







1. 简介
- 基于Spark的流式处理框架
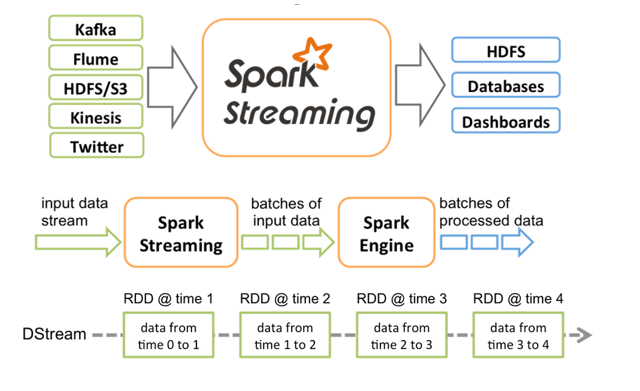
- SparkStreaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,进行处理后,处理结果保存在HDFS、Databases等各种地方
- SparkStreaming接收这些实时输入数据流,会将它们按批次划分,然后交给Spark引擎处理,生成按照批次划分的结果流
- SparkStreaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream。DStream本质上表示RDD的序列。任何对DStream的操作都会转变为对底层RDD的操作
2. DStream
- Spark Streaming provides a high-level abstraction called discretized stream or DStream,which represents a continuous stream of data. DStreams can be created either from input datastreams from sources such as Kafka, Flume, and Kinesis, or by applying high-leveloperations on other DStreams. Internally, a DStream is represented as a sequence of RDDs(Spark Streaming提供称为离散流或DStream的高级抽象,它表示连续的数据流。 DStreams可以从来自诸如Kafka,Flume和Kinesis之类的输入数据流中创建,也可以通过在其他DStream上应用高级开发来创建。 在内部,DStream表示为一系列RDD)
- DStream的本质就是一个时间为key,rdd为value的map,HashMap[time,rdd]

3. 简单理解
- 数据通过inputdata stream不断流进来;Spark Streaming根据时间把流进来的数据划分成不同Job(batches of inputdata),每个Job都有对应的RDD依赖,而每个RDD依赖都有输入的数据,所以这里可以看作是由不同RDD依赖构成的batch,而batch就是Job;然后由Spark Engine得出一个又一个的结果。
参考:
[1] http://spark.apache.org/docs/1.6.2/streaming-programming-guide.html















 8780
8780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









