







集合
集合
对象容器,用于存放对象
优势:
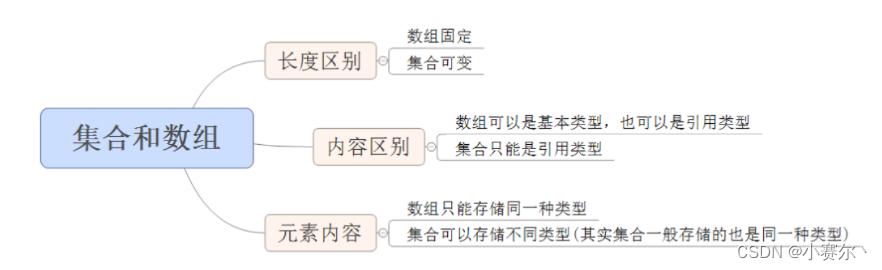
数组定长,一旦定义不能改变
数组中没有方法
数组中只能存放相同的数据类型的数据特点:
长度可以改变
集合中丰富的操作元素的方法
集合中只能存储引用数据类型的数据分类:
单例集合(集合中的一个元素保存一个数据) Collection
接口的接口 对象的集合
双列集合(集合中的一个元素保存两个数据) Map
接口 键值对的集合
| 集合和数组的区别 |
|---|
 |
Collection接口
| 集合架构 |
|---|
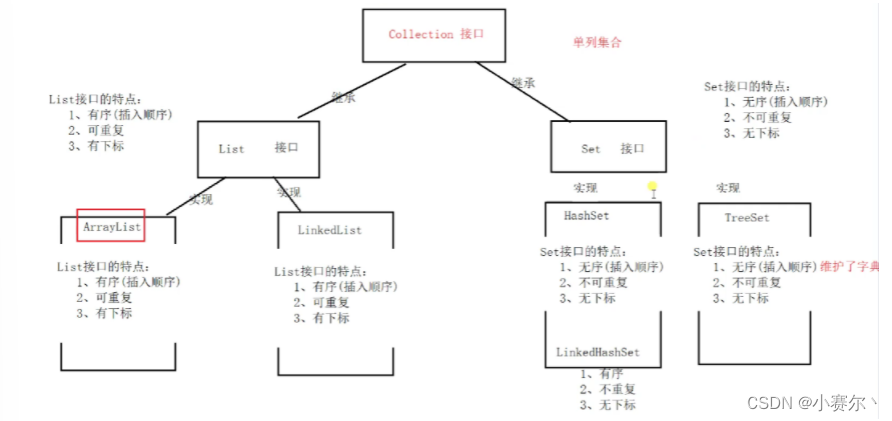 |
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
创建对象
Collection coll=new ArrayList()
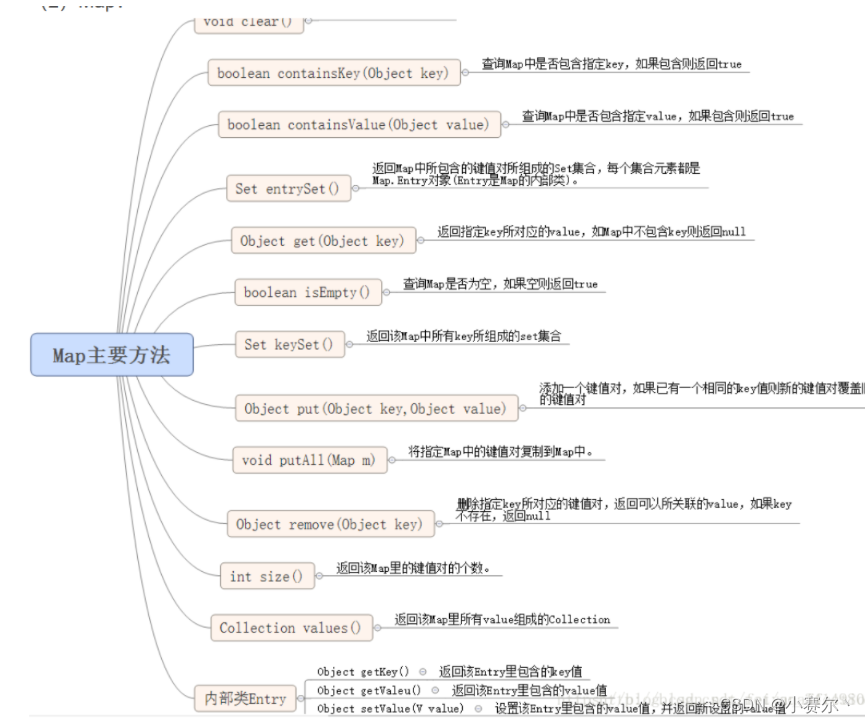
接口下的常用方法
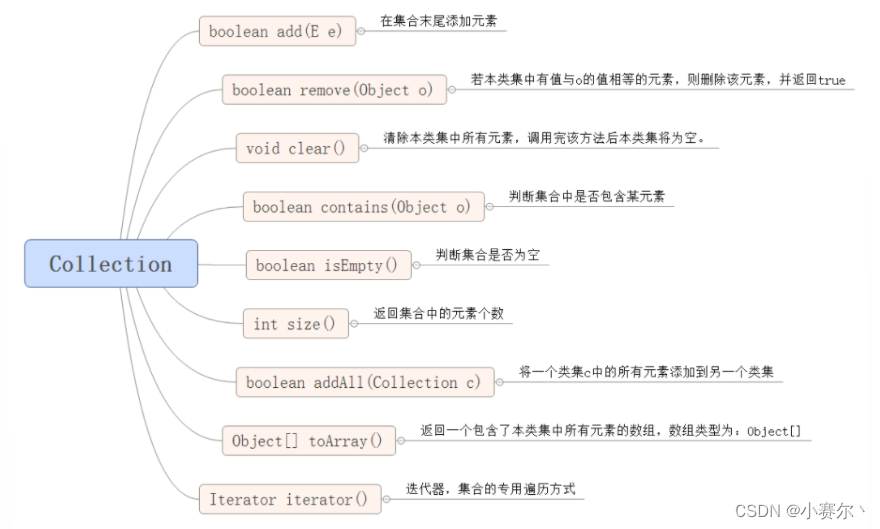
add() 集合中添加元素
add(1); //1–>Integer–>Object 自动装箱–>多态(向上转型)
clear方法,清空集合中所有元素 contains方法 判断集合是否包含某个元素
isEmpty判断集合是否为空
remove方法 移除集合中元素返回boolean类型。如果集合中不包含则删除失败
size()返回集合中元素的个数
toArray将集合转换成数组 xxAll() 操作一个集合的元素
addAll 向一个集合中添加另一个集合
containsAll 判断一个集合中是否包含另一个集合
removeAll 从一个集合中移除另一个集合
| Collection集合的方法 |
|---|
 |
list
| List |
|---|
 |
set
hashCode+equals
list/set区别
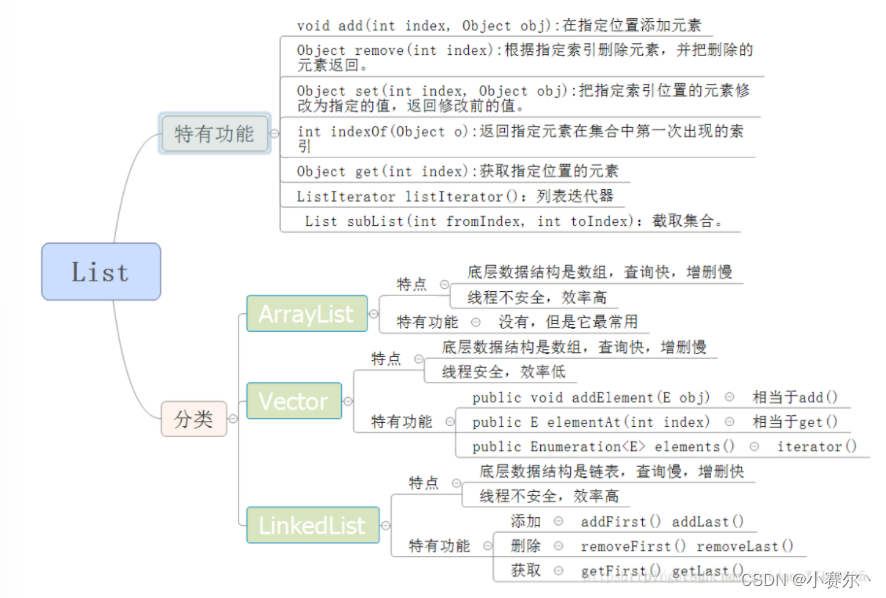
List特点:元素有放入顺序,元素可重复
Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉
set只能用迭代器
list可用下标或迭代器
适用场景
当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
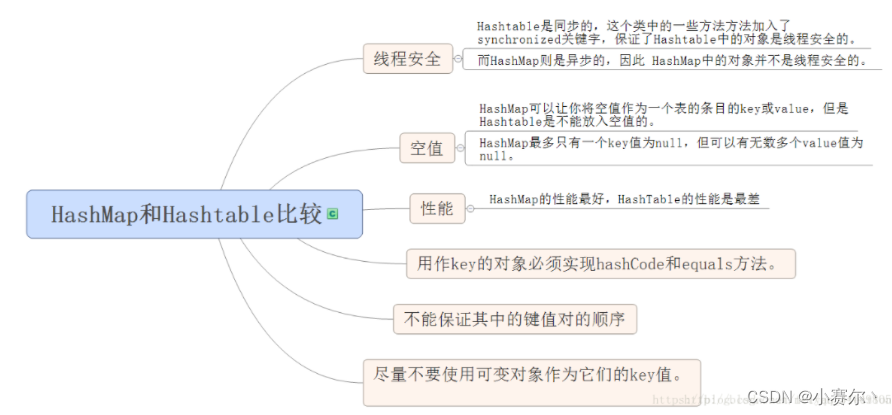
线程安全Vector
HashSet其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet
map集合
保存具有映射关系的数据,Map 没有继承 Collection 接口, Map 提供 key 到 value 的映射
| HashMap和HashTable的比较 |
|---|
 |
迭代器
迭代器原理
迭代是重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。
| 迭代器原理 |
|---|
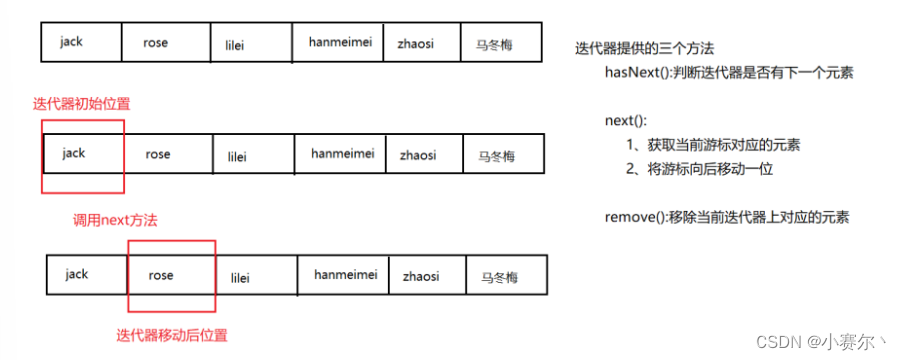 |
获取迭代器对象
(标配代码)
//获取迭代器对象
Iterator it=coll.Iterator()
//判断是否有下一个元素,有取出,没有结束循环
while(it.hasNext()){
//获取下一个元素并移动游标到下一个位置
System.out.println(it.next());
}
/*注意
迭代器不能使用多次,多次使用重新获取
迭代器迭代完成之后,迭代器的位置在最后一位。 所以迭代器只能迭代一次
同一次迭代中,不能多次使用next方法
可能会出错 NoSuchElementException
迭代器在迭代过程不能调用add或者remove方法
不能向集合中添加或者删除元素,ConcurrentModificationException*/
泛型基本使用
泛型:参数化类型
作用:
避免类转化异常
在没有使用泛型的时候,向集合中存储的实际是Object类型,所以获取的时候也是Object类型
老师和学生类里,学生类有个方法,遍历集合时调不了(发生了多态)
如果要这个元素,需要发生向下转型
那么在整个存储集合元素的时候,就不停发生向下和向上转型,泛型的好处就是类型转换的操作提前到了编译期
特点:
泛型集合在存储元素的时候支持多态(不推荐使用)用的时候还得强转
泛型定义的时候不存在多态
泛型擦除:在jdk1.7以后,右边的<>中不用定义泛型类型
集合的泛型不能是基本类型,得用包装类
语法:
泛型定义 集合类型<泛型> 变量名 = new 集合类型<>();
Collection coll=new ArrayList();
ArrayList类
常用方法
- add(int index, E element)
- remove(int index)
- set(int index, E element)
- get(int index)
- subList(int beginIndex,int endIndex)
- list.listIterator();
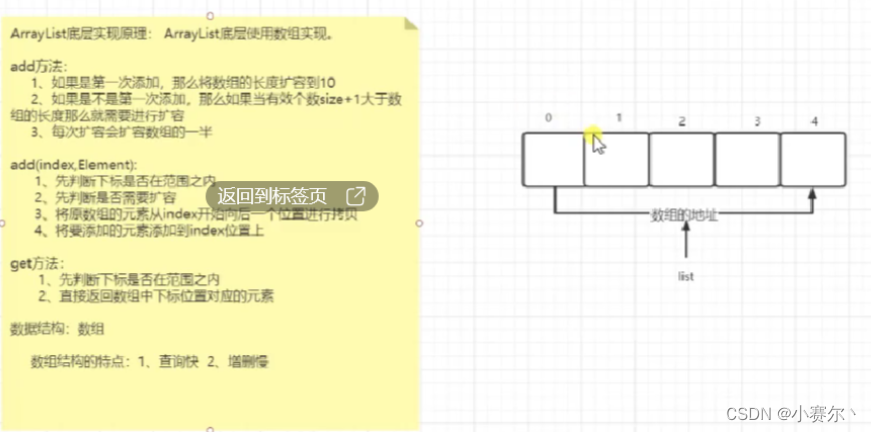
ArrayList集合
基于Collection的方法上增加了一些下标方法
底层:数组
创建ArrayList集合
ArrayList<String> list=new ArrayList<>()
方法
向指定下标位置添加一个元素,下标范围0~List.size
list.add(index,element);
移除指定下标位置的元素,下标范围0~list.size-1
list.remove(index);
修改指定下标位置的元素,下标范围0~list.size-1
list.set();
获取指定下标位置的元素,下标范围0~list.size-1
list.get();
List集合遍历
使用迭代器
for循环
注意:
只有list集合才有for循环的形式(才有下标)
增强for循环
for(类型 变量名:集合|数组){}
类型:集合或数组中每一个元素的类型
变量名:集合中遍历出来的元素(每一项)
快捷键:list.for
实现原理
ArrayList其底层实现使用数组
LinkedList
常用方法
常用的方法与ArrayList一致。自己独有一些向首尾添加移除等方法(可以模拟对列、堆栈等数据结构)
创建LinkedList集合
LinkedList list=new LinkedList<>()
方法
基于ArrayList的方法上增加
Collection和带下标的方法LinkList类中都有
提供了链表/队列/堆栈的方法链表:
向链表头尾添加元素
addFirst();
addLast();队列:
将元素添加到队尾
list.offer()
获取队列的第一个元素,但不移除
list.peek()
获取队列的第一个元素,并移除
list.poll()
提供了堆栈:元素添加到栈底
list.push()
栈顶获取元素并移除
list.pop()
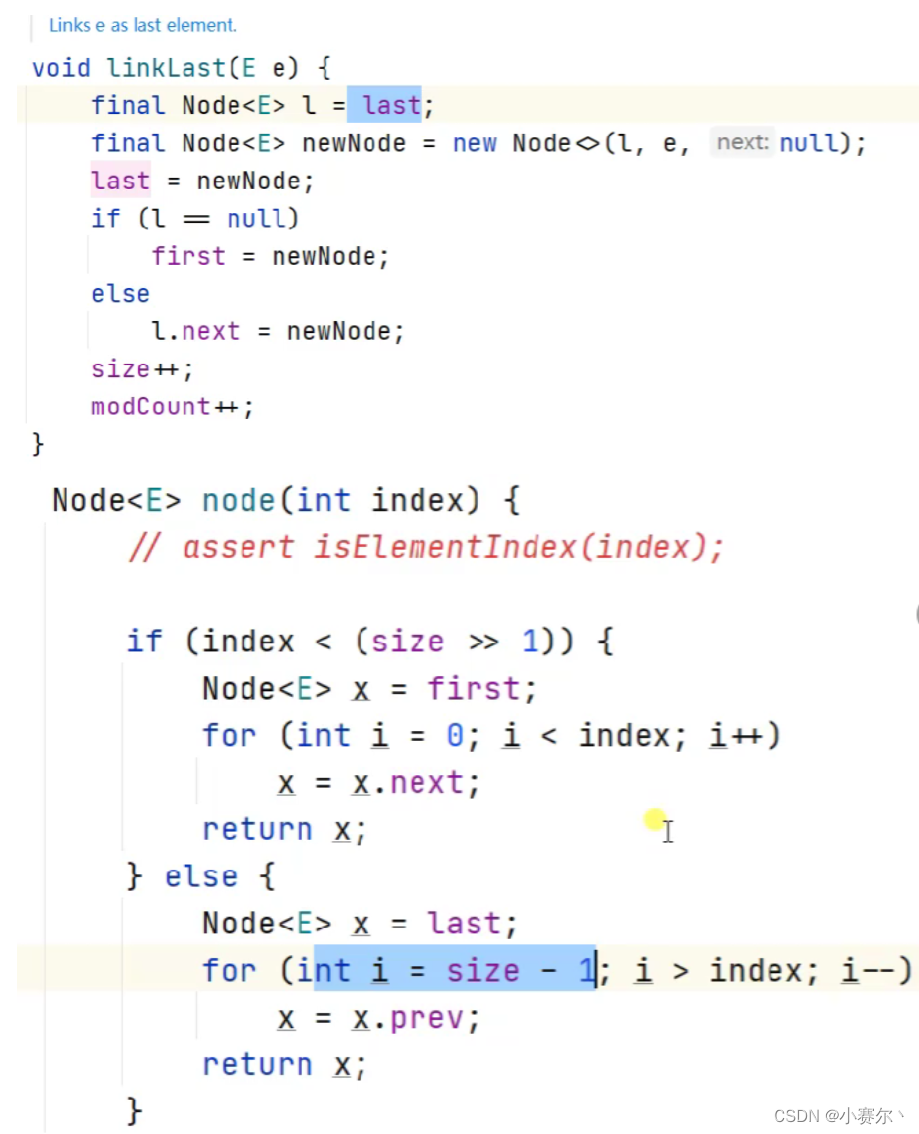
| 实现原理 |
|---|
 |
堆栈和队列结构
| 堆栈和队列结构 |
|---|
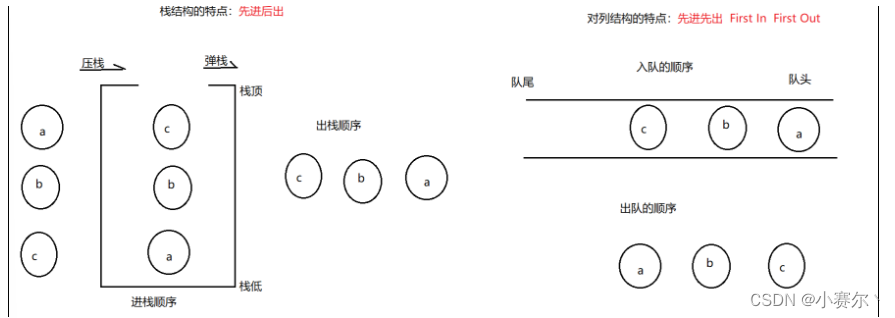 |
堆栈结构
先进后出
队列
先进先出
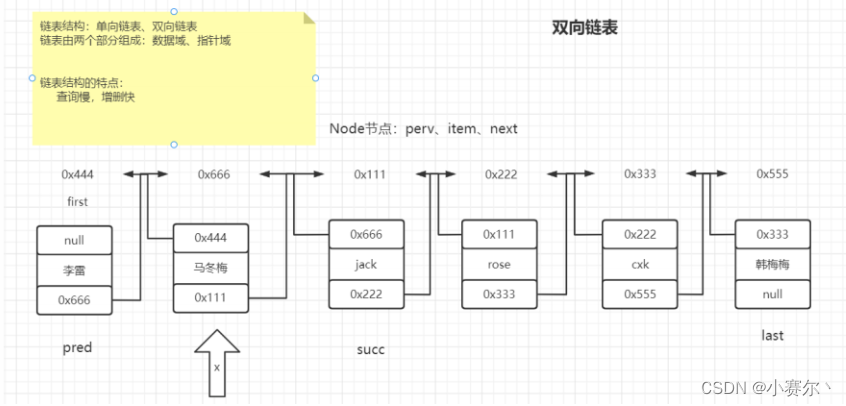
双向链表
增删快,查询慢
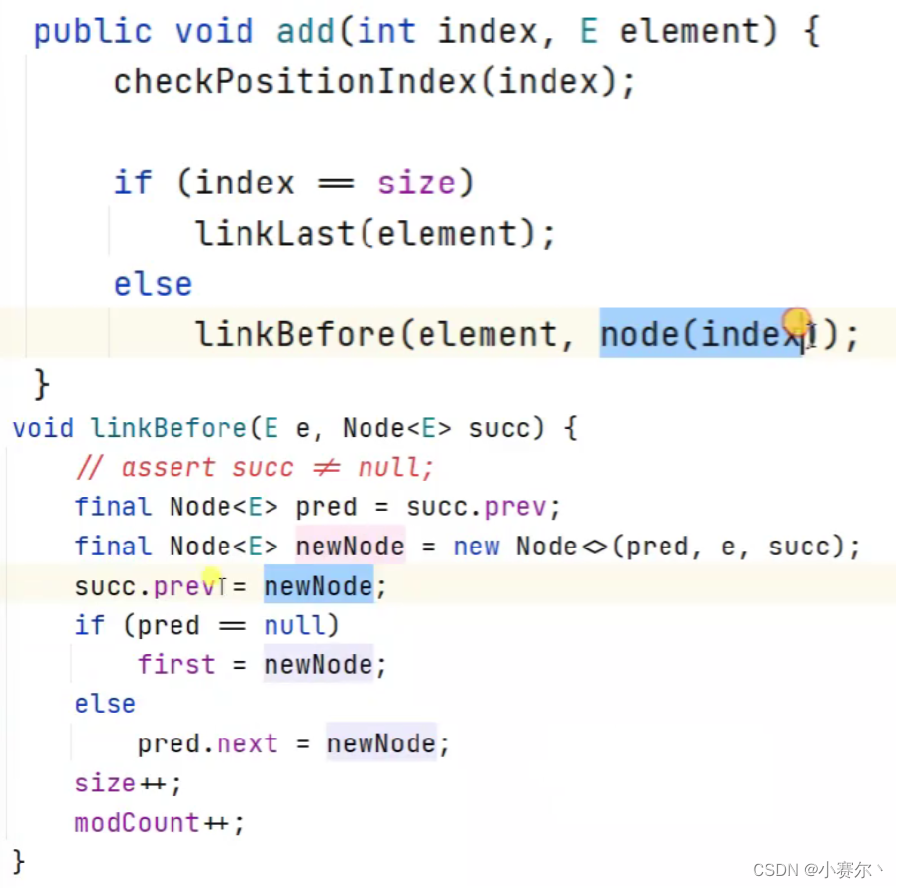
链表:数据域(元素),指针域(别人的地址)
Node节点,定义的同时产生一个新地址
public class Node{
E item; //存放数据
Node<E> prev; //上一个节点
Node<E> next; //下一个节点
}
Vector类
常用方法
与 ArrayList 的方法基本一致
Vector(开发基本不用)
创建Vector对象
Vector<String> vector=new Vector<>()
区别
Vector与ArrayList相同,底层也是一个数组(增删慢、查询快)
在创建对象的时候,创建一个长度为10的数组,而
ArrayList是等到添加元素时才初始化长度10的数组
ArrayList线程不安全,效率高
Vector是线程安全的,但效率低(同步锁,多线程一个)
LinkedList底层使用双向链表实现(增删快、查询慢)
实战开发中真的需要多线程下使用集合,会用CopyOnWriteArrayList(读写锁)
Set集合
set集合
无序/不重复/没下标
HashSet类
常用方法与Collection接口中定义的方法一致
特点:
- 无序 (插入顺序)
- 无下标
- 不可重复
HashSet 去重原理
HashSet
HashSet没特殊的方法,他的方法与Collection中学的一致
底层:HashMap
HashSet去重原理
HashSet首先比较对象的hash值,不一致,直接添加到集合
当值一样时,进而比较equals方法,如果equals方法返回false,就认定两个对象不相等,可以直接添加到集合中
当equals返回true时,认定相等,无法添加
LinedkHashSet
Set集合中唯一一个有序的
底层: LinkedHashMap
双列集合
Map实现
HashMap
HAshtable/Properties
键(key),值(value) 键值对
键:不能重复,无序 值:可以重复,无序
HashMap对象
创建HashMap对象
String表示键的类型 Object表示值
HashMap<String,Object> map=new HashMap<>()
常用方法(基本用前两个)
向map中添加元素
map.put()
向map中获取元素
map.get()
判断map集合中是否包含指定的key或者指定的value
map.containsKey/Value
获取Map中所有的key
Set<String> keySet=map.keySet();
for(String s:keySet){
System.out.println(s);
}
获取Map中所有的Value
Collection<Object>value=map.values();
for(Object value:values){
System.out.println(value);
}
获取Map中所有的Key-Value
//Entry是Map集合中的一个内部类,一个Entry就表示一个键值对
Set<Map.Entry<String Object>> entrySet=map.entrySet();
for(Map.Entry<String Object> entry:entrySet){
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
/*一个用户对象User类表示
多个用户对象,以前:User[] 现在: List<User>
假设User类用的不多,这时没必要创建User类,可用Map代替他
一个用户对象
HashMap<String,Object> map=new HashMap<>()
map.put("username","admin")
多个用户对象
List<Map<String,Object>>
*/
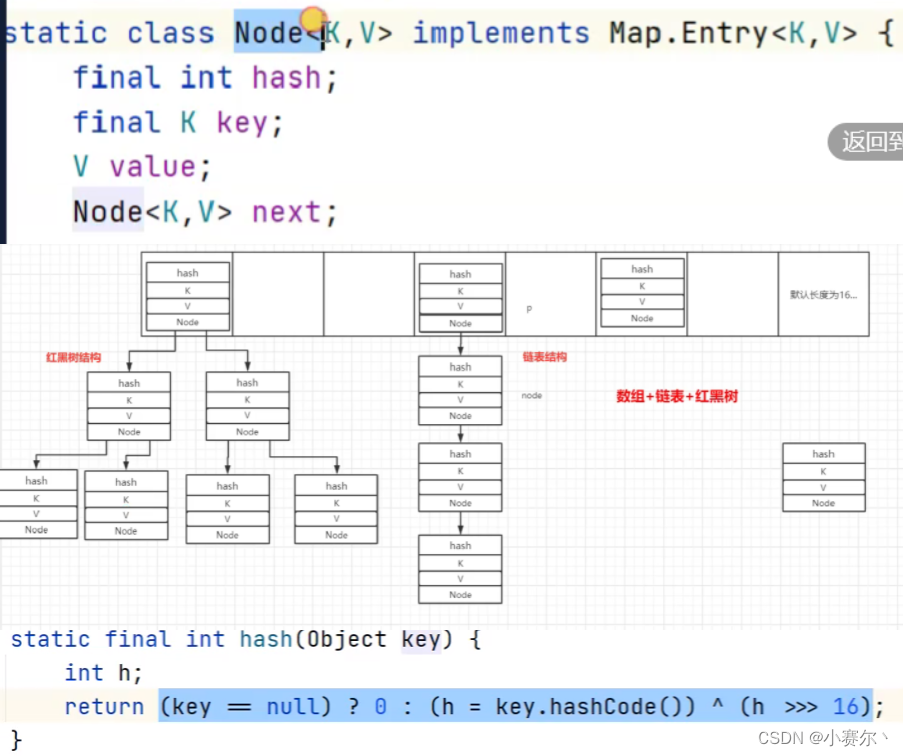
HashMap底层原理
数组+链表+红黑树
17.8/9/10

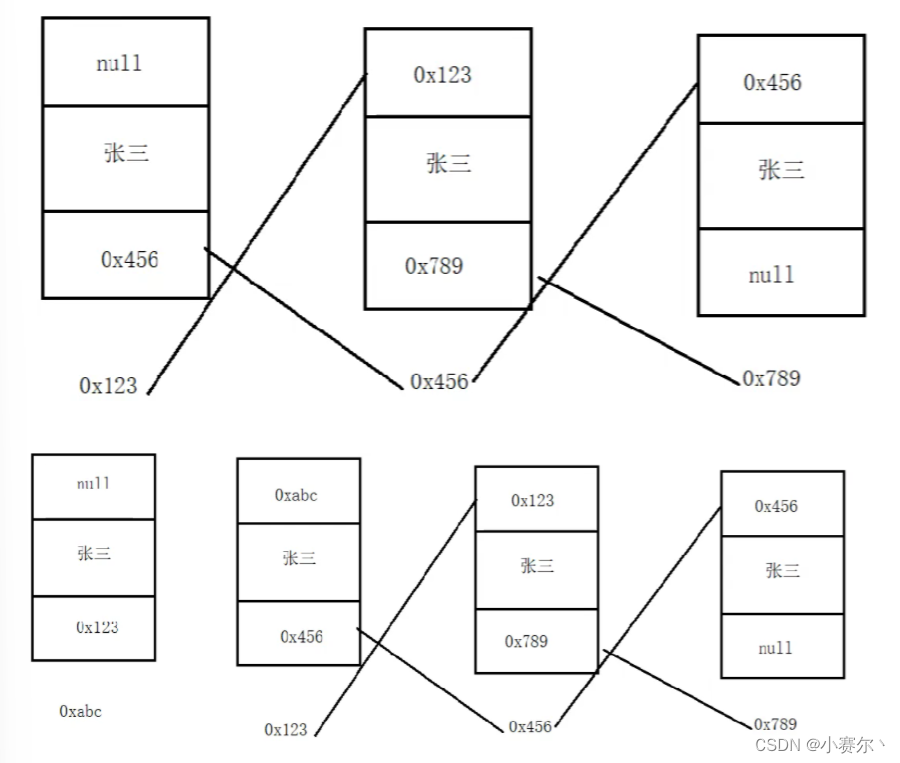
单向链表















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











