










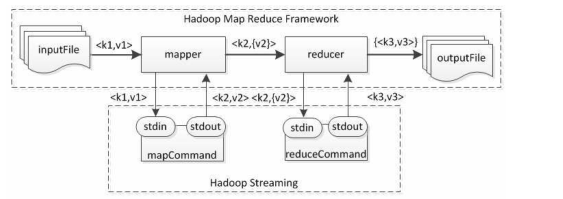
Hadoop使用Streaming技术来替代Java编程,允许用户使用其他语言实现业务逻辑处理Streaming采用UNIX标准输入输出机制(stdin/stdout)作为应用程序和Hadoop计算框架之间的数据接口标准只要符合标准I/O接口,开发人员便可以选择任意语言编写
Map/Reduce模块
下面来做个测试:
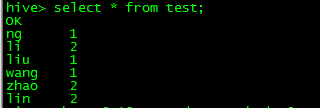
表里一共有两列数据,当第二列的sex为1时,输入为man,当sex为2 时输出为women
一、在Hive里面创建表
CREATE TABLE IF NOT EXISTS test (name String,sex int)
row format delimited fields terminated by ',';二、加载数据
先准备好text.txt
内容如下:
li,2
liu,1
wang,1
zhao,2
lin,2
加载进表里
load data local inpath 'text.txt' into table test;
三、使用python编写UDF
# encoding: utf-8
#!/usr/bin/python
import sys
def parsesex(line):
data=int(line)
if data == 1:
return 'man'
elif data == 2:
return 'womem'
else:
return 'error'
for line in sys.stdin:
line = line.strip()
print(parsesex(line))
四、测试
在hive里面加载py文件
add file /usr/local/src/test.py
在HQL中使用TRANSFORM函数动态执行Python文件:
select TRANSFORM(sex) USING 'python test.py' as sex from test;

测试成功。
如果遇到报错:
Job Submission failed with exception 'java.io.IOException(Unable to close file because the last block does not have enough number of replicas.)'
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
说明机器性能不好,换一个好点的机器,或者重新提交一次任务试试。















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









