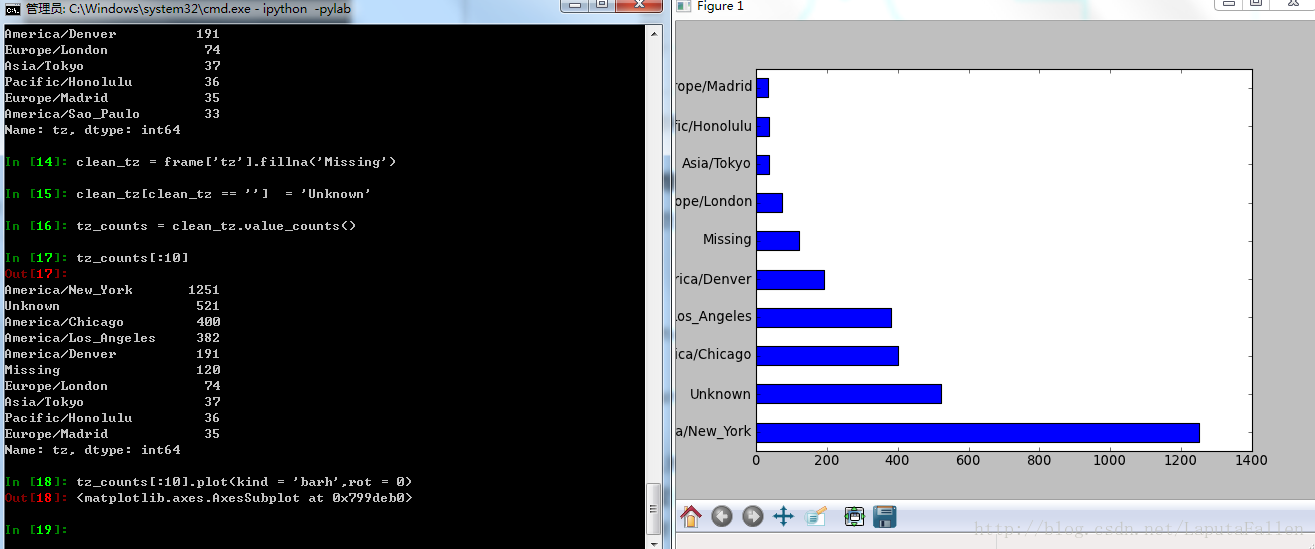
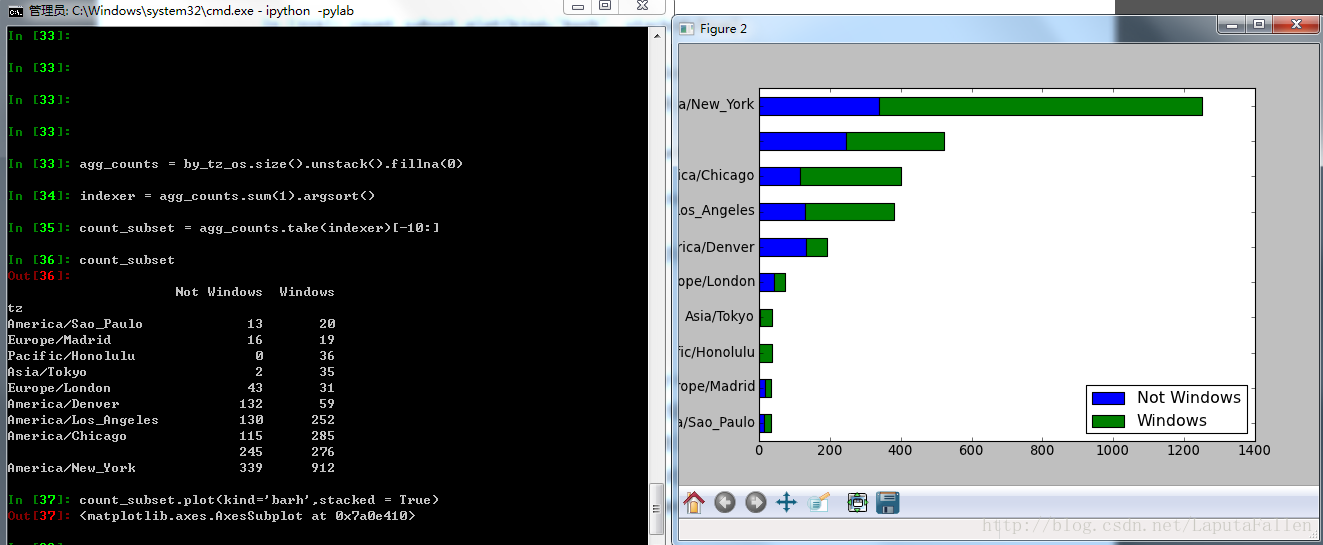
选取最常出现的时区,并绘制条形图:
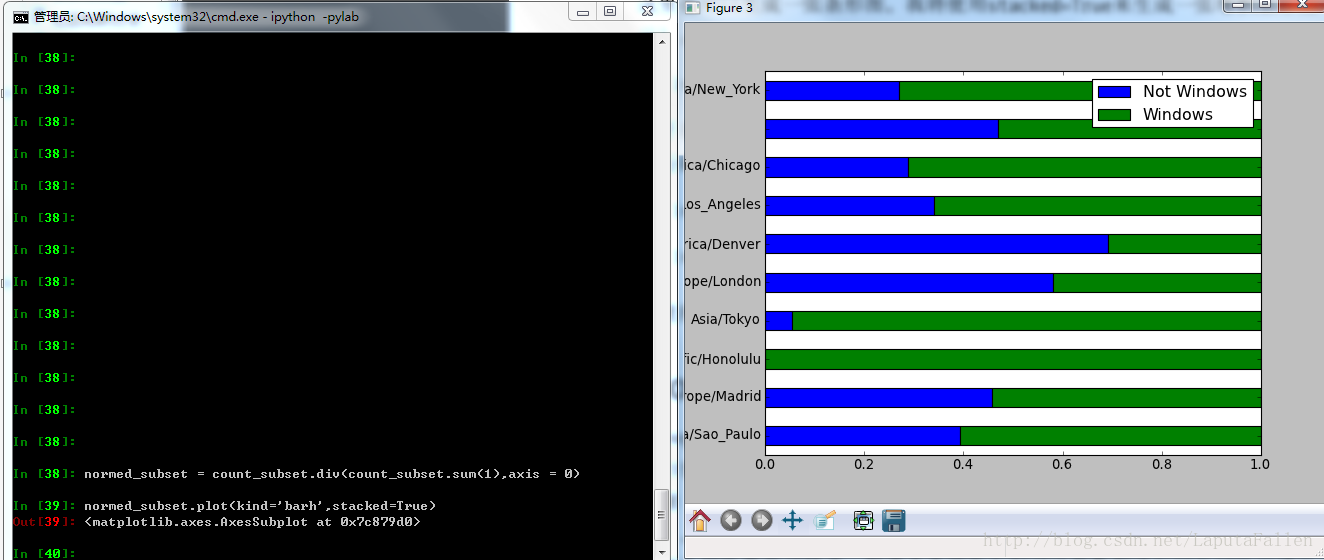
反映操作系统用户比例的堆积条形图:
调用pandas.read_table将数据(未以字典形式存储,以一些分隔符分割)转换为DataFrame:
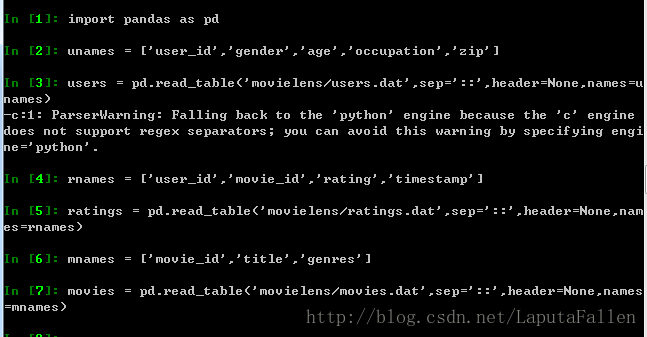
合并users,ratings,movies这三张表,注意pandas可以通过列名识别键:
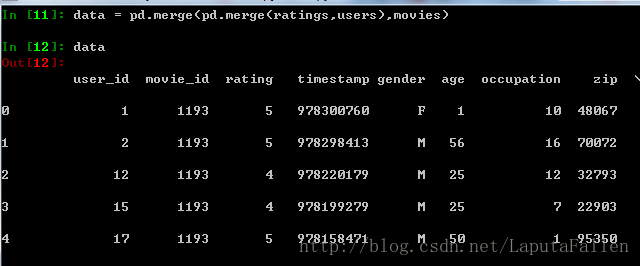
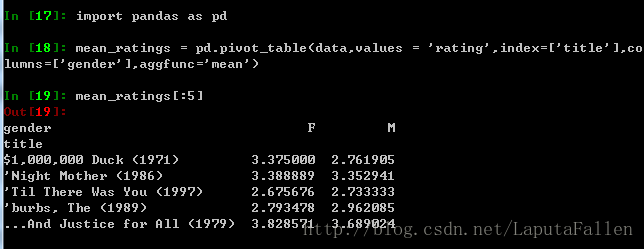
利用聚合方法pivot_table,按性别计算每部电影的平均得分:
利用groupby()分组,过滤掉评分数据不够250条的电影:
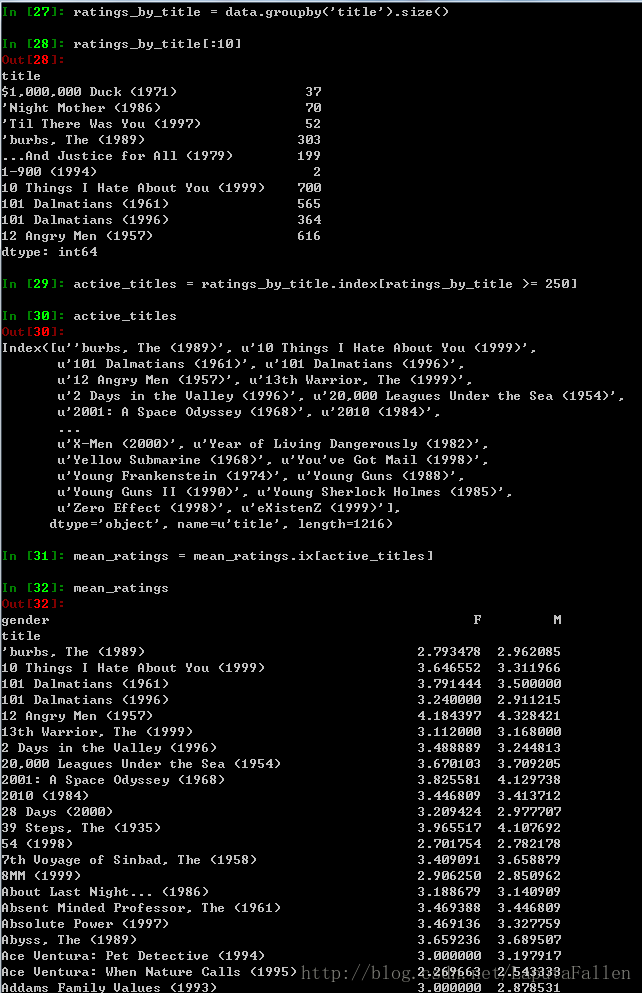
对DataFrame进行排序,sort_index()方法:
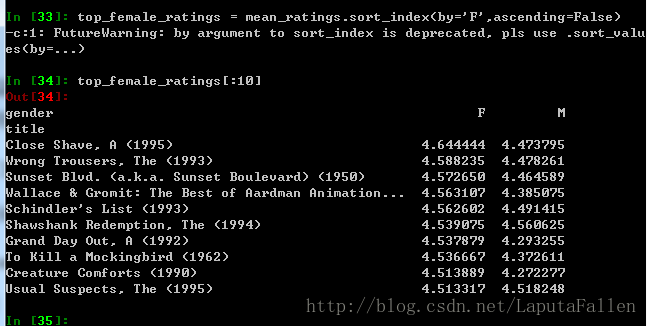
为mean_ratings**添加分歧列**,比较男女分歧:
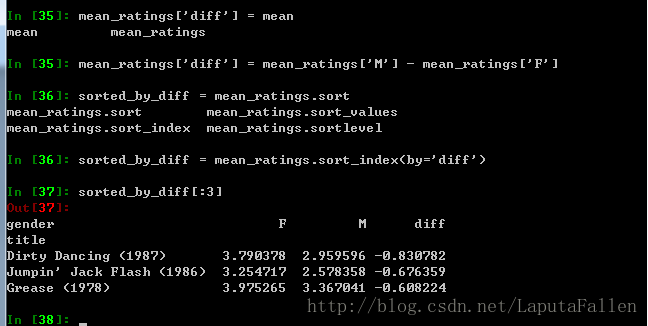
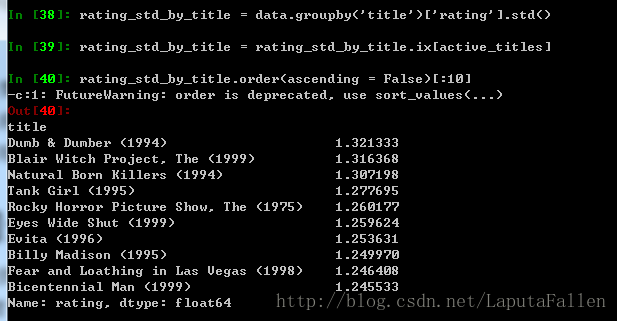
利用std()计算分歧最大的电影(即标准差):
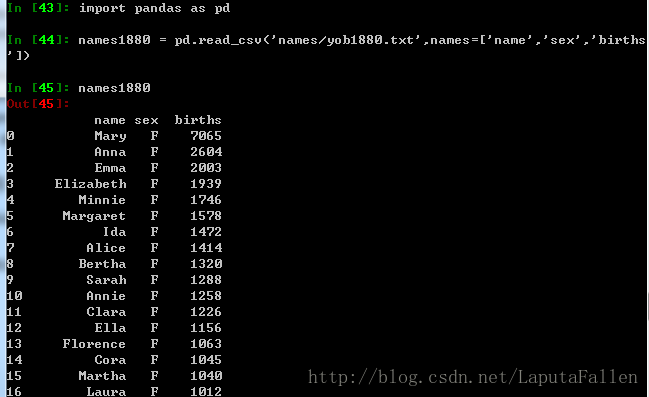
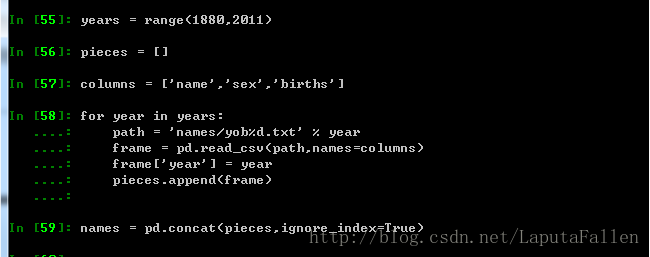
利用pandas.read_csv加载数据到DataFrame:
对frame分组后两种方式聚合数据:

利用pandas.concat()进行数据组装,两点需要注意,1.pandas.concat默认按行组装,2.ignore_index必须为True:
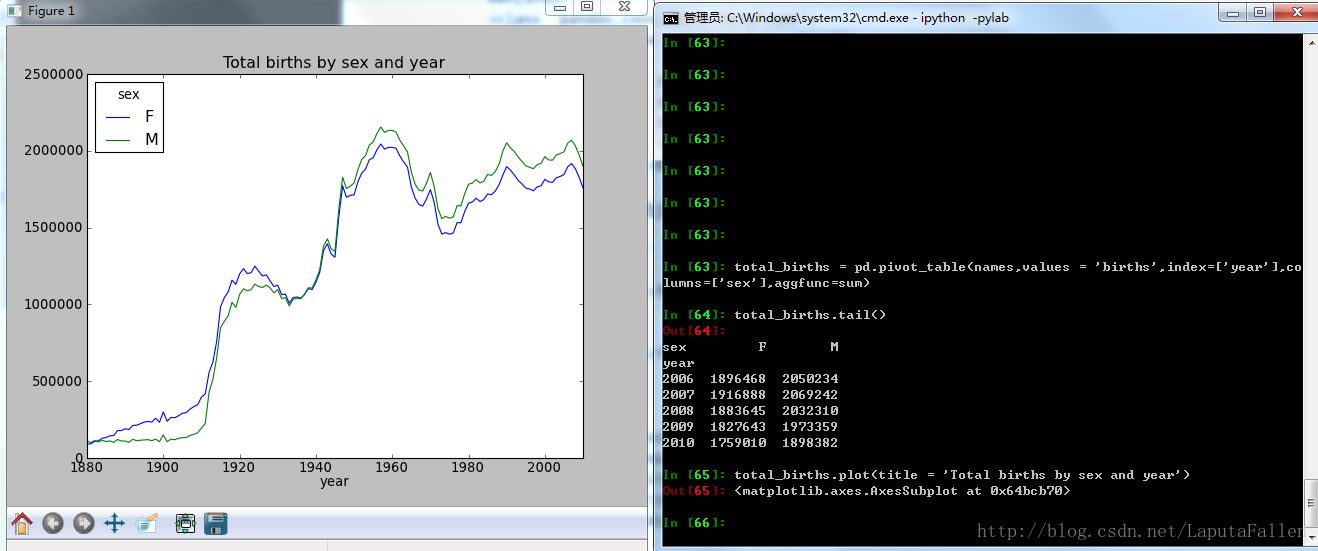
调用pivot_table后绘图:
插入prop列,用于存放指定名字的婴儿数相对于总出生数的比例:

利用np.allclose校验数据:
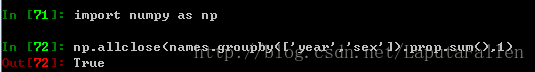















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









