






MySQL慢查询(慢日志)
慢日志:就是将操作时间过长的SQL语句以及信息写入到日志中
如何定位慢日志:show profiles
开启慢日志
1.查看慢日志是否开启
show variables like '%query%' (ON是开启、OFF是关闭)
2.如何启用慢日志
set global slow_query_log='ON';
-- 持久性,通过配置文件设置
[mysqld]
log_output=FILE,TABLE
slow_query_log=ON
long_query_time=0.001
slow_query_log_file = /usr/local/mysql/mysql-8.0/logs/slow_query.log
#一次性的,通过命令设置, long_query_time 是时间阈值。为方便测试,此处认为超过0.001s的就属于慢查询
mysql> SET GLOBAL log_output = 'FILE,TABLE';
mysql> set GLOBAL slow_query_log=ON;
mysql> SET GLOBAL long_query_time = 0.001;
mysql> SET GLOBAL slow_query_log_file = '/usr/local/mysql/mysql-8.0/logs/slow_query.log';3.MySQL的慢日志有两种输出格式
table(推荐):以表格的形式存储在Mysql数据库的slow_log表中。
优点:便于查询和分析
file:慢日志以文件形式存储在磁盘上。
优点:便于传输和存储
show variables like '%log_output%';set global log_output=’FILE’;
set global log_output=’TABLE’;
set global log_output=’FILE,TABLE’;select * from mysql.slow_log;TRUNCATE TABLE mysql.slow_log;Redis慢日志和MySQL 慢日志的区别
MySQL Explain优化命令使用
truncate table 表名 //相当于删除表重新建了一个新表 自增id会从0开始
delete from student //删除数据不删表 自增id会保留
区别:1.id 2.delete可以恢复 truncate无法恢复
select_type列
- SIMPLE: 表示查询中不包含子查询或UNION操作符的简单查询。
- PRIMARY: 表示查询中包含子查询,并且该子查询处于顶层位置。
- SUBQUERY: 表示查询中的子查询,在FROM子句中被其他查询引用。
- DERIVED: 表示查询中的派生表,是从子查询结果中创建的临时表。
- UNION: 表示查询中使用了UNION或UNION ALL操作符进行多个查询结果的合并。(UNION会把重复的数据去除 UNION ALL展示所有数据,不会去重)
- UNION RESULT: 表示UNION操作后的结果集。
- DEPENDENT SUBQUERY: 表示子查询的结果取决于外部查询的值。
- DEPENDENT UNION: 表示UNION操作的结果取决于外部查询的输入。
- UNCACHEABLE SUBQUERY: 表示子查询的结果无法被缓存,通常是因为子查询中使用了非确定性函数或用户变量。
- DEPENDENT UNION RESULT: 表示外部查询对于UNION操作结果的依赖。
type列(重点)
"type"列用于表示访问表时所采用的访问类型。
- const: 表示通过索引只能匹配到一行数据。 explain select * from student where id = 1688
- eq_ref: 表示使用了等值连接(例如,使用主键或唯一索引连接表)。explain SELECT * FROM student s1 JOIN student s2 ON s1.id = s2.id WHERE s1.age = 25
- ref: 表示使用了非唯一索引进行查找,并返回匹配的多行或一行数据。 explain select * from student where name = '张68'
- range: 表示使用了索引进行范围查找,例如使用比较符(>, <, BETWEEN)或IN操作符。 explain select * from student where age < 1688
- index: 表示全索引扫描,也就是说用了某一个索引的全部, 通常发生在查询使用索引覆盖的情况下。explain select count(*) from student ;explain select sum(age) from student
- all: 表示全表扫描,即没有使用索引,需要遍历整个表进行查询。 explain select * from student
连接查询
左连接、右连接一定是使用小表连大表(效率高)

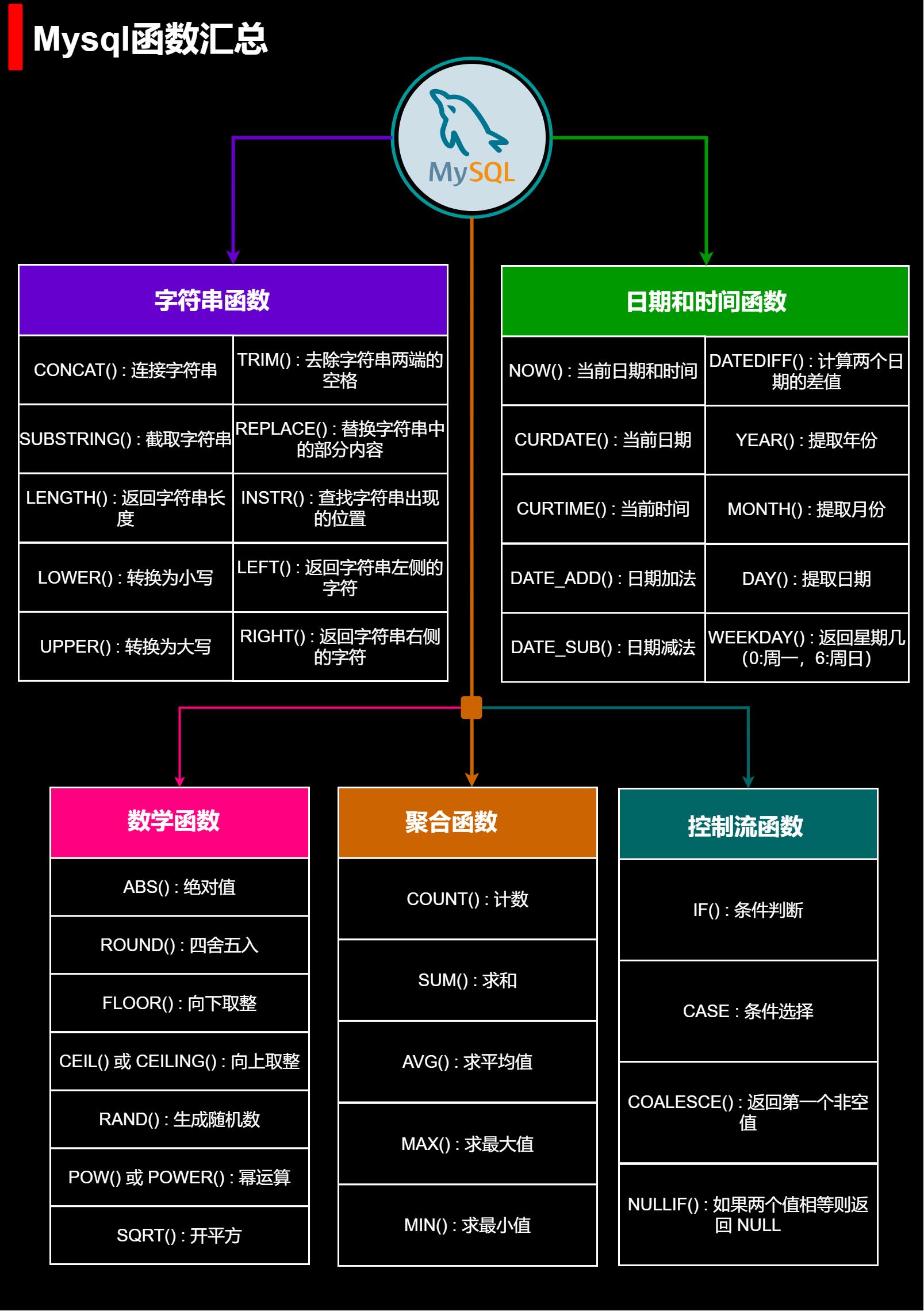
聚合函数
COUNT:统计行数量
SUM:获取单个列的合计值
AVG:计算某个列的平均值
MAX:计算列的最大值
MIN:计算列的最小值
SQL关键字
1.分页(limit)
查询学生表中数据,跳过100条,从第101条开始显示,取6 条
SELECT * FROM student limit 100,6; 2.倒序(order by......desc)
select * from user order by id desc limit 0 63.分组(group by)
根据性别分组并计算每个组的总数
SELECT sex , count(*) FROM student group by sex4.去重(distinct)
根据学生姓名去重
select distinct name FROM studentSQL Select 语句完整的执行顺序
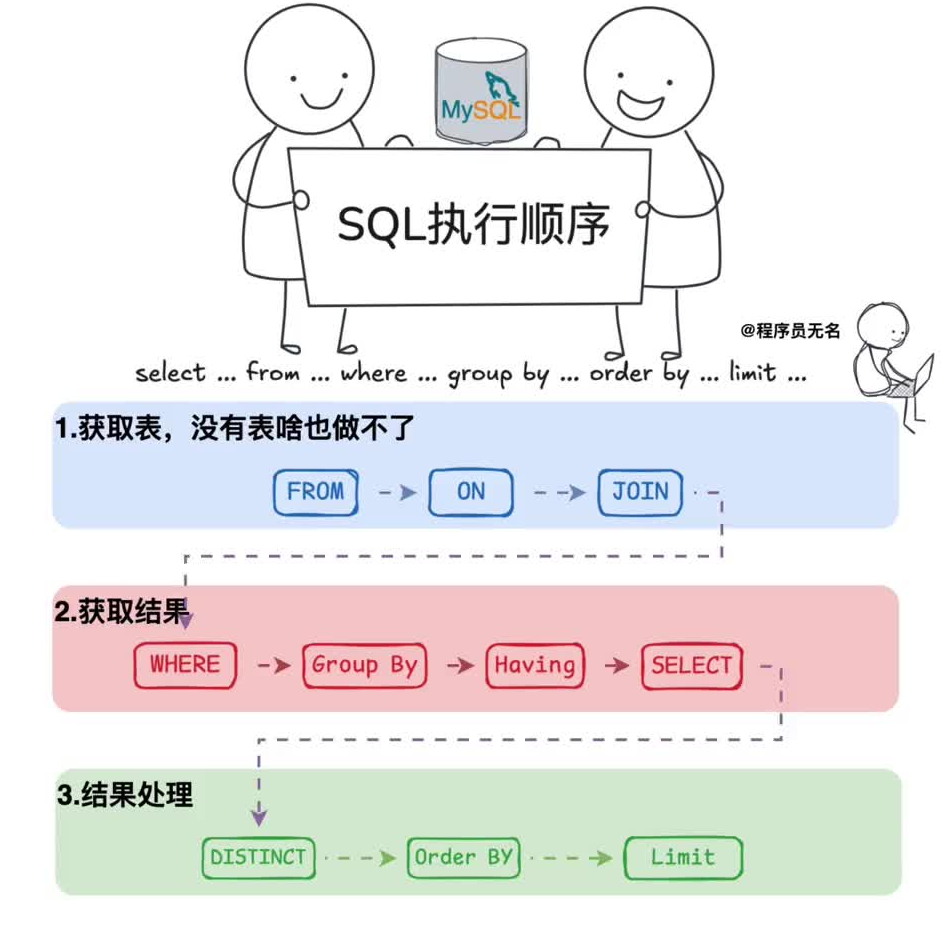
from...left join...on...where...group by...having..select...avg()/sum()...order by...asc/desc...limit...
数据库三范式
1.第一范式
原子性,列或属性不可再分
2.第二范式
①、每一行数据有唯一的主键
②、非主键字段必须依赖于主键字段 (解决行的冗余)
3.第三范式
非主键字段不依赖于其它非主键字段(解决列的冗余:比如订单明细中的商品名称)
存储引擎(高薪常问)
两种存储引擎:MyISAM、InnoDB
区别:
1.事务支持:MyISAM不支持事务 InnoDB支持事务
2.锁定机制(锁的粒度):MyISAM是锁表 InnoDB是锁行
3.外键支持:MyISAM不支持外键约束 InnoDB支持外键约束
4.并发性能:InnoDB要高于MyISAM
数据库事务
1.事务特性(ACID)
原子性:事务要么全部执行,要么就全部不被执行
一致性:事务执行前后的数据必须一致,例如转账,不管怎么转都是这些钱
隔离性:确保多个并发事务之间的数据一致性,即一个事务执行时不受其他事务的影响
持久性:事务一旦结束,数据就持久到数据库
undo_log AC(原子性和一致性) redo_log D(持久性)
2.事物的隔离级别
①读未提交:读到了别人未提交的数据,导致脏读
②读已提交(针对 update 或 delete):读的时候,别人提交了数据导致多次读的数据不一致,导致不可重复读
③可重复读(MySQL的默认隔离级别、针对 insert):事务A读之后,事务B又新增的多条数据,事务A再次读的时候就发现多了几条数据,导致了幻读
InnoDB 存储引擎通过多版本并发控制机制(MVCC)解决该问题
④可串行化:排队,性能低
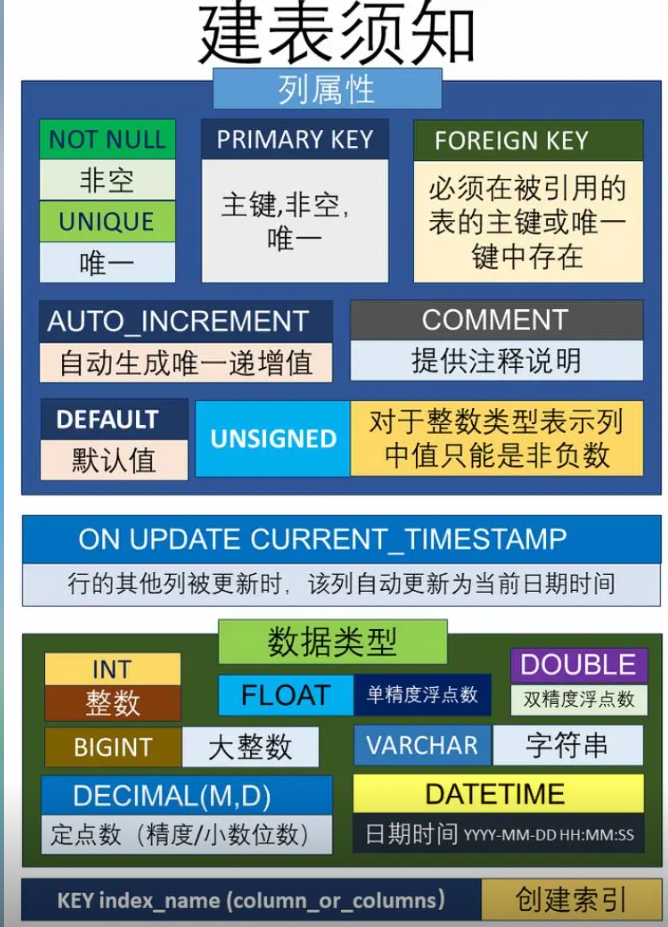
索引的概念和优点
空间换时间
优点:加快查询效率
缺点:1.占用内存空间 2.影响增删改,效率低下
索引的分类
1.普通索引:最基本的索引,没有限制(值可重复)
2.唯一索引:索引列的值必须唯一 (可以有空值)(会员表里的手机号、身份证)
3.主键索引:索引列的值必须是非空且唯一,一般用primary key来约束
4.联合索引:多个字段上的索引(手机号和密码、订单表中的会员id和状态、商品表中的分类和状态)
5.全文索引:一般不用 ES更好用
聚集索引和非聚集索引
区别:
B树与B+树的区别:
1.存储数据的位置:
①B树:数据存储在每一个节点中
②B+树:所有数据都存储在叶子节点中,非叶子节点仅包含索引信息。叶子节点包含了完整的数据和索引键
2.叶子节点之间的连接
①B树:叶子节点之间没有连接
②B+树:叶子节点之间通过指针相互连接,形成一个链表或循环链表,提高效率
如何避免索引失效
1.范围条件查询
2.索引列上操作(使用函数、计算等)导致索引失效
3.字符串不加引号,造成索引失效
4.尽量使用索引覆盖,避免select * ,这样能提高查询效率
索引覆盖: 通过索引就能找到你要的资料信息
回表:通过索引不能完全拿出你要的信息,需要通过数据表再次查询一次才能获取到
5.or关键字连接:只要有一个or条件没有索引就全表扫描
6.使用!=
7.like以通配符开头('%asda...')导致索引失效 最左匹配原则
8.排序列包含非同一个索引的列
数据库锁
1.行锁和表锁
行锁:访问数据库的时候,锁定整个行数据, 防止并发错误
表锁:访问数据库的时候,锁定整个表数据,防止并发错误
区别:
表锁:开销小,加锁快,不会出现死锁;锁定力度大,发生锁冲突概率高,并发度最低
行锁: 开销大,加锁慢,会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高
2.悲观锁和乐观锁
(1)悲观锁:顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会 block 直到它拿到锁。
传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
(2)乐观锁: 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。
乐 观 锁 适 用 于 多 读 的 应 用 类 型 , 这 样 可 以 提 高 吞 吐 量 , 像 数 据 库 如 果 提 供 类 似 于write_condition 机制的其实都是提供的乐观锁。
MySQL优化
1.定位执行效率慢的sql语句(慢查询日志)
根据Skywalking
根据sql慢日志
ELK
2.优化索引
①索引设计原则
- 对查询频次较高, 且数据量比较大的表, 建立索引.
- 索引字段的选择, 最佳候选列应当从 where 子句的条件中提取, 如果 where 子句中的组合比较多, 那么应当挑选最常用, 过滤效果最好的列的组合.
- 使用唯一索引, 区分度越高, 使用索引的效率越高,能建唯一索引就建唯一索引,或者普通索引
- 索引并非越多越好, 如果该表赠,删,改操作较多, 慎重选择建立索引, 过多索引会降低表维护效率. 不是越多越好
- 使用短索引, 提高索引访问时的 I/O 效率, 因此也相应提升了 Mysql 查询效率.
- 如果 where 后有多个条件经常被用到, 建议建立复合索引, 复合索引需要遵循最左前缀法则, N 个列组合而成的复合索引, 相当于创建了 N 个索引.
3.sql语句调优
- 根据业务场景建立复合索引只查询业务需要的字段,如果这些字段被索引覆盖,将极大的提高查询效率.
- 多表连接的字段上需要建立索引,这样可以极大提高表连接的效率.
- where 条件字段上需要建立索引, 但 Where 条件上不要使用运算函数,以免索引失效.
- 排序字段上, 因为排序效率低, 添加索引能提高查询效率.
- 优化 order by 语句: 在使用 order by 语句时, 不要使用 select *, select 后面要查有索引的列, 如果一条 sql 语句中对多个列进行排序, 在业务允许情况下, 尽量同时用升序或同时用降序.
- 优化 group by 语句: 在我们对某一个字段进行分组的时候, Mysql 默认就进行了排序,但是排序并不是我们业务所需的, 额外的排序会降低效率. 所以在用的时候可以禁止排序, 使用 order by null 禁用.
select age, count(*) from emp group by age order by null- 尽量避免子查询, 可以将子查询优化为 join 多表连接查询.
4.合理的数据库设计
遵循数据库三范式
保留冗余字段
增加派生列
分割表
数据表拆分:主要就是垂直拆分和水平拆分。
水平切分:将记录散列到不同的表中,各表的结构完全相同,每次从分表中查询, 提高效率。
垂直切分:将表中大字段单独拆分到另外一张表, 形成一对一的关系。
扩展















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









