






lightGBM需要安装在64位系统上,如果是32位的系统,则无法解析lightGBM模型,因此有必要写一个函数可以直接解析lightGBM模型,方法是利用light.train的模型的dump_model方法产生json模型,然后利用上他,如前这个dump_model有些小bug,dump后feature_names会有些小差别,因此对齐进行替换保证feature_name一致。
1. 导入模块
from sklearn.datasets import make_classification
import lightgbm as lgb
import pandas as pd
import numpy as np
import json2.创建用于解析模型的类
#
class InferenceLightGBM(object):
'''
用于lightGBM dump_model产生的模型进行推断,以实现在没有安装lightGBM的电脑上进行解析模型
'''
def __init__(self,model_file=None,category_file=None):
with open(model_file,'r') as json_file:
self.model_json = json.load(json_file)
# 模型json 字典
with open(category_file,'r') as json_file:
# 分类特征序号
self.categories = json.load(json_file)
# print(self.categories)
self.feature_names = self.model_json['feature_names']
def predict(self,X):
'''
预测样本
'''
try:
columns = list(X.columns)
except :
print('{} should be a pandas.DataFrame'.format(X))
if self.model_json['feature_names'] == columns:
y = self._predict(X)
return y
else:
raise Exception("columns should be {}".format(self.feature_names),)
def _sigmoid(self,z):
return 1.0/(1+np.exp(-z))
def _predict(self,X):
'''
对模型树字典进行解析
'''
feat_names = self.feature_names
results = pd.Series(index=X.index)
trees = self.model_json['tree_info']
for idx in X.index:
X_sample = X.loc[idx:idx,:]
leaf_values = 0.0
# 对不同的树进行循环
for tree in trees:
tree_structure = tree['tree_structure']
leaf_value = self._walkthrough_tree(tree_structure,X_sample)
leaf_values += leaf_value
results[idx] = self._sigmoid(leaf_values)
return results
def _walkthrough_tree(self,tree_structure,X_sample):
'''
递归式对树进行遍历,返回最后叶子节点数值
'''
if 'leaf_index' in tree_structure.keys():
# 此时已到达叶子节点
return tree_structure['leaf_value']
else:
# 依然处于分裂点
split_feature = X_sample.iloc[0,tree_structure['split_feature']]
decision_type = tree_structure['decision_type']
threshold = tree_structure['threshold']
# 类别特征
if decision_type == '==':
feat_name = self.feature_names[tree_structure['split_feature']]
categories = self.categories[feat_name]
category = categories[str(split_feature)]
category = str(category)
threshold = threshold.split('||')
if category in threshold:
tree_structure = tree_structure['left_child']
else:
tree_structure = tree_structure['right_child']
return self._walkthrough_tree(tree_structure,X_sample)
# 数值特征
elif decision_type == '<=':
if split_feature <= threshold:
tree_structure = tree_structure['left_child']
else:
tree_structure = tree_structure['right_child']
return self._walkthrough_tree(tree_structure,X_sample)
else:
print(tree_structure)
print('decision_type: {} is not == or <='.format(decision_type))
return None
3.创建分类样本及训练模型
X,y = make_classification(n_classes=2,n_samples=200,random_state=100,n_features=10)
sex_list = ['Male','Female']
age_list = ['Youth','Adult','Elder']
X = pd.DataFrame(X,columns=['Col_{}'.format(i) for i in range(10)])
for i in range(200):
X.loc[i,'Sex'] = np.random.choice(sex_list)
for i in range(200):
X.loc[i,'Age'] = np.random.choice(age_list)
X['Sex'] = X['Sex'].astype('category')
X['Age'] = X['Age'].astype('category')
dtrain = lgb.Dataset(X,y,feature_name='auto',categorical_feature='auto',free_raw_data=False)booster_params = {
'boosting_type': 'gbdt',
'objective':'binary',
'learning_rate':0.1,
'num_leaves': 31,
'feature_fraction':0.8,
'bagging_fraction':0.8,
}
evals_result = {}
gbm = lgb.train(booster_params,
num_boost_round=200,
train_set=dtrain,
valid_sets=[dtrain],
valid_names=['tr'],
evals_result=evals_result,
verbose_eval=50,
early_stopping_rounds=10,
)
model_json = gbm.dump_model()
model_json['feature_names'] = list(dtrain.data.columns)
with open("sample_model.json",'w') as json_file:
json.dump(model_json,json_file,ensure_ascii=False)
cat_features = [column for column in dtrain.data.columns if hasattr(dtrain.data[column],'cat')]
category_dict = dict()
for cat_feature in cat_features:
category_dict[cat_feature] = {v:k for k,v in enumerate(list(dtrain.data[cat_feature].cat.categories))}
with open("category_feature_map.json",'w') as json_file:
json.dump(category_dict,json_file,ensure_ascii=False)4.测试对比
inf_lgb = InferenceLightGBM("sample_model.json","category_feature_map.json")
sample = dtrain.data
result_json = inf_lgb.predict(sample)
result_gbm = gbm.predict(sample )
diffrence = result_json.values - result_gbm
diffrence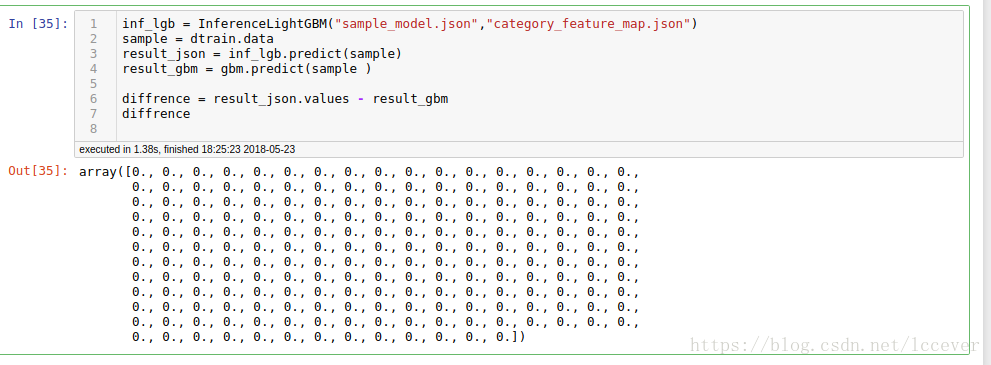















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









