







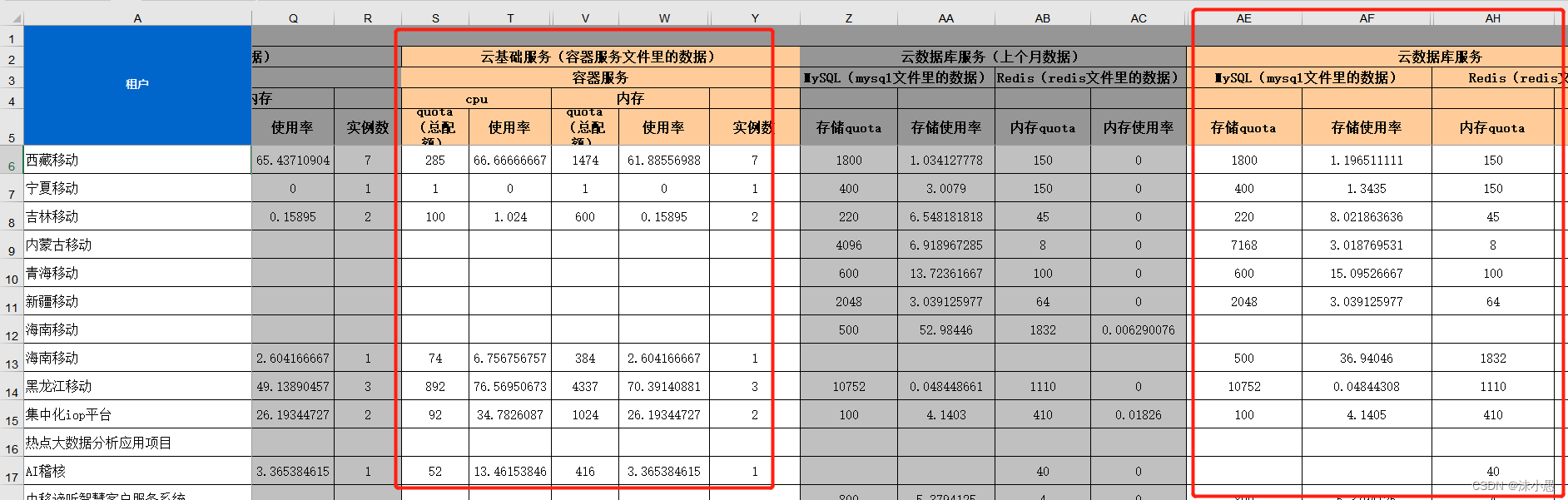
一、需要把多个文件读写进附件2与附件3中,其中涉及到表中的表头与文件字段名不同,因此需要处理表头与文件的对应相关,在整体的写进过程中,还存在租户名的情况,因此也处理把报错的租户名进行处理,还一此其它问题也有处理最终的写入如下图所示(仅一部分
二、整体代码(里面增加了步骤的说明)
import os
import xlrd
import xlwt
from datetime import date
from xlutils.copy import copy
from xlutils.filter import process, XLRDReader, XLWTWriter
'''步骤一:请取附件2与附件3的文件'''
cwd = os.getcwd()
#遍历当前路径,路径,文件全部爬出来
for dirpaths, dirnaames,filenames in os.walk(cwd):
#dirpaths路径,dirnaames文件夹的名字,filenames所有文件的名字
#判断.xls文件是否存在,xlrd只能读取.xls的文件,若为xlsm的文件请转化为.xls文件
for filename in filenames:
if filename.endswith(".xls") :
if filename.startswith('附件2'):
filename2 = filename
wb2 = xlrd.open_workbook(filename, formatting_info=True)
sheet2 = wb2.sheet_by_index(0)
elif filename.startswith('附件3'):
filename3 = filename
wb3 = xlrd.open_workbook(filename, formatting_info=True)
sheet3 = wb3.sheet_by_index(0)
'''步骤二:把附件2与附件3中读取租户所在的行'''
def get_rows(m, n, sheet):
ans = {}
maxr= 0
for r in range(m, n):
tenantName = sheet.cell(r, 0).value
#去除空格的情况
if tenantName:
ans[tenantName] = r
maxr = r
return ans,maxr
rows2, r2 = get_rows(5, sheet2.nrows, sheet2) #附件2
rows2['ai稽核'] = rows2.pop('AI稽核') #表中的租户与文件中的租户同有差异,更改存储字典中租户名
rows3, r3 = get_rows(2, sheet3.nrows, sheet3) #附件3
'''步骤三:写入数据进的表中,先复制原表'''
def get_nwb(wb):
nwb = copy(wb)
nsheet = nwb.get_sheet(0)
return nwb, nsheet
#获取原表与原表中的sheet
nwb2, nsheet2 = get_nwb(wb2)
nwb3, nsheet3 = get_nwb(wb3)
'''步骤四:把文件中名称与表中的所需要的填写对应上,KEY为文件名,为后面写入文件做准备,需要读取的多个文件名用V隔开'''
#获取附件2的需要填写的字段
file2 = {
'容器服务哈池V容器服务呼池' : {'CPU总配额(G)':18, 'cpu使用率(%)':19, '内存总配额(G)':21, '内存使用率)(%)':22,'实例数(个)':24},
'哈池mysqlV呼池mysql':{'存储总配额(G)':30,'存储使用率(%)':31},
'redis哈池Vredis呼池':{'内存总配额(G)':33,'内存使用率(%)':34}
}
#获取附件3的需要填写的字段
file3 = {
'hdfs1':{'目录总配额(G)':6, '实例数(个)':7},
'yarn':{'内存最大配额(G)':11, 'cpu_最大配额(个)':12, '实例数(个)':13},
'hive':{'库总配额(G)':16, '实例数(个)':17},
'hbase' : {'命名空间流量(G/min)':23, '命名空间请求限制数(G)':24, '表的数目(个)':25, '区域数(个)':26, '实例数(个)':27},
'kafka1': {'分区数(个)':36, '副本数(个)':37, '容量(GB)':38, '实例数(个)':39},
'呼池mysqlV哈池mysql':{'存储总配额(G)':54, '存储使用量(G)':55, '存储使用率(%)':56, '实例数(个)':57},
'redis哈池Vredis呼池':{'内存总配额(G)':77, '节点数(个)':78, '副本数(个)':79, '卷总配额(G)':80, '内存使用量(G)':81, '卷使用量(G)':82, '内存使用率(%)':83, '卷使用率(%)':84, '实例数(个)':85},
'gbases': {'内存总配额':90, 'CPU总配额':91, '存储总配额':92, '实例数':93},
'vertica哈池Vvertica呼池':{'内存总配额(G)':96, '实例数(个)':97}
}
'''步骤五:获取原表的填写的格式'''
w = XLWTWriter()
process(XLRDReader(wb3,'unknown.xls'), w)
style = w.style_list[sheet3.cell_xf_index(8, 3)]
'''步骤六:读写文件的数据'''
def get_write_file(file, sheetname, rows, r): #file各文件列,sheetname表名,rows行,r为最大的行数
#把依次把各文件读入 allData 字典中
for h, b in file.items(): #h为租户名,b为字典列名:列
f = str(h).split('V') #f为文件的列表
tenantData = {} #文件中列名:数值
tenantName = '' #租户名
allData = {} #所有租户的字典
for path in f:
for line in open(path, 'r', encoding='utf-8'): #打开表
line = line.strip() #去掉空格
if line.find('*') != -1 :
if tenantName and tenantData: #如何值不为空
allData[tenantName] = tenantData
elif line.split(':')[0] == 'tenantName' :
tenantName = line.split(':')[1].strip()
if tenantName in allData:
tenantData = allData[tenantName]
else:
tenantData = {}
elif len(line.split(':')) > 1 and line.split(':')[1] and line.split(':')[1].strip() != 'NULL':
k = line.split(':')[0].split('-')[-1]
if path.find('redis') != -1 and k != 'hu服务名':
k = k.split('s')[-1]
k = k.split('u')[-1]
k = k.split('r')[-1]
elif path.find('gbases') != -1:
k = k.split('(')[0]
if k in b:
tenantData.setdefault(k, 0)
tenantData[k] += float(line.split(':')[1])
allData[tenantName] = tenantData
#每完成一次allData字典,就把对应的值写入表(附件)中
for key, value in allData.items(): #key是租户名,v为数据的字典 (从文件来
for k, v in value.items(): #k是表头名,v为数据(从文件来
if key not in rows:
r += 1
rows[key] = r
sheetname.write(r, 0, key, style)
for i in b: #i是与表中的表头(从表来
if i == k:
sheetname.write(rows[key], b[i], v, style)
break
#写进附件2
get_write_file(file2, nsheet2, rows2, r2)
nwb2.save("{}\\newfile\\{}.xslx".format(cwd, filename2.split('.')[0]))
#写进附件3
get_write_file(file3, nsheet3, rows3, r3)
nwb3.save("{}\\newfile\\{}.xslx".format(cwd, filename3.split('.')[0]))
print('结束')














 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









