







schema.xml
Field(域)
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
name:域的名称
dynamicField(动态域)
<dynamicField name="*_s" type="string" indexed="true" stored="true" />name:动态域的名称,是一个表达式,*匹配任意字符,只要域的名称和表达式的规则能够匹配就可以使用
uniqueKey(唯一键)
<uniqueKey>id</uniqueKey>copyField(复制域)
<copyField source="cat" dest="text"/>可以将多个Field复制到一个Field中,以便进行统一的检索,当创建索引时,solr服务器会自动的将源(source)域中的内容复制到目标(dest)域中
fieldType(域类型)
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
name:域类型的名称
配置中文分词器
在Lucene中我们使用IK分析器,这里也需要引入中文分词器,
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>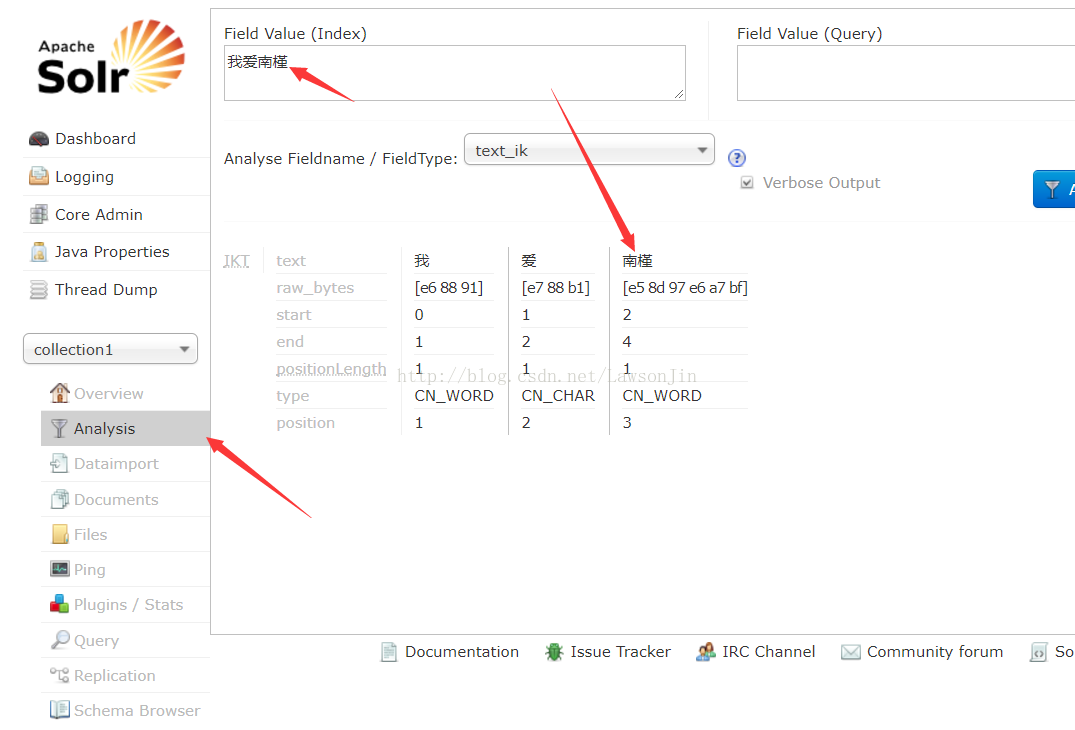
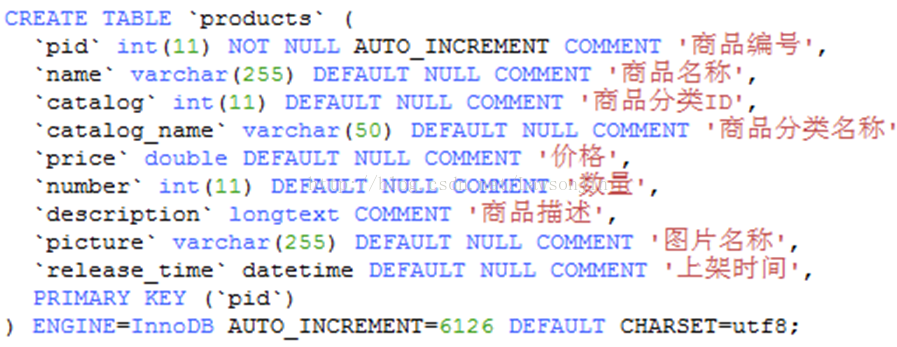
定义Field域
<!-- product start-->
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_catalog_name" type="string" indexed="true" stored="false" />
<field name="product_price" type="double" indexed="true" stored="true" />
<field name="product_description" type="text_ik" indexed="true" stored="false" />
<field name="product_picture" type="string" indexed="false" stored="true"/>
<field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>
<!-- product end-->因为id已经定义过id域,这里就用定义过的了
dataimportHandler
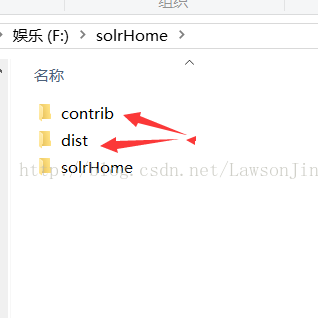
粘贴到contrib\dataimporthandler\lib
没有lib目录,需要手动创建(可以不放lib文件夹中,后面的配置文件路径匹配即可)
然后再复制Mysql的驱动包,粘贴到contrib\db\lib,contrib没有db\lib目录,需要手动创建
再然后修改solrconfig.xml,加载刚刚复制进来的jar包
添加如下配置即可,注意solr.install.dir为SolrCore目录, ../代表上级目录
<lib dir="${solr.install.dir:../..}/contrib/dataimporthandler/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../..}/contrib/db/lib" regex=".*\.jar" />
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
最后创建data-config.xml配置文件
在collection1\conf\目录下创建data-config.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://127.0.0.1:3306/solr"
user="root"
password="root"/>
<document>
<entity name="product" query="SELECT pid,name ,catalog_name,price,description,picture FROM products">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
</entity>
</document>
</dataConfig>
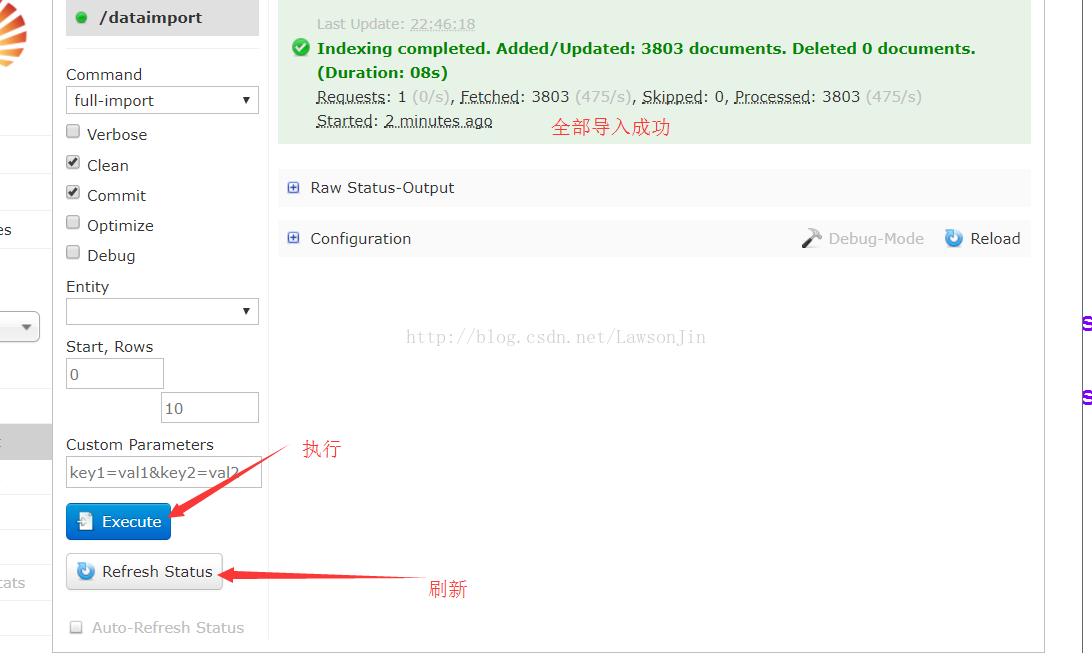
重启tomcat,进入DataaImport功能首页。
直接点Execute蓝色执行按钮,然后一直按刷新的refresh Status直到,
SolrJ查询
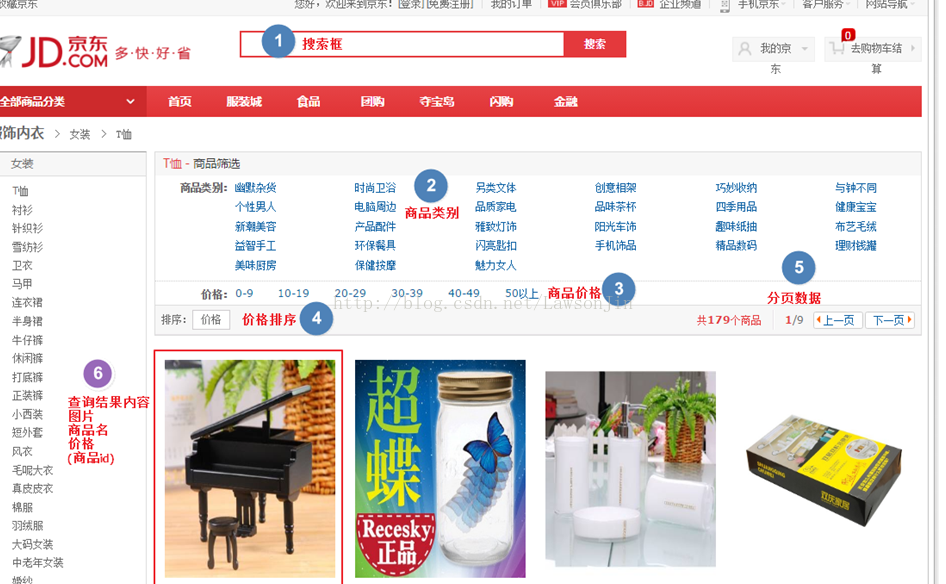
先来看看solr在web服务器里的查询
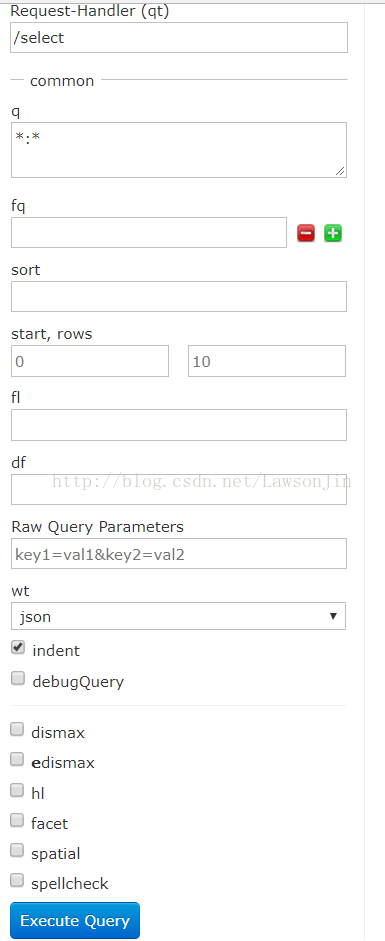
1. q:查询关键字,必须的
请求的q是字符串,如果查询所有使用*.*
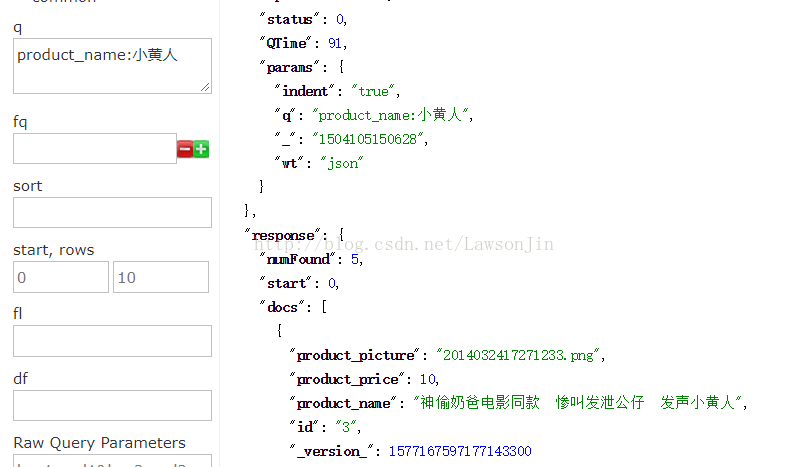
我们来查一下商品名是小黄人的
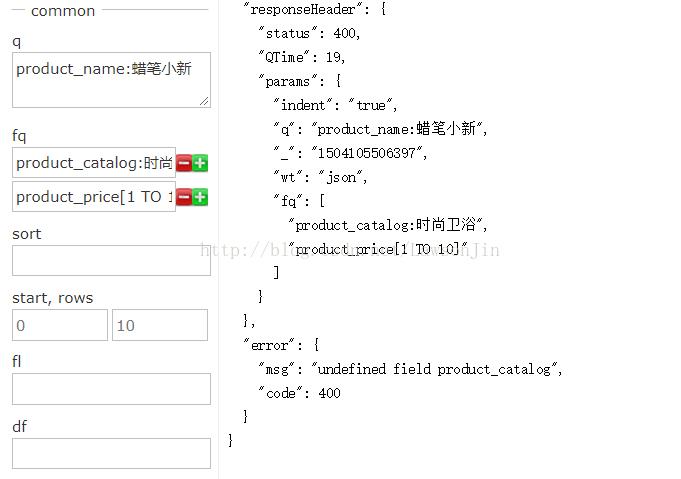
2.fq(filter query):
作用:在q的查询结果之上进行条件过滤,再根据fq查询,fq是一个数组,可以填多个条件
首先q查询商品名为蜡笔小新的,分类是时尚卫浴,价格在1-10之间的
当然也可以使用 * 代表无限
20以上: product_price:[20 TO *]
20以下:product_price:[* TO 20]
3. sort 排序, desc代表降序,asc代表升序
按照价格降序
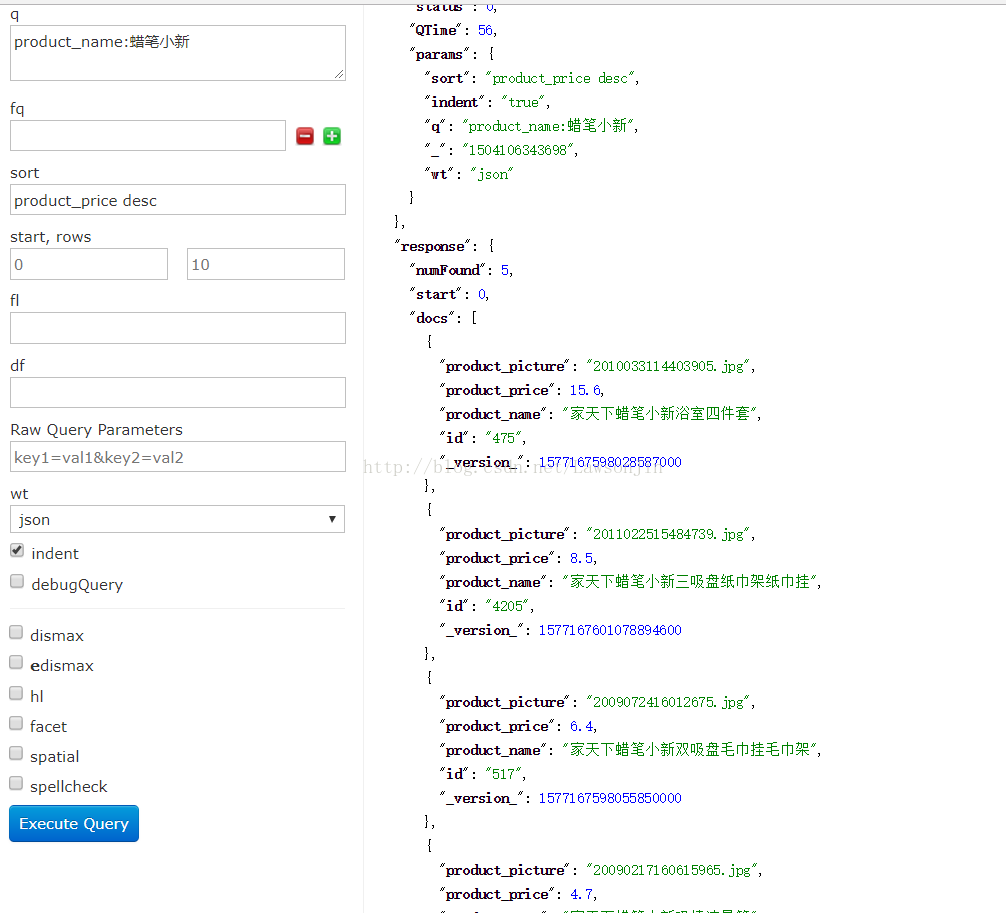
4.start ,rows
start:分页显示,默认从0开始
rows:查多少条数据,配合start来实现

从10开始查20条
5.fl(field List): 指定返回哪些字段内容,用逗号或者空格隔开

fl:product_picture,product_price,id
只显示这三个字段,可以看到,那些没用的字段就没了。
6.df:指定默认搜索Field
比如写上 product_name 那么我们的q就没必要在写product_name:蜡笔小新了,直接写蜡笔小新就ok了
7.wt(writer type):指定输出格式
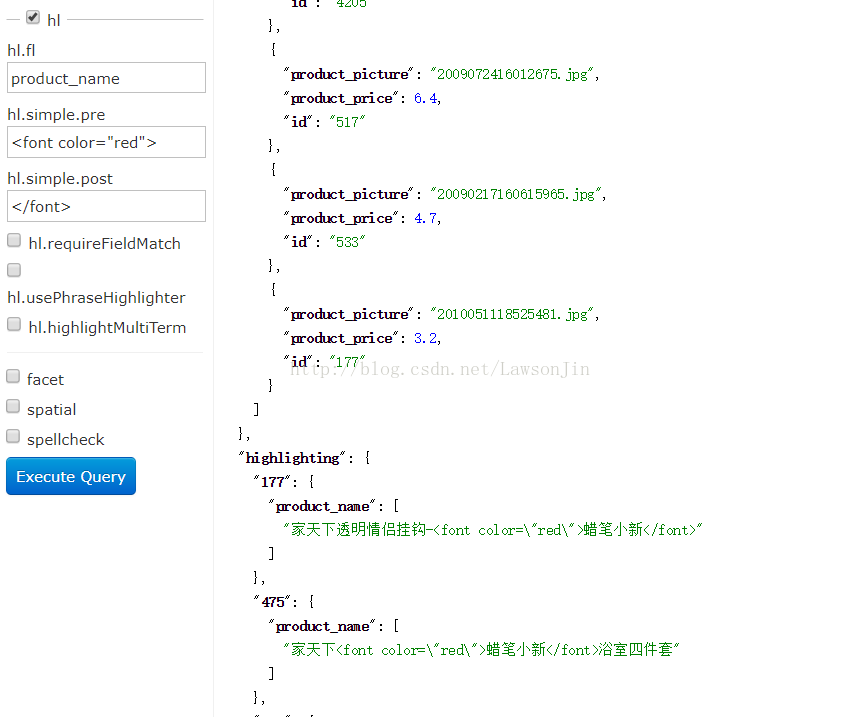
8.hl:是否高亮,是否高亮Field,设置格式前缀和后缀。
solrJ的简单查询
@Test
public void testSearchIndex1() throws Exception {
SolrQuery query =new SolrQuery();
query.setQuery("*:*");
QueryResponse response = solrServer.query(query);
SolrDocumentList results = response.getResults();
for (SolrDocument solrDocument : results) {
System.out.println("------");
System.out.println(solrDocument.get("product_name"));
}
}
solr复杂查询
@Test
public void testSearchIndex2() throws Exception {
SolrQuery query =new SolrQuery();
//设置 q 查询
query.setQuery("蜡笔小新");
// 设置 fq
// query.setFilterQueries("product_catalog_name:时尚卫浴", "product_price:[5.5 TO 20]");
//设置排序
query.setSort("product_price",ORDER.desc);
//分页
query.setStart(0);
query.setRows(10);
//设置显示的Field域
query.setFields("id,product_name,procuct_price");
//设置默认搜索域
query.set("df", "product_name");
//设置高亮
query.setHighlight(true);
query.addHighlightField("product_name");
query.setHighlightSimplePre("<font color=\"red\">");
query.setHighlightSimplePost("</font>");
QueryResponse response = solrServer.query(query);
Map<String, Map<String, List<String>>> map = response.getHighlighting();
SolrDocumentList results = response.getResults();
for (SolrDocument solrDocument : results) {
System.out.println("------");
//获取高亮数据
List<String> list = map.get(solrDocument.get("id")).get("product_name");
if(list!=null && list.size()>0){
System.out.println(list.get(0));
}else{
System.out.println(solrDocument.get("product_name"));
}
}
}结果
家天下<font color="red">蜡笔小新</font>浴室四件套
------
家天下<font color="red">蜡笔小新</font>三吸盘纸巾架纸巾挂
------
家天下<font color="red">蜡笔小新</font>双吸盘毛巾挂毛巾架
------
家天下<font color="red">蜡笔小新</font>吸墙洁具筒
------
家天下透明情侣挂钩-<font color="red">蜡笔小新</font>















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











