







在上篇, 我们已经从使用 / 机制 / AOF 过程中涉及的辅助功能等方面简单了解了 Redis AOF。
这篇将从源码的形式, 进行深入的了解。
1 Redis 整个 AOF 主要功能
Redis 的 AOF 功能概括起来就 2 个功能
- AOF 同步: 将客户端发送的变更命令, 保存到 AOF 文件中
- AOF 重写: 随着 Redis 的运行, AOF 文件会不断变大, 在文件达到配置的条件时, 触发重写机制, 缩小文件的大小
2 AOF 同步 - 将变更命令写入到文件
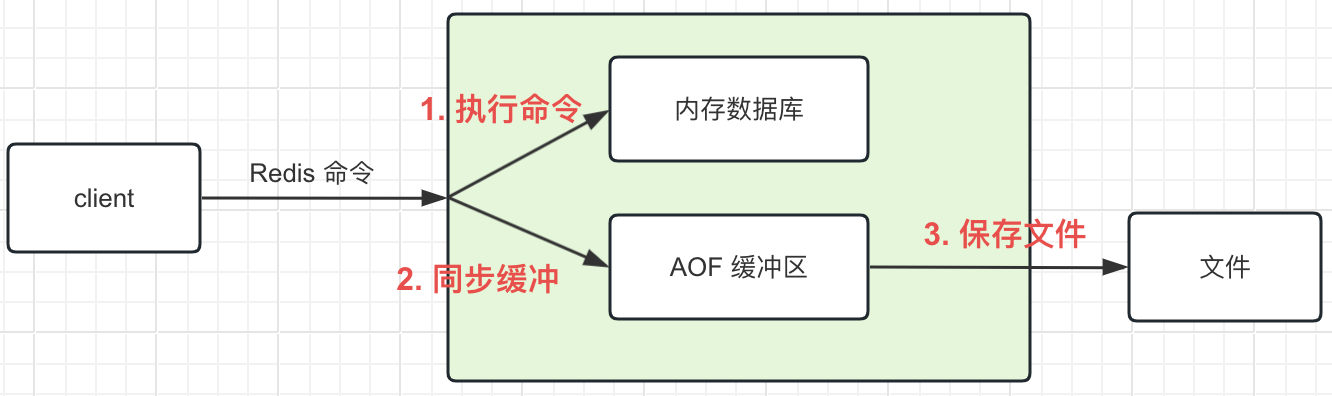
如图 Redis AOF 同步过程
- Redis 收到客户端发送的变更命令, 执行这个命令, 其间会修改在内存中数据库的数据
- Redis 将这个变更命令同步到一个 AOF 缓冲区
- Redis 将 AOF 缓冲区中的数据同步到 AOF 文件中
整个 AOF 同步过程, 我们拆成 2 个部分进行分析
- 命令写入 AOF 缓冲区
- AOF 缓冲区写入 AOF 文件
2.1 变更命令写入 AOF 缓冲区
2.1.1 前置知识梳理
在 AOF 同步过程中, 在客户端的变更命令和 AOF 文件中, 有一个 AOF 缓冲区的存在。
主要作用是在 AOF 过程中, 可以缓冲客户端发送的命令, 后面可以将这些命令一次性多条写入到 AOF 文件中。
其本身的定义很简单, 就是一个字符串, 也就是 sds。
struct redisServer {
// 很简单就是一个字符串, 后面的命令追加到这个字符串的后面
sds aof_buf;
}
客户端发送的变更命令转为 RESP 协议格式的字符串, 然后追加到已有的字符串后面即可, 这样就形成了一个命令的缓冲区。
2.1.2 逻辑触发入口
在 AOF 开启过程中, 客户端的命令会在执行完成后, 再保存一份到 AOF 缓冲区, 这个保存的入口就是在 Redis 执行所有命令的 call 函数中。
可以简单理解为, Redis 接收到了客户端的命令后, 就会调用 call 函数, call 函数里面会在命令执行前做一些处理, 然后执行命令, 最后在命令执行后再做一些处理。
call 函数的逻辑如下:
```c
/**
* Redis 命令执行过程
* @param c 客户端
* @param flags 一个标识, 通过二进制的形式封装了很多功能的标识, 比如当前命令是否需要 AOF 传播, 是否需要记录日志等
*/
void call(client *c, int flags) {
// 省略
// 执行对应的客户端命令
c->cmd->proc(c);
// 省略
// 入参的 flags 设置了 CMD_CALL_PROPAGATE 标识, 表示当前的命令需要传播
// 同时对应的客户端内部的标识不是 CLIENT_PREVENT_PROP (客户端的命令阻止传播)
if (flags & CMD_CALL_PROPAGATE && (c->flags & CLIENT_PREVENT_PROP) != CLIENT_PREVENT_PROP) {
// 省略
// 命令传播标识, 默认为 none, 即什么都不做
int propagate_flags = PROPAGATE_NONE;
// 命令导致数据脏了, 也就是修改了数据, 需要 aof 和 repl 传播 (repl 也就是主从复制, 同步给从节点)
if (dirty)
// 修改命令传播标识为需要 AOF 和 repl 传播
propagate_flags |= (PROPAGATE_AOF|PROPAGATE_REPL);
// 当前的客户端设置了需要强制同步传播, 更新命令传播标识为需要 repl 传播
if (c->flags & CLIENT_FORCE_REPL)
propagate_flags |= PROPAGATE_REPL;
// 当前的客户端设置了需要强制 AOF 传播, 更新命令传播标识为需要 AOF 传播
if (c->flags & CLIENT_FORCE_AOF)
propagate_flags |= PROPAGATE_AOF;
// CLIENT_PREVENT_REPL_PROP 这个标识表示当前的客户端的命令不需要 repl 传播
// 命令的执行过程 (上面的 proc 函数就是调用各个命令各自的执行逻辑), 内部可以通过 preventCommandPropagation() 等函数
// 给当前的客户端的 flags 设置 CLIENT_PREVENT_REPL_PROP 等标识, 也就是不需要主从复制的标识
if (c->flags & CLIENT_PREVENT_REPL_PROP || !(flags & CMD_CALL_PROPAGATE_REPL))
// 取消 命令传播标识 中的命令复制传播标识
propagate_flags &= ~PROPAGATE_REPL;
// 同上一步的取消主从复制传播标识
if (c->flags & CLIENT_PREVENT_AOF_PROP || !(flags & CMD_CALL_PROPAGATE_AOF))
// 取消 命令传播标识 中的 AOF 保存标识
propagate_flags &= ~PROPAGATE_AOF;
// 命令传播标识 不为 none, 且当前的命令不是模块命令
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
// 调用 propagate 进行命令的传播
propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags);
}
}
/**
* Redis 命令传播
* @param cmd Redis 命令
* @param dbid Redis 命令执行的数据库号
* @param argv Redis 命令的参数
* @param argc Redis 命令的参数个数
* @param flags 命令标识
*/
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc, int flags) {
// AOF 开启了, 同时命令传播标识为 需要 AOF 传播
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
// 将当前的命令保存到 AOF 缓冲区
feedAppendOnlyFile(cmd,dbid,argv,argc);
// 命令传播标识为 需要 repl 传播
if (flags & PROPAGATE_REPL)
// 将当前的没拿过来同步给从节点
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}
上面就是命令写入 AOF 缓冲区的触发入口, 而真正的命令写入 AOF 缓冲区 的过程的话就是 feedAppendOnlyFile 函数了。
2.1.3 具体的实现逻辑
feedAppendOnlyFile 函数的定义如下
/**
* 命令写入 AOF 缓冲区
*
* @param cmd Redis 命令
* @param dictid Redis 命令执行的数据库号
* @param argv Redis 命令的参数
* @param argc Redis 命令的参数个数
*/
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
// 缓存字符串, 用于临时存放命令的文本
sds buf = sdsempty();
robj *tmpargv[3];
// 命令写入的数据库和当前 AOF 选中的数据库不是配置的, 手动加入一段, select 对应的数据库
// 后面通过 AOF 文件恢复数据, 才能恢复到正确的数据库中
if (dictid != server.aof_selected_db) {
char seldb[64];
// 将当前命令选中的数据库号数 (0, 1, 2, 3) 写入到字符数组 seldb 中
snprintf(seldb,sizeof(seldb),"%d",dictid);
// 拼接出一个 select 数据库号 的语句, 这个语句是遵守 RESP 协议
buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n", (unsigned long)strlen(seldb),seldb);
// 修改 aof 当前的选中的数据库号数
server.aof_selected_db = dictid;
}
// expire / pexpire / expireat 这三个命令, 在 AOF 保存的时候, 会转为 expireat key 具体的过期时间 (单位毫秒) 的格式存入到 AOF 文件中
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand || cmd->proc == expireatCommand) {
// 转为过期对应的文本, 同时追加到 buf 中
buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]);
} else if (cmd->proc == setexCommand || cmd->proc == psetexCommand) {
// setnx / psetex 2 个命令拆分为 set 和 expireat 2 个命令进行处理
tmpargv[0] = createStringObject("SET",3);
tmpargv[1] = argv[1];
tmpargv[2] = argv[3];
// 往 buf 中追加 set 命令
buf = catAppendOnlyGenericCommand(buf,3,tmpargv);
// 创建的对象手动修改引用计数, 便于内存回收
decrRefCount(tmpargv[0]);
// 往 buf 中追加 expireat 命令, 同理会转弯为 expireat key 具体的过期时间 (单位毫秒) 的格式
buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]);
} else if (cmd->proc == setCommand && argc > 3) {
// set 命令同时参数大于 3 个, 也就是带有超时时间了
int i;
robj *exarg = NULL, *pxarg = NULL;
// 同样是, 先写入 set 命令
buf = catAppendOnlyGenericCommand(buf,3,argv);
// 计算后面的超时时间
for (i = 3; i < argc; i ++) {
if (!strcasecmp(argv[i]->ptr, "ex")) exarg = argv[i+1];
if (!strcasecmp(argv[i]->ptr, "px")) pxarg = argv[i+1];
}
serverAssert(!(exarg && pxarg));
// 根据计算出来的超时时间, 转为 RESP 协议的文本
if (exarg)
buf = catAppendOnlyExpireAtCommand(buf,server.expireCommand,argv[1], exarg);
if (pxarg)
buf = catAppendOnlyExpireAtCommand(buf,server.pexpireCommand,argv[1], pxarg);
} else {
// 其他的命令直接转为 RESP 协议的字符串进行追加
buf = catAppendOnlyGenericCommand(buf,argc,argv);
}
// 如果 AOF 功能开启中, 则将命令追加到 AOF 缓冲区中
// 后续在进入事件循环之前,这些命令会被保存到磁盘上,并向给对应的 client 回复执行结果
if (server.aof_state == AOF_ON)
// 3 个缓冲区中的一个, AOF 缓冲区, 保存变更的 Redis 命令
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
// 如果后台正在进行重写,那么将命令再追加一份到重写缓冲区中,以便我们记录重写时 AOF 文件和当前数据库的差异
if (server.aof_child_pid != -1)
// 这里不展开, 后面聊
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
}
变更命令到 AOF 命令缓冲区的过程到这里结束了, 接下来就是 AOF 缓冲区到 AOF 文件的过程了。
2.2 AOF 缓冲区写入 AOF 文件
2.2.1 前置知识梳理
1. write + fsync 函数
在操作系统中, 将应用的内存数据保存到真正的磁盘文件中, 实际需要通过 2 个函数
- write 函数, 将缓冲区中的数据写入到系统缓冲中, 一般是达到一定数量或者时间, 才会真正的写入到磁盘中, 单独的通过 write 函数, 无法 100% 保证数据的完整性
- fsync 函数, 一个比较耗时的操作, 可以立刻将系统缓冲中的数据写入到磁盘中
2. Redis 线程池 RIO
因为 fsync 函数比较耗时, 所以 Redis 维护了一个线程池 (Redis 内部叫做 BIO), 用来处理一些比较耗时的操作。
现在 Redis 这个线程池只处理 3 种任务类型
- close 函数, 也就是关闭文件
- fsync 函数, 立即刷新系统缓冲到磁盘
- Redis 内部的延长删除无用内存
所以在 AOF 缓存区写入到 AOF 文件中, 会先通过 write 将里面的数据写入到系统缓冲,
然后根据当前的 AOF 保存策略, 决定是否需要执行 fsync 函数和 fsync 的执行能否交给线程池。
3. AOF 文件同步策略
将 AOF 缓冲区中的数据写入到 AOF 文件, Redis 提供了 3 种策略
- no: 不进行同步, 由操作系统自己决定, 也就是只执行 write 函数
- always: 每次 write 后, 都立即执行 fsync
- everysec: 每次 write 后, 不会立即执行 fsync, 理论是每秒执行一次 fsync, 同时内部会将 fysnc 的执行交由线程池执行
4. everysec 的特殊性
同步策略为 everysec 时, 为了性能, fsync 函数的执行不是由 Redis 的主线程处理的, 而是通过向线程池提交一个 fsync 的任务, 由后台线程池执行。
那么就存在一种特殊情况
- 主线程在 flushAppendOnlyFile (AOF 缓存区写入到文件的函数) 完了 write, 提交了一个任务到后台线程, 假设此时的数据量很大, fsync 需要执行很长时间
- 主线程又执行到了 flushAppendOnlyFile 了, 而上一次的 fsync 函数还没执行完, Redis 会选择延迟执行, 将一个变量 aof_flush_postponed_start 设置为当前时间, 结束
- 后面主线程执行到定时任务时, 会判断这个变量是否大于 0, 是的话, 会再次执行 flushAppendOnlyFile, 也就是这次 AOF 同步延迟到定时处进行执行
- 但是延迟到定时任务处触发, 还是无法保证后台线程一定执行完了 fsync 了, 所以 flushAppendOnlyFile, 会根据当前的时间和变量里面存储的时间进行比较, 还是在 2 秒内, 不做任何处理, 而大于 2 秒, 立即执行 AOF 缓冲区写入文件的逻辑
理解了上面 3 个点, 下面 AOF 缓冲区的数据写入到 AOF 文件的过程就简单很多了。
2.2.2 逻辑触发入口
将缓冲区中的数据写入到文件的函数为 flushAppendOnlyFile, 而在 Redis 中会触发这个函数的有 5 个地方
- 通过命令动态地关闭 AOF 功能时, 会进行一次保存, 即动态的将 appendonly yes 设置为 appendonly no
- Redis 服务器正常关闭之前, 会执行一次
- 在 AE 事件循环中配置的 beforesleep 函数中就会调用一次, 这个是 AOF 功能的主要的保存入口
- Redis 的定时器函数 serverCron (默认为 100 毫秒执行一次), 会判断上次执行的 flushAppendOnlyFile 是不是延迟执行, 是会调一次 (这个延迟的行为, 在 flushAppendOnlyFile 中有分析)
- 最后一个就是定时器函数 serverCron (默认为 1000 毫秒执行一次), 判断上次 AOF 写入状态, 失败就执行一次
后面 2 种都是在 serverCron 中, 代码如下
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// 省略
// 上次的 AOF 写文件时, 没有执行, 而是将 aof_flush_postponed_start 设置为 true, 表示需要延迟处理, 则在这里进行判断出来
if (server.aof_flush_postponed_start)
flushAppendOnlyFile(0);
run_with_period(1000) {
// 上次的写文件失败了
if (server.aof_last_write_status == C_ERR)
flushAppendOnlyFile(0);
}
// 省略
}
2.2.3 具体的实现逻辑
整个 AOF 缓冲区的数据写入到 AOF 文件的实现函数就是 flushAppendOnlyFile, 定义如下
/**
* AOF 缓冲区数据写入文件
*
* 当持久策略被设置为 everysec, 实际上会由后台线程进行处理, 那么当前这次刷新写入时, 后台可能有线程还在写入, 所以这时的操作会延迟写入
*
* @param force 1:表示无视后台的 fsync, 直接写入, 0: 表示可以延迟, 一般 AOF 过程都是 0
*/
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
// 缓冲区没有数据, 正常缓冲区没有数据, 就可以结束了
// 但是 Redis 在里面对一个极端情况的兼容, 有点绕, 有兴趣可以了解一下, 也可以跳过
if (sdslen(server.aof_buf) == 0) {
// 即使在缓冲区数据为空的情况下, 也需要检查一次是否需要执行 fsync 操作 (fsync: 将缓冲区数据写回磁盘)
// 因为在 everysec 模式下, fsync 仅在 AOF 缓冲区不为空时调用
// 如果在一秒钟调用一次的 fsync 之前, 用户停止了写命令 (stop write commands, 也就是没有发送任何变更的命令), 将会导致缓冲中的数据无法及时刷新
// 这种情况的分析, 个人的猜测在后面的备注中进行分析
// 1. 配置的持久化策略为 everysec 每秒执行一次 fsync
// 2. 已经同步到磁盘的内容大小 != 当前 AOF 文件的内容大小
// 3. 当前的时间 > 上次 AOF fsync 的时间
// 4. 当前没有请求 fsync 的任务在线程池中
// 4 个条件都符合, 尝试进行 fsync, 否则直接返回
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && server.aof_fsync_offset != server.aof_current_size
&& server.unixtime > server.aof_last_fsync && !(sync_in_progress = aofFsyncInProgress())) {
goto try_fsync;
} else {
return;
}
}
// 持久策略为每秒 fsync 一次, 判断后台的线程池是否有线程在执行 fsync
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
// aofFsyncInProgress 返回值为 true, 表示当前有 BIO 线程在执行 fsync
sync_in_progress = aofFsyncInProgress();
// 持久策略为每秒 fsync 一次, 同时不需要强制写入文件
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
// 当前有 BIO 线程在执行 fsync
if (sync_in_progress) {
// 0 表示当前没有延迟执行
if (server.aof_flush_postponed_start == 0) {
// 当前有后台线程在执行 fsync, 那么先延长一下, 设置 aof_flush_postponed_start 为当前时间, 然后结束, 后面定时器执行到了, 判断这个值大于 0,
// 重新进入 flushAppendOnlyFile 函数进行 AOF 缓冲区保存, 也就是延迟执行
server.aof_flush_postponed_start = server.unixtime;
return;
// 如果之前有设置延迟执行, 然后又进入到这个函数(大部分场景是定时器触发), 此次后台还是有线程在执行 fsync,
// 但是当前时间和上一次设置的延迟时间小于 2 秒, 可以接受, 暂时还是不做任何处理
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
// 直接返回
return;
}
// 上面的情况分析
// 第一次执行完 flushAppendOnlyFile 后, 但是数据量很大, 导致 fsync 很耗时,
// 那么第二次 flushAppendOnlyFile 极端情况需要在 2 秒后才会进行
// 延迟 fsync 的次数 + 1
// 到了这一步表示线程池中有请求 fsync 的任务, 同时上次延迟距离当前时间超过 2 秒了
server.aof_delayed_fsync++;
// 记录日志
serverLog(LL_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.");
}
}
// 下面的 latency 开头的函数基本都是延迟统计相关的, 不影响具体的逻辑, 可以跳过
latencyStartMonitor(latency);
// 步骤 BB, 后面备注分析在缓存区没有数据还需要执行 fsync 用到
// 调用 write 函数将缓冲区中的数据写入到文件 (此时还在系统级缓存, 还没写入到磁盘, 可以通过 fsync 强制刷入到磁盘)
nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
latencyEndMonitor(latency);
if (sync_in_progress) {
latencyAddSampleIfNeeded("aof-write-pending-fsync",latency);
} else if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) {
latencyAddSampleIfNeeded("aof-write-active-child",latency);
} else {
latencyAddSampleIfNeeded("aof-write-alone",latency);
}
latencyAddSampleIfNeeded("aof-write",latency);
// 将缓冲区中的数据 write 到系统后, 可以把延迟执行设置为 0
server.aof_flush_postponed_start = 0;
// 写入到系统的数据长度不等于当前 AOF 缓冲区的长度, 进入异常处理
if (nwritten != (ssize_t)sdslen(server.aof_buf)) {
static time_t last_write_error_log = 0;
int can_log = 0;
// 上次记录错误日志的时间距离现在 30 秒了, 需要再记录多一次移除日志
if ((server.unixtime - last_write_error_log) > AOF_WRITE_LOG_ERROR_RATE) {
can_log = 1;
last_write_error_log = server.unixtime;
}
// -1, 没有写入任何数据, 就直接失败了
if (nwritten == -1) {
// 写入失败
if (can_log) {
serverLog(LL_WARNING,"Error writing to the AOF file: %s", strerror(errno));
// 保存错误到 redisServer 的 aof_last_write_errno
server.aof_last_write_errno = errno;
}
} else {
// 大于 -1 但是不等于缓冲区的大小, 写入成功了一部分,
if (can_log) {
// 记录日志
}
// 将 AOF 的文件大小修改为 aof_current_size 的大小, 返回值 0 成功, -1 失败
// 也就是恢复回写入前的文件内容
if (ftruncate(server.aof_fd, server.aof_current_size) == -1) {
// 记录日志
} else {
// 设置为 -1, 表示 AOF 中没有写入成功的部分数据
nwritten = -1;
}
server.aof_last_write_errno = ENOSPC;
}
// 同步策略为 always
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
// 这种情况无法处理了, 已经告知客户端写入成功了, 但是当前写入失败了, 直接退出程序。
serverLog(LL_WARNING,"Can't recover from AOF write error when the AOF fsync policy is 'always'. Exiting...");
exit(1);
} else {
// 设置上一次写入状态为异常, 在定时器中会判断这个状态, 再次触发 flushAppendOnlyFile
server.aof_last_write_status = C_ERR;
if (nwritten > 0) {
// 更新当前 aof 文件的大小 = 当前的大小 + 写入部分的大小, 同时将缓冲区中这部分大小的数据移除
// 表示这部分写入成功了, 剩余部分下次调用继续
server.aof_current_size += nwritten;
sdsrange(server.aof_buf,nwritten,-1);
}
return;
}
} else {
// 写入成功
if (server.aof_last_write_status == C_ERR) {
// 最新最近一次写的状态为 C_OK
server.aof_last_write_status = C_OK;
}
}
// 更新当前 AOF 文件的大小
server.aof_current_size += nwritten;
// 如果当前 AOF 缓冲区足够小,小于 4K,那么重用这个缓存,否则释放 AOF 缓冲区, 然后重新分配一个
if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) {
sdsclear(server.aof_buf);
} else {
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
try_fsync:
// no-appendfsync-on-rewrite (正在重写, 不执行 fsync) 被设置为 yes
// 正在执行 后台保存 RDB 或者 后台保存 AOF, 直接返回
if (server.aof_no_fsync_on_rewrite && (server.aof_child_pid != -1 || server.rdb_child_pid != -1))
return;
// 持久策略为 always
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
latencyStartMonitor(latency);
// 宏定义, 在 Linux 系统中执行 fdatasync 函数, 其他系统执行 fsync 函数
redis_fsync(server.aof_fd);
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
// 更新 aof_fsync_offset 为当前的 AOF 文件大小
server.aof_fsync_offset = server.aof_current_size;
// 上次 fsync 为当前的时间
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC && server.unixtime > server.aof_last_fsync)) {
// 持久策略为 everysec 同时当前的时间大于上次 fsync 的时间
// 步骤 AA, 后面备注分析在缓存区没有数据还需要执行 fsync 用到
// 当前没有请求 fsync 的任务在线程池中
if (!sync_in_progress) {
// 提交一个任务, 最终就是一个后台线程执行一次 redis_fsync 函数
aof_background_fsync(server.aof_fd);
// 更新 aof_fsync_offset 为当前的页的大小
server.aof_fsync_offset = server.aof_current_size;
}
server.aof_last_fsync = server.unixtime;
}
}
// 返回 true, 如果当前已经有一个请求 fsync 的任务了, 返回 true
int aofFsyncInProgress(void) {
return bioPendingJobsOfType(BIO_AOF_FSYNC) != 0;
}
// Redis 的 BIO 更像是一个线程池, 下面的方法是提交一个任务到对应任务链表
// 同时会尝试唤醒线程池对应的线程去执行任务, 具体的实现可以看一下 bio.c 这个文件
void aof_background_fsync(int fd) {
bioCreateBackgroundJob(BIO_AOF_FSYNC,(void*)(long)fd,NULL,NULL);
}
// 调用 write 函数, 写入数据到文件
ssize_t aofWrite(int fd, const char *buf, size_t len) {
ssize_t nwritten = 0, totwritten = 0;
// 调用 write 函数将 server.aof_buf 中的数据写入到系统级缓存中
while(len) {
nwritten = write(fd, buf, len);
if (nwritten < 0) {
if (errno == EINTR) {
continue;
}
return totwritten ? totwritten : -1;
}
len -= nwritten;
buf += nwritten;
totwritten += nwritten;
}
// 写入的内容大小
return totwritten;
}
上面就是一个将 AOF 缓冲区中的数据写入到系统的过程, 一个正常的流程如下:
- 如果当前同步策略是每秒 fsync, 同时有 BIO 线程在后台处理 fsync 了, 设置 redisServer 的延迟 AOF 时间 aof_flush_postponed_start 为当前时间, 等待下次执行, 结束
- 调用 write 把 AOF 缓冲区的数据写入到系统级缓存中
- 获取写入到系统级缓存的数据长度
- 写入到系统级缓存的数据长度不等于 AOF 缓冲区的数据长度, 进行异常处理, 结束
- 长度一样, 更新 redisServer 的最新 AOF 写入状态 aof_last_write_status 为成功状态
- 更新当前 AOF 文件的大小 aof_current_size 为 aof_current_size + 最新写入的数据长度
- 清空 AOF 缓冲区的数据
- 如果配置的持久策略为 always, 立即执行 fsync
- 如果配置的持久策略为 everysec, 当前的时间大于上次 fsync 的时间, 同时线程池中没有 fsync 任务, 提交一个到线程池, 更新当前的 fsync 写入量的 aof_fsync_offset 为当前的 AOF 文件大小
- 更新最新的 AOF fsync 时间为当前时间
备注:
在上面的代码中, 在 AOF 缓冲区没有数据的情况下, 还会进行条件的判断后, 尝试进行 fsync 的操作, 需要进行这种情况的情景, 个人猜测如下
- 第一次走入这个方法, sync_in_progress 为 false, 走到下面的步骤 AA, 开启了一个后台 BIO 线程进行 fsync, 假设当前的 aof_fsync_offset = aof_current_size = xx
- 第二次走入到这个方法, sync_in_progress 为 true, 走到步骤 BB 时, 后台的 BIO 线程已经完成任务, 结束了, 所以这时候 sync_in_progress 理论应该为 false 了, 但是此时还是为 true
- 第二次同样走到了下面的步骤 AA, 这是 aof_current_size 已经是追加到了最新的大小了, 设为 yy, 因为 sync_in_progress 为 true, aof_fsync_offset 还是 xx, 最新的数据已经 write 到系统级缓存了, 但是没有 fsync
- 如果这时候用户没有在向 Redis 中进行更改命令, AOF 缓冲区就会一直为空, 无论走几次到这个方法, 都不会走到下面的逻辑, 这时候就存在 AOF 文件中的数据和真正的数据有偏差
- 所以在 AOF 缓冲区为空的情况下, 还要进行多一次判断, 进行 fsync
3 AOF 重写 - AOF 文件瘦身
整个 AOF 重写过程, 会稍微复杂一些, 因为涉及到 2 个进程。
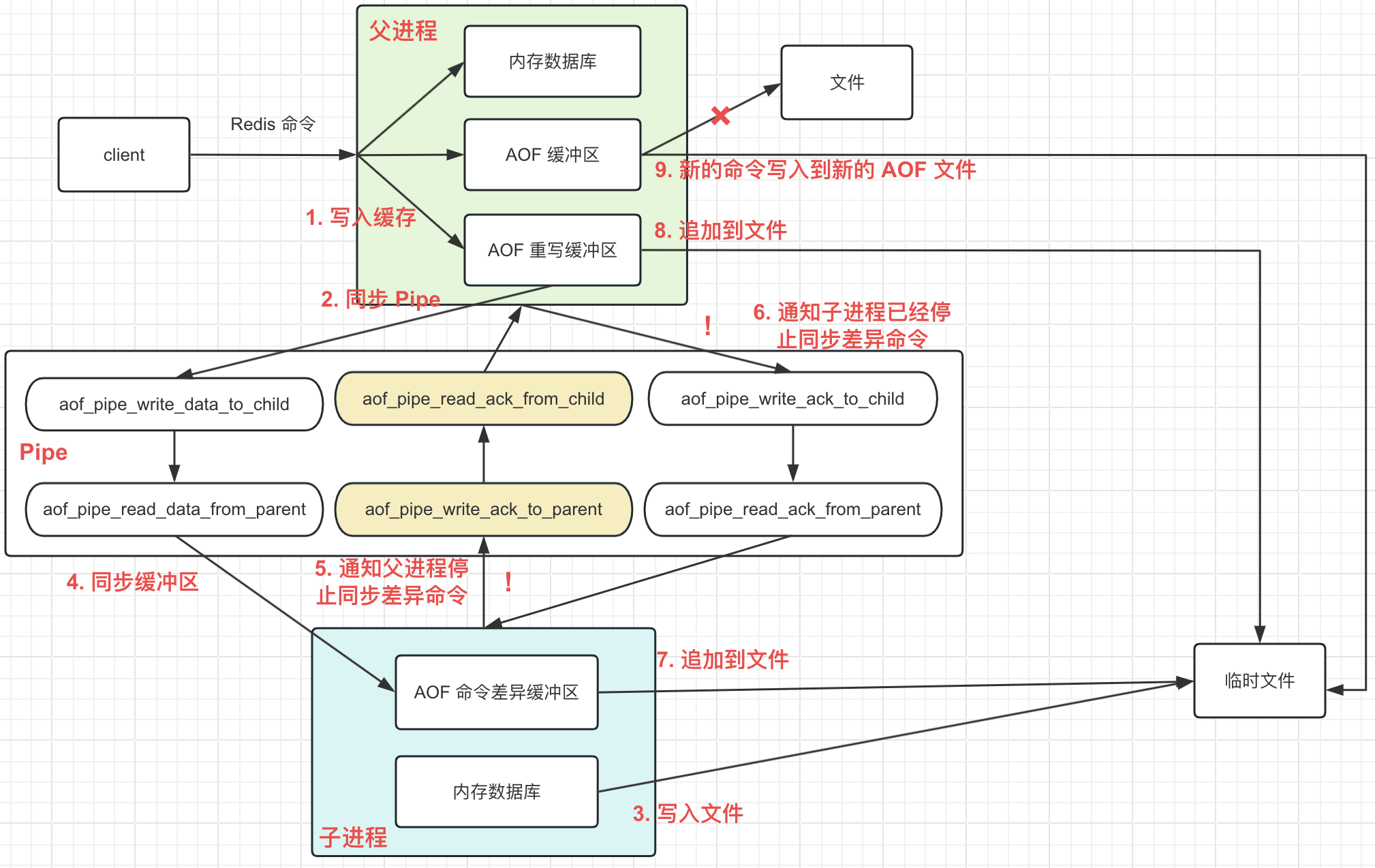
如图是整个 AOF 重写过程
当 Redis 服务端发现整个 AOF 文件达到配置的重写条件了
- 立即创建出 6 个 Pipe 通道 (这些通道主要用于父子进程的通信)
- 父进程通过 fork 操作, 创建出子进程 (fork 可以理解为克隆, 此时子进程和父进程完全一样, 拥有父进程所有数据的快照), 由子进程会执行 AOF 重写的过程
fork 操作后, 父进程将继续运行
- 在收到客户端的变更命令后, 处理完同步到内存数据库中, 写入到 AOF 缓冲区, 此时还会写入一份到 AOF 重写缓冲区中
- 后面不断将 AOF 重写缓冲区中的数据通过 Pipe 通道同步给子进程
备注: 在子进程重写的这段过程, 命令还是会写入到 AOF 缓冲区中, 并同步写入 AOF 文件中
fork 出来的子进程, 此时不会有任何的数据变更了
- 根据自身内存数据库, 将里面的数据写入到一个新的 AOF 临时文件
- 在将内存数据写入到 AOF 临时文件中, 会按照每写入 10m 数据到文件时, 就通过 Pipe 将父进程同步过来的差异命令保存到自身的 AOF 子进程差异缓冲区中
- 当内存数据库中的数据全部写入到 AOF 临时文件后, 通过 Pipe 向父级发送一个 !, 通知父进程停止同步差异命令
- 父进程收到子进程发送过来的 !, 会停止向子进程同步差异命令, 并通过 Pipe 发送一个 !, 进行响应
- 子进程收到父进程发送过来的 ! 后, 会将自身的 AOF 子进程差异缓冲区 中的数据写入到 AOF 临时文件中
备注: 此时子进程任务完成
父进程运行过程中, 会不断检查 AOF 子进程的状态
- 当发现子进程已经停止了, 父进程进行将 AOF 重写缓冲区中的省略的数据写入到 AOF 临时文件中
- 写入完成后, 将 AOF 临时文件替换掉旧的 AOF 文件, AOF 重写过程完成, 后面收到的 Redis 命令, 会写入到新的 AOF 文件中
至此, 这个 AOF 重写过程就完成了。
将上面的过程, 再概括一下就是
- fork 出来的子进程, 拥有了和父进程一样的内存数据, 子进程先把这些内存数据写入到一个 AOF 临时文件
- 父进程在子进程同步内存数据到文件的过程中, 还在处理客户端请求, 将这段时间的变更命令保存下来
- 子进程内存数据同步到临时文件完成了, 将父进程这段时间保存下来的变更命令拿过来, 继续追加到 AOF 临时文件中
- 父进程在子进程将变更命令追加到临时文件的过程中, 继续把这段时间的变更命令保存下来
- 子进程将第一次同步过来的的变更命令追加到 AOF 临时文件后, 完成任务, 结束
- 父进程在子进程结束后, 自己剩余的变更命令同步到 AOF 临时文件,这个 AOF 临时文件就是完整的数据了
3.1 前置知识梳理
3.1.1 AOF 重写过程中涉及到的 Pipe 通道
整个 AOF 重写的过程是需要父子 2 个进程共同合作完成的, 那么这个过程就涉及到通讯, 在 Redis 中, 通讯的方式是通过 Pipe 管道来实现的。
从 Redis 对 Pipe 的使用可以得出下面的特点,
- Pipe 需要两两配合使用, 比如 A 和 B 2个 Pipe 组成一对, 父进程向 A Pipe 写入数据, 子进程可通过 B Pipe 读取到父进程同步过来的数据
- 一对 Pipe 组合的数据同步方向是不可逆的, 父进程通过 A Pipe 同步给子进程, 子进程没法反着过来通过 B Pipe 同步数据给父进程
从上面的流程图中可以看到有 6 个 Pipe, 共 3 组
- aof_pipe_write_data_to_child 和 aof_pipe_read_data_from_parent, 主要是父进程将子进程重写过程中产生的变更命令同步给子进程
- aof_pipe_write_ack_to_parent 和 aof_pipe_read_ack_from_child, 主要是用于子进程通知父进程停止同步变更命令
- aof_pipe_write_ack_to_child 和 aof_pipe_read_ack_from_parent, 主要用于父进程响应子进程的停止同步变更命令的请求
3.1.2 AOF 重写过程涉及到的 2 个缓冲区
1. AOF 重写缓冲区
AOF 重写缓冲区, 主要是在 AOF 重写过程中, 缓冲这段时间修改了内存数据的命令。
fork 出来的子进程, 根据自身的内存数据库快照, 生成一个新的 AOF 临时文件后。
生成的过程中, 父进程还在处理客户端的命令, 这些命令会导致数据变更, 需要把这些命令追加到 AOF 临时文件, 才是最终完整的数据。
而这个缓存区中就是父进程保存子进程重写过程中, 导致数据变更的命令。
那么这个缓冲区是什么样的呢?
struct redisServer {
// 重写缓存链表, 当前正在进行重写时, 会把命令写入到这个列表, 待重写完成后, 再追加到文件
list *aof_rewrite_buf_blocks;
}
/**
* AOF 重写缓存列表的节点定义
*/
typedef struct aofrwblock {
// 下面的缓存数组已经使用的空间和剩余的空间
unsigned long used, free;
// 用来缓存需要写入到文件的命令文本内容, 当数组所有空间使用完了, 会新建一个新的缓存节点
// AOF_RW_BUF_BLOCK_SIZE = 1024*1024*10
char buf[AOF_RW_BUF_BLOCK_SIZE];
} aofrwblock;
一个链表, 链表的节点就是一个 10kb 的字节数组, 即每个节点可以存储 10kb 的数据, 写满了就再新建一个节点。
这个缓冲区的作用和写入的时机, 实际在上面的 AOF 重写同步中已经有遇到了, 这里对数据写入的时机和逻辑进行一个代码级别的整理。
/**
* 在上面 AOF 命令写入缓冲区中, 可以知道, 在执行命令执行后, 会有个命令传播的逻辑, 里面会调用到这个 feedAppendOnlyFile 函数
* 这个函数会判断当前是否正在进行 AOF 重写, 如果是, 会将命令追加一份到 AOF 重写缓冲区中, 保存子进程重写过程中, 主进程这段时间处理的变更命令
*/
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
// 省略
// 如果后台正在进行重写,那么将命令追加到重写缓冲区中,以便我们记录重写时 AOF 文件和当前数据库的差异
if (server.aof_child_pid != -1)
// 这里就是将变更命令写入到 AOF 重写缓冲区
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
}
/**
* @param s: 需要写入的数据
* @param len: 需要写入的数据长度
*/
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
// 获取重写缓冲区列表
listNode *ln = listLast(server.aof_rewrite_buf_blocks);
aofrwblock *block = ln ? ln->value : NULL;
while(len) {
// 重写缓冲列表已经有数据了
if (block) {
// 当前列表的最后一个节点需要分配多少的长度出来
// 剩余的空间 < 需要的空间 ? 剩余多少分配多少 : 存储内容需要的长度
unsigned long thislen = (block->free < len) ? block->free : len;
if (thislen) {
// 当前的节点空间还有剩余的
memcpy(block->buf+block->used, s, thislen);
block->used += thislen;
block->free -= thislen;
s += thislen;
// 计算出还需要多少空间
len -= thislen;
}
}
// len > 0, 说明还需要空间, 但是当前的节点没有空间了, 需要新建一个节点
if (len) {
// 还需要空间
int numblocks;
// 分配以新的缓存节点, 同时放到列表的尾部
block = zmalloc(sizeof(*block));
block->free = AOF_RW_BUF_BLOCK_SIZE;
block->used = 0;
listAddNodeTail(server.aof_rewrite_buf_blocks,block);
// 获取当前的重写缓存列表的节点长度
numblocks = listLength(server.aof_rewrite_buf_blocks);
// 加 1 后是 10 的倍数
if (((numblocks+1) % 10) == 0) {
// 记录日志
int level = ((numblocks+1) % 100) == 0 ? LL_WARNING : LL_NOTICE;
serverLog(level,"Background AOF buffer size: %lu MB", aofRewriteBufferSize()/(1024*1024));
}
// 回到循环的头部, 再来一次循环
}
}
// 注册一个文件事件, 用来将缓冲区的数据写入到 aof_pipe_write_data_to_child 中, 然后在 Pipe 的作用下, 可以同步到 aof_pipe_read_data_from_parent
// 只需要注册一个就可以了
if (aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) {
aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child, AE_WRITABLE, aofChildWriteDiffData, NULL);
}
}
// 把当前的 AOF 缓冲区同步到 aof_pipe_write_data_to_child, 在 Pipe 的作用下间接同步到 aof_pipe_read_data_from_parent
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
listNode *ln;
aofrwblock *block;
ssize_t nwritten;
UNUSED(el);
UNUSED(fd);
UNUSED(privdata);
UNUSED(mask);
while(1) {
// 获取头节点
ln = listFirst(server.aof_rewrite_buf_blocks);
block = ln ? ln->value : NULL;
// 停止同步或者没有 AOF 缓冲区时, 删除这个事件
// 后续如果停止同步的标识还是 true, 又有缓冲区数据, 在 aofRewriteBufferAppend 会重新新建一个这个事件, 可以重新开始执行
if (server.aof_stop_sending_diff || !block) {
// 删除这个事件
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child, AE_WRITABLE);
return;
}
if (block->used > 0) {
// 把 block 的数据写入到 aof_pipe_write_data_to_child
nwritten = write(server.aof_pipe_write_data_to_child, block->buf, block->used);
if (nwritten <= 0) return;
memmove(block->buf,block->buf+nwritten,block->used-nwritten);
block->used -= nwritten;
block->free += nwritten;
}
if (block->used == 0)
listDelNode(server.aof_rewrite_buf_blocks,ln);
}
}
看起来很长的一段逻辑, 实际概括起来就 2 个步骤。
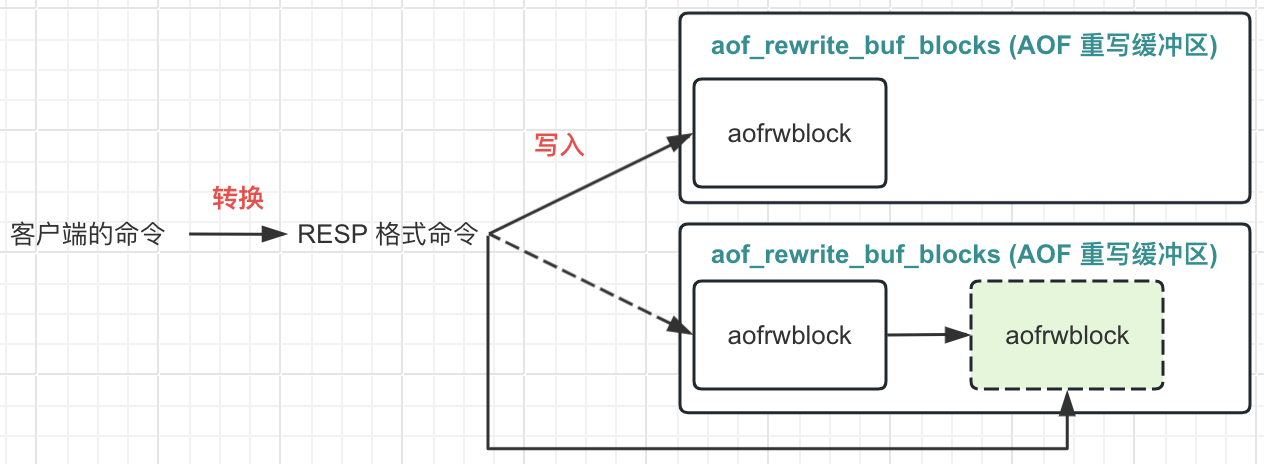
- 将客户端的命令转为 RESP 协议格式的字符串
- 将 RESP 协议格式的字符串写入到 AOF 缓冲区中
2.1 写入的 AOF 缓冲区本质是一个链表, 尾节点还有空间, 那么尾结点能写多少就写多少
2.2 尾节点写完了, 就重新分配一个节点, 然后继续写入, 直到现在的命令字符串写完
2. AOF 子进程差异缓冲区
通过上面的简单流程, 我们知道: 整个 AOF 重写过程是在通过 fork 函数, 克隆出一个子进程进行操作。
因为正常整个 Redis 的内存会很大, 重写的时间会很长, 如果把这个过程放在父进程, 过程会影响到 Redis 的正常运行,
同理, 整个 Redis 的内存很大, 所以整个 AOF 重写的过程不会很快, 那么这段时间产生的新的变更命令 (存放在上面的 AOF 重写缓冲区), 可能也会很多。
如果这些命令追加到新的 AOF 文件中放在父进程, 也可能会影响到 Redis 的正常运行。
所以 Redis 重写过程中,会通过 Pipe 通道, 将这些命令同步给子进程自己的一个缓存区。
子进程在根据内存数据库重写完成后, 随便将这个缓冲区的数据追加到新的 AOF 文件中, 即把这段重写过程中产生的变更命令还是让子进程来处理。
而这个缓冲区就是 AOF 子进程差异缓冲区,定义如下
struct redisServer {
// AOF 子进程差异缓冲区
sds aof_child_diff;
}
同样是一个字符串 sds。
子进程通过 Pipe 将 AOF 重写缓存区的数据同步到这个 AOF 子进程差异缓冲区的逻辑如下:
// 将 aof_pipe_read_data_from_parent 中的数据读取到 server.aof_child_diff 中
ssize_t aofReadDiffFromParent(void) {
char buf[65536];
ssize_t nread, total = 0;
// 将 aof_pipe_read_data_from_parent 中的数据读取到 buf 中
while ((nread = read(server.aof_pipe_read_data_from_parent,buf,sizeof(buf))) > 0) {
// 把 buf 的数据拼接到 aof_child_diff 中
server.aof_child_diff = sdscatlen(server.aof_child_diff,buf,nread);
total += nread;
}
return total;
}
备注: 这里还有个问题, 子进程将重写过程 AOF 变更命令追加到 AOF 文件的过程中, 还是会产生新的变更命令 (此时还是存放在 AOF 重写缓冲区中),
Redis 将这段时间的变更命令的写入文件放在了父进程执行了。
整个 AOF 重写的过程, 需要的了解的前提知识大概就这些了, 后面进入代码的逻辑分析。
3.2 逻辑触发入口
在 Redis 触发重写机制的方式有 2 个
- 通过 bgrewriteaof 命令
- 定时器, 定时检查 AOF 文件, 如果满足配置文件里面设置的条件, 就触发
bgrewriteaof 命令方式对应的逻辑函数为 bgrewriteaofCommand, 里面的逻辑如下
- 如果已经在执行重写中了, 返回错误提示
- 如果当前正在执行 RDB 保存时, 只会先将 redisServer 中的 aof_rewrite_scheduled 属性设置为 true, 返回提示后, 结束, 后面通过定时器判断这个状态确定是否需要触发
- 调用 rewriteAppendOnlyFileBackground 执行重写
而定时器的触发代码如下
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// 代码省略
// 后台没有进程在 RDB 和 AOF, 同时通过 bgrewriteaof 命令设置了定时刷新重写 AOF
// 当用户调用 bgrewriteaof 命令时, Redis 正在 RDB, 会先将 aof_rewrite_scheduled 设置为 true, 然后返回, 而不是执行 AOF
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 && server.aof_rewrite_scheduled) {
rewriteAppendOnlyFileBackground();
}
// 后台有进程在 RDB 或者 AOF
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 || ldbPendingChildren()) {
// 代码省略
} else {
// 代码省略
// 1. 开启了 AOF 功能
// 2. 后台没有进程在 RDB 和 AOF
// 3. 配置了目前 AOF 文件大小超过上次重写的 AOF 文件的百分比
// 4. 当前的 AOF 文件大小超过了配置的需要触发重写的最小大小
if (server.aof_state == AOF_ON && server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&
server.aof_rewrite_perc && server.aof_current_size > server.aof_rewrite_min_size) {
// 计算当前的文件增长的比例
long long base = server.aof_rewrite_base_size ? server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
// 超过了就调用 rewriteAppendOnlyFileBackground 进行重写
if (growth >= server.aof_rewrite_perc) {
rewriteAppendOnlyFileBackground();
}
}
}
// 代码省略
}
上面就是 AOF 重写触发的入口了, 而 AOF 重写的逻辑最终都是统一到了 rewriteAppendOnlyFileBackground 函数。
3.3 具体的实现逻辑
3.3.1 父进程执行 rewriteAppendOnlyFileBackground 函数, AOF 重写前的操作
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
long long start;
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1)
return C_ERR;
// 创建 Pipe 通道, 用于父子进程之间通信
// 内部会创建父子通讯需要的 6 个 Pipe
if (aofCreatePipes() != C_OK)
return C_ERR;
// 开通另一组通道, 不涉及主流程
// 用于子进程向父子进程通讯, 在 AOF 中主要用于通知父进程, 子进程此次重写使用了多少额外内存
openChildInfoPipe();
// 获取当前时间
start = ustime();
if ((childpid = fork()) == 0) {
// 子进程
// fork 完成, 子进程, 从这里开始执行逻辑
// 清除子进程不需要的资源
closeClildUnusedResourceAfterFork();
// 设置标题
redisSetProcTitle("redis-aof-rewrite");
// 创建临时文件, 文件名 temp-rewriteaof-bg-进程ID.aof
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid());
// 执行 rewriteAppendOnlyFile 函数, 进行 AOF 文件的重写
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
// 子进程重写完成的一些收尾工作, 基本不涉及主流程, 通知父进程过程中子进程修改了多少数据
// 计算当前进程使用修改了多少内存
size_t private_dirty = zmalloc_get_private_dirty(-1);
if (private_dirty) {
serverLog(LL_NOTICE, "AOF rewrite: %zu MB of memory used by copy-on-write", private_dirty/(1024*1024));
}
server.child_info_data.cow_size = private_dirty;
// 子进程的信息发送给父进程, 也就是拷贝到 server.child_info_pipe[2] 中
sendChildInfo(CHILD_INFO_TYPE_AOF);
// 结束
exitFromChild(0);
} else {
exitFromChild(1);
}
} else {
// 父进程
// fork 完成, 父进程, 从这里开始执行逻辑
// 计算 fork 消耗的时间
server.stat_fork_time = ustime()-start;
// 计算 fork 的速率,GB/每秒
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024);
// 延迟统计
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
// fork 失败 关闭通道
closeChildInfoPipe();
serverLog(LL_WARNING, "Can't rewrite append only file in background: fork: %s", strerror(errno));
aofClosePipes();
return C_ERR;
}
serverLog(LL_NOTICE,"Background append only file rewriting started by pid %d",childpid);
server.aof_rewrite_scheduled = 0;
server.aof_rewrite_time_start = time(NULL);
server.aof_child_pid = childpid;
// 和 RDB 类似, 更新全局的 dict.dict_can_resize 进行字典扩容的控制, 控制存储数据的 dict 扩容
updateDictResizePolicy();
server.aof_selected_db = -1;
// 清空 redisServer 的 repl_scriptcache_dict 字典和 repl_scriptcache_fifo 这个列表
// 和主从复制相关
replicationScriptCacheFlush();
return C_OK;
}
return C_OK;
}
3.3.2 子进程执行的 rewriteAppendOnlyFile 函数就是 AOF 重写真正过程
// 这里的入参 filename 格式为 temp-rewriteaof-bg-进程 ID, 而不是真正的 AOF 文件名
int rewriteAppendOnlyFile(char *filename) {
rio aof;
FILE *fp;
char tmpfile[256];
char byte;
// 重新根据进程ID 获取一个文件名 temp-rewriteaof-进程ID.aof 的文件
// 数据先写入到这个文件, 后面在重命名为入参的 filename
snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
serverLog(LL_WARNING, "Opening the temp file for AOF rewrite in rewriteAppendOnlyFile(): %s", strerror(errno));
return C_ERR;
}
// 清空 aof_child_diff 的数据, 这个就是 AOF 子进程差异缓冲区
server.aof_child_diff = sdsempty();
// 初始 rio 流, 也就是 IO 流, 用于写入数据到文件
rioInitWithFile(&aof,fp);
// 设置文件自动同步
// 当写入的字节数达到了 REDIS_AUTOSYNC_BYTES (1024*1024*32) 的倍数, 就执行一次 fsync,
if (server.aof_rewrite_incremental_fsync)
rioSetAutoSync(&aof,REDIS_AUTOSYNC_BYTES);
// Redis 4.0 的特性, AOF 和 RDB 混用
// 先将当前的数据以 RDB 的格式存储下来, 添加的这段时间, 在缓冲区的再以 AOF 的方式存储
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(&aof,&error,RDB_SAVE_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
// 将当前 Redis 内存数据库中的数据写入到 AOF 文件中
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
// 当前的内存数据库的数据都写入完成
// 执行 fflush 函数, 更新缓存中的数据到文件中
if (fflush(fp) == EOF) goto werr;
// 执行 fsync 函数
if (fsync(fileno(fp)) == -1) goto werr;
int nodata = 0;
mstime_t start = mstime();
// 尽量 将内存数据写入到 AOF 临时文件过程中 产生的差异命令同步过来
// 当前时间和重写的开始时间差在 1 秒内, 同时没有连续 20 次读取到空数据
while(mstime()-start < 1000 && nodata < 20) {
// 尝试从通道 aof_pipe_read_data_from_parent 也就是重写缓冲区中读取数据, 每次阻塞 1 毫秒
// 读取到的数据长度小于等于 0, 进入下一次循环, 为读取到数据次数 + 1
if (aeWait(server.aof_pipe_read_data_from_parent, AE_READABLE, 1) <= 0) {
nodata++;
continue;
}
nodata = 0;
// 从重写缓冲区读数据到 aof_child_diff
aofReadDiffFromParent();
}
// 写入一个 ! 到 aof_pipe_write_ack_to_parent, 通过通道间接同步到父级的 aof_pipe_read_ack_from_child
// 请求父进程停止发送差异数据, 也就是重写缓冲区
if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr;
// 将从父级读取 ack 的 aof_pipe_read_ack_from_parent 设置为非阻塞的
if (anetNonBlock(NULL,server.aof_pipe_read_ack_from_parent) != ANET_OK) goto werr;
// 在 5000ms 之内,从 aof_pipe_read_ack_from_parent 读取 1 个字节的数据保存在 byte 中, 同时判断 byte 是否为 '!'
if (syncRead(server.aof_pipe_read_ack_from_parent,&byte,1,5000) != 1 || byte != '!') goto werr;
serverLog(LL_NOTICE,"Parent agreed to stop sending diffs. Finalizing AOF...");
// 此时父进程不会在同步差异命令过来了, 再做最后一次同步, 将 Pipe 通道中残留的数据同步过来
// 再次从父级中读取差异数据
aofReadDiffFromParent();
serverLog(LL_NOTICE, "Concatenating %.2f MB of AOF diff received from parent.", (double) sdslen(server.aof_child_diff) / (1024*1024));
// 将 aof_child_diff 中的数据写入到 aof 文件中
if (rioWrite(&aof,server.aof_child_diff,sdslen(server.aof_child_diff)) == 0) goto werr;
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
// 重命名文件名
if (rename(tmpfile,filename) == -1) {
serverLog(LL_WARNING,"Error moving temp append only file on the final destination: %s", strerror(errno));
unlink(tmpfile);
return C_ERR;
}
serverLog(LL_NOTICE,"SYNC append only file rewrite performed");
return C_OK;
werr:
serverLog(LL_WARNING,"Write error writing append only file on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
return C_ERR;
}
子进程将自身内存数据库中的数据写入到 AOF 临时文件的逻辑
/**
* 将 Redis 数据库中的数据都写入到文件
* 原理就是变量数据库中的数据, 然后将每个 key 和 key 对应的 value 写入到文件中
* 同时为较小文件的大小, 会使用批量相关的命令来替代单个命令
* 比如向 list 类型的结构添加数据, 可以通过 lset 一个一个元素的添加, 也可以通过 RPUSH 一次添加多个
* 所以 Redis AOF 文件能缩小的原因就是这个
*
* 同时内部为了安全性, 单个批量命令内部的元素会控制不超过 AOF_REWRITE_ITEMS_PER_CMD 64 个
*/
int rewriteAppendOnlyFileRio(rio *aof) {
dictIterator *di = NULL;
dictEntry *de;
size_t processed = 0;
int j;
// 逐个遍历所有的数据库
for (j = 0; j < server.dbnum; j++) {
char selectcmd[] = "*2\r\n$6\r\nSELECT\r\n";
redisDb *db = server.db+j;
dict *d = db->dict;
// 对应的数据库没有数据, 跳过
if (dictSize(d) == 0)
continue;
// 字典迭代器
di = dictGetSafeIterator(d);
// 向文件中写入 *2\r\n$6\r\nSELECT\r\n数据库的编号的长度\r\n数据库的编号, 也就是 select 数据库
if (rioWrite(aof,selectcmd,sizeof(selectcmd)-1) == 0) goto werr;
if (rioWriteBulkLongLong(aof,j) == 0) goto werr;
while((de = dictNext(di)) != NULL) {
sds keystr;
robj key, *o;
long long expiretime;
keystr = dictGetKey(de);
o = dictGetVal(de);
// 将字符串的 key 转为 redisObject 对象, 编码 encoding 默认为 OBJ_ENCODING_RAW, 引用次数 refcount 为 1
initStaticStringObject(key,keystr);
expiretime = getExpire(db,&key);
if (o->type == OBJ_STRING) {
char cmd[]="*3\r\n$3\r\nSET\r\n";
// 写入上面的文本
if (rioWrite(aof,cmd,sizeof(cmd)-1) == 0) goto werr;
// 写入 key
if (rioWriteBulkObject(aof,&key) == 0) goto werr;
// 写入 value
if (rioWriteBulkObject(aof,o) == 0) goto werr;
} else if (o->type == OBJ_LIST) {
if (rewriteListObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_SET) {
// 下面的几个写入和 list 类型跳过
if (rewriteSetObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_ZSET) {
if (rewriteSortedSetObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_HASH) {
if (rewriteHashObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_STREAM) {
if (rewriteStreamObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_MODULE) {
if (rewriteModuleObject(aof,&key,o) == 0) goto werr;
} else {
serverPanic("Unknown object type");
}
// 如果 key 设置了过期时间, 写入过期时间
if (expiretime != -1) {
char cmd[]="*3\r\n$9\r\nPEXPIREAT\r\n";
if (rioWrite(aof,cmd,sizeof(cmd)-1) == 0) goto werr;
if (rioWriteBulkObject(aof,&key) == 0) goto werr;
if (rioWriteBulkLongLong(aof,expiretime) == 0) goto werr;
}
// AOF_READ_DIFF_INTERVAL_BYTES = 1024*10
// 重写文件每写入 10 M, 就通过通道从父级中读取差异
if (aof->processed_bytes > processed + AOF_READ_DIFF_INTERVAL_BYTES) {
// 更新已写的字节数
processed = aof->processed_bytes;
// 通过通道 aof_pipe_read_data_from_parent 将重写缓冲区中的数据读取到 aof_child_diff 中
aofReadDiffFromParent();
}
}
}
return C_OK;
werr:
if (di)
dictReleaseIterator(di);
return C_ERR;
}
// list 类型的数据写入
int rewriteListObject(rio *r, robj *key, robj *o) {
long long count = 0, items = listTypeLength(o);
if (o->encoding == OBJ_ENCODING_QUICKLIST) {
quicklist *list = o->ptr;
quicklistIter *li = quicklistGetIterator(list, AL_START_HEAD);
quicklistEntry entry;
while (quicklistNext(li,&entry)) {
if (count == 0) {
// 获取当前 rpush 的元素个数, 最大为 AOF_REWRITE_ITEMS_PER_CMD 64 个
int cmd_items = (items > AOF_REWRITE_ITEMS_PER_CMD) ? AOF_REWRITE_ITEMS_PER_CMD : items;
// 写入参数个数 *参数个数
if (rioWriteBulkCount(r,'*',2+cmd_items) == 0) return 0;
// 写入 rpush 命令
if (rioWriteBulkString(r,"RPUSH",5) == 0) return 0;
// 写入 key 值
if (rioWriteBulkObject(r,key) == 0) return 0;
}
// 依次写入元素
if (entry.value) {
if (rioWriteBulkString(r,(char*)entry.value,entry.sz) == 0) return 0;
} else {
if (rioWriteBulkLongLong(r,entry.longval) == 0) return 0;
}
// 写入一次 count + 1 次, 当 count == 上限的 64 个, 重新值为 0
// 从而可以重新写入一个 rpush
if (++count == AOF_REWRITE_ITEMS_PER_CMD) count = 0;
items--;
}
quicklistReleaseIterator(li);
} else {
serverPanic("Unknown list encoding");
}
return 1;
}
整个 AOF 重写的因为涉及到了子进程, 所以复杂度就上去了, 整理如下:
父进程
- 定时器判断满足重写条件或者执行了 bgrewriteaof 命令, 触发 AOF 重写
- 父进程创建出 6 个文件描述符, 用来创建 6 个通道, 分别用于: 父进程将数据写给子进程, 子进程通知父进程 ack, 父进程通知子进程 ack
- 创建完通道后, 设置 aof_stop_sending_diff 为 0, 也就是 false, 表示可以将重写缓冲区的数据继续推送给子进程
- 父进程 fork 出一个子进程, 然后进行一些统计相同的配置后, 进行处理其他的命令 (此处是子进程的开始地方)
- 父进程处理到修改性质的命令时, 依旧是会进行把当前命令的变更写的已有的 AOF 文件中, 同时判断到当前在进行 AOF 重写, 会把当前命令对应的文本保存到 AOF 重写缓存区 aof_rewrite_buf_blocks
- 判断当前的 AE 循环中是否有 aof_pipe_write_data_to_child 这个文件描述符 (这个就是上面 6 个文件描述符之一) 对应的文件, 没有则创建 1 个文件, 执行的逻辑为 aofChildWriteDiffData
- 因为有事件存在, 每次 AE 循环时, 都会执行到 aofChildWriteDiffData 函数, 逻辑就是将 AOF 重写缓存区 aof_rewrite_buf_blocks 中的数据全部写到 aof_pipe_write_data_to_child 中, 同时在 aof_stop_sending_diff 为 true 或者 aof_rewrite_buf_blocks 中的数据转移完成时, 删除这个事件。写入到 aof_pipe_write_data_to_child 的数据在通道的作用下, 会自动同步到子进程的 aof_pipe_read_data_from_parent 中
上面就是父进程的逻辑, 下面的子进程的逻辑
- 因为子进程是通过 fork 操作创建出来的, 所以子进程和父进程是完全一样的, 也就是当前子进程拥有着和父进程一样的字典, 存放着所有键值对的数据, 同时不受父进程的影响, 也就是快照
- 临时创建出一个 temp-rewriteaof-bg-进程ID.aof 文件, 用来保存当前的数据
- 判断 server.aof_use_rdb_preamble 是否为 true, 也就是是否开启了 RDB 和 AOF 混用的功能, 开启了, 就先将当前的数据字典的数据以 RDB 的方式进行保存, 否则就是根据数据字典执行命令重写
- 命令重写的逻辑: 用批量相关的命令来替代单个命令, 同时在执行的过程中不断的将 aof_pipe_read_data_from_parent 中的数据读取到自身的 aof_child_diff 中
- 数据字典中的数据都处理完成后, 子进程向 aof_pipe_write_ack_to_parent 写入一个 !, 在通道的同步下, 同步到父进程的 aof_pipe_read_ack_from_child 中 (父级收到了, 先将 aof_stop_sending_diff 设置为 true, 向 aof_pipe_write_ack_to_child 写入了一个 !, 同样在管道的同步下, 最终到了子进程的 aof_pipe_read_ack_from_parent, 最后删除这个 aof_pipe_read_ack_from_child 描述符的事件)
- 向 aof_pipe_write_ack_to_parent 写入 ! 后, 等待 5000ms, 从 aof_pipe_read_ack_from_parent 中读取数据, 超时读取, 读取到的不是 !, 异常处理, 结束
- 从 aof_pipe_read_ack_from_parent 读取到了 !, 表示读取到了父级的确认 ack, 最后一次从 aof_pipe_read_data_from_parent 读取数据到 aof_child_diff, 确保在文件描述符中没有父进程写向子进程的数据了
- 把 aof_child_diff 中的数据追加到临时的 AOF 文件中
- 通过 rename 函数将临时文件重命名为配置的入参的文件名 (AOF 重写入参的文件名为: temp-rewriteaof-bg-进程ID.aof, rename 函数会先将同名的文件, 文件夹删除)
从上面的过程中看起来, 好像完美了, 但是别忘了这里涉及到了并发, 在父子进程互相 ack 确认时, 父进程收到 ack 时, 只是把 aof_stop_sending_diff 设置为 true, 也就是确保 AOF 重写缓存区的数据不会再写给子进程。
而子进程收到 ack, 只是把当前所有的 AOF 重写缓存区中的数据写入到文件中, 子进程自己的任务到此就结束了。
而这个过程, 父进程还会继续处理其他的命令, 这些新的命令只能由父进程自己处理
- 将当前 AOF 重写缓存区中的数据写入到 AOF 临时文件
- 重命名 AOF 临时文件, 整个 AOF 重写正式完成
3.3.3 父进程监听子进程结束, AOF 重写收尾
首先入口, 还是在定时器 serveCron 中, 定时的检查子进程的状态是否为结束了, 是的话, 执行结束逻辑
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// 省略
// 检查是否有 RDB 子进程或者 AOF 重写子进程结束了
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 || ldbPendingChildren()){
int statloc;
pid_t pid;
// wait3 可以获取所有的进程是否有一个进程退出状态的, 有的话, 进行彻底的销毁,同时返回其进程 id
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
if (WIFSIGNALED(statloc))
bysignal = WTERMSIG(statloc);
if (pid == -1) {
// 异常情况, 打印日志
serverLog(LL_WARNING,"wait3() returned an error: %s. rdb_child_pid = %d, aof_child_pid = %d", strerror(errno), (int) server.rdb_child_pid, (int) server.aof_child_pid);
} else if (pid == server.rdb_child_pid) {
// rdb 进程逻辑省略
} else if (pid == server.aof_child_pid) {
// 进程 id 为 AOF 重写进程 id
// 执行最终的清除逻辑
backgroundRewriteDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0)
// 获取子进程发送给父进程的信息
receiveChildInfo();
} else {
// 其他的情况
if (!ldbRemoveChild(pid)) {
serverLog(LL_WARNING, "Warning, detected child with unmatched pid: %ld", (long)pid);
}
}
// 重新设置字典的可以扩容标识为 true
updateDictResizePolicy();
// 关闭 Pipe
closeChildInfoPipe();
}
} else {
// 判断是否需要进行 RDB 或者 AOF 重写
// 省略
}
// 省略
}
// 父进程对 AOF 重写最后的处理
void backgroundRewriteDoneHandler(int exitcode, int bysignal) {
// exitcode == 0 表示子进程是执行完逻辑后, 主动退出的
if (!bysignal && exitcode == 0) {
int newfd, oldfd;
char tmpfile[256];
long long now = ustime();
mstime_t latency;
serverLog(LL_NOTICE, "Background AOF rewrite terminated with success");
latencyStartMonitor(latency);
// 再次通过子进程的进程 ID 获取到 AOF 重写的临时文件名 temp-rewriteaof-bg-进程ID.aof, 也就是 AOF 重写临时文件
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof",(int)server.aof_child_pid);
// 打开文件
newfd = open(tmpfile,O_WRONLY|O_APPEND);
if (newfd == -1) {
serverLog(LL_WARNING, "Unable to open the temporary AOF produced by the child: %s", strerror(errno));
goto cleanup;
}
// 把最后剩余的信息从 aof_rewrite_buf_blocks 写入到指定的文件
if (aofRewriteBufferWrite(newfd) == -1) {
serverLog(LL_WARNING, "Error trying to flush the parent diff to the rewritten AOF: %s", strerror(errno));
close(newfd);
goto cleanup;
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-rewrite-diff-write",latency);
serverLog(LL_NOTICE,"Residual parent diff successfully flushed to the rewritten AOF (%.2f MB)", (double) aofRewriteBufferSize() / (1024*1024));
// aof_fd 为当前的 AOF 文件的文件描述符, 等于 -1, 应该是 AOF 功能停用了
// 这时为了下面的流程能走下去, 从配置文件中获取到配置的文件名, 尝试打开禁用前的文件
if (server.aof_fd == -1) {
oldfd = open(server.aof_filename,O_RDONLY|O_NONBLOCK);
} else {
oldfd = -1;
}
latencyStartMonitor(latency);
// 将临时文件重命名为配置的文件名
if (rename(tmpfile,server.aof_filename) == -1) {
serverLog(LL_WARNING, "Error trying to rename the temporary AOF file %s into %s: %s", tmpfile, server.aof_filename, strerror(errno));
close(newfd);
if (oldfd != -1) close(oldfd);
goto cleanup;
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-rename",latency);
if (server.aof_fd == -1) {
close(newfd);
} else {
oldfd = server.aof_fd;
server.aof_fd = newfd;
// 根据同步策略进行 fsync
if (server.aof_fsync == AOF_FSYNC_ALWAYS)
redis_fsync(newfd);
else if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
aof_background_fsync(newfd);
server.aof_selected_db = -1;
// 更新当前 AOF 文件的大小
aofUpdateCurrentSize();
// 更新最新的 AOF 文件大小和重写大小
server.aof_rewrite_base_size = server.aof_current_size;
server.aof_fsync_offset = server.aof_current_size;
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
server.aof_lastbgrewrite_status = C_OK;
serverLog(LL_NOTICE, "Background AOF rewrite finished successfully");
if (server.aof_state == AOF_WAIT_REWRITE)
server.aof_state = AOF_ON;
// 关闭打开的文件
if (oldfd != -1)
bioCreateBackgroundJob(BIO_CLOSE_FILE,(void*)(long)oldfd,NULL,NULL);
serverLog(LL_VERBOSE,"Background AOF rewrite signal handler took %lldus", ustime()-now);
} else if (!bysignal && exitcode != 0) {
// 非正常退出
server.aof_lastbgrewrite_status = C_ERR;
serverLog(LL_WARNING, "Background AOF rewrite terminated with error");
} else {
// 非正常退出
if (bysignal != SIGUSR1)
server.aof_lastbgrewrite_status = C_ERR;
serverLog(LL_WARNING, "Background AOF rewrite terminated by signal %d", bysignal);
}
cleanup:
// 清除工作
aofClosePipes();
aofRewriteBufferReset();
aofRemoveTempFile(server.aof_child_pid);
server.aof_child_pid = -1;
server.aof_rewrite_time_last = time(NULL)-server.aof_rewrite_time_start;
server.aof_rewrite_time_start = -1;
if (server.aof_state == AOF_WAIT_REWRITE)
server.aof_rewrite_scheduled = 1;
}
// AOF 重写缓冲区数据写入文件
ssize_t aofRewriteBufferWrite(int fd) {
listNode *ln;
listIter li;
ssize_t count = 0;
listRewind(server.aof_rewrite_buf_blocks,&li);
while((ln = listNext(&li))) {
aofrwblock *block = listNodeValue(ln);
ssize_t nwritten;
if (block->used) {
nwritten = write(fd,block->buf,block->used);
if (nwritten != (ssize_t)block->used) {
if (nwritten == 0) errno = EIO;
return -1;
}
count += nwritten;
}
}
return count;
}
到了这一步, 整个 AOF 的重写过程才真正的结束了。














 3433
3433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









