






目录
★六个特性 功能性、可靠性、易用性、效率、维护性、可移植性 (功考,易效,可维)
文件操作 touch/mkdir/rm/cp/mv/cat/tail/grep
为什么选择测试:
研发体系:开发--研发--运维
开发难度大,周期长,要求高竞争激烈,科班基础要牢靠
测试门槛低,周期短,入行要求低, 后续也可以成长为代码开发的自动化开发工程师。非科班,转行人,大龄零基础人,有开发基础人友好

路径明确:功能(入行)-----自动化(成长)------性能(自我鞭策)
参照路线:自学软件测试怎么学?【史上最详细学习路线】(附全套资料)_软件测试自学路线-CSDN博客
软件测试的重要性
- 发现缺陷与错误:软件测试的主要目标之一是发现和识别潜在的缺陷和错误。通过对软件进行全面的测试,可以减少在实际使用过程中可能遇到的问题和风险。
- 提高软件质量:软件测试有助于提高软件的质量和稳定性。在早期进行测试可以及时发现和修复问题,从而降低后期产品返工和维护的成本。
- 用户满意度:通过进行全面的软件测试,可以确保软件的功能和性能符合用户的期望。这有助于提升用户满意度,增加用户对软件的信任度。
- 保护品牌声誉:软件缺陷和错误可能会对企业的品牌声誉造成严重影响。通过高质量的软件测试,可以减少由于缺陷引起的潜在损失,保护企业的声誉和信誉。
软件测试是什么:
使用人工或自动化手段来运行或测试某个系统的过程,其目的在于检验他是否满足规定的需求或弄清楚预期结果与实际结果之间的差别。
手段:手工点点点,自动(执行代码替代手工操作)
按规定的需求,测试预期结果与实际结果是否相符!
发展方向:
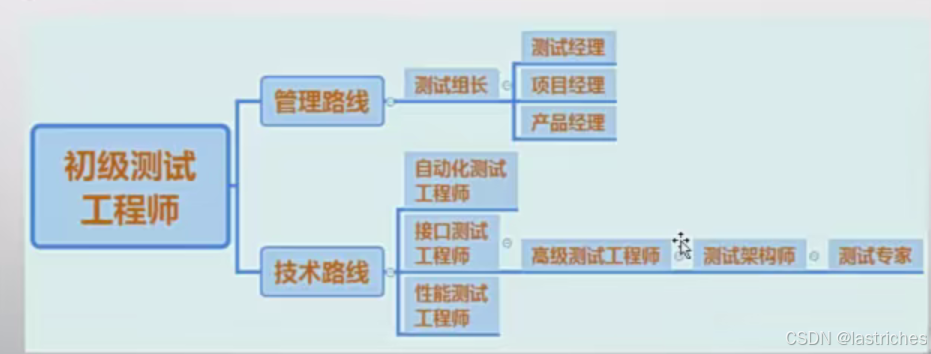
-----阶段一:测试基础------
预备准备:
软件安装:
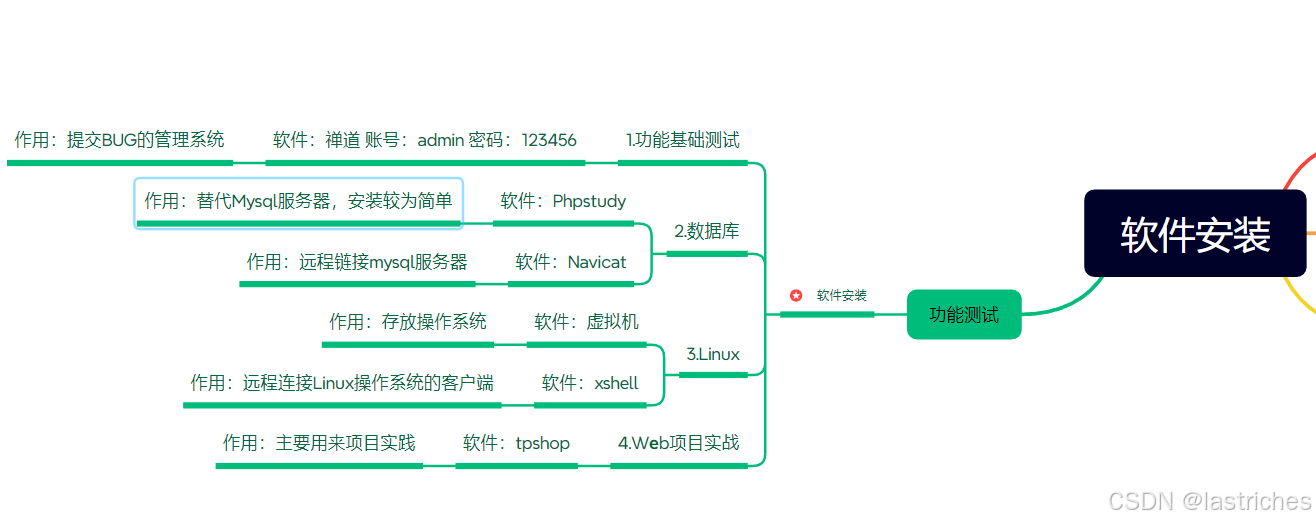
1.禅道ZenTao安装:
安装步骤
1. 根据个人电脑系统类型,确认安装包类型,若个人电脑是64位,可以安装64位的安装包,反之安装32位的。 查看个人电脑系统类型通过:右键我的电脑-属性-系统类型 。
2. 以下为禅道在Windows下的两个安装包,分别为Window32位和Windows64位
3. 双击对应安装包,解压缩到某一个分区的根目录,比如d:\chandao,必须是根目录
4. 进入目录,点击start.exe进行启动
5. 打开的界面中,点击启动禅道。6. 当内容框中弹出成功启动apachezt和mysqlzt 的提示证明安装成功 。 打开浏览器访问如下图地址:
说明:若端口被占用,可以修改apache和mysql的启动端口。(只有在端口被占用时可操作如下步骤)
1. 点击集成面板(运行chandao/start.exe后出现的控制台)左上角 服务-卸载服务 点击集成 面板左上角 服务-配置默认端口,修改端口号后保存
2. 退出集成面板后重新以管理员身份运行 chandao/start.exe 点击启动禅道。
3. 启动集成面板之后,点击“启动禅道”按钮,系统会自动启动禅道所需要的apache和mysql服务
4. 启动成功之后,点击“访问禅道”,即可打开禅道环境的首页
2.数据库安装:
1.使用 phpstudy 安装 MySQL
注:phpstudy 中集成了很多版本的 mysql ,可以随意的切换 。
2. Navicat 破解版安装与连接数据库
注:Navicat可以远程连接Mysql服务器,提供了可视化编辑界面
3.Linux本地虚拟安装
1.VMware workstation安装虚拟机:
安装步骤:
1. 新建虚拟机
2.选择自定义
3. 选择要安装的操作系统
4. 选择虚拟机的CPU核数和数量
5. 设置虚拟机的内存
2 安装操作系统
安装步骤:
1. 开启虚拟机
2. 选择简体中文
3. 安装所必要的软件
4.选择左侧最后一项,右侧的复选框都勾选上 。点击左上角的完成 。
5.选择后请检查返回的界面是否正确 。
6.若不能激活"开始安装"(英文版为Begin installation)按钮,请选择下面的 INSTALLTION
DESTINATION
7.设置root的密码,学习时为了方便登录,建议设置一个简单的密码,防止忘记 。
8 .安装完成后需要完成一次重启。
9.重启后,进入的界面,需要选择接收许可证 。
3.安装Xshell和XFTP
4.Web实战项目tpshop安装:
tpshop是用于进行web项目实战使用的 。此软件安装非常简单 。具体安装步骤如下:
1. 选择安装包进行解压,右击tpshop进行解压 .选择解压文件 。
2. 将所有文件解压到phpstudy下的www目录下,这里phpstudy建议放在根目录下 。
3. 启动phpstudy,确认两个服务启动成功 。
需要注意的是这里的服务会和禅道所有的服务产生冲突, 使用phpstudy时一定要把禅道停掉, 切记、切记、切记。
4. 这时打开浏览器,在浏览器地址栏中输入: localhost ,点击接受 。
5. 输入数据库密码和管理员密码 ,这里需要注意的是,数据库密码是root(固定的). 管理员密码可以 自己设置,为了方便记忆,建议设置一个简单的 。点击创建数据后,就会自动往数据库中创建表。
6. 安装完成后,就会进入这个界面 ,这两个按钮分别对应两个系统。
前台系统地址:http://localhost/
后台系统地址:http://localhost/index.php/Admin/Admin/login.htm
补充工具:
流程图绘制:Visio/在线ProcessOn
截图工具:Snipaste
日志工具:Notepad++
笔记工具:obsidian
功能测试:
测试基础:
1.软件介绍
1.1 什么是软件
国际定义:与计算机系统操作有关的计算机程序、规程、规则以及可能有的文件、文档和数据
教科书:
运行时,能够提供所要求功能和性能的指令或计算机程序集合
程序能够满意地处理信息的数据结构
描述程序功能需求以及程序如何操作和使用所要求的文档
即:软件=程序+数据+文档
2.软件开发过程模型
基本开发过程:可行性分析、需求分析、总体设计、详细设计、编码、测试、维护阶段。即软件生命周期
2.1 瀑布模型
瀑布模型:软件计划(可行性分析)-需求分析-设计-编码-测试-维护
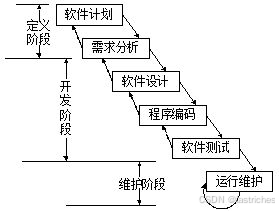
知识参照博主:软件生命周期模型——瀑布模型-CSDN博客
- 瀑布模型
- 原型模型
- V模型
- 螺旋模型
- 迭代模型
2.2 V模型
★V模型:
无法回溯,只需要关注该环节的工作内容即可,不支持反复修改需求。 例如航空航天项目
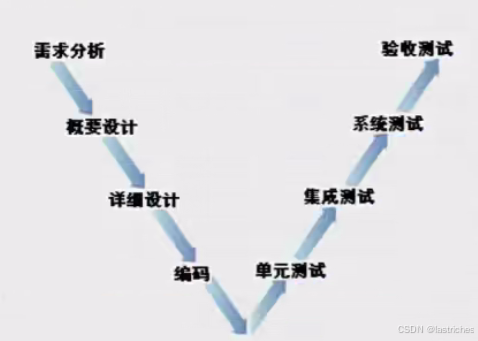
需求分析:产品经理撰写:需求分档说明书 评审会议设计开发、测试、UI等
概要设计:参照博主:软件设计过程--概要设计&&详细设计_概要设计和详细设计的内容-CSDN博客
详细设计:产品经理:设计产品原型图 开发:开发文档
编码:写代码
单元测试:又称模块测诚,针对软件设计中的最小单位—程序模块,进行正确性检查的测试工作。单元测试需要从程序的内部结构出发设计测试用例。多个模块可以平行地独立进行单元测试。测试代码,(看代码)
测试技术:白盒测试 大部分由开发来完成
单元定义:C中指一个函数,Java中指一个类,在图形化的软件中,单元一般指1个窗口,1个菜单。
集成测试:又叫组装测试,通常在单元测试的基础上,将所有程序模块进行有序的、递增的测试。重点测试不同模块的接口部分。开发人员将开发的各独立模块集成起来,实现某一功能的测试。例如淘宝:登录-浏览商品-加入购物车-下单-结算 (看接口)
测试技术:灰盒测试(接口测试)大部分由开发人员完成,测试工程师协助测试
系统测试(功能测试):已经有成型的测试软件,由测试工程师来完成 (看界面)主要验证产品的各个模块是否可以正常使用
测试技术:黑盒测试
验收测试:整个系统测试阶段完成后,由开发,产品及甲方客户验收,给客户完整演示产品的各个模块。客户通过,可以安排部署上线
注:四大测试可参照:软件测试的四个阶段(单元测试、集成测试、系统测试、验收测试)_测试阶段-CSDN博客
2.3 迭代模型
迭代模型:
把一个复杂且周期较长的开发任务,分解成很多小周期内可完成的任务。每一个小周期就是一次迭代,每一次迭代都会交付或开发一个可以交付的软件产品。
与传统瀑布式开发相反(需求经常变动),弥补了弱点。成功率和生产率提高
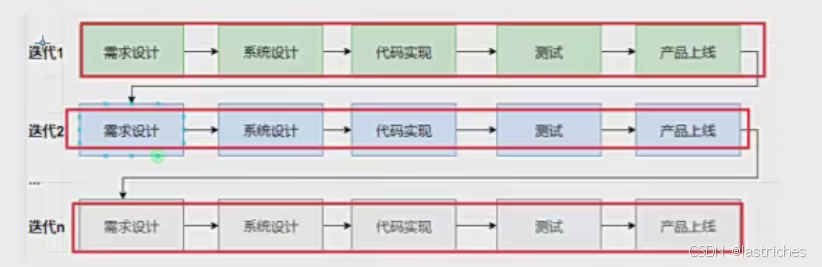
特点:
- 线性开发模型,但是将一个大系统分为若干个迭代分析模型逐次上线,极大缩短迭代周期。
- 每个版本需求根据产品上线后的反馈来制定
- 因为上线周期短,所以文档轻量化
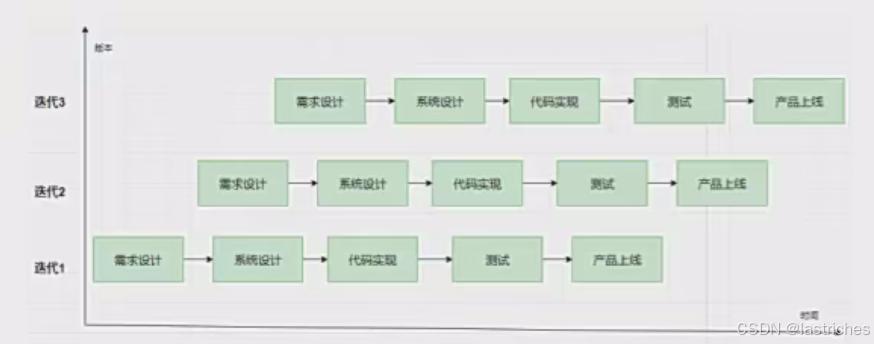
特点:
- 进一步压缩上线周期,把串行的开发方式改为并行方式。但人力成本较高
- 每个版本的需求仍然是根据产品上线的反馈来制定的
- 因为上线周期短,所以文档轻量化
迭代式模型开发的特点:
- 降低风险(人多速度快不易延期)
- 得到早期用户反馈
- 可以持续地测试和集成
- 快速地更新迭代,上线周期短,文档轻量化
- 迭代频率高
- 每个迭代地版本是由单独的小组来完成的
- 上线周期较短,文档比较轻量化,所以比较注重人与人之间的高度协作(沟通表达,理解能力)
2.4 敏捷开发模型
敏捷开发模型:以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发
快速迭代,小步快跑。比迭代开发模型周期更短,上线频率更高,更需要协作 [2--3周]
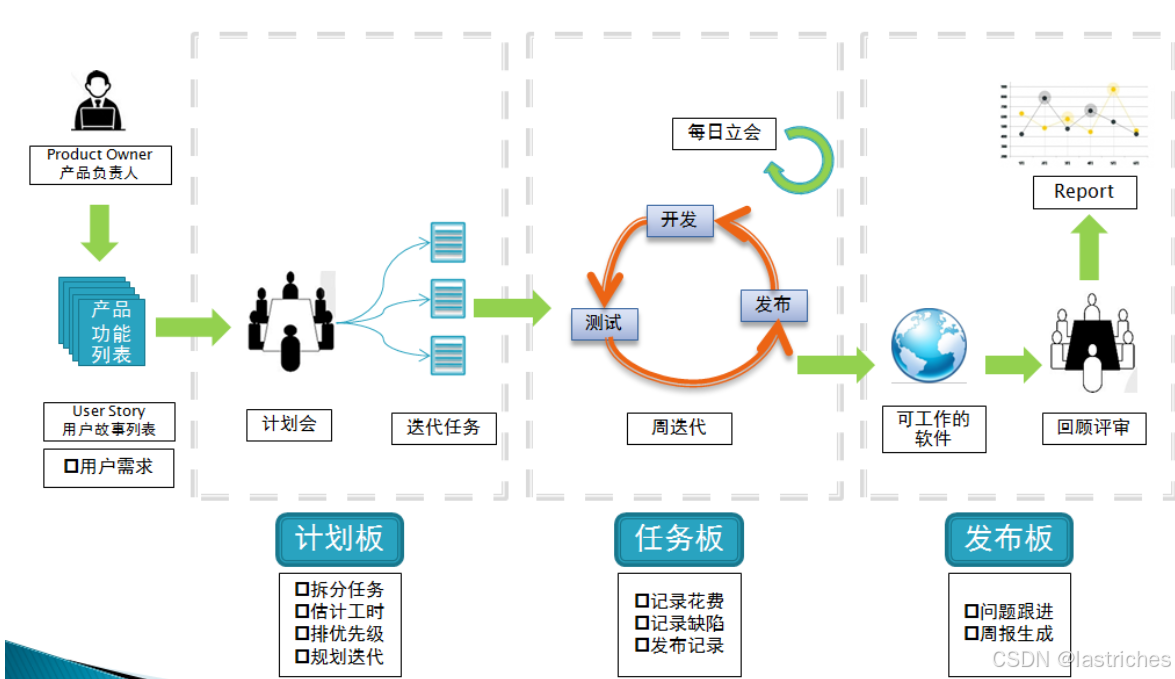
可参照博主:软件开发模式之敏捷开发(scrum)-CSDN博客
敏捷模型是一种迭代和增量的开发方法,它强调灵活性、快速反应和客户协作。在敏捷模型中,需求被分解成许多可以增量开发的小部分,每个增量部分都是在迭代中开发的。这种方法的主要目的是促进项目的快速完成,通过使过程适应项目,删除对特定项目可能不是必须的活动来实现敏捷性,避免任何浪费时间和精力的事情。
2.5 总结
四者对比:
瀑布式 , V模型 :都是需求-设计-编码-测试-交付的大致顺序流程。都要求每一个开发阶段都要做到最好,特别是前期阶段,错误越少积累则成本损失越低
迭代式:不要求每一个阶段的任务都做得最好,接受不完美。而是追求以最短的时间,最少的损失先将主要功能搭建起来,尽早交付一个“不完美的成果物”,得到客户和用户的反馈信息后再去完善
敏捷开发,迭代式开发:两者都强调在较短的周期内提交软件,但是周期更短,因此也更加强调队伍素质和协作
扩展可以参照博主:10种软件开发模型整理_软件开发模型的分类与应用-CSDN博客
3.软件质量模型
软件质量是客户满意的主要因素,而软件测试就是软件质量保证的一个重要手段
软件质量,即软件与明确地、隐含地定义的需求相一致的程度。软件质量模型是评价软件质量的国际标准。
★六个特性 功能性、可靠性、易用性、效率、维护性、可移植性 (功考,易效,可维)
功能性:客户对于软件功能性的需求,软件所实现的功能达到它的设计规范和满足用户需求的程度
可靠性:软件持续运行的能力,在规定的时间,规定的条件下软件不发生错误的概率
易用性:对于一个软件,用户在学习、操作和理解过程中所做努力的程度。客户易上手易理解
效率:产品的性能,在规定条件下,用软件实现某种功能所需的计算机资源(包括时间)的有效程度
维护性:产品可被修改的能力,当环境改变或软件运行发生故障时,为使其恢复正常运行所做努力的程度
可移植性:软件产品从一种环境迁移到另一种环境的能力,为使一个软件从现有运行平台向另一个运行平台过度所做努力的程度
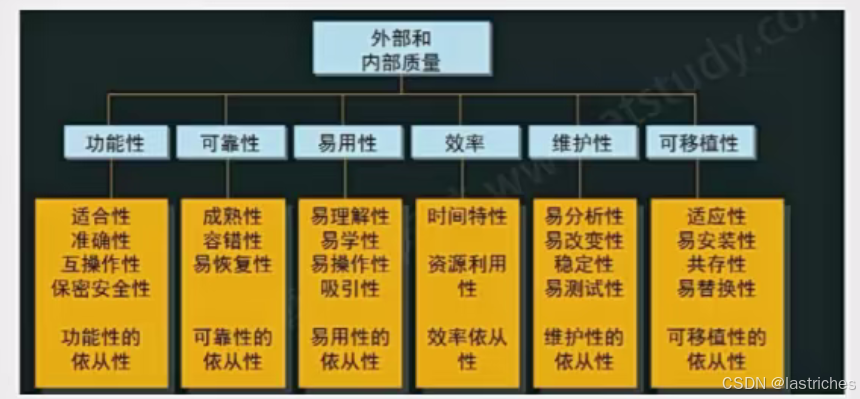
扩展知识,可看博主:
测试工程师需求的是:
- 功能
- 性能
- 易用性
- 兼容性
- 安全
4. 环境介绍
开发环境:开发人员为了联调程序而搭建的环境
测试环境:测试人员为了测试程序而搭建的环境
准生产环境:也称为预发布环境/灰度环境,测试人员为了模拟生产环境而搭建的环境
生产环境:也称为线上环境,用户访问的系统所部署的环境
什么软件测试?
软件测试是使用人工或自动的手段来运行或测定某个软件系统的过程,其目的在于检验他是否满足规定的需求或弄清楚预期结果与及时结果之间的差别。
!测试的本职工作必须且自需保障实际结果达到了需求的预期结果 !
注:
需求:需求说明书中的规定功能
预期结果:按照需求说明书中规定的结果
实际结果:软件开发人员开发出的程序执行结果
1. 软件测试分类
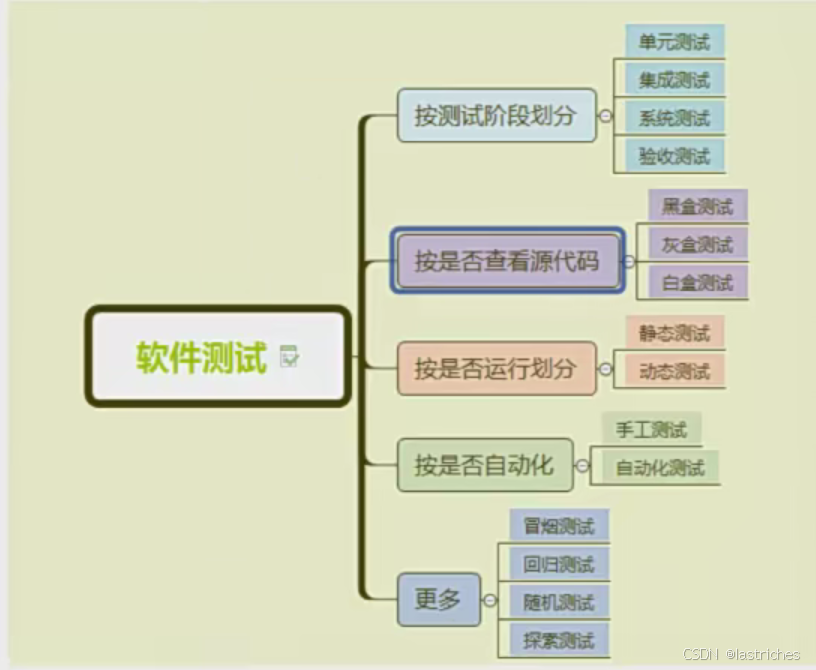
1.1 按测试阶段划分
单元测试 -------> 集成测试 -------> 系统测试 ------> 验收测试

单元测试、集成测试、系统测试的比较:
1. 测试技术不同
单元测试:白盒测试
集成测试:灰盒测试
系统测试:黑盒测试
2. 评估基准不一样
单元测试:基准是逻辑覆盖率
集成测试:基准是接口覆盖率
系统测试:基准是对需求的覆盖率
3.考察范围不一样
单元测试:单元内部的数据结果,逻辑控制,异常处理等
集成测试:模块与模块之间,接口与接口数据传递,以及各模块能否完好的集合在一起
系统测试:这个系统相对于需求的符合度
验收测试:确保软件实现能够满足用户的需求(实际是产品来做)
α测试:Alpha测试
内测版本,通常只在公司内部进行测试,有可能是测试人员,有可能是公司其他部门参与进行
β测试:Beta测试
公测版本,针对所有用户开发的测试版本
目的:更多的收集用户的反馈和线上的BUG,然后进行修正,为正式版本做准备
1.2 按是否查看源代码
黑盒测试:
- 黑盒测试也称为功能测试,测试中把被测的软件看作一个黑盒子,不关心盒子的内部结构是什么,只关心软件的输入数据和输出数据,更多是站在用户角度去测试。测试
例如:输入5 + 2,查看输出为7,黑盒测试人员只关心输出是不是7
白盒测试:
- 白盒又称结构测试或者逻辑驱动测试或基于代码的测试。白盒指的打开盒子,去研究里面源代码的逻辑实现。开发
灰盒测试:
- 介于白盒和黑盒之间的一种测试。灰盒测试多用于集成测试阶段,不仅关注输出、输入的正确性,也关注主程序内部的情况。开发主导,测试辅助
1.3 按是否运行分类
静态测试:
- 静态测试是指不运行被测程序本身,仅通过分析或检查源程序的语法、结果、过程、接口来检查程序的正确性。对需求规格说明书PRD、软件设计说明书、源程序进行结构分析、流程图分析、符号执行来找错
动态测试:
- 动态测试是指按预先设计好的数据和步骤运行被测程序,检查运行结果与预期结果的差异,并分析运行效率、正确性和健壮性等性能。 由三部分组成:构造测试用例、执行程序、分析程序的输出结果
1.4 按是否自动化分类
手工测试(Manual)
- 手工测试就是人工按照测试用例的步骤执行被测程序,然后观察结果从而比对软件的输出和测试用例的预期结果是否相一致
如:测试用例的编写,测试用例的评审,测试用例的修改等
自动化测试
- 自动化测试是指把以人为驱动的测试行为转化为机器执行的一种过程,即模拟手工测试步骤通过程序员编写的测试脚本自动地测试软件,包括所有测试阶段,跨平台兼容且是进程无关的
其他
★冒烟测试Smoke:(评审开发人员交付测试的程序是否满足用来测试的标准)
- 冒烟测试目的是确认软件基本功能正常使用,一般会从所编写的用例中选取一组最基本的用例进行执行,一般通过冒烟测试来衡量开发提出测试版本是否达到测试标准
注:重点是最核心的功能模块(一般是主干流程)
随机测试Ad-hoc Testing:(主要是对被测软件的一些重要功能进行复测,也包括测试哪些当前用例没有覆盖到的测试)经验
- 随机测试主要是根据测试者的经验对软件进行功能抽查,没有约束性的随便进行测试,更多的依据经验和尝试性地进行测试
探索性测试Exploratory:(一种测试思维,强调人的主观能动性)
- 探索性测试旨在促使测试人员抛弃繁杂地测试计划和测试用例设计过程,在碰到问题时及时改变测试策略。
回归测试:
- 回归测试旨在针对提交给开发的BUG,在开发修改后,除了进行BUG是否解决的验证,同时还要测试是否有新的BUG被引发,有没有影响到其他功能
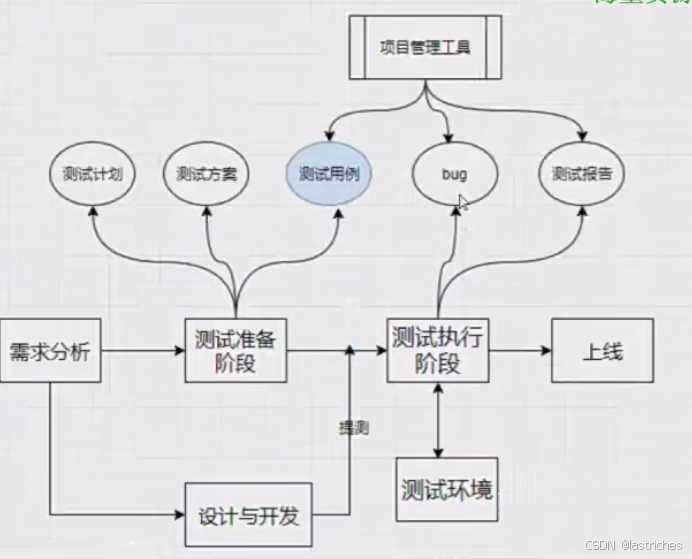
★软件测试流程
软件测试流程:需求评审--->需求分析(测试人员)--->编写测试计划---->提前测试点---->编写测试用例和评审用例---->冒烟测试----> 执行测试用例---->bug提交与管理
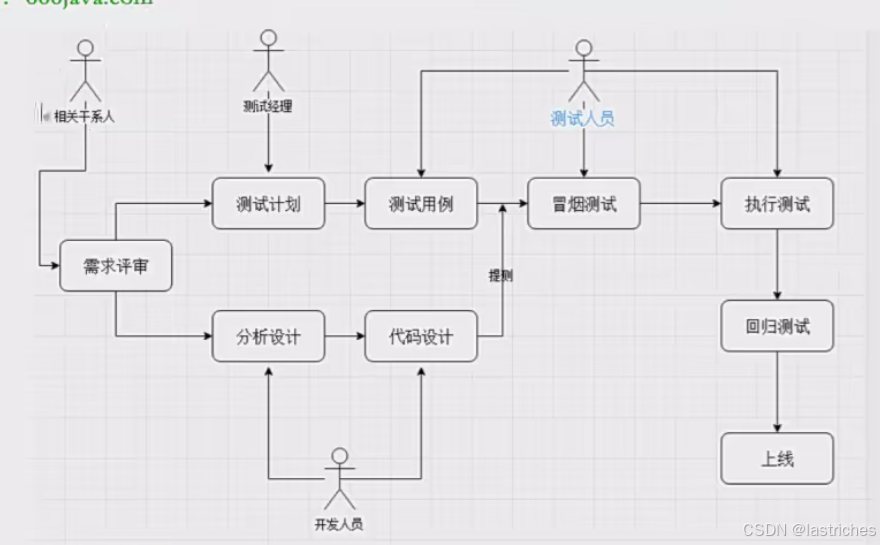
1. 需求评审(产品主导)

需求分析:

2. 编写测试计划
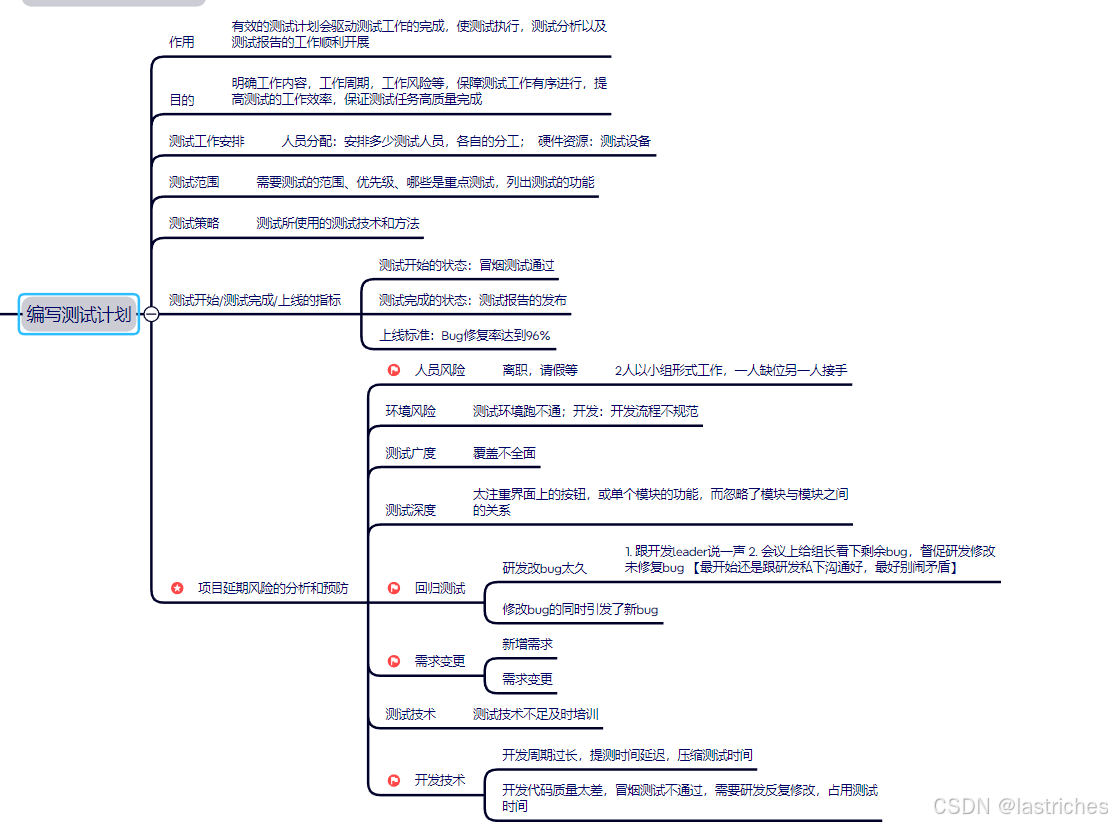
提取测试点:
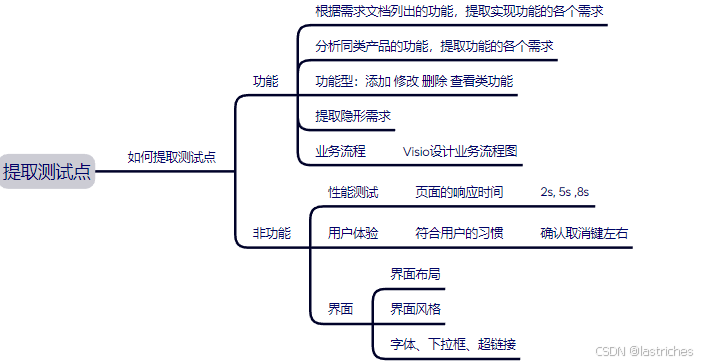
注:业务流程:单独功能穿起来形成主要功能 VISIO梳理业务流程图
技术方法:
- 等价类划分:根据需求说明书规定的输入范围划分,符合规定条件的称为有效等价类
- 边界值分析法:专注于测试输入或输出的边界值,等于略高于最小值,等于略低于最大值称为有效边界值
- 状态迁移法:通过状态的变化反应不同业务流程
- 场景法:又称为流程设计方法。通过运用场景来对系统的功能或业务流程进行描述,从而模拟实际用户的操作流程 涉及三种场景:基本流,备选流,异常流
- 错误推断法:一种基于经验和直觉推测程序中所有可能存在的各种错误,从而有针对性的设计测试法。错误推断法要素共有三点,分别为:经验、知识、直觉。
- 因果图
- 决策表
- 正交检验法
场景法
基本流:系统按照正确有效的业务执行完毕的一条流程。一般是用户操作最频繁的一种操作
备选流:系统按照无效或错误的业务执行的一条流程,一般是用户可能会有的一种操作
场景法测试用例的写作步骤:
1. 分析基本流和业务场景(用ProcessOn在线或Visio软件进行流程图绘制)
淘宝购物流程:购物
基本流:登录账号--浏览商品--加入购物车--支付--生成订单
备选流1:登录--忘记密码--找回密码流程
备选流2:登录--忘记密码--密码输入错误次数超过3次--账户被锁定
备选流3:登录--账号未注册
备选流4:商品支付,余额不足--充值
备选流5:商品支付,切换支付方式
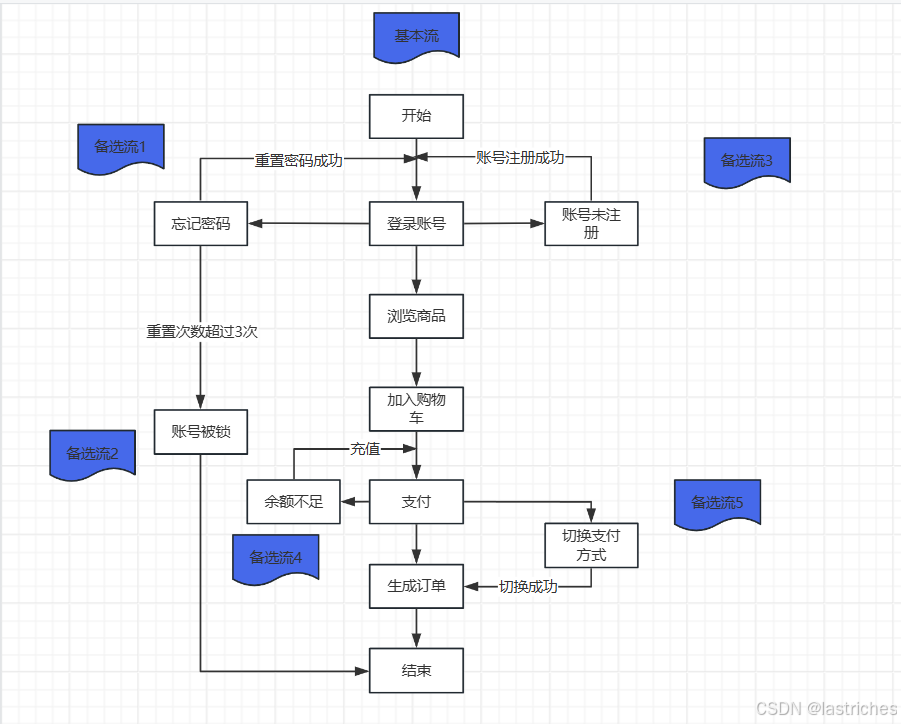
2. 根据基本流和备选流组合成不同的业务场景,场景要具有一定的业务意义
场景1:基本流
场景2:基本流+备选流1
·
·
·
3. 将无意义的业务场景去掉
4. 最后将每个业务场景生成相应的测试用例
技术方法的详细描述具体可参照博主:软件测试方法精讲-CSDN博客
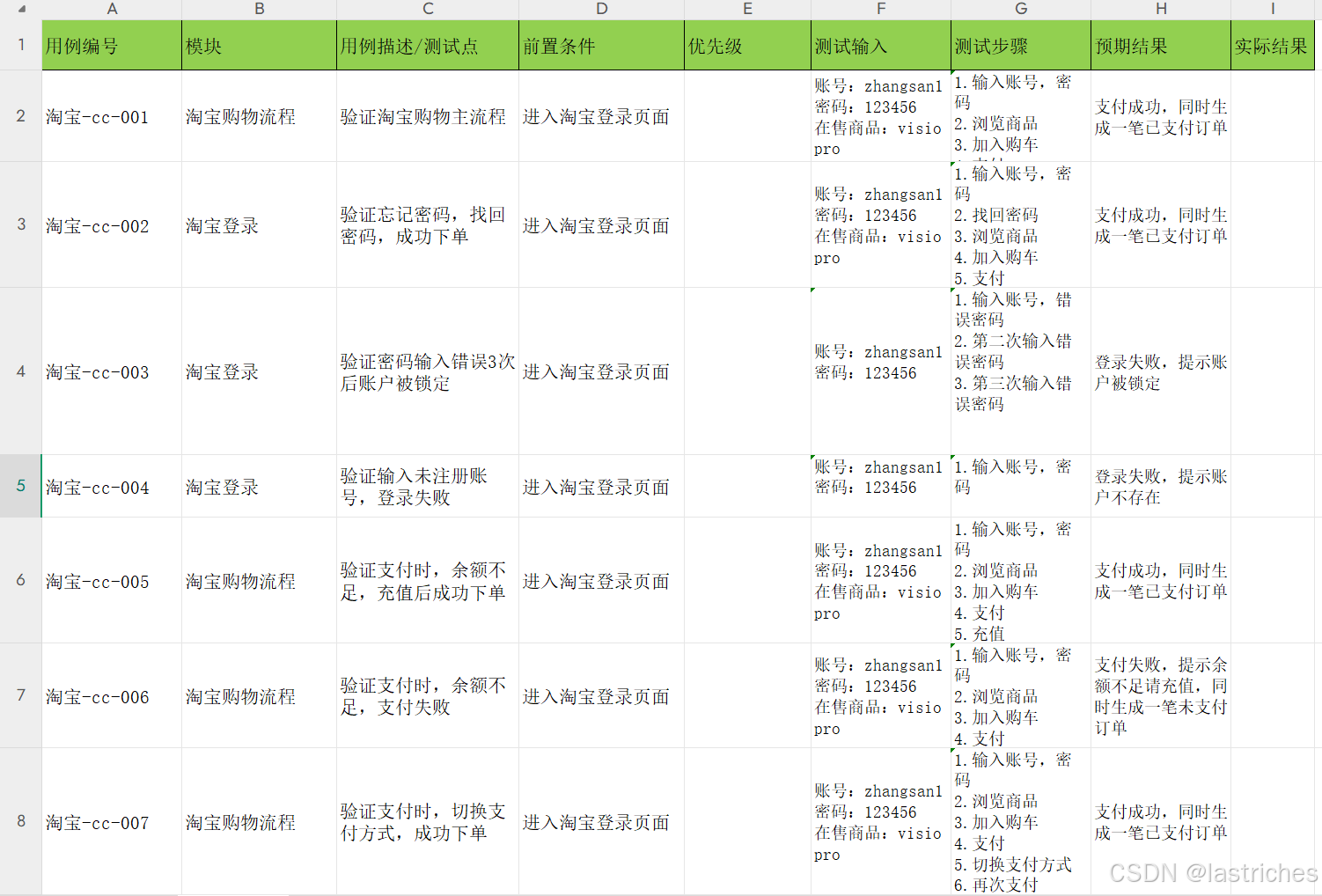
3. 设计测试用例与用例评审
测试用例
测试用例的定义:是为了验证软件是否符合需求而设计的一组由输入、执行条件、预期结果的文档
测试用例的编写流程:需求分析---提取测试点--编写测试用例--评审--修改
测试用例的作用:
- 验证软件是否满足需求
- 提高测试覆盖率,避免遗漏一些测试场景
- 测试人员工作内容的衡量
★测试用例要点:(编块描 前优入 步果 )
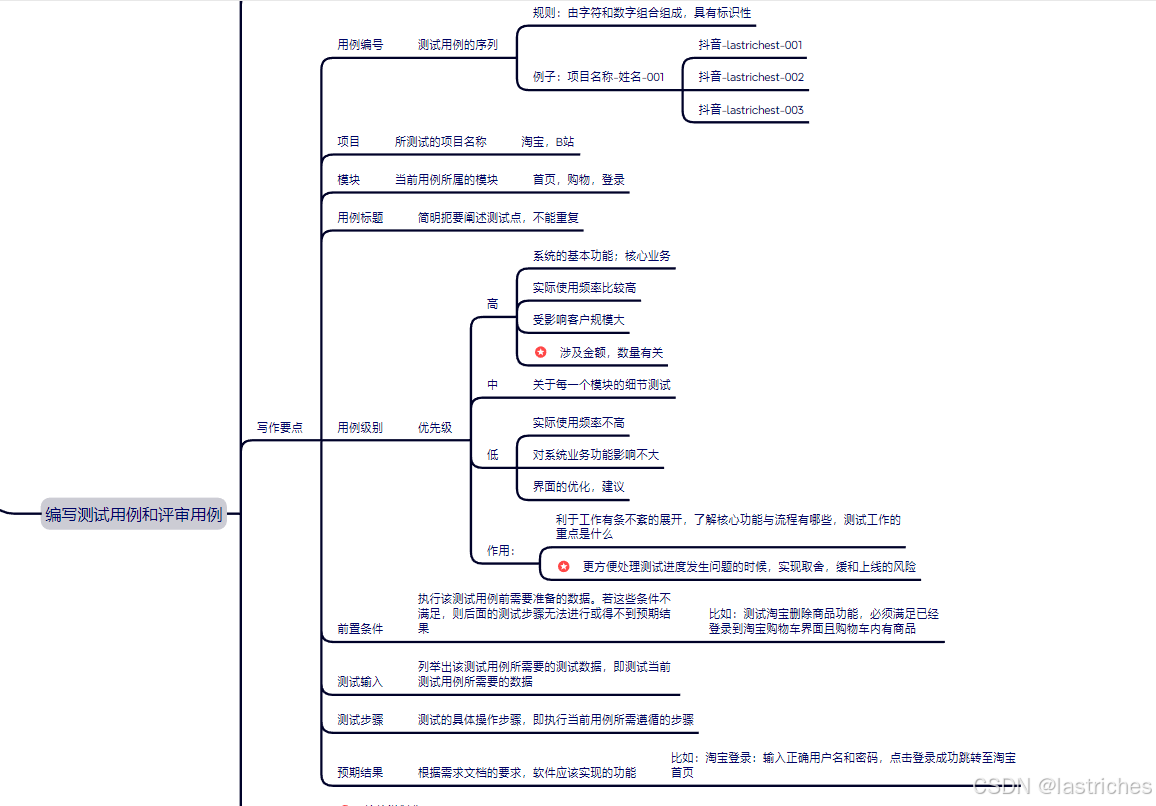
具体案例可参照博主:一文教你如何编写测试用例_测试用例八大要素-CSDN博客
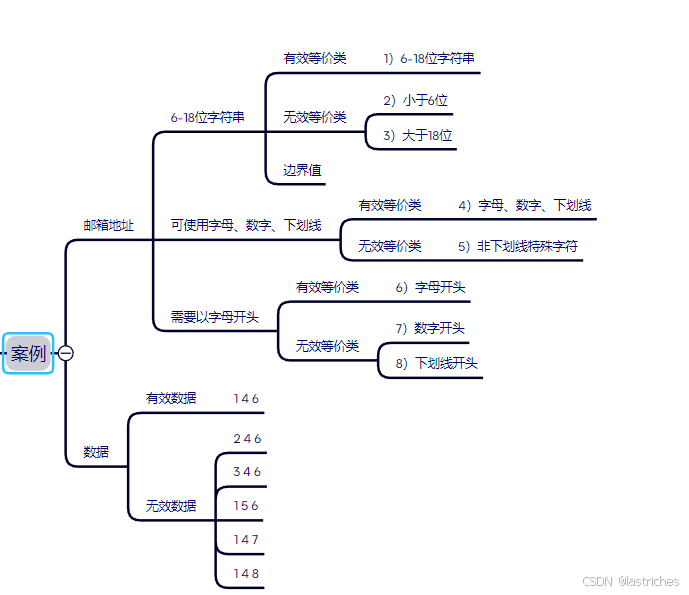
作业1:分别运用等价类划分、边界值分析法。针对邮箱地址编写测试数据

等价类划分:
作业2:依据场景法的定义给出ATM柜台取款的基本流和备选流

- 基本流:插卡-输入密码-查询余额-输入金额-输入密码-取款
- 备选流1:插卡无效
- 备选流2:输入密码错误
- 备选流3:输入密码错误次数过多,锁定账户
- 备选流4:输入金额大于账户余额
- 备选流5:输入金额大于当日限额
- 备选流6:输入金额不符合要求
作业3:针对禅道的登录功能设计一条测试用例,包含构成测试用例的八大必要元素
练习:针对登录功能编写两条测试用例,一条登录成功,一条登录失败!
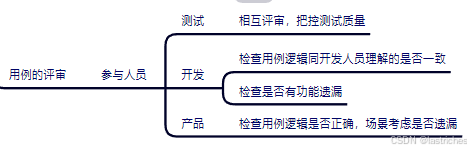
用例评审
参与人员:测试,开发,产品
冒烟测试
冒烟测试通过,则测试人员全面进入执行测试用例阶段
4. 执行测试用例
时间充足情况下:执行全部测试用例
时间不充足的情况下:按照优先级从高到低执行
5. BUG提交与管理
5.1 软件缺陷
5.1.1 软件缺陷的定义
软件缺陷又被叫为Bug,是软件或程序中存在某种破坏正常运行能力的问题,错误或者其他隐藏的功能缺陷。缺陷的存在会导致软件产品在某种程度上不能满足用户的需求。
5.1.2 软件缺陷的常见类型
- 功能,特性没有实现或部分实现
- 设计不合理,存在缺陷
- 数据不正确,精度不够
- 运行出错,系统报错、退出、界面混乱
- 用户不能接受的问题,查看时间过长,界面不美观,不易理解等
5.1.3 软件缺陷产生的原因
- 需求设计错误,如业务逻辑考虑不全面
- 系统架构设计不合理,如没有考虑多并发,数据库字段设计不合理
- 程序代码问题,如错误的算法,业务逻辑判断不准确
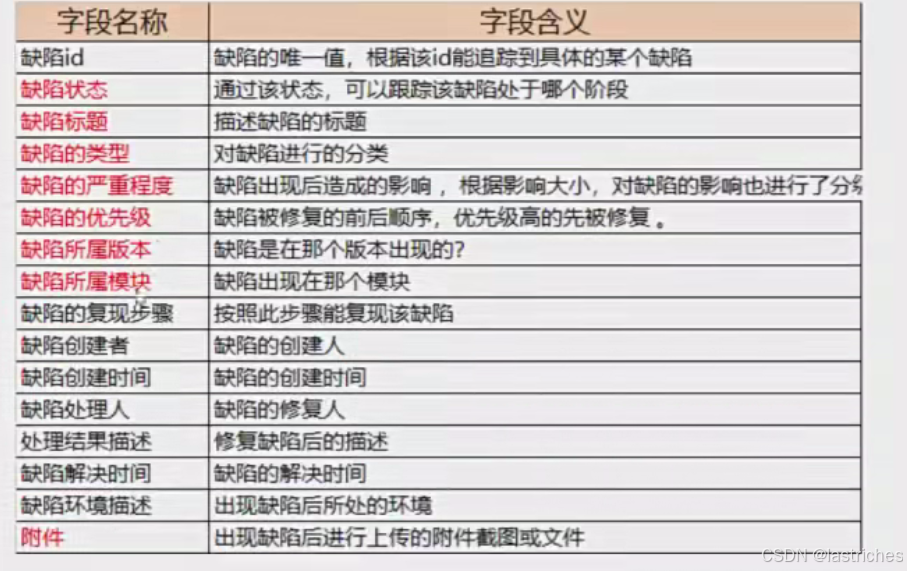
5.1.4 软件缺陷中包含的信息
软件缺陷的类型:
- 功能问题
- 界面UI问题
- 兼容性适配问题
- 易用性问题
- 性能问题
- 安全问题
缺陷的优先级:
- 紧急:立即修复,例如系统闪退
- 高:四小时内修复,例如支付功能异常
- 中:两天内修复
- 低:版本上线前修复或不修复
- 无关紧要:可以延期修复或者不修复
缺陷的严重程度:
- 致命:系统宕机,程序退出,核心功能不可用
- 严重:阻塞流程,主要功能不可用,数据错误,主要性能指标不达标
- 一般:不太严重的bug,次要功能不可用
- 提示:某些界面提示,例如密码规则提示
- 建议:用户体验、界面优化的建议型bug
可参照博主:软件缺陷主要包含哪些要素?_缺陷要素有哪些-CSDN博客
5.2 bug的整体流程
bug的整体流程:测试人员执行测试用例发现bug,提交bug,开发人员修复bug,测试人员回归测试,确认bug是否修复,选择关闭bug,或重新激活bug让研发继续修复
BUG描述总结:
难点:想要写出一个好的bug,其实最难的就是如何准确、简洁、完整的描述
解决方案:
- 1标题+1图片
- 1标题+1视频(难以复现的bug)
- bug描述的总结:所属模块+执行动作+出现现象
5.3 项目管理工具:禅道/JIRA
禅道的使用
使用步骤:
1. 创建用户
- 1. 创建用户
- 2. 设置权限
- 3. 自定义权限
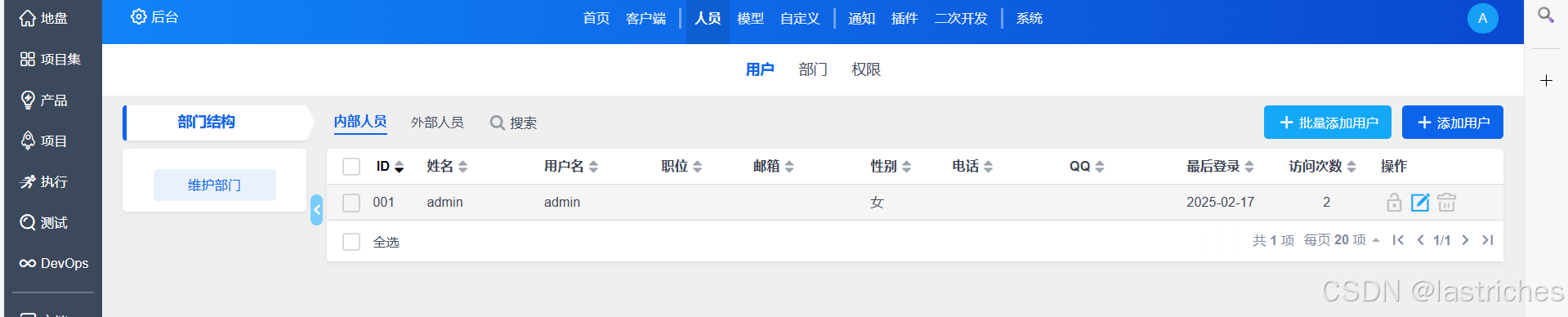
2. 基本流程
- 1.创建产品
- 2.创建项目
- 3.设置团队成员
- 4.创建版本
3. 测试人员使用 见TPshop实战项目
6. 编写测试报告

测试报告是指把测试过程和结果写成文档,对发现的问题和缺陷进行分析,为纠正软件存在的质量问题提供依据,同时为软件验收和交付打下基础。是测试阶段最后的产物
6.1 作用:
对测试来说:
- 测试结束的一个标志
- 形成一份可以参考的材料
- 对于整个测试过程或设计方法的一些改进建议
对整个项目和团队来说:
- 把关
- 预防
- 报告
- 改进
6.2 主要内容
测试过程和结果写成文档 发现的问题和缺陷进行分析 + 软件存在的风险说明 和 总结与改进建议
- 测试工作的过程与结果
- 风险说明
- 缺陷汇总与分析
- 测试工作的总结与改进
----阶段二:数据库和Linux------
MySQL数据库
1. 简介
网课教程:【合集】数据库原理及应用 东南大学 徐立臻 共72讲_哔哩哔哩_bilibili
具体可查看博主:十万字数据库笔记_设计表每个人设计一张表,至少具有四个属性,并列举这个关系当中的所有候选码-CSDN博客
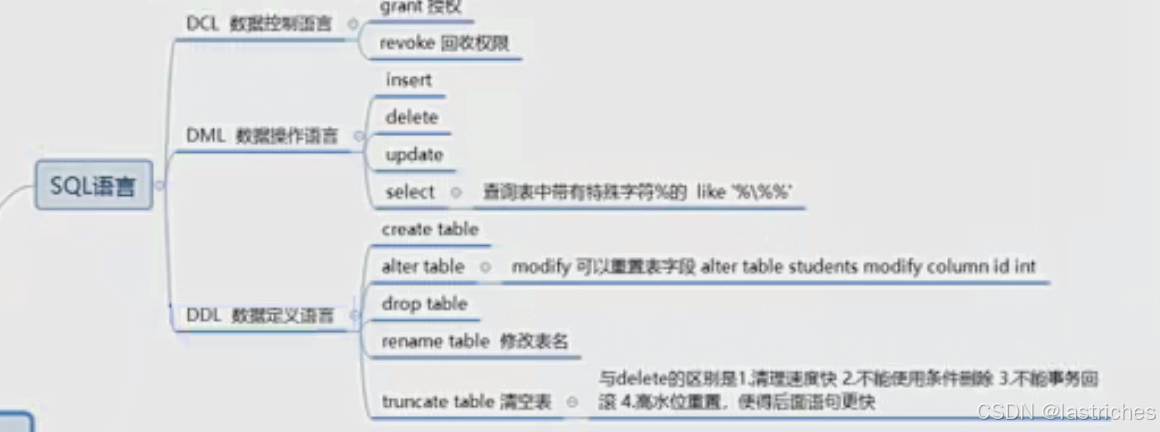
SQL 语言
Structured Query Language:结构化查询语言
SQL 是一门特殊的语言,专门用来操作关系型数据库,当前关系型数据库都支持使用 SQL 语言进行操作,也就是说可以通过SQL语言操作 oracle、mysql、sqlserver、sqlite 等所有的关系型数据库。
SQL 语言主要分为:
- DQL: 数据查询语言, 用于对数据进行查询, 如 select;
- DDL: 数据定义语言, 进行数据库、 表的管理等, 如 create、 drop;
- DML: 数据操作语言, 对数据进行增、 删、 改, 如: insert,update,delete;
- DCL(Data Control Language):数据控制语言,例如:授权grant、销权限revoke....
- TPL: 事务处理语言, 对事务进行处理, 包括 begin transaction, commit, rollback;
对于测试工程师来讲, 重点是数据的查询, 需要熟练编写 DQL,掌握 DDL,DML即可;
SQL 语言不区分大小写。每句结束用 ; 隔开
2. 安装与环境搭建
2.1 MySQL安装
2.1.1 软件安装
方式1:官网安装:MySQL :: Download MySQL Community Server
安装参考博主:Mysql超详细安装配置教程(保姆级)_mysql安装及配置超详细教程-CSDN博客
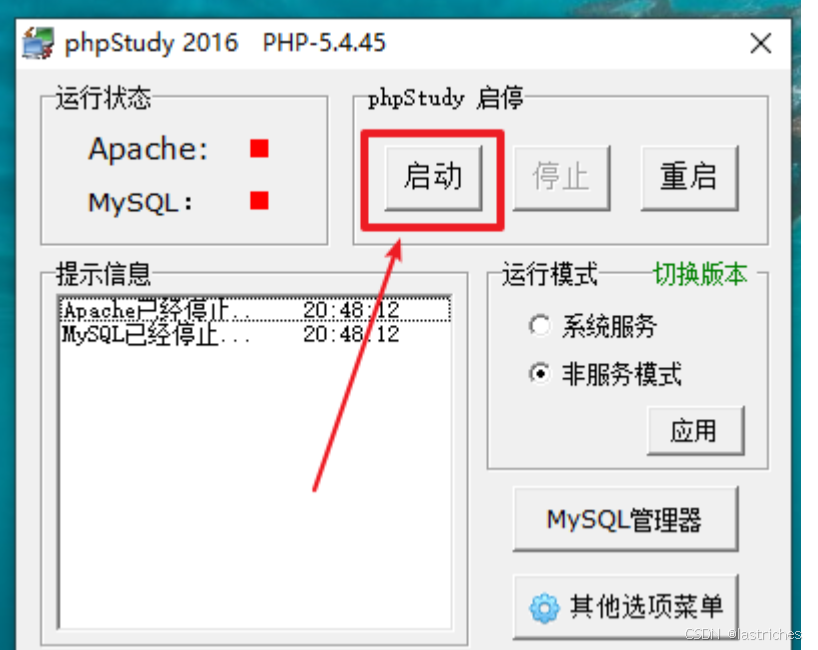
方式2:使用phpstudy集成环境
1. 下载phpstudy,如我这里选择的是:phpStudy20161103.zip
2. 解压phpstudy,进行目录安装phpStudy20161103.exe
3. 双击phpstudy的快捷方式启动mysql的服务
2.1.2 配置环境变量
配置环境变量的作用
实现在CMD的任意目录下,都可以很方便地启动某一个软件。
如果不配置环境变量,需要每次都在cmd命令中切换到mysql安装路径下的bin文件目录下才能调用mysql命令。
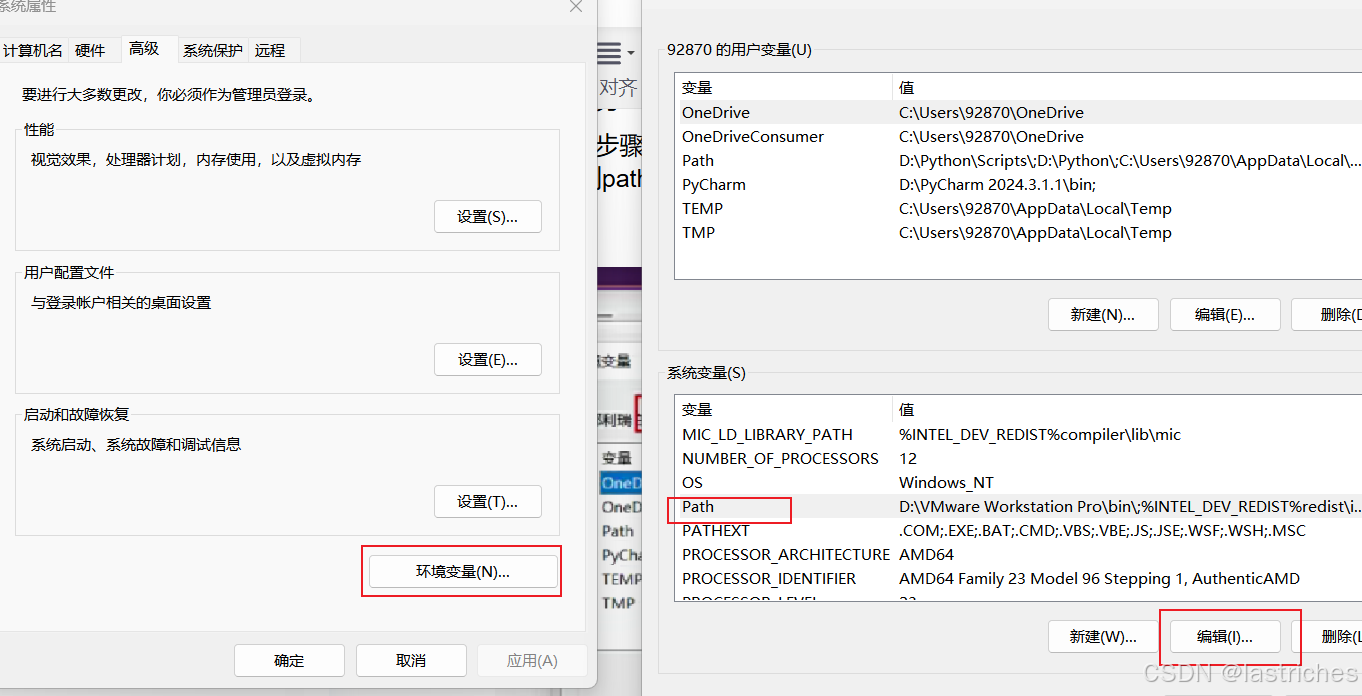
步骤:
- 1. 打开phpstudy服务
- 2. 添加环境变量,步骤:右键"计算机"--选择"属性”---选择高级系统设置---选择“环境变量’…-在'系统变量’中找到path变量:-…点击“编辑'【双击path变量】--在变量值后输入mysql的bin文件路径
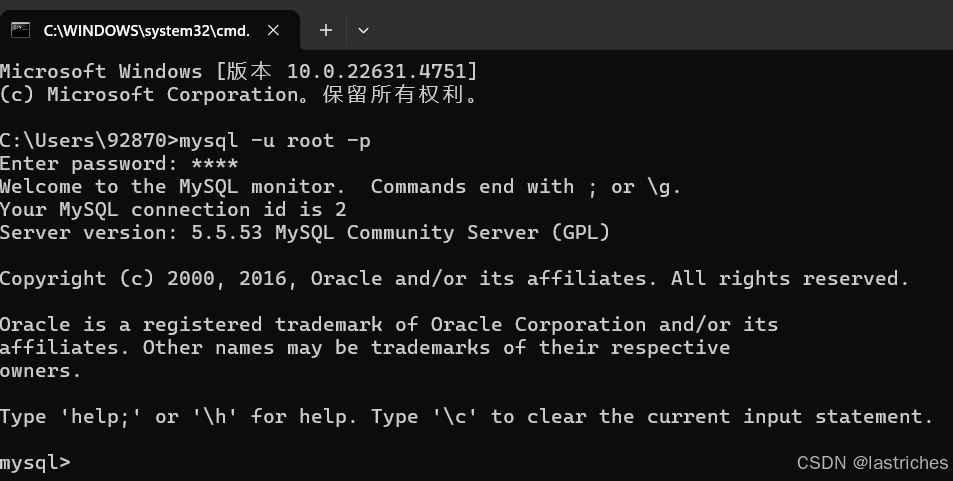
查看效果
cmd命令窗口输入mysql -u(以什么方式登录) root -p(用密码验证)
phpstudy默认账号/密码 root/root
2.2 Navicat安装
Navicat是一款功能强大的数据库管理工具,可用于管理多种类型的数据库,提供了简洁直观的用户界面,易于理解和操作。
安装可参考博主:Mysql工具之Navicat16安装教程(超简单保姆级教程)-CSDN博客
3. Navicat的使用
3.1 连接数据库
1. 打开Navicat,点击连接,点击MySQL。
2. 输入连接数据库的信息
- 连接名:给数据库连接起的名字,一般起一个有语义的名字
- 主机名或IP地址:数据库所在IP地址
- 端口:数据库的端口号,MySQL默认端口号为3306
- 用户名:数据库的用户名
- 密码:数据库的密码
3. 输入连接信息,先点击连接测试,然后再点击确定。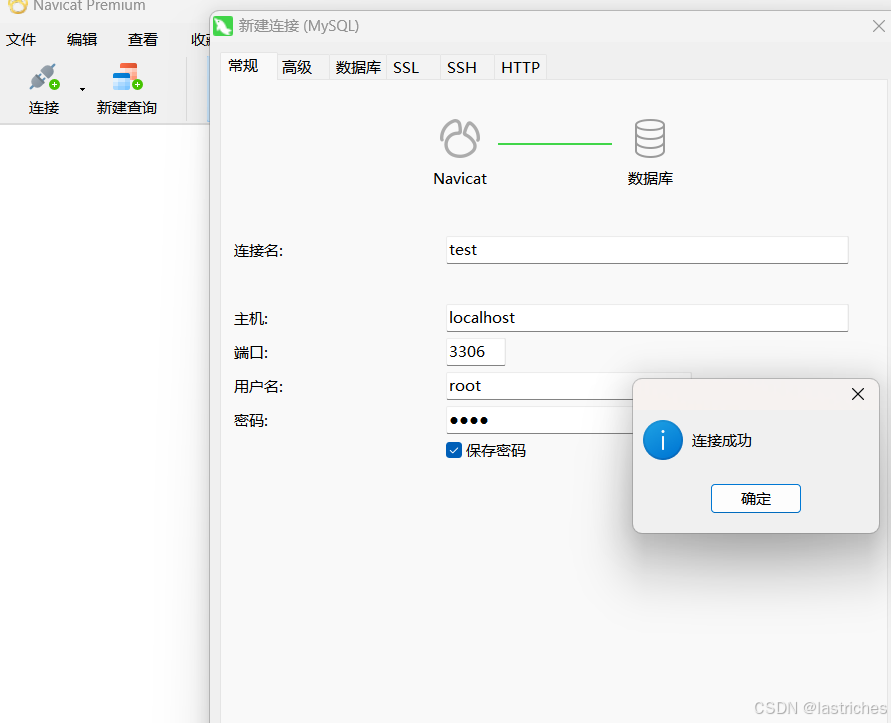
3.2 数据库操作
- 新建数据库
1. 右击数据库名,点击“新建数据库”
2. 输入数据库名,字符集选择utf8 --UTF-8 Unicode ,排序规则utf8_general_ci .点击确定
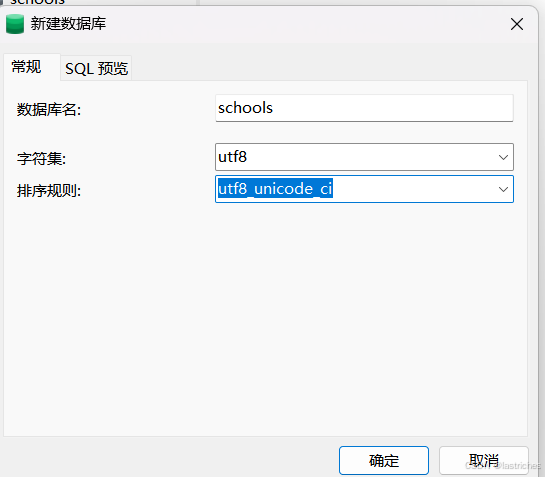
- 删除数据库
- 打开数据库
只有打开数据库才能对数据库中的表进行操作
3.3 表的操作
- 新建表:在某一个数据库下选中表右键,点击“新建表”
- 修改表:选中其中的某一张表,点击“设计表”
- 删除表:选中其中的某一张表,点击“删除表”
- 查询表:双击打开某一张表可查看表中数据
3.4 常用数据类型
- 整型 int 有符号范围(-2147483648 ,2147483647);无符号int unsigned范围(0 ,4294967295)
- 小整数:tinyint 有符号范围(-128,127);无符号tinyint unsigned(0,255)
- 小数:decimal 如 decimal(5,2)表示共存 5 位数,小数占 2 位,不能超过 2 位;整数占 3 位,不
- 能超过三位;
- 字符串:varchar 如varchar(3)表示最多3位字符
- 日期时间: datetime 范围(1000-01-01 00:00:00 ~ 9999-12-31 23:59:59),如 '2020-01-01
- 12:29:59'。
具体可参照博主:数据库基础类型详解-CSDN博客
3.5 编写SQL
1. 选中某一个数据库,点击查询按钮
2. 在弹出的界面中,点击“新建查询”
3. 在打开的编辑器窗口中输入SQL语句,点击运行
4. 运行第一个SQL语句,输入select now();显示系统当前日期
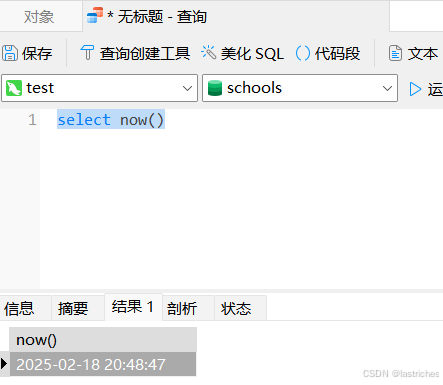
4 SQL概述
4.1 注释
- 单行注释:-- 注释内容
-- sql语句 #中间需要有空格- 多行注释:/*注释内容*/
/*
这是一个多行注释的例子
*/4.2 数据库操作
- 创建库 create database 数据库名
- 删除库 drop database 数据库名
- 使用库 use 数据库名
4.3 表的操作
- 创建表
create table 表名(
列名1 数据类型(长度),
列名2 数据类型(长度)
)
- 删除表
drop table 表名 /delete/truncate
4.4 数据的操作
- insert插入
insert into 表名(字段1, ...) values(值1, ...)
- select查询
select 字段1,... from 表名
select 字段1 as 别名1, 字段2, ... from 表名 as 别名
- update修改数据
update 表名 set 字段1=值1 , 字段2=值2....[where 条件]
- delete删除,支持条件删除记录
delete from 表名 where 条件
- truncate删除,速度快但只能删除整个表
truncate table 表名
4.5 字段的约束
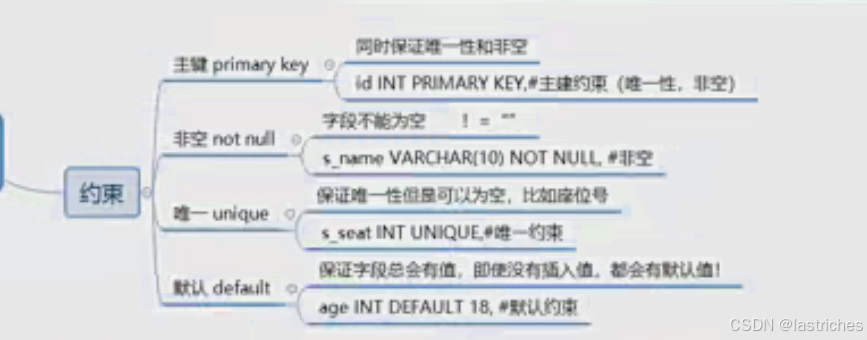
- 主键: primary key
- 非空:not null 注:not null !=空,指的是不可以插入null值,但是可以插入空值
- 唯一:unique
- 默认值:default
具体可参照博主:数据库—— MySQL数据库字段约束_mysql 字段约束-CSDN博客
★★4.6 条件查询 where子句
语法:select * from 表名 where 条件;
使用where子句对表中的数据进行筛选,符合条件的数据会出现在结果集中
- 说明1:条件支持> , >= , < , <= , !=
- 说明2: 条件支持or或,and和
- 说明3: 条件支持not非;not只有一个条件:not 条件
- 说明4:条件支持模糊查询like: %表示任意多个字符;_表示一个任意字符
案例:查询name以李开头的老师数据
select * from teachers where name like "李%"
- 说明5:条件支持查询范围 in:表示一个非连续的范围内;between... and...: 表示在一个连续的范围内
select * from students where city in('北京',‘上海’);
select age from students where age between 20 and 30;
- 说明6:条件支持空/非空判断 is null ;is not null
4.7 排序 order by
数据可以按照某个字段进行排序,方便查看
默认按照字段值从小到大排序
- asc(默认)从小到大排序,即升序
- desc从大到小排序,即降序
select * from 表名 order by 字段1 asc|desc, 字段2 asc|desc....
★4.8 聚合函数
目的是快速得到统计后的数据
注意:不能放到where后面使用
- count:总记录数 count(字段)
- max: 求此字段的最大值,用于整型 max(字段)
- min: 求此字段的最小值
- sum: 表示此字段的和 sum(字段)
- avg: 表示此字段的平均值 avg(字段)
4.9 数据分组
定义:按照字段分组,跟此字段相同的数据会存放在一个组中
目的:配合聚合函数,对每一组数据进行统计
select 字段1,字段2,聚合函数..... from 表名 group by 字段1,字段2....
案例:查询各种性别的人数
select sex,count(*) as 人数 from students group by sex
4.9.1 分组后的数据筛选
语法:select 字段1,字段2,聚合函数..... from 表名 group by 字段1,字段2....
having 字段1,....聚合.... [ having 后面的条件运算符与where一致]
案例: 分别使用where 和having 子句查询男生总人数
select sex, count(*) from students where sex='男生'
select sex, count(*) from students group by sex having sex='男生'
补充:where 和 having的区别
- where是对from后面指定的表进行数据筛选,属于对原始数据整张表的筛选
- ★having是对group by分组后的结果进行筛选
- having后面可以用聚合函数,where后面不可以用聚合函数
案例:
查询班级人数大于1的班级及总人数
select class,count(*) from students group by class having count(*)>1
查询班级中女生人数大于等于1的班级及总人数
表 students 查询目标 class count(*) 条件 sex='女' and count(*)>1
SELECT class,COUNT(*) FROM students
GROUP BY class,sex
having sex='女' and count(*)>=1
4.10 数据分页
4.10.1 获取部分行的数据
当数据量过大时,往往可以只查询部分数据即可
limit:
获取前n行 select * from students limit n
获取第m行开始的n行 select * from students limit m,n; limit start,count
4.10.2 分页
当一张表数据过多时,可以分页展示

★5. 连接查询
5.1 概念
当查询结果来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的结果返回
连接查询可以通过连接运算符(连接条件)实现多个表查询
5.2 内连接
查询结果只显示两个表中满足连接条件的部分
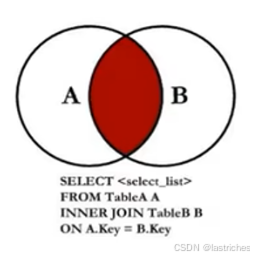
语法1:
select * from 表1 inner join 表2 on 表1.字段 = 表2.字段
语法2:
select * from 表1 , 表2 where 表1.字段 = 表2.字段
5.3 左连接
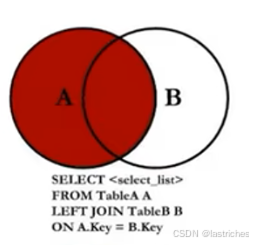
两个表在连接过程中除了返回满足连接条件的行以外还返回左表中不满足条件的行,这种连接称为左外连接。即查询的结果为两个表匹配到的数据加左表特有的数据,对于右边中不存在的数据置null
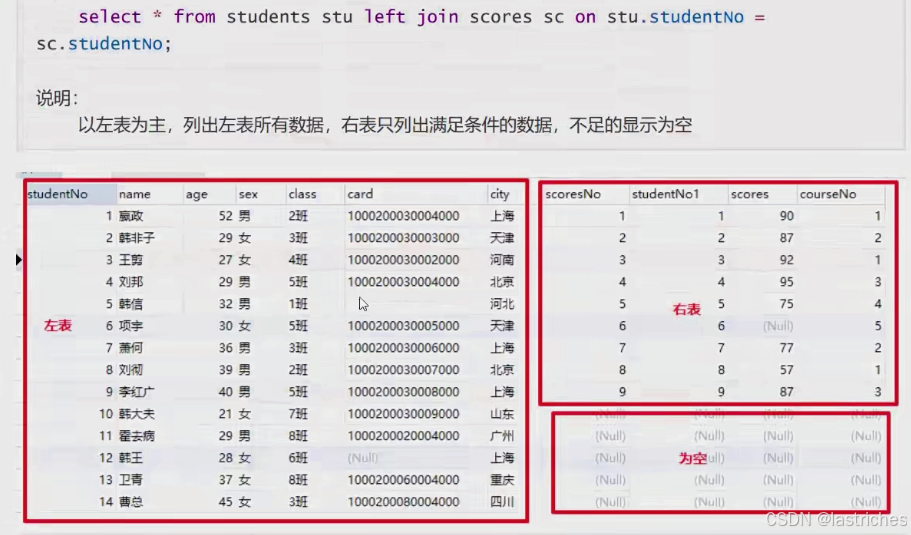
语法:
select * from 表1 left join 表2 on 表1.字段 = 表2.字段
5.4 右连接
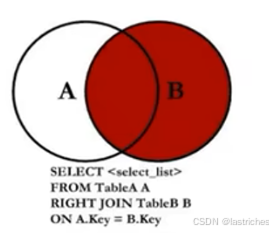
两个表在连接过程中除了返回满足连接条件的行以外还返回右表中不满足条件的行,这种连接称为右外连接。即查询的结果为两个表匹配到的数据加右边特有的数据,对于左表中不存在的数据使用null
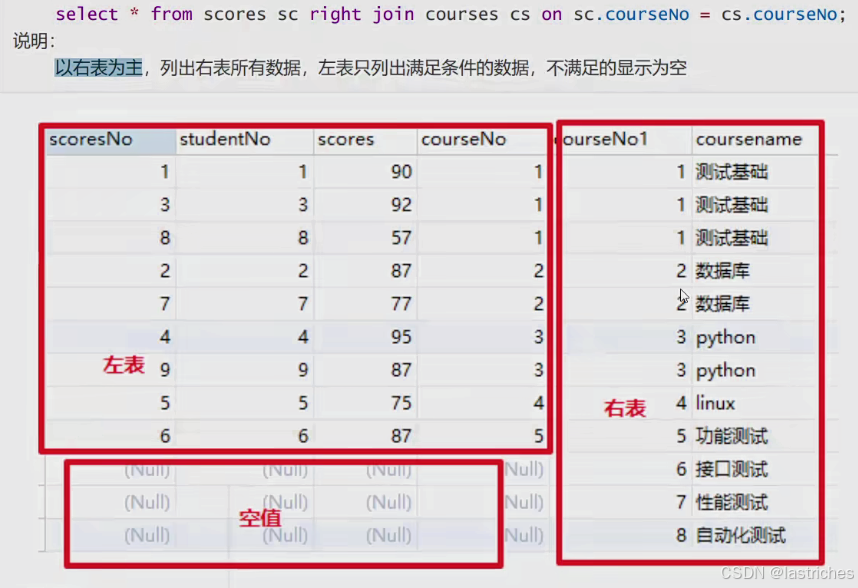
语法:
select * from 表1 right join 表2 on 表1.字段 = 表2.字段
具体可参照博主:SQL数据查询——连接查询_sql连接查询-CSDN博客
★6. 子查询
SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。
6.1 定义
在一个select语句中嵌入了另外一个select语句,那么被嵌入的select语句称之为子查询语句
注:外层select称为主查询,内层select称为子查询
6.2 主查询和子查询的关系
- 子查询是嵌入主查询中的
- 子查询辅助主查询,充当条件或数据源
- 子查询是可以独立存在的语句,是一条完整的select语句
案例:# 查询工资大于149号员工工资的员工的信息
实现思路:
- 1:查询149号员工工资 SELECT salary FROM employees WHERE employee_id=149
- 2: 查询大于第一步获得条件的结果 SELECT employee_id,last_name,salary FROM employees WHERE salary>(1)
SELECT employee_id,last_name,salary FROM employees
WHERE salary>(
SELECT salary FROM employees
WHERE employee_id=149); //子查询充当条件
案例:#查询29岁学生的成绩
实现思路:
- 1:查询出29岁的学生学号:select studentNo from student where age = 29
- 2:根据学号查询出成绩:select score from scores where studentNo in (1)
select score from scores
where studentNo in (
select studentNo from student
where age = 29);
具体可参照博主:SQL子查询详解:使用、分类及实例解析-CSDN博客
7. 内置函数
字符串函数
拼接字符串:concat(str1, str2.....)
查询字符串:length(str) 查询字符个数 select * from student where length(name)=9 注utf-8中汉字一个占3位
截取字符串:注:中英文都只占一位
- 从左边截取:left(str,len) 返回字符串str左端len个
- 从右边截取:right(str,len) 返回字符串str右端len个
- 从中间截取:substring(str,pos,len) 返回字符串str从位置pos起len个
- select left(name,1) from students //返回姓
取出空格:
- 返回删除左右两侧空格的字符串: trim(str)
- 取出左边空格:ltrim(str)
- 去除右边空格:rtrim(str)
数学函数
四舍五入:round(n, d) :n表示原数,d表示小数位置,默认为0
select round(avg(age)) from students //对学生的平均年龄四舍五入
随机数:rand (),随机返回0-1.0的浮点数
时间函数
当前日期:current_date()
当前时间:current_time()
当前日期时间:now()
8. SQL练习平台
Linux系统
1. 安装Linux系统(虚拟机)
准备如下资源文件:
具体过程可查看博主:VMware虚拟机安装Linux教程(超详细)_vmware安装linux虚拟机-CSDN博客
语言设置
- 1. 打开设置Setting
- 2. 进入语言选项,跳转界面语言
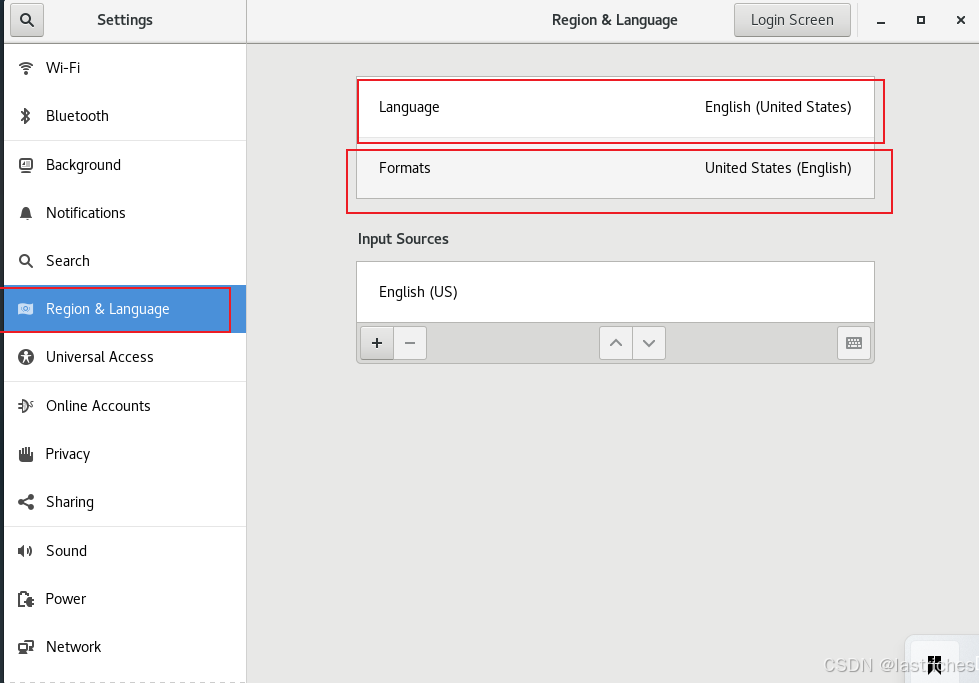
2. Linux和xshell的使用
xshell是一款功能强大的SSH(Secure Shell)客户端工具,它主要用于远程连接和管理Linux或Unix服务器。xshell提供了一个安全的终端窗口,用户可以通过网络连接到远程服务器,并执行命令、编辑文件、传输文件等操作。它在Windows平台上运行,并为用户提供了一个用户友好的界面和丰富的功能,使得远程服务器管理变得更加便捷和高效。
具体介绍可查看博主:xshell是用来干嘛的(非常详细),零基础入门到精通,看这一篇就够了-CSDN博客
2.1 xshell的使用:
前期准备
# ifconfig 命令 查看设备网络信息或设置
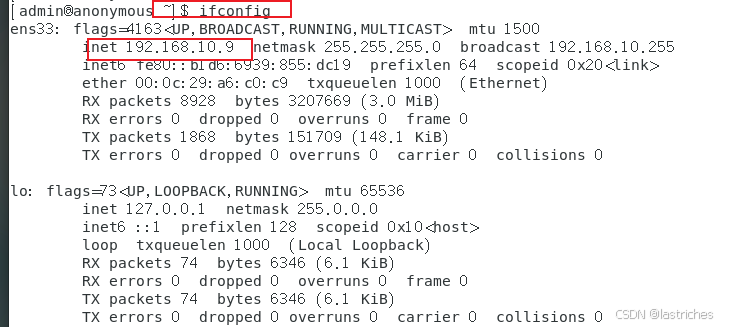
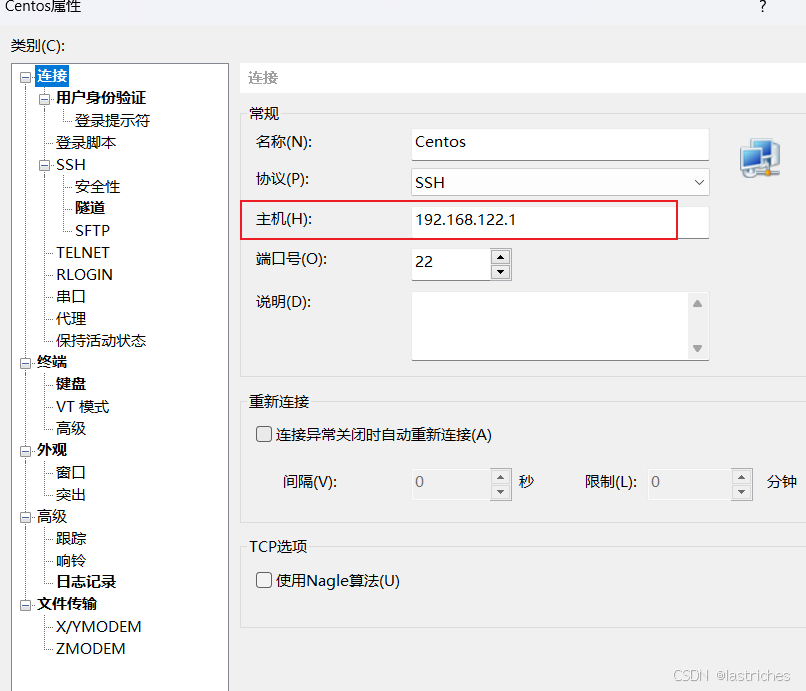
xshell建立连接
3. Linux操作系统
想深入了解可参考博主:❤️肝下25万字的《决战Linux到精通》笔记,你的Linux水平将从入门到入魔❤️【建议收藏】_linux笔记 小小明-CSDN博客
简单来说,Linux是一个操作系统,类似Windows。用于控制和管理计算机硬件和软件资源一个程序。为使用计算机的用户提供了可交互的操作界面。因为其稳定性、安全性等因素,因而服务器领域主要使用Linux系统
3.1 主要目录介绍
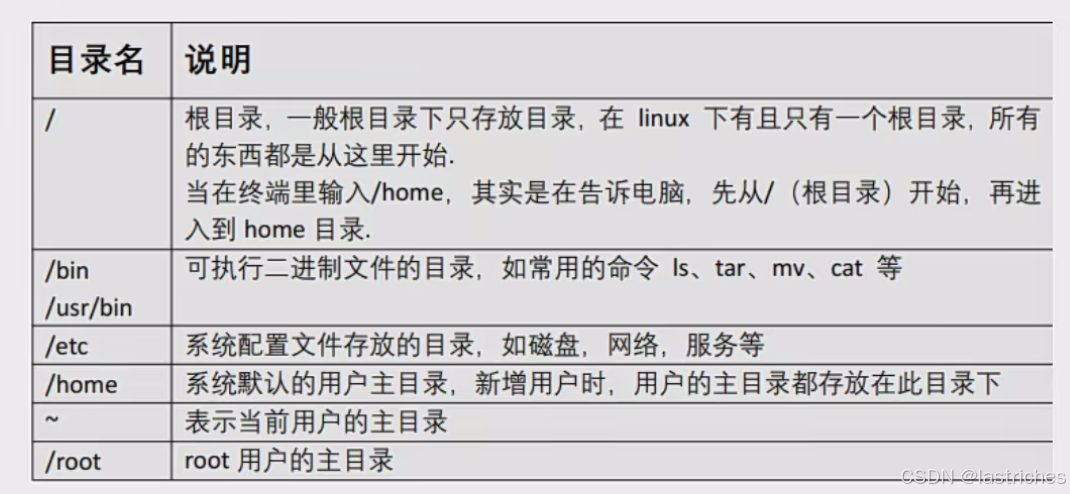
3.2 命令
详情可参考:Linux面试必备20个常用命令(文末免费下载Linux命令大全工具)_linux常用命令-CSDN博客
基本常用命令
- ls: list 查看当前文件夹的内容
- cd: change directory 切换文件夹
cd ../返回上一级 父子级可以直接切因为不会有重名,越级切换要逐次编写命令
- touch 文件名: 创建文件
- mkdir 目录名(目录即文件夹):make directory 创建目录
- rm 文件名:remove 删除文件
- rm -r 目录名:remove 删除目录
查询历史命令:
- 按上、下键可在曾使用过的命令中切换
- 退出不想执行当前选择的命令,按ctrl+c
自动补全:
- 在敲出文件/目录/命令前几个字母之后,按tab键位。当输入没有歧义时,系统会自动补全名称。
- 若还存在其他可选文件,再按tab系统会显示可支持补全的文件
帮助命令:
- help: 查看命令的帮助信息 比如 ls --help
- man: 查看命令的帮助手册 比如 man ls
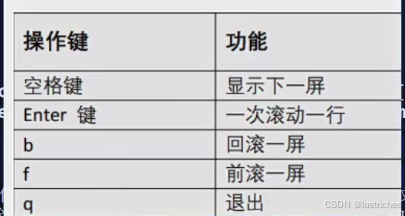
3.3 进阶命令
查看目录内容和切换目录(目录,即文件夹)pwd ls
- pwd: 查看当前所在目录
- ls: 查看目录内容(文件夹内部有什么)
语法: ls [-lah] [文件/目录]
常用选项 [-lah]
-a :显示指定目录下的所有子目录与文件,包括隐藏文件
-l: 以列表的方式显示文件的详情 等于命令 ll
-h: 配合-l 以人性化的方式显示文件大小
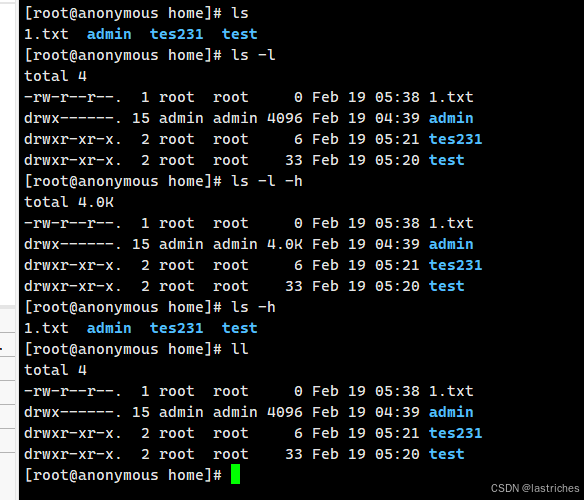
注:Linux中文件和目录的特点
- 所有文件和目录、命令都对大小写敏感
- 以 . 开头的文件为隐藏文件
- . 代表当前目录
- .. 代表上一级目录
文件描述编码说明
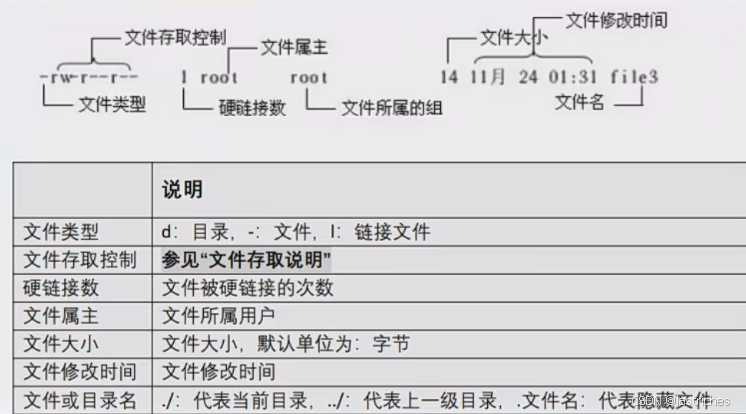
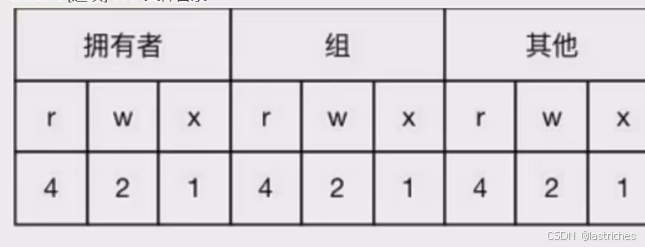
文件存取说明:
字符依次含义: 拥有者:本人;组:所在组的其余人;其他用户:组外其余人
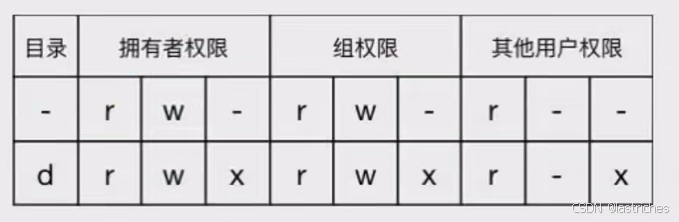
注:rwx的含义:
- r: read 读 对文件查看该源文件内容,对目录有查看的权限
- w: write 写 对该源文件进行编辑,可以移动、新建、修改、删除该目录中的内容。
- x: excute 执行 执行/运行:运行该文件和目录
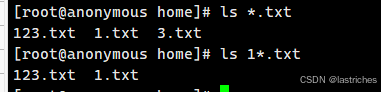
命令行通配符
- * 表示匹配任意长度的任意字符
- ? 表示匹配任意一个字符
- [ ] 表示匹配[ ]内的任意单个字符 | [abc]: 匹配a , b , c 中的任意一个字符 | [a-f]: 匹配从a到f范围内的任意一个字符
- [^] 表示匹配[ ]外的任意单个字符 |
使用示例:
搭配ls命令
ls *.txt
ls ?.txt
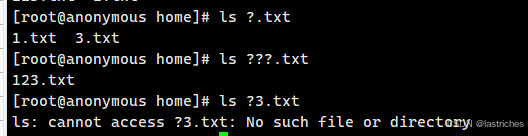
ls [].txt
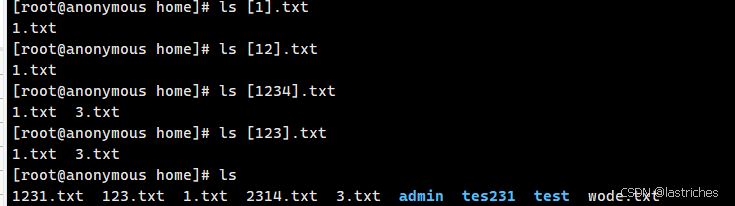
ls [^].txt

修改目录和文件的权限 chmod
语法:change mode 修改用户和组对目录和文件的权限
chmod [选项] 权限 文件目录
- 字母法修改权限

语法:
chmod [u/g/o/a] [+/-/=] rwx 文件/目录
u: user文件所有者 g: group文件所属组 o:other表示u和g以外的用户 a: all同时设定以上三组
+:增加权限 ; - :取消权限;=:设定权限
例如:chmod u+rwx,g+r-w,o-x 文件/目录
- 数字法修改权限
语法:
chmod [选项] 777 文件/目录
选项参数
-r: 修改目录权限时需指定的参数
7 7 7:为各组权限值相加:
注:无权限值置为0
例如:777-->拥有者,组,其他有rwx权限;644:-->拥有者rw, 组r, 其他r
不清楚可以查看博主:chmod 777 到底是啥 ???看完这个你就完全懂了!-CSDN博客
切换目录指令进阶 cd
基础:
- cd 目录名:进入指定目录
- cd : 切换到当前用户的主目录(/home/用户目录)
进阶:
- cd ~ : 切换到当前用户的主目录,同cd
- cd .. : 切换到上级目录
- cd / :切换到根目录
相对路径和绝对路径:不同操作系统使用的斜杠不同(Linux系统是/, window系统是\, 知道即可)
相对路径:从一个目录为起点到另外一个的目录的路径,表示相对于当前目录所在的目录位置
绝对路径:总是从根目录开始的路径,表示从根目录为起点到某一个目录的路径;
文件操作 touch/mkdir/rm/cp/mv/cat/tail/grep
创建文件----touch
语法:touch 文件名
- 如果文件不存在,将创建一个空文件
- 若文件存在,只会修改文件末次修改日期
创建目录----mkdir命令
语法:mkdir [选项] 目录
- 若目录不存在,将创建一个空目录
- 若目录已存在,则会出现报错提示
选项参数:
- -p 递归创建多个目录层级 mkdir -p a1/b2
- -m 用于手动配置所创建目录的权限 mkdir -m 777 test
具体可参考:Linux常用命令----mkdir命令_mkdir -p-CSDN博客
删除文件或目录----rm命令
注意:文件删除后不能恢复
语法:rm [选项] 文件/目录
选项:
- -f:强制删除,忽略不存在的文件,不需提示
- -r:删除目录是需指定的参数
复制文件----cp指令
语法:cp [选项] 源文件 目标文件
cp -r dir1 dir2 #拷贝dir1目录到dir2
- 针对文本文件,若目标文件不存在的话,系统会直接新建一个指定名称的文件用于复制
- 针对文本文件,若目标文件存在内容的话,系统会提示是否覆盖目标文件的内容
- 针对目录,若目标目录不存在的话,系统会直接新建一个指定名称的目录用于复制源目录下的子文件/子目录
- 针对目录,若目标目录存在的话,系统会将源文件整体移动过来。
- 只有当目标目录中文本文件与源文件文本文件有重合时,系统才会提示是否覆盖
选项参数:
- -r: 复制目录时需加上此参数
- -f: 再覆盖目标文件之前给出提示让用户确认
移动文件/目录----mv指令
移动文件或目录,也可以用来给文件和目录重命名
语法:mv [选项] 源文件 目标文件
移动之后,源文件自动删除。借此可以将目标文件指定为不存在的用来重命名的名称实现重命名
选项参数:
- -i: 在覆盖目标文件之前将给出提示要求用户确认(一般不加)
查看文件内容----cat指令
语法:cat [选项] 文件
选项参数:
- -n: 对输出的所有行进行编号
- -b: 对输出的非空行进行编号
示例:查看操作系统信息 cat /proc/version
分页查看----more命令
分屏显示文件内容,一页一页地看
语法: more 文件
★查看文本内容----tail命令
通常情况下,tail 命令用于实时查看日志文件,可以使用 -f 参数跟踪文件内容的变化
语法:tail [选项] [文件]
选项参数:
- -f: 循环次数
- -n<行数>: 显示文件尾部的n行内容 想看几行n赋值为几
示例:tail -f access.log 实时查看日志信息
过滤查看----grep
用于根据给定的规则搜索文本,并将匹配的行打印出来。
语法:grep [选项] '规则' 文件
选项参数:
- -v: 反转规则查找
- -n: 对输出的所有行进行编号
- -i: 忽略大小写
规则:
- "xxx": 返回包含内容xxx的行
- ^a: 匹配所有以a开头的行
- $a: 匹配所以以a结尾的行
- *c: 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p
- *a: 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行
- 可组合使用
具体可参照博主:Linux 系统 grep 命令超详细讲解_grep命令详解-CSDN博客
3.4 补充指令
- 清屏:clear
- 打印:echo 在终端中打印出指明的内容
- 重定向符:> 输出重定向:将命令的执行结果输出到一个文件中
语法:
命令 >文件名 将内容覆盖文件原有的内容
命令 >> 文件名 把内容追加到原有文件的末尾
- 管道符号:| 用于将一个命令的输出作为另一个命令的输入
示例:命令 | grep '规则' yum list | grep -n java-17-openjdk-portable*
- 查找文件: find 在指定的目录下搜索满足条件的文件
语法:find [路径] -name 文件名
在当前目录中,可省去指定路径
- 查找程序:which 查找linux命令所在的位置
- 压缩解压:gzip/zip/unzip/tar
gzip: 压缩与解压
语法:生产.gz文件
# 压缩文件 gzip 文件名 压缩后源文件会自动被删除
# 解压文件 gzip -d 文件名 解压后源文件会被自动删除
# 压缩文件夹(压缩的是该文件夹下的子文件):gzip -r 目录 压缩后会在该目录下生产一个压缩包
# 解压文件夹(解压的是该文件夹下的压缩文件): gzip -rd 目录
zip/unzip 解压缩
语法:生成.zip文件
#压缩文件 zip 压缩文件.zip 源文件
#压缩目录 zip -r 压缩文件.zip 源目录
#解压文件 unzip 压缩文件.zip
#解压目录 unzip 压缩文件夹.zip
- 打包文件:tar 将多个文件或目录打包成一个文件
具体可查询博主:Linux 打包命令 tar 详解_linux tar-CSDN博客
3.5 系统相关信息
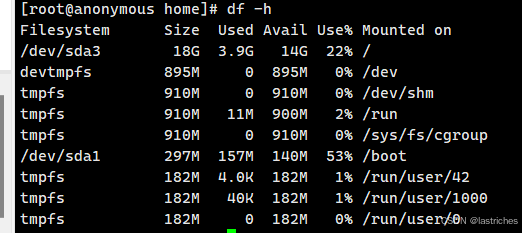
查看磁盘情况----df命令
语法: df [选项]
选项参数 :
-h: 以人性化方式显示文件大小
查看文件大小--du命令
语法:du [选项]
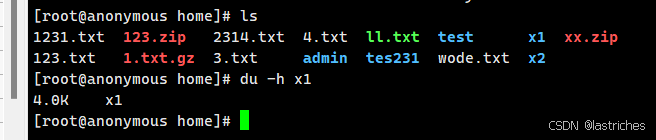
查看进程----ps命令
用来查看当前进程的信息
语法:ps [选项]
选项参数:
- -a: 显示终端上所有运行,包括其他用户的进程
- -u: 显示进程的详细状态
- -x: 显示没有控制终端的进程
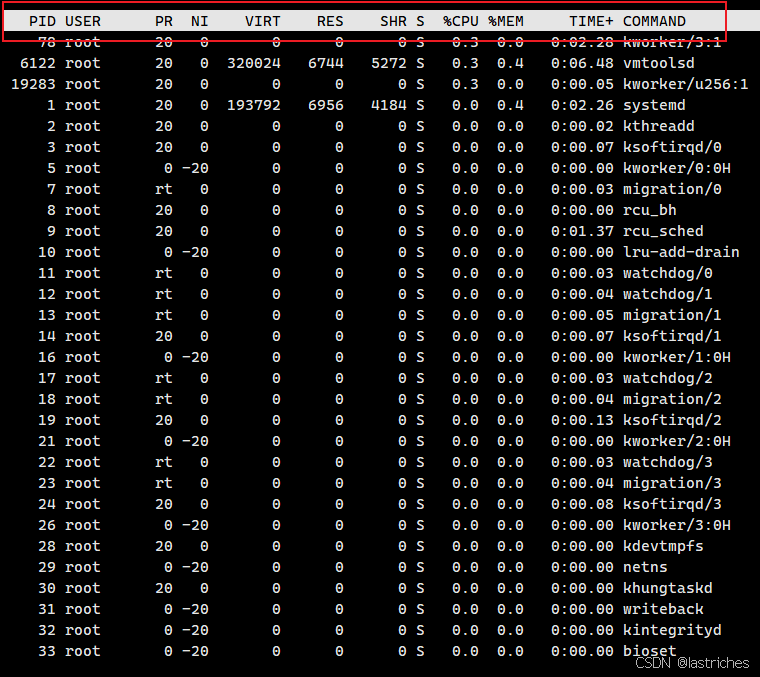
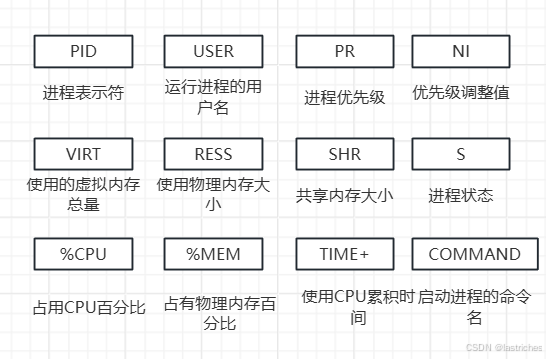
查看进程的运行状态----top命令
语法:top [选项] 类似windos的任务管理器,是动态展示的
选项参数:可参考博主:Linux命令top_linux top-CSDN博客
杀死进程----kill命令
语法:kill [选项] PID #PID 进程标识符
网络信息的查看----ping/ifconfig/
ping命令:查询是否可以连接到目标主机
ifconfig: 显示Linux设备网络信息
netstat: 查看网络端口
3.6 用户权限介绍
root用户:系统管理员
切换用户----su命令
退出当前用户----exit命令
新增用户----useradd命令
修改密码----passwd命令 passwd [用户名]
删除用户----userdel命令 userdel [用户名]
查看当前用户登录名----whoami命令
4. Vi编辑器
类比Windows可以直接打开文本文件进行编辑,Linux系统则需要借助Vi这一文本编辑程序。
- 在没有图形界面的环境下,要编辑文件,
vi是最佳选择! - Vi: Visual Interface 是
Linux中 最经典 的文本编辑器;Vim: Vi improved 是从vi发展出来的一个文本编辑器,支持 代码补全、编译 及 错误跳转 等方便编程的功能
Vi的三种基本工作模式:
- 命令模式
- 输入模式/编辑模式
- 末行模式/底线命令模式
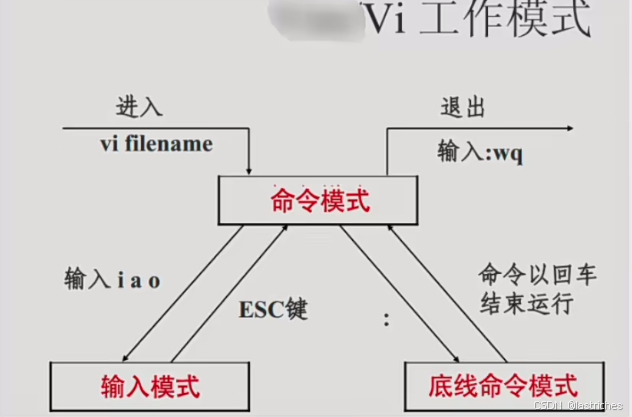
基本工作流程:
- 1.命令行输入vi+文件名,进入vi命令模式
- 2.在命令模式按下i/a/o等进入文本输入模式
- 3.插入或编辑文件内容
- 4.编辑完成后按ESC回到命令模式 注:此时还不能直接退出
- 5.从命令模式按:进入末行模式
- 6.按wq保存退出,或这按q!不保存退出
命令模式
无论处在什么模式按下ESC都会返回命令模式。命令模式不支持输入文本,但有以下命令可使用:
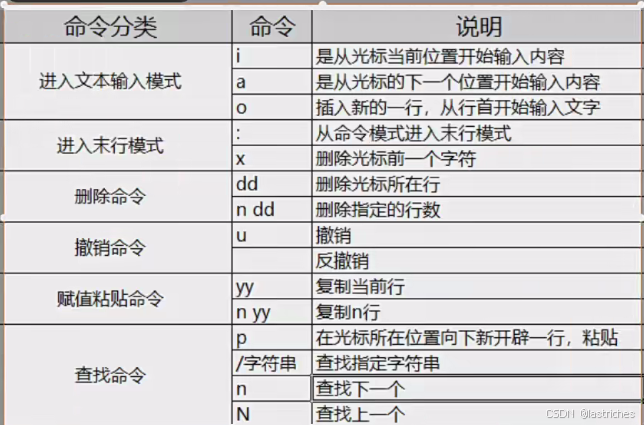
输入模式
i,a,o进入。类比windows编辑文本
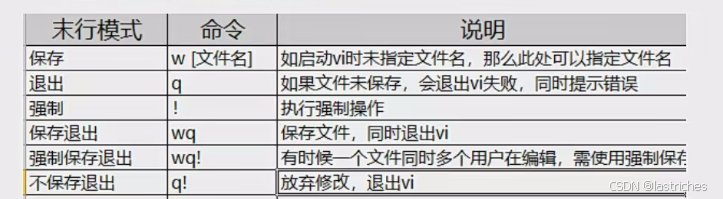
末行模式
命令行模式下按:键
TPshop实战项目
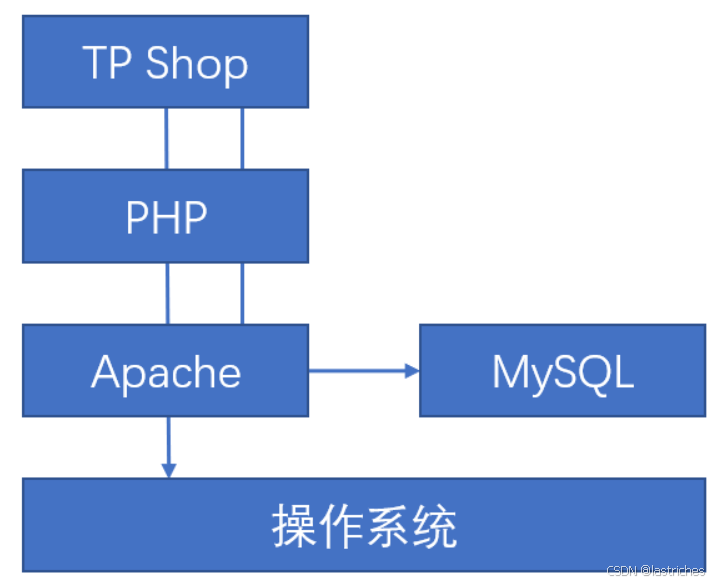
环境搭建
- Windows环境的搭建:前文已经介绍过
windows+Apache+MySQL+PHP+项目文件
Apache+MySQL+PHP:采用Phpstudy集成环境
注:Apache是一种开源的网页服务器web serve,提供网页信息流量服务功能
PHP是一种通用的开源脚本语言,实现TPshop网上商城的业务逻辑与动态页面展示
MySQL数据库,存储与管理数据
- Linux环境的搭建:较为复杂,放在后续讲解
Linux+Nginx+MySQL+PHP+项目文件
注:Nginx是一种网页服务器web serve,提供网页信息流量服务功能
项目介绍
- 项目信息来源
测试人员可以从需求文档、技术和使用环境、相关人员处收集信息建立起对整个项目的全面认识
- 项目的业务特性
tpshop是一款开源的网上购物商场,类比于淘宝、京东
- 项目用户
访客、注册用户、管理员、仓管、客服等(场景法建立业务主干流程)
- 项目架构:
用Xmind等类似工具建立起一个项目中系统和其子系统,子系统和其各元素的组织关系,反映项目的系统架构,帮助测试人员明确功能测试需要覆盖的功能项
注:一般到模块的具体功能项就不再细分了

- 项目的技术栈
数据库表:
- 商场会员对应的tp_users
- 商城商品对应的tp_goods
- 订单对应的tp_orders
注:选择相应表,点击DDL功能或按钮查看表的描述
作业1:tp_users 如何查询tp_users表中最后一条用户的信息
![]()
作业2:修改用户昵称nickname
![]()
作业3:tp_goods查看排序在前十条的商品信息(重命名为id,商品名称,库存,售价)

作业4:修改商品名称
![]()
作业5:tp_order tp_users查看手机号是15728743912的会员昵称和所下的订单信息

实战1:注册账号选购商品后去tp_order表查询自己的订单信息
第一步:注册账户
第二步:尝试在数据库中查询刚注册好的用户信息
select * from tp_users GROUP BY user_id DESC LIMIT 1
第三步:添加地址---选购商品--提交订单--显示订单提交成功
第四步:根据手机号查询刚刚生成的订单信息
SELECT * from tp_order where mobile=18532038129
实战演练
框架流程可参照博主:
黑马测试基础-TPshop项目(1)_tpshop开源商城黑马-CSDN博客
黑马测试基础-TPshop项目(2)_黑马tpshop项目源码-CSDN博客
实战简介,通过TPhshop我们将遵循测试的整体流程体验功能测试的实际业务操作,复习之前的知识点并在此过程中进行查漏补缺
step one :迭代版本的需求评审(产品主导)
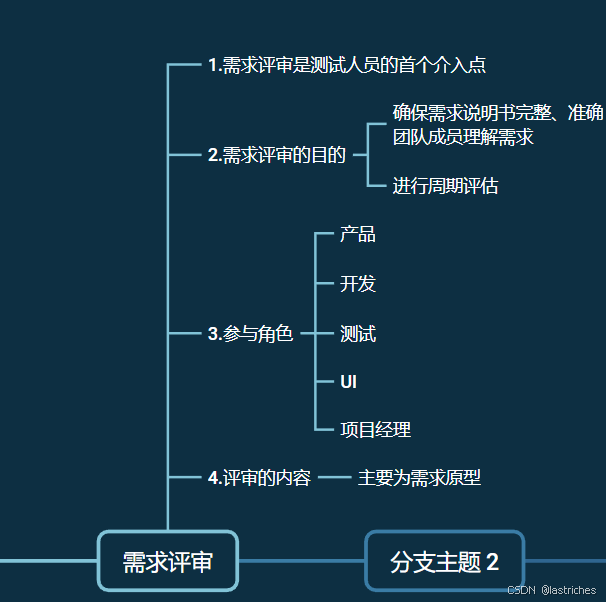
此时测试人员的职责是
- 确认自己对需求要有清晰的理解,没有疑惑
- 确认需求文档完整、准确,能够指导后期工作
- 对需求中不合理的地方提出自己的修改建议
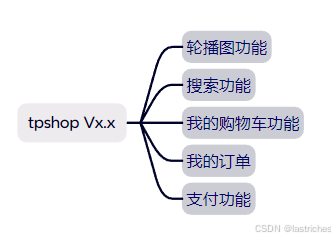
假设产品说明本次迭代的版本共包含5个功能,分别为:
轮播图、搜索、我的购物车、我的订单、支付
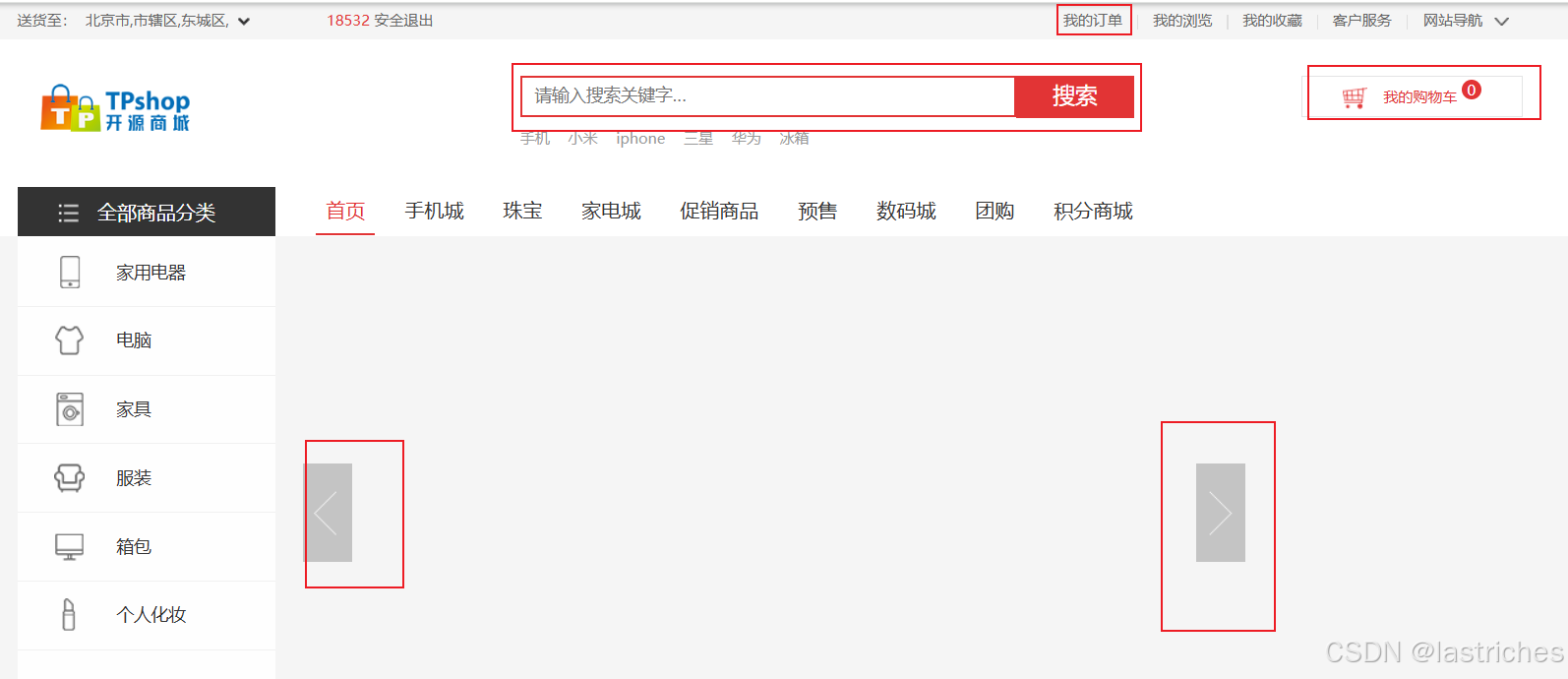
------------------------------------------需求评审完成----------------------------------------
step two: 需求分析
在需求评审结束,原则上需求说明书已经完整、准确; 团队人员对需求的理解都清晰一致
接下来测试人员将根据评审会议中的笔记,其他同类型或旧原型项目继续熟悉产品的需求说明书,旨在明确各需求模块的所要求实现的各功能是什么。
这里假设需求说明书对本次迭代的产品功能模块规定的需求细节如下
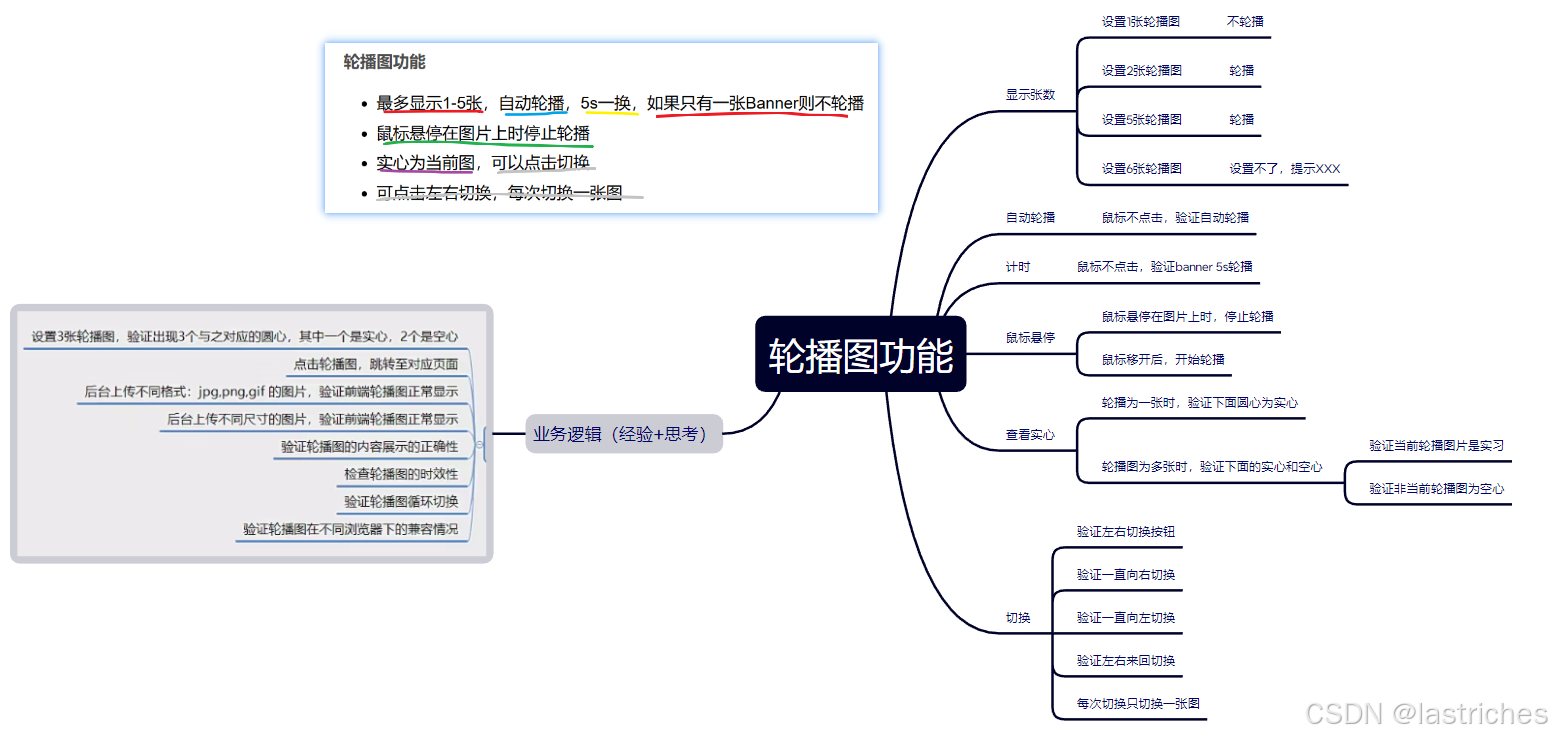
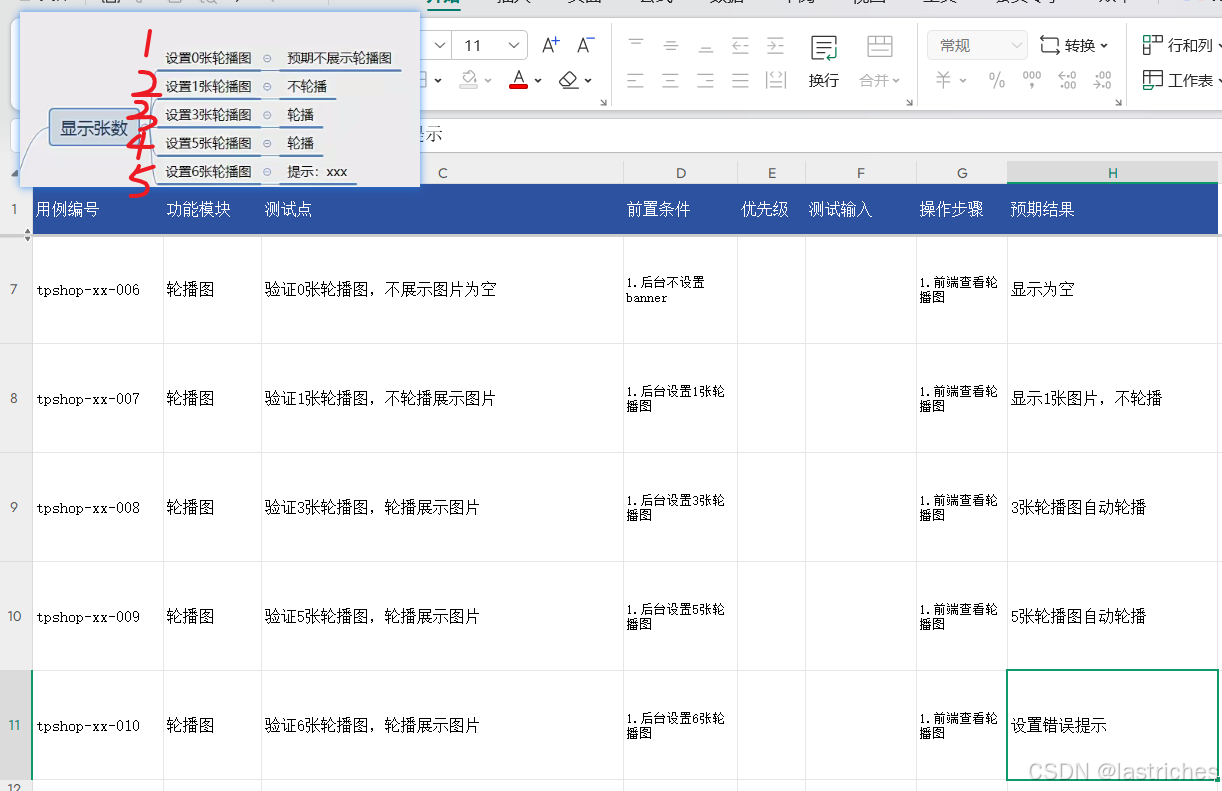
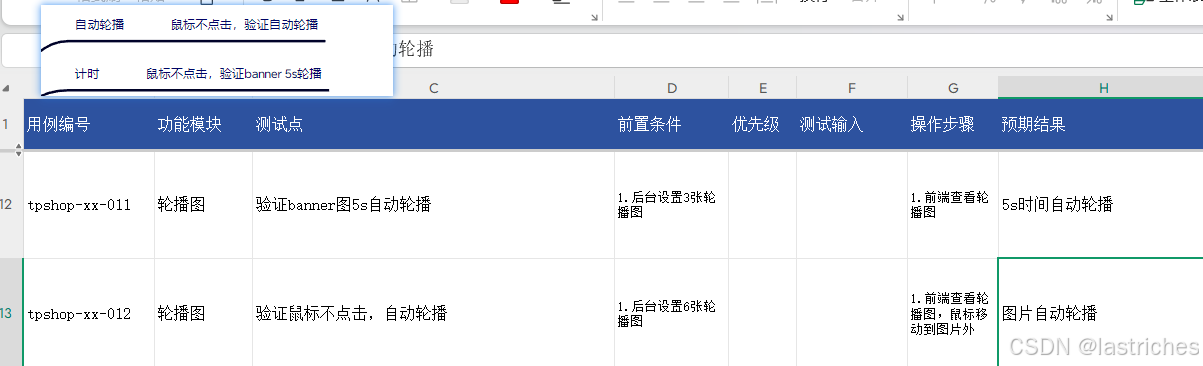
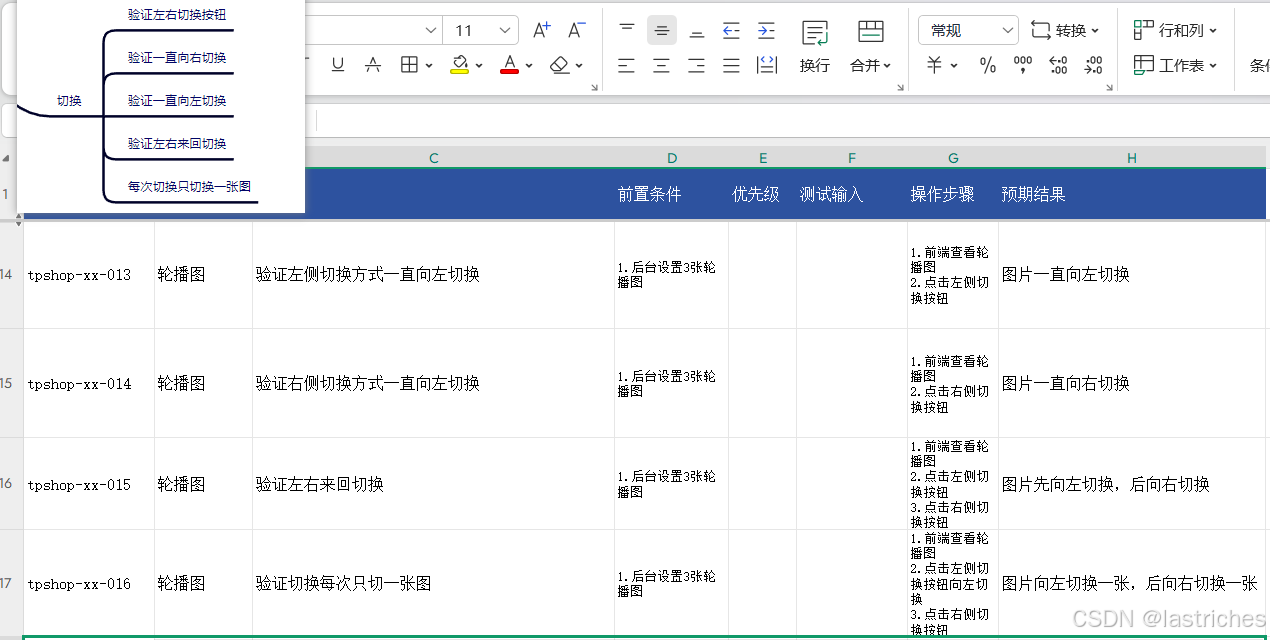
轮播图功能
- 最多显示1-5张,自动轮播,5s一换,如果只有一张Banner则不轮播
- 鼠标悬停在图片上时停止轮播
- 实心为当前图,可以点击切换
- 可点击左右切换,每次切换一张图
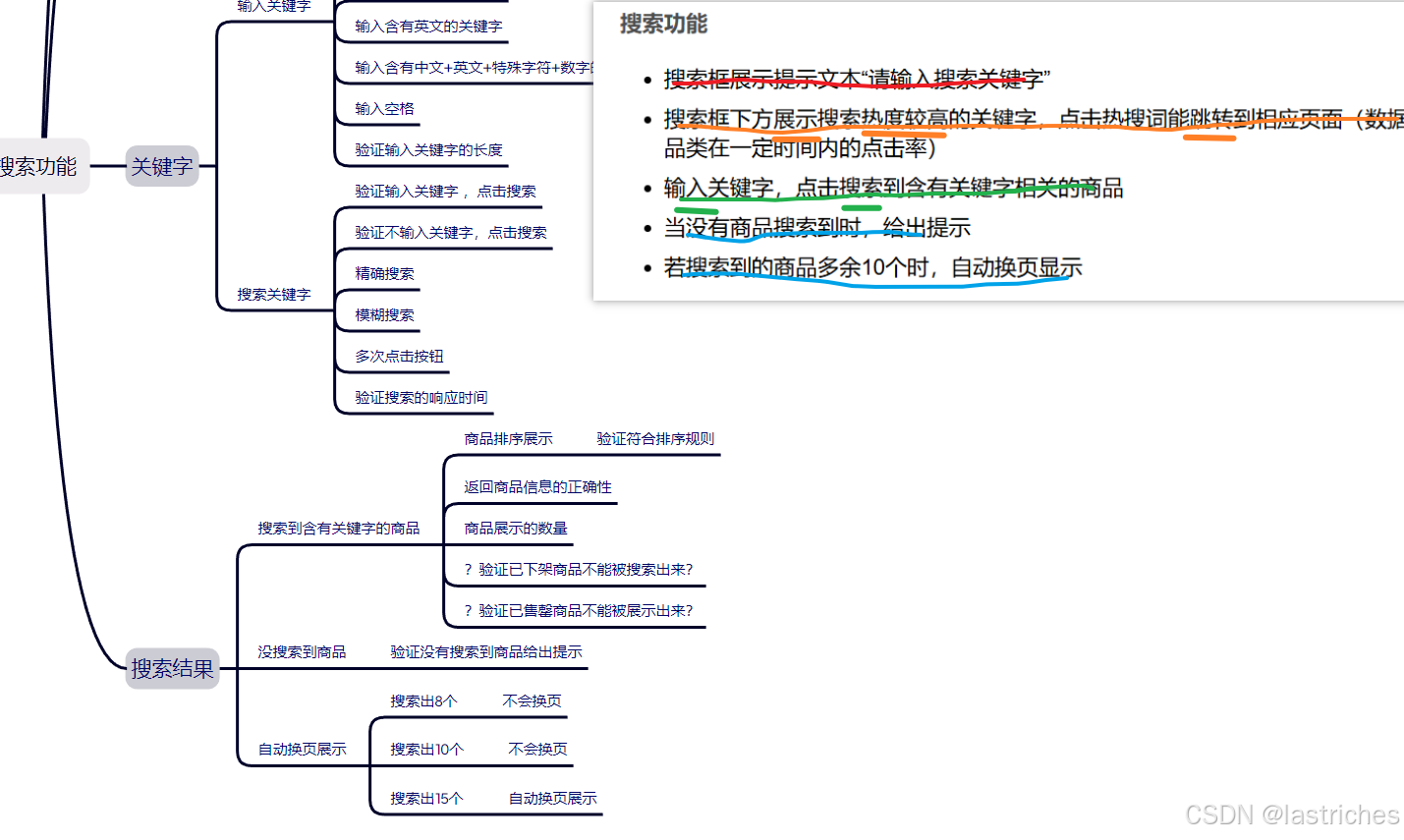
搜索功能
- 搜索框展示提示文本“请输入搜索关键字”
- 搜索框下方展示搜索热度较高的关键字,点击热搜词能跳转到相应页面(数据库建表统计产品品类在一定时间内的点击率)
- 输入关键字,点击搜索到含有关键字相关的商品
- 当没有商品搜索到时,给出提示
- 若搜索到的商品多余10个时,自动换页显示
我的购物车功能
- 可以添加商品到购物车
- 可以添加不同商品到购物车
- 购物车右上角显示添加到购物车的数量
- 购物车的商品可以进行更新
- 购物车的商品也可以删除
- 点击购物车按钮,直接跳转到购物车页面
我的订单功能
- 当没有订单时,页面提示'您还没有订单,快去逛逛吧~当没有订单时,页面提示'您还没有订单,快去逛逛吧~'
- 当订单购物成功时,可以已购商品的信息
- 每个订单都可以查看详细信息
- 订单可以按状态分类展示
- 每个订单都会有一个唯一的订单号
支付功能
- 支付可以选择多种方式进行支付,如支付宝,微信,网银
- 进入订单页面时,该商品被锁定,其它用户无法购买该商品
- 商品被锁定时,提供立即付款和取消订单按钮,点击取消订单时,取消该商品的购买
- 当商品支付成功时,提示付款成功,进入卖家发货状态
- 订单超时时,自动取消该订单购买操作
step three: 编写测试计划

step four: 提取测试点以编写测试用例并评审

提取测试点
①首先先整体后局部
先考虑产品的最核心模块,即业务的主干流程
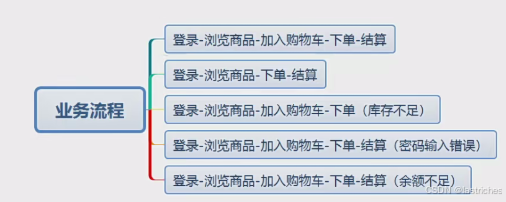
②然后再先正向后逆向
主干流程的正向基本流为:基本流:注册-登录-选商品-加入购物车-下单-支付
逆向从备选流出发,考虑基本流执行过程中会导致系统无效或错误的业务执行,从而形成逆向回路的一条流程
③最后再先功能后其他
根据需求分析中得出的模块功能需求列表,尽可能地提取测试点,如下:
轮播图功能:
搜索功能

我的购物车功能
我的订单功能
支付功能
编写测试用例
主流程:

轮播图:
step five: 部署测试环境与冒烟测试
补充:
设置轮播图
TPshop后端系统管理界面进入编辑,设置广告位置为首页banner广告轮播,开始日期和结束日期设置为近期否则过期会不显示,设置完成后返回前端界面即可查看效果
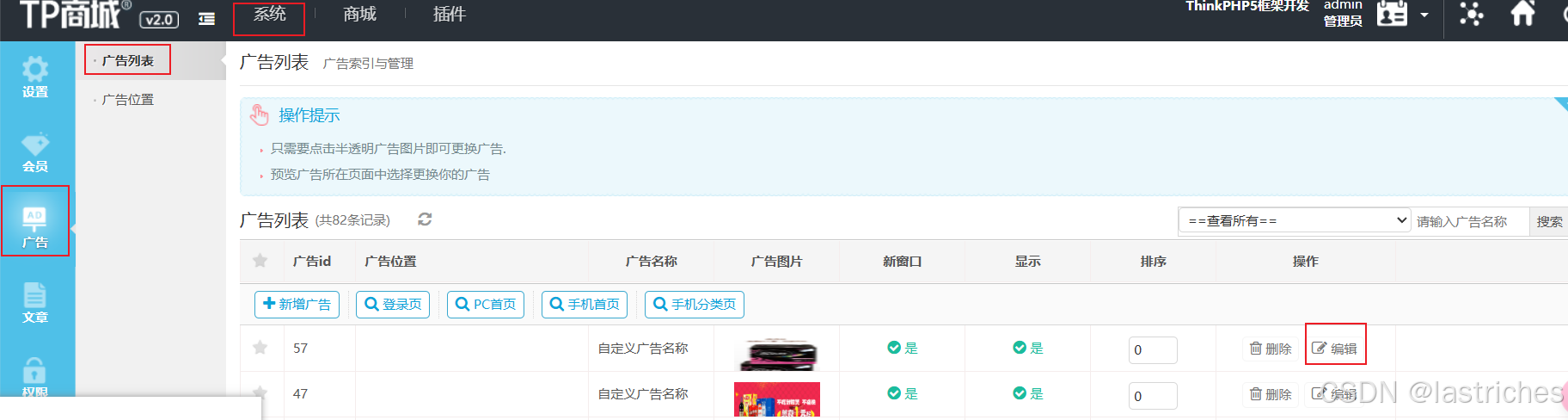
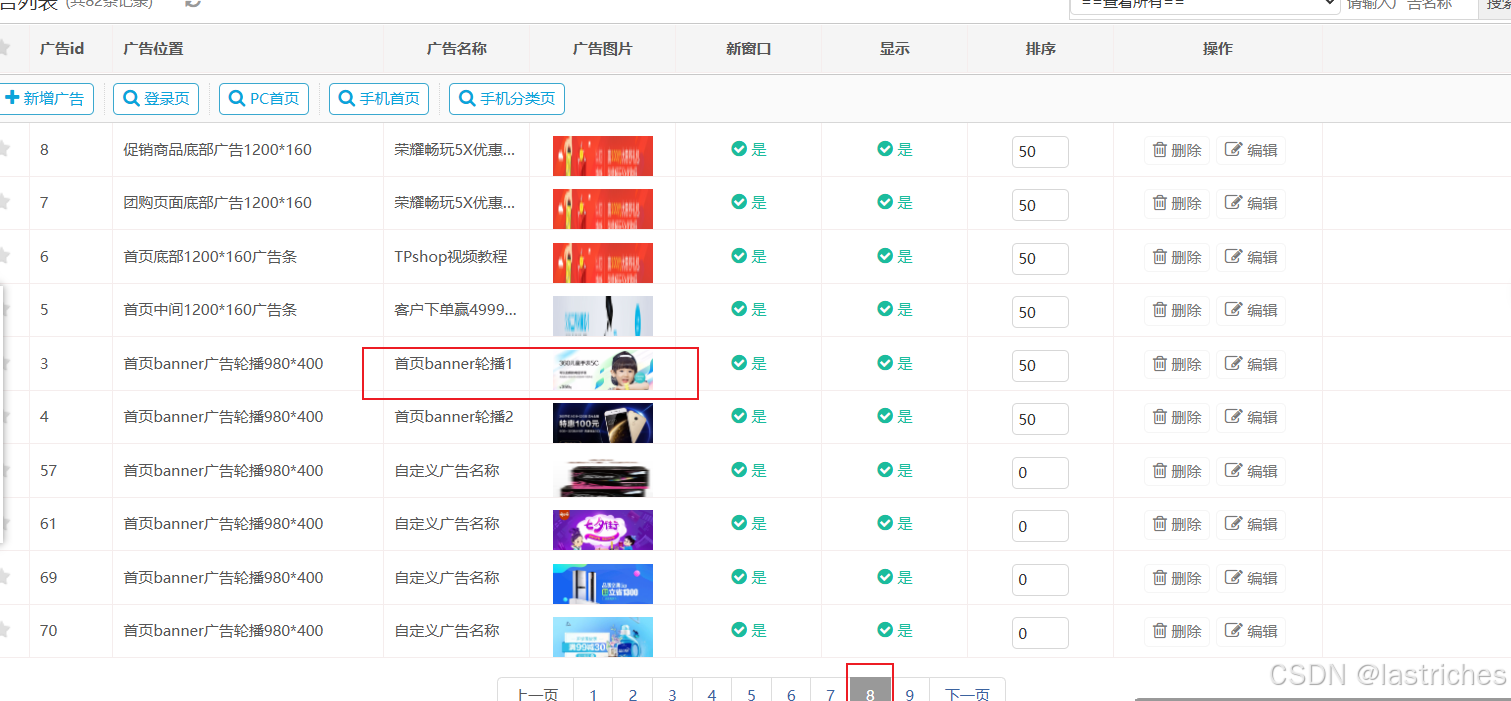
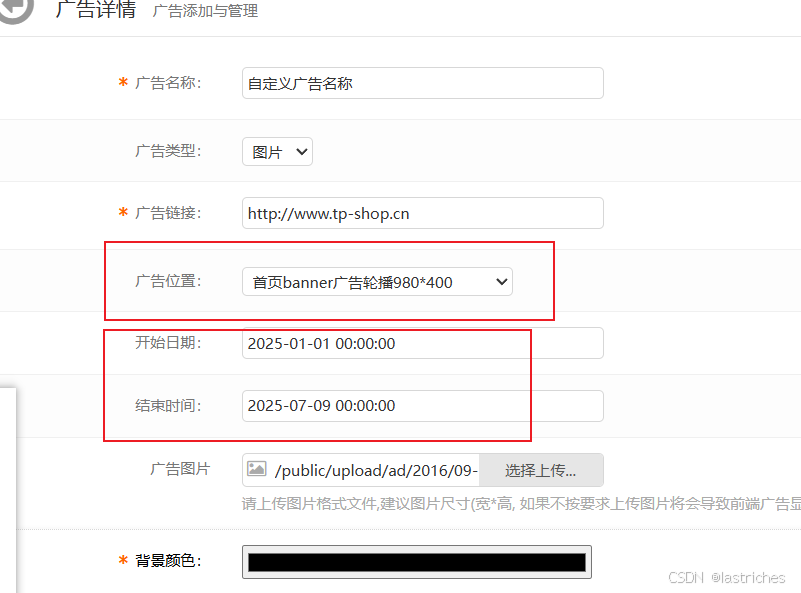
设置自定义搜索的商品:
TPshop后端系统管理界面进入编辑,自定义添加商品。注意添加关键词使前端搜索时可以用关键字搜索,提交成功后返回前端进行关键字搜索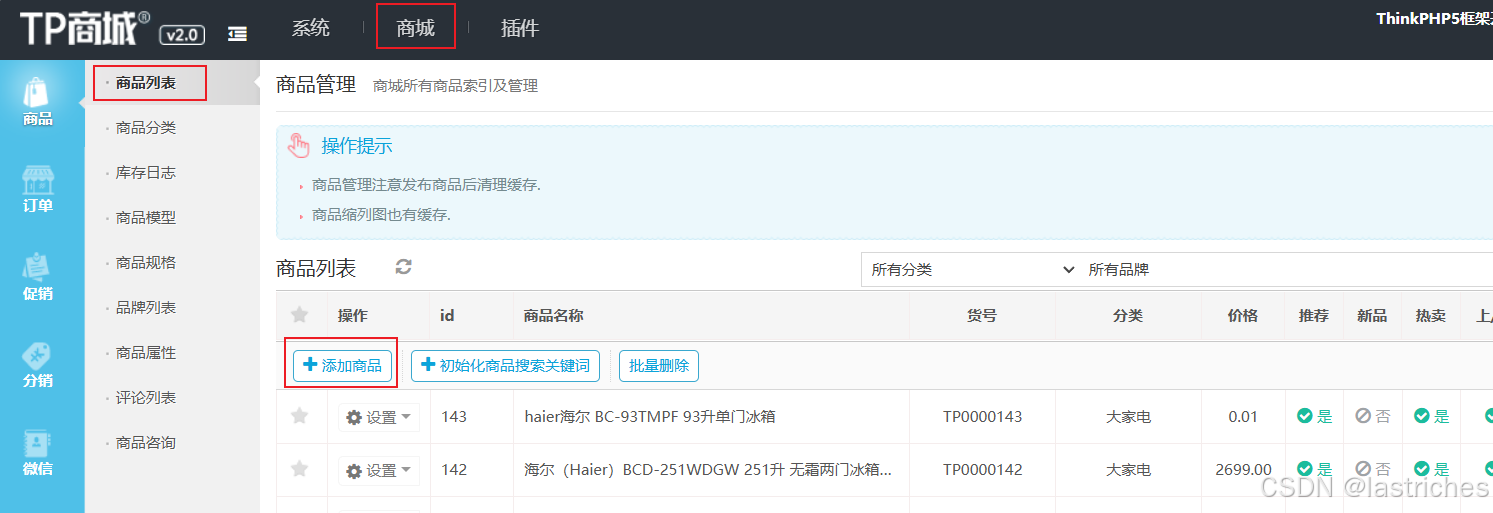
step six: 执行测试用例
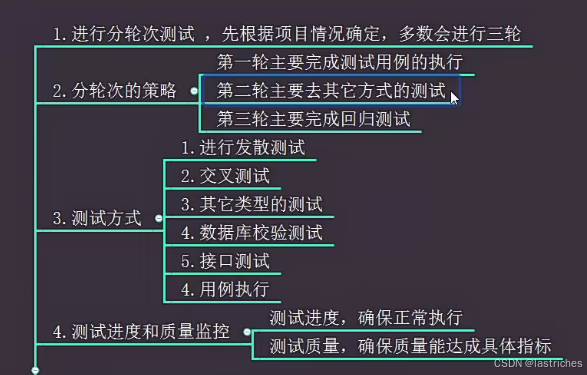
step seven: bug提交与管理

step eight: 完成测试报告

step nine: 上线测试
禅道提交BUG
-----阶段三:编程入门-----
Python基础(为零基础人提供,有一定基础的可以略看)
1. 了解进制数与进制转换
1.1 进位计数制
在计算机语言中,进制是一种表示数字的方式,它决定了一个数字的基数和表示规则。最常见的进制包括:
十进制(Decimal):基数为10,使用0-9这10个数字表示。 逢十进一 D
二进制(Binary):基数为2,使用0和1表示。 B
八进制(Octal):基数为8,使用0-7表示。
十六进制(Hexadecimal):基数为16,使用0-9和A-F表示。 H 0x
每种进制都有其独特的特点和应用场景。进制转换是将数字从一种进制表示转换为另一种进制表示的过程。
基数:每个数码位所用到的不同符号的个数,r进制的基数为r
位权介绍:
用数据所在的相应位置来表示数据值的权重
例如:十进制 5 4.1 2:5的权重:10^1 ; 4的权重:10^0 ; 1的权重:10^-1; 2的权重: 10^-2
1.2 进制转换
其他进制-->十进制
每个数乘以位权的累积:

二、八、十六进制的互相转换
二进制--->八进制
根据二进制基数为2,八进制基数为8。在二进制转八进制时将二进制数按3位一组进行划分,每组即可转换为对应的八进制的符号表示

八进制--->二进制
将二到八转换过程进行逆变换,每个八进制符号用3位二进制表示

二进制--->十六进制
根据二进制基数为2,十六进制基数为16。在二进制转十六进制时将二进制数按4位一组进行划分,每组即可转换为对应的十六进制的符号表示

十六进制--->二进制
将二到十六转换过程进行逆变换,每个十六进制符号用4位二进制表示

八进制--->十六进制/十六进制--->八进制
以二进制数为中介完成互相转换
例:
- 将八进制数转换为二进制数
- 将二进制数转换为十六进制数
十进制--->其他进制

针对十进制的整数部分
根据r进制和十进制的基数特点通过取余法得到每位上相应进制的符号表示:

针对十进制的小数部分
对小数点后的数进行整体乘以r取整操作,对小数点以后的数×2,取结果的整数部分,然后再用小数部分再×2,再取结果的整数部分……以此类推,直到小数部分为0。然后把取的整数部分按先后次序排列,就构成了二进制小数部分的序列

同样因为十进制到二进制比较方便,十进制的其他进制的转换也可以以二进制为中介,先转换为二进制再在此基础上对应的r进制转换(一般也就是8,16)
深入学习可查看博主:2024考研408-计算机组成原理第二章-数据的表示学习笔记_408考研 补码的加减交替会考吗-CSDN博客
2. 了解代码语言分类
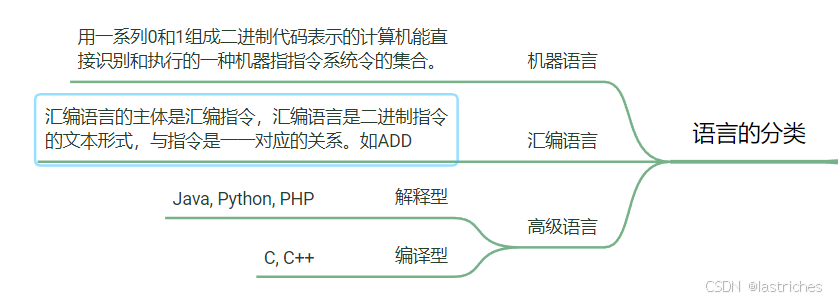
高级语言转换到汇编语言的过程叫做编译,由汇编语言转换到机器语言的过程叫做汇编,边翻译边执行的叫做解释
简单了解可参照:机器语言、汇编语言(低级语言)、高级语言_机械语言-CSDN博客
3. Python环境搭建
安装python语言环境
安装Pycharm编辑
可参照博主:2024最详细Python安装+Pycharm安装教程!_python安装教程-CSDN博客
4. Python前置知识
Python语法格式
命名规则:
- 以字母、数字、下划线组合命名
- 不能以数字开头
- 对大小写敏感,请区分大小写
- 不要使用python中的关键字
- 变量名应该具有描述性,以便代码可读性
关键字:
注释:
- 单行注释 #
- 多行注释 """ xxx """ / ''' xxx '''
- 快捷键注释:ctrl+/
缩进:
与其他语言采用{ } ;分割语句块不同,Python用缩进来识别代码块和代码之间的逻辑(隶属)关系,缩进相同的代码是一个代码块。快捷键Tab 四个空格
多行:
使用\将单行的内容人为分割成多行在代码编辑时显示,方便查看。实际仍然按单行输出
运算符:
- 算术运算符:+,-,*,/,%,//(商向下取整),**(次方)
- 比较运算符:==,>, <,<= , >= , !=
- 赋值运算符:+=, =, -=, *=, /=, %=, //=, **=
- 身份运算符:is ,is not 身份运算符用于比较两个对象的身份是否相同,即它们是否是内存中的同一个对象 用来判断是否两个变量指向同一个对象
- 成员运算符:in ,not in 快速确定给定值是否是值集合的一部分
- 逻辑运算符:not , and与 , or或 , !非
数据类型:
基本的数据类型:数字型、字符串、元组、列表、字典、集合
不可变数据类型:数字型、字符串、元组
可变数据类型:列表、字典、集合
- 整型: int 数字型 2
- 浮点型: float 数字型 2.0
- 布尔型: bool 数字型 True ; False
- 字符串: str 'xx' 可遍历
- 空值: None
- 列表: List [元素1,元素2] 可变序列类型 [1,2,'列表',False] 可遍历
- 元组: Tuple 不可变序列类型 (1,2,'元组',True) 可遍历
- 字典: Dict d = {key1 : value1, key2 : value2 } 可遍历
- 可变集合:set 一个无序的不重复元素序列 可变集合set {元素1,元素2} set(value) 可遍历
- 不可变集合:frozenset
具体可参看博主:3. Python基础:基本数据类型(九种数据类型)_python的基本数据类型-CSDN博客
补充博主:python基础篇总结:数据类型_python数据类型-CSDN博客
常用数据类型及其函数介绍:
参考:
快速入门:Python3 字符串 | 菜鸟教程
Python 标准库 — Python 3.13.2 文档全面介绍:Python 标准库 — Python 3.13.2 文档
-
整型、浮点型、布尔值数字类型一般结合运算符使用
random() 生成在[0,1)范围内随机数
int(x) 将x转换为一个整数。
float(x) 将x转换到一个浮点数。
len(x)放回数据的长度
range(起始数字,末位数字,步长)创建一个可遍历的整数列表
-
字符串
截取字符串的值:
语法 str[头下标:尾下表 :截取步长]
索引值从左往右以 0 为开始值,从右往左-1 为从末尾的开始位置;
注:索引左闭右,开尾下表值取不到,因而若是想取到尾下标所在的值得扩大取数范围;步长取负值时,为逆取
str='mynameis_liu' print(str[-1:1:-1]) # uil_sieman
字符换格式化显示:
① 将数据转换为指定的输出格式。就是占位符,主要是通过%的方式,将数字、字符传递到字符串里所在位置,传递的时候按照顺序传递
语法:' xxx %选项 xxx ' % (被格式化的对象)
print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
选项参数:
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
② 格式化字符串的函数 str.format(),它增强了字符串格式化的功能。基本语法是通过 {} 和 : 来代替以前的 % ;format 函数可以接受不限个参数,位置可以不按顺序
num1=1
num2=3
num3=4
print('{}+{}={}'.format(num1,num2,num3))
print('{1}+{0}={2}'.format(num1,num2,num3))
print('{num2}+{num1}={num3}'.format(num1=2,num2=4,num3=6))
③ f-string字符串格式化
f字符串格式化包含了由花括号括起来的替换
字段print(‘xx={替换字段}’),替换字段是表达式,在运行时计算并且使用format()协议进行格式化
import datetime
name = "zings"
age = 17
date = datetime.date(2019,7,18)
print(f'my name is {name}, this year is {date:%Y},Next year, I\'m {age+1}')
深入学习其他格式化显示的方法可参考博主:Python字符串格式化详解-CSDN博客
转义字符
r 'xxx\xx\ ' 字符串前+R取消系统对转义字符的识别
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
内建函数
string.center(width, fillchar): 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
string.count(str, beg, end): 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数
......
注:字符串也可以结合运算符使用
例如*:重复显示一个字符串;+:合并两个字符串
-
列表list[元素1,元素2]
截取列表的值:
语法 list[头下标:尾下表 :截取步长]
索引值从左往右以 0 为开始值,从右往左-1 为从末尾的开始位置;
注:索引左闭右,开尾下表值取不到,因而若是想取到尾下标所在的值得扩大取数范围;步长取负值时,为逆取
list1=[1,2,True,'str1',[4,'str2']] print(list1[1],list1[-1],list1[3:4],list1[-1][1]) # 2 [4, 'str2'] ['str1'] str2
向列表中追加元素:
语法:
单个整体增加list.append( )
逐个批量增加list.extend( )
修改元素:
语法:依据索引修改指定位置元素 list[0]=2
插入元素:
语法:依据索引在指定位置插入元素
list.insert(索引,元素)
删除元素:
①语法:依据索引删除指定位置元素,并返回被删除元素
list.pop(index)
②语法:依据元素的值删除指定的元素,被删除的元素为第一个遍历到的符合条件的值
list.remove(obj)
排序:
语法:
list.sort(cmp=None, key=None, reverse=False)
实例可查看:Python List sort()方法 | 菜鸟教程
- cmp -- 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
注:列表也可以结合运算符使用
例如*:重复显示列表中元素;+:拼接列表的元素
-
元组tuple[元素1,元素2]
截取元组的值:同列表
统计元组中元素的个数:同列表
语法:
tuple.count(obj)
返回元素在元组中的首个索引:同列表
语法:
tuple.index(obj)
强制修改元组的数据:借助列表
将元组转换为列表 tuple2=list(tuple1)
修改列表中的值
再将列表转换为元组 tuple1=list(tuple2)
注:元组也可以结合运算符使用
例如*:重复显示列表中元素;+:拼接列表的元素
-
集合set(元素1,元素2) ; {元素1,元素2}
向集合中追加元素:
语法:
set.add(元素)
删除元素:
①语法:依据元素的值删除指定的元素,被删除的元素为第一个遍历到的符合条件的值.
set.discard(obj) //删除不存在元素时不会有提示
②语法:依据元素的值删除指定的元素,被删除的元素为第一个遍历到的符合条件的值
set.remove(obj) //删除不存在元素时会有提示
③语法:随机删除集合中的一个元素
set.pop()
交并差集
| difference() | 返回多个集合的差集 |
| intersection() | 返回集合的交集 |
| union() | 返回两个集合的并集 |
-
字典 Dict
获取字典中的所有key
语法:
dict.keys
获取字典中的所有value
语法:
dict.values()
获取指定key的value值
①语法:
dict.get(key)
②语法:
dict[key]
同时获取key和value的item值
语法:
dict.items()
5.强制转换

6. Python代码
练习1:在方框里打印字符串,屏幕长度为80,方框长度比字符串长6,左边距为(屏幕长度-方框长度)/2,字符串在方框的中央
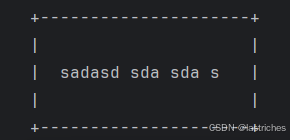
***依据图形绘制***
#屏幕长度
screen_length=80
#输入字符串
str=input("要显示的字符串")
#方框长度
box_length=len(str)+6
#左边距
left_margin=(screen_length-box_length)//2
#顶部方框
print(' ' * left_margin + '+' + '-' * (box_length-2) + "+" )
#第一行
print(' ' * left_margin + '|' + ' ' * (box_length-2) + '|')
#第二行,字符串得居中
print(' ' * left_margin + '|' + ' ' * ((box_length-len(str)-2)//2) + str +' '*((box_length-len(str)-2)//2)+'|')
#第三行
print(' ' * left_margin + '|' + ' ' * (box_length-2) + '|')
#底部
print(" " * left_margin + "+" + "-" * (box_length - 2) + "+")
***使用center函数***
#屏幕长度
screen_length=80
#输入字符串
str=input("要显示的字符串")
#方框长度
box_length=len(str)+6
#顶部方框
top_line="+" + '-'* (box_length-2)+"+"
print(top_line.center(80))
#第一行
first_row="|" + ' '*(box_length-2)+"|"
print(first_row.center(80))
#第二行
second_row="|" + ' '*2 + str +' '*2+'|'
print(second_row.center(80))
#第三行
third_row="|" + ' '*(box_length-2)+"|"
print(third_row.center(80))
#底部方框
bottom_line="+" + '-'* (box_length-2)+"+"
print(bottom_line.center(80))
***进阶*** 提示:使用字符串的center函数


















 4785
4785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









