









一、cpu的认识
计算器的硬件由cpu,内存和I/O三部分组成。CPU是我们机箱里面一块小芯片。它的职责就是负责运行指令,但是指令并非保存在cpu中而是保存在内存中,它的第一条指令放在地址为0xFFFFFFF0处。它会准备好中断向量表,并且根据中断向量表找到对应的指令,然后执行。
cpu运行的时候会出现进程,cpu它是有很多的寄存器的,比如PC主要用来存储内存地址,每次用来记住下一次要执行的地址。程序的流程被分为三种:顺序执行,循环,条件分支。顺序执行是按照指令记录在内存中的先后顺序依次的一种流程;循环为在特定的条件下反复的执行多次的一种流程。条件分支指的是判断若干个条件是否成立,举例出现另外的情况。
cpu访问的内存位置是会在一段时间内被经常访问的,并且该内存地址附近也会被很快访问到,这个称为程序的局部性原理。为了减少与内存的直接访问,它会经常访问的同一块区域的东西放在自己的寄存器中。寄存器是位于cpu与I/Ozho中的数据存储器。
二、进程
冯.诺依曼提出"存储程序"的思想,并将计算器从逻辑上分为五类:运算器,控制器,存储器,输入设备和输出设备。因为cpu在遇到读/写硬盘等的I/O操作时会空闲,为了提高效率,添加了进程的概念。正在运行的一个程序叫做进程。进程会保留cpu运行到的第XXX行的指令,cpu寄存器的值,打开的文件,并且记录使用的时间,等待的时间等等信息.。这些信息也被称为PCB(Processing Control Block)。内存里面有多个程序就可能操作同一个地址,内存中的数据就会被覆盖掉。在批处理系统中,所有的程序都是从0开始装载的,系统的程序指令中引用的是物理内存地址。为了解决覆盖出现静态重定位,为直接修改程序的指令。(例如给每个地址加上1000,MOV [345] AX变为MOV [1345] AX),接着发现会遇到内存紧缩就给cpu加了一个基址寄存器,用来保存起始地址。这样对于第一个程序这个地址值是0,第二个地址值就是地址加上基址寄存器的值才是真正的访问的地址值。
分时系统是通过将cpu的运行时间分成一小块一小块的时间,然后一个进程运行一段时间,把当前时间片段用完之后就让出cpu给其他进程使用。为了防止内存不够用,利用局部性原理将程序分块装载到内存。(局部性原理:分为时间局限性和空间局限性。时间局限性主要是讲如果程序中某条指令被执行,则不久之后该指令可能再次被执行;如果某个数据被访问,则不久之后该数据可能再次被访问。空间局部性讲得是一旦程序开始访问某个存储单元。)程序分块,分成一块一块,这样一小块,一小块被叫做页框,每个4kb,装载程序的时候按照页框的大小来进行。
厉害的前人发现一个程序是可以比内存大的,那么给一个比程序大的虚拟空间,程序的指令使用虚拟地址,在使用MMU(内存管理单元)映射到真实的物理内存地址。并且将虚拟地址也按照真实的物理内存的大小来分块(被称为页)。这样产生了一个页表,用来映射虚拟页面和物理页面。如果cpu访问一个还没有被映射到的物理内存页面就会产生缺页中断。然后由操作系统去硬盘中调取。之后的地址就变成了两部分-页号和偏移量,cpu的内存管理单元会进行地址的转换。cpu其实会将最常访问的页表项放到缓存里面。
为了程序的标准化和更加贴合程序的需求,一个程序会被代码段,数据段,堆栈段.。操作系统会记录每一个段的起始位置和结束位置,以及每一个段的保护位。
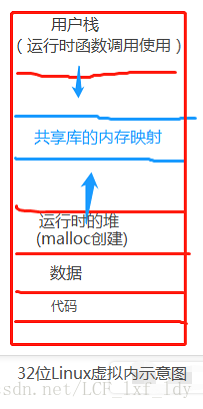
为了解决和I/O交互的高效性,使其能够同时对同一份文档进行操作,引入线程。把进程当成一个资源管理器,在里面进行几个轻量级的进程,被叫做线程,这些线程共享进程的所有资源(如地址空间,全局变量,文件源等等),一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。每个线程又拥有自己的函数调用栈,自己的态等。
三、硬盘
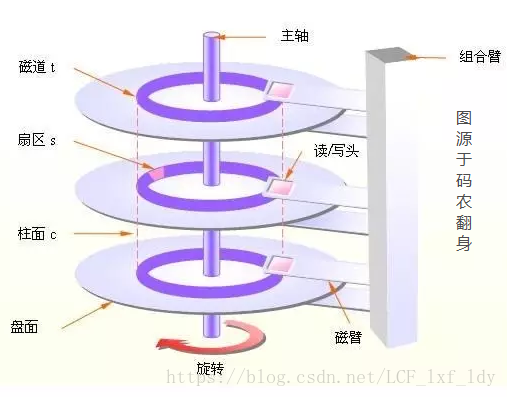
硬盘是一个在断电了可以存储文件的家伙,虽然速度比cpu,内存慢的多的多,但目前来说就是不可或缺的组件。由主轴、磁道、扇区,柱面,盘面,读写头,组合臂,磁臂组成。”寻到时间” 是指硬盘将磁头移到指定的柱面,每个磁盘来讲其实就是指定的磁道。“旋转时间”指的是移到指定的柱面之后还要旋转磁盘,让磁头指向指定的扇区。
硬盘主要是用来对目录和文件进行操作,采用索引式,指定某个磁盘块来存储某文件的属性和该文件所需要使用的磁盘块。该磁盘被称作iNode(索引节点),可以通过inode来找到该文件使用的所有磁盘块,这样顺序访问和随机访问都很快。当然,目录也是一样的,分配一个磁盘块作为iNode,存放着目录的属性和目录的磁盘块号。当需要读取/Dirs/File.txt文件,就要先读取根目录的iNode+根目录的磁盘块,然后是访问/Dirs的iNode+/Dirs的磁盘块,接着是/File.txt的INode+File.txt的磁盘块。当然没那么简单,我这里只是一笔带过,当需要删除文件的时候就要先删除目录中的文件,然后释放iNode到空闲的节点池中,最后释放磁盘块到空闲的磁盘池中。在操作之前还要记录要进行的事情,形成日志的记录,先把日志写入磁盘再开始真正的读/写等操作,等所有的步骤都搞定就可以擦除日志,减少磁盘的使用空间。
看着上面的圈圈有没有想到JJ的歌呢?有没有想到怎么去管理哪些空闲的磁盘呢?毕竟没有使用的磁盘块可是有N多的,佩服设计者将硬盘按照位图法将整个大磁盘分成无数由0和1 标记的小磁盘块,1表示已经被使用,0表示未被使用。这样有新文件的时候就可以拿着标记0的磁盘块去存储啦,而且每一个磁盘块只要1 bit很 小呢。
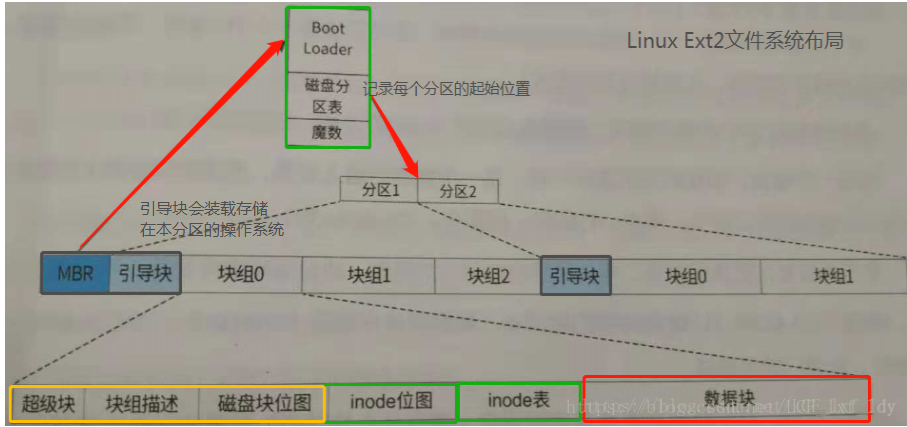
我只把Linux Ext2的文件系统拿出来晒了一下,NTFS、FAT、Ext3就想必你也知道大概的样子滴。嗯,硬盘有的由MBR(Master Boot Record)和各个磁盘分区组成。Master Boot Record 有引导块和磁盘分区表。每一个分区都有一个引导块,引导块是用来装载存储在本分区的操作系统的,当然不会每个分区都有操作系统。磁盘分区表是用来记录分区的初始位置并且标识那个磁盘分区是活动分区,让系统找到然后价值该分区的引导块接着执行。此表乃由64字节组成,其中的每个分区项占了16个字节,所以只有4个区,当然可扩展啦,你只要将其中的一个区设置为扩展分区,然后在里面划分成逻辑分区,就可以分很多个区啦!所以硬盘一般被分为主分区和扩展分区。
由上图可见,每个分区不仅有引导块还有很多块组。而块组中有包含着磁盘块总数,每个磁盘块大小、空闲块数、iNode数、超级块、块组描述、磁盘块位图、iNode位图,iNode表和数据块等。这就是简单的文件系统布局啦。














 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









