






引言
在构建企业级AI应用时,如何有效整合本地部署的大语言模型(LLM)是需要重点考虑的技术环节。本文将深入探讨在Dify平台上集成Ollama和Xinference两大开源框架的完整解决方案,实现包括对话模型、Embedding模型和Rerank模型的全栈本地部署。
1. 修改Dify配置文件
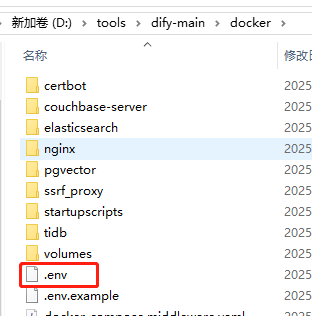
进入Dify的安装目录,找到.env文件,在文件末尾添加下面两行配置:
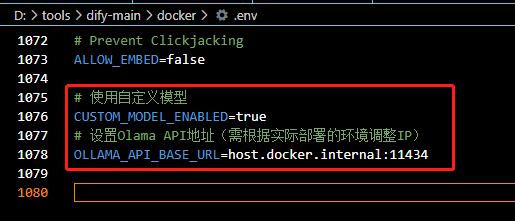
# 使用自定义模型
CUSTOM_MODEL_ENABLED=true
# 设置Olama API地址(需根据实际部署的环境调整IP)
OLLAMA_API_BASE_URL=host.docker.internal:11434
Ollama 默认服务器端口 11434, 通过配置环境变量的方式可更改为自定义的服务端口。
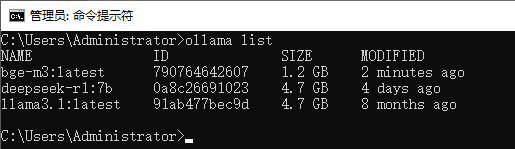
列出Ollama在计算机上部署的模型:
ollama list
启动 Ollama (无需运行桌面应用程序):
ollama serve

2. 为Dify配置本地(对话)大模型
进入Dify的主界面 http://localhost/apps ,点击右上角用户名,点击弹出菜单下中的【设置】
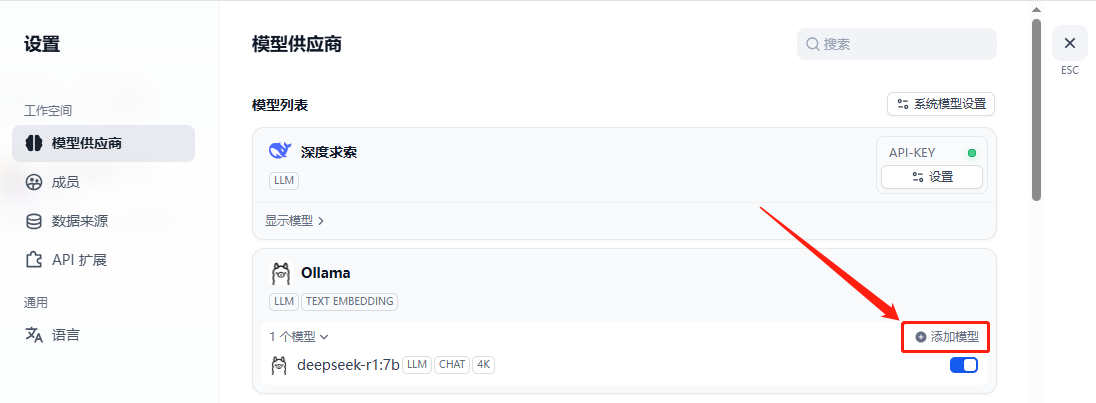
点击界面左侧“模型供应商”,进入模型供应商配置界面,找到Ollama后点击【添加模型】按钮(若没有找到Ollama,需先到Dify市场中安装)
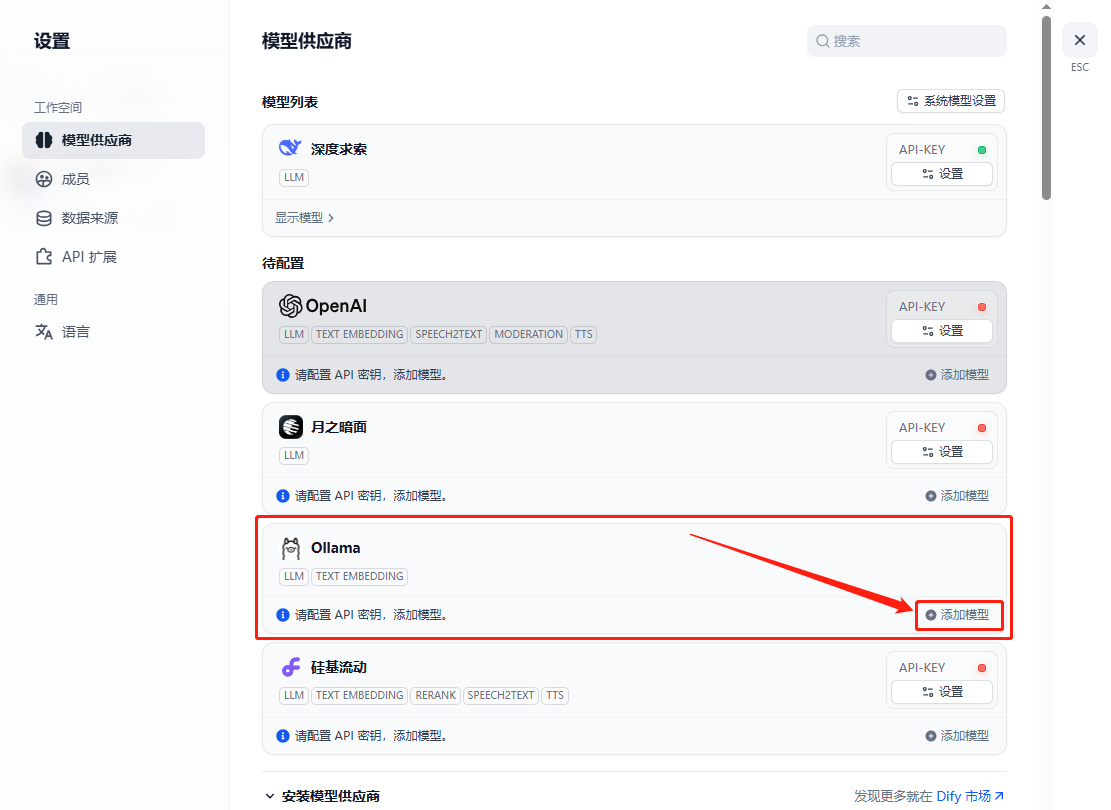
这里我填入的是Ollama部署的deepseek-r1:7b模型,填入配置文件中添加的Ollama API地址:host.docker.internal:11434

点击【保存】,可以看到模型已经添加成功:
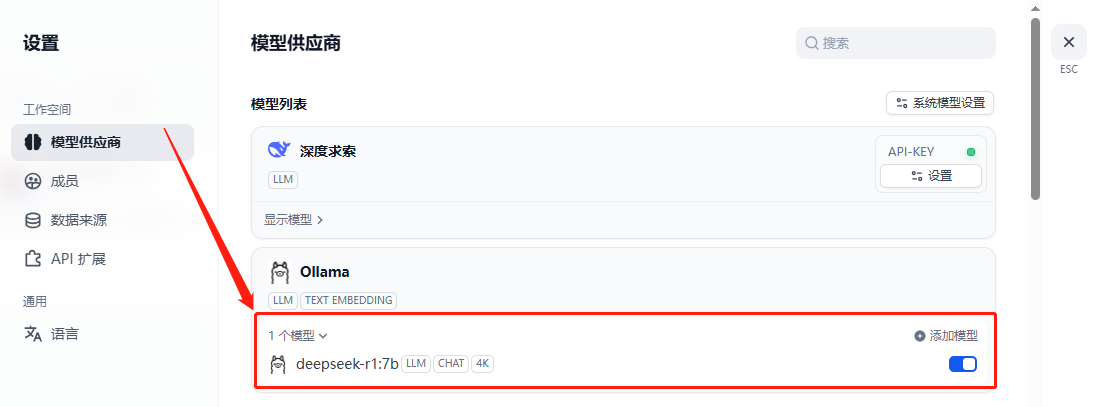
这里,可以立即将系统模型配置为刚刚添加的本地模型。当然,也可以在实际的工作流中另外设置。
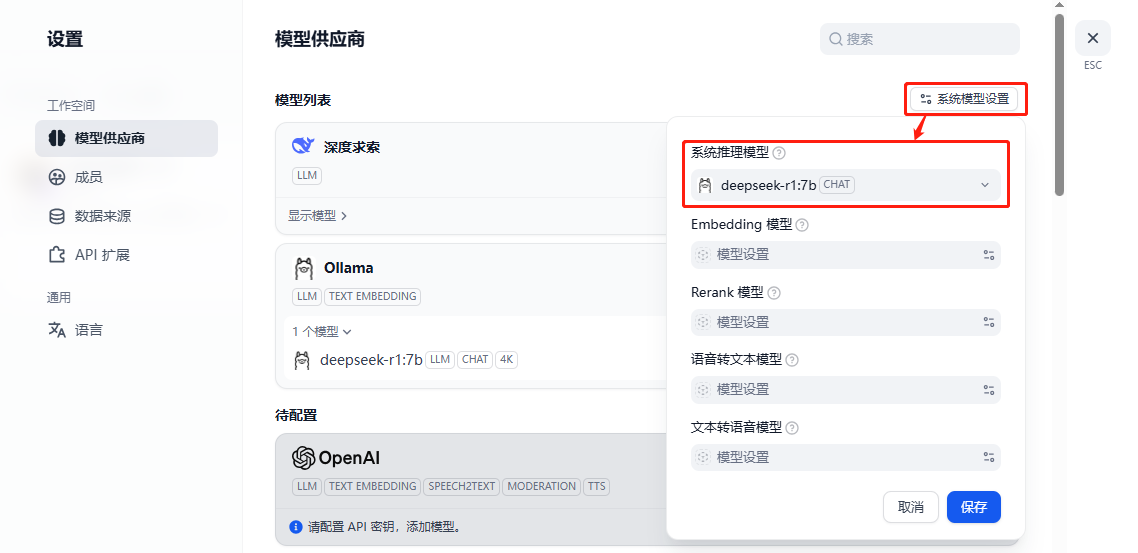
如果需要创建属于我们自己的本地知识库,还需要额外配置一个Embedding模型。
3. 为Dify配置Embedding模型
依然可以使用前面配置的deepseek-r1:7b模型,但deepseek-r1毕竟不是专门为嵌入场景训练的embeddinig模型,这使得用deepseek-r1作为嵌入模型时,对于一些问题的回答与预期效果有一定的偏差。这里将使用网友推荐的bge-m3模型作为我们Dify项目中的嵌入模型。
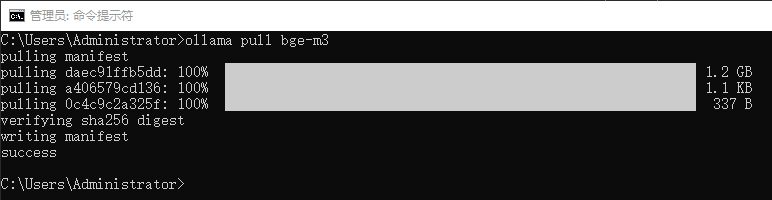
安装 bge-m3
ollama pull bge-m3
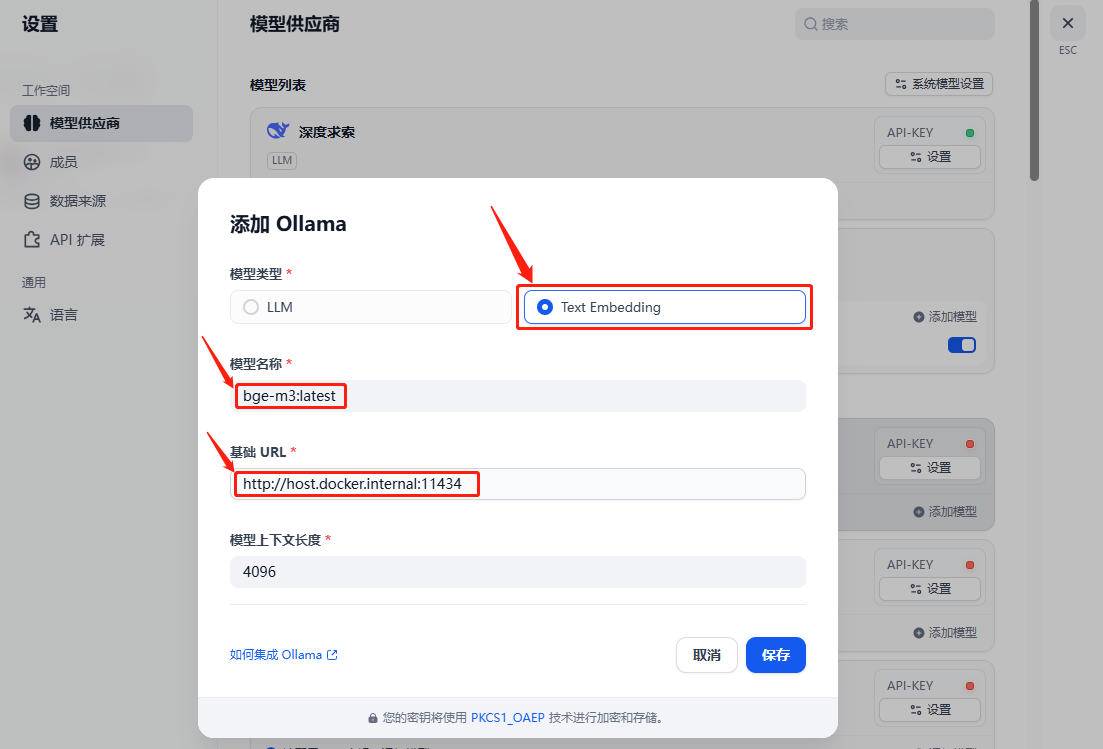
配置 Embedding 模型
同样,填入相应信息后保存:
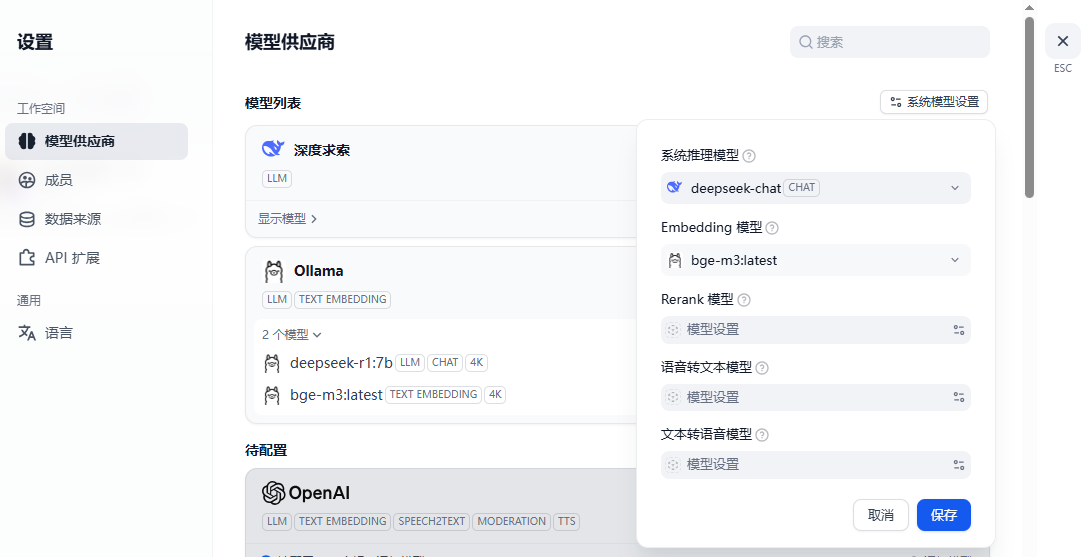
4. 为Dify配置Rerank模型
当前较优的重排模型是Cohere(需要付费)。考虑到成本,建议使用开源模型如 bge-reranker-base 和 bge-reranker-large,其中bge-reranker-large模型具有与 Cohere相似的能力。
由于Dify中的Ollama模型不支持直接调用Rerank API,因此需要再借助xinference配置Rerank模型。
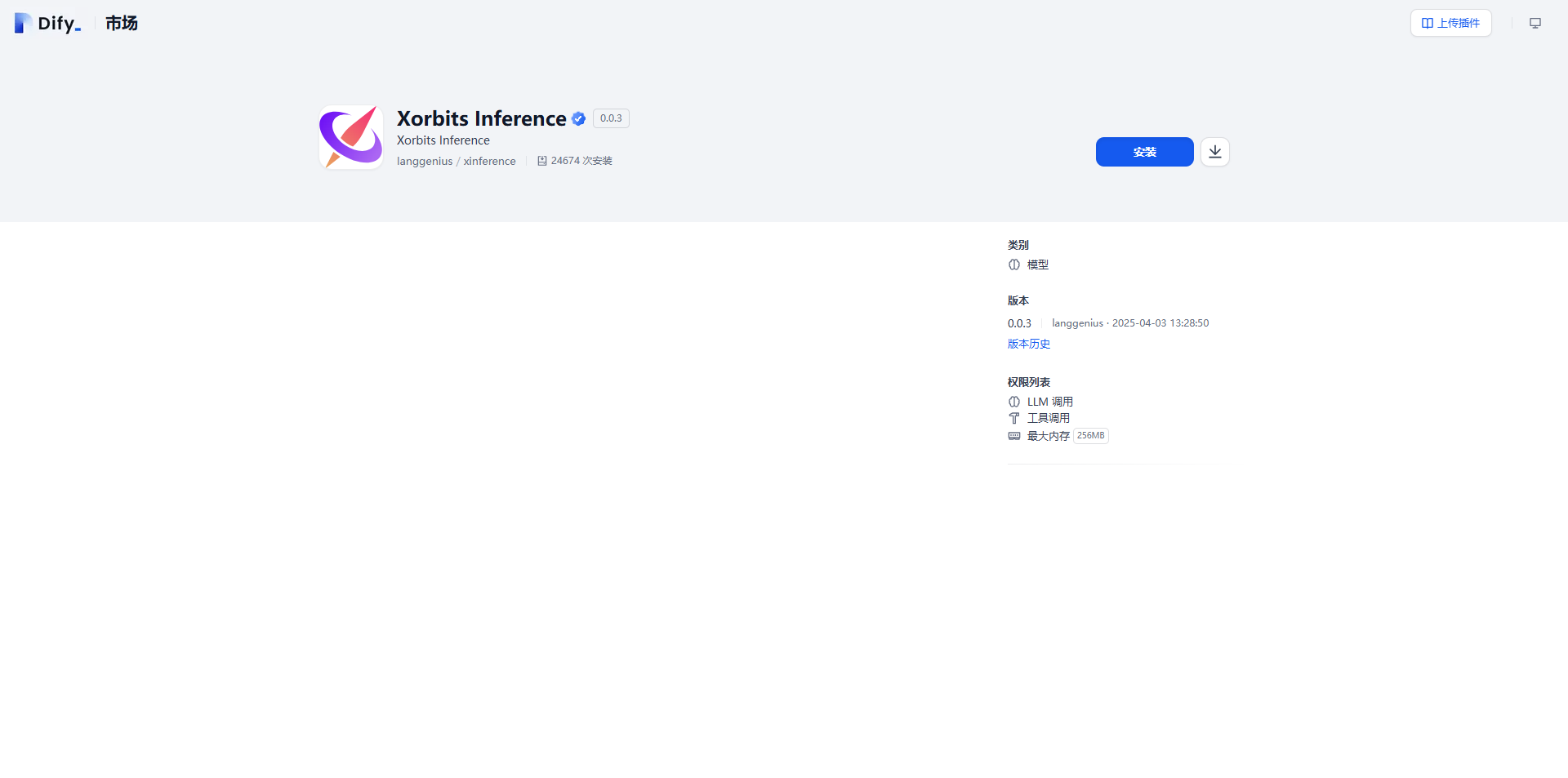
同时,使用 Xinference 官方的 Docker 镜像一键安装和启动 Xinference 服务(需NVIDIA GPU):
docker run -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
参考链接:Xinference自定义模型
机器上只有CPU或想直接配置Xinference服务,也可以先用conda配置一个Python环境,然后安装完整版的Xinference服务:
- 创建一个名为xinference的conda环境:
conda create -n xinference python=3.11
- 激活环境,安装torch框架和完整的xinference(包含依赖项):
pip install torch
pip install xinference[all]
- 启动Xinference本地服务器(Win10/11 IP应使用(替换为你的IP)或通过
ipconfig获取的本机ip):
conda activate xinference
xinference-local --host (替换为你的IP) --port 9999
# 例:
# xinference-local --host 192.168.1.123 --port 9999
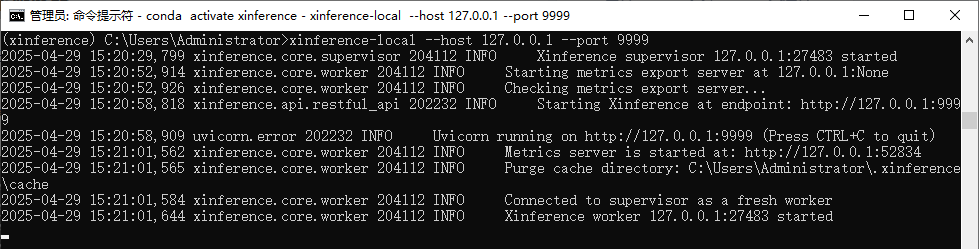
(注:若需要将xinference部署的模型提供给Dify调用,建议将IP写为通过ipconfig命令查出的本机IP,不建议直接使用本地回环)
- 验证服务可用性:
conda activate xinference
curl http://(替换为你的IP):9999/v1/cluster/auth
输出:{“auth”:false}
// 响应含义:当前集群未启用认证功能
{"auth":false} // 表示无需API密钥即可访问
{"auth":true} // 表示需要X-API-Key请求头
6.①可以进入xinference的WebUI界面:http://(替换为你的IP):9999/ui/#/launch_model/rerank,选择bge-reranker-v2-m3模型:
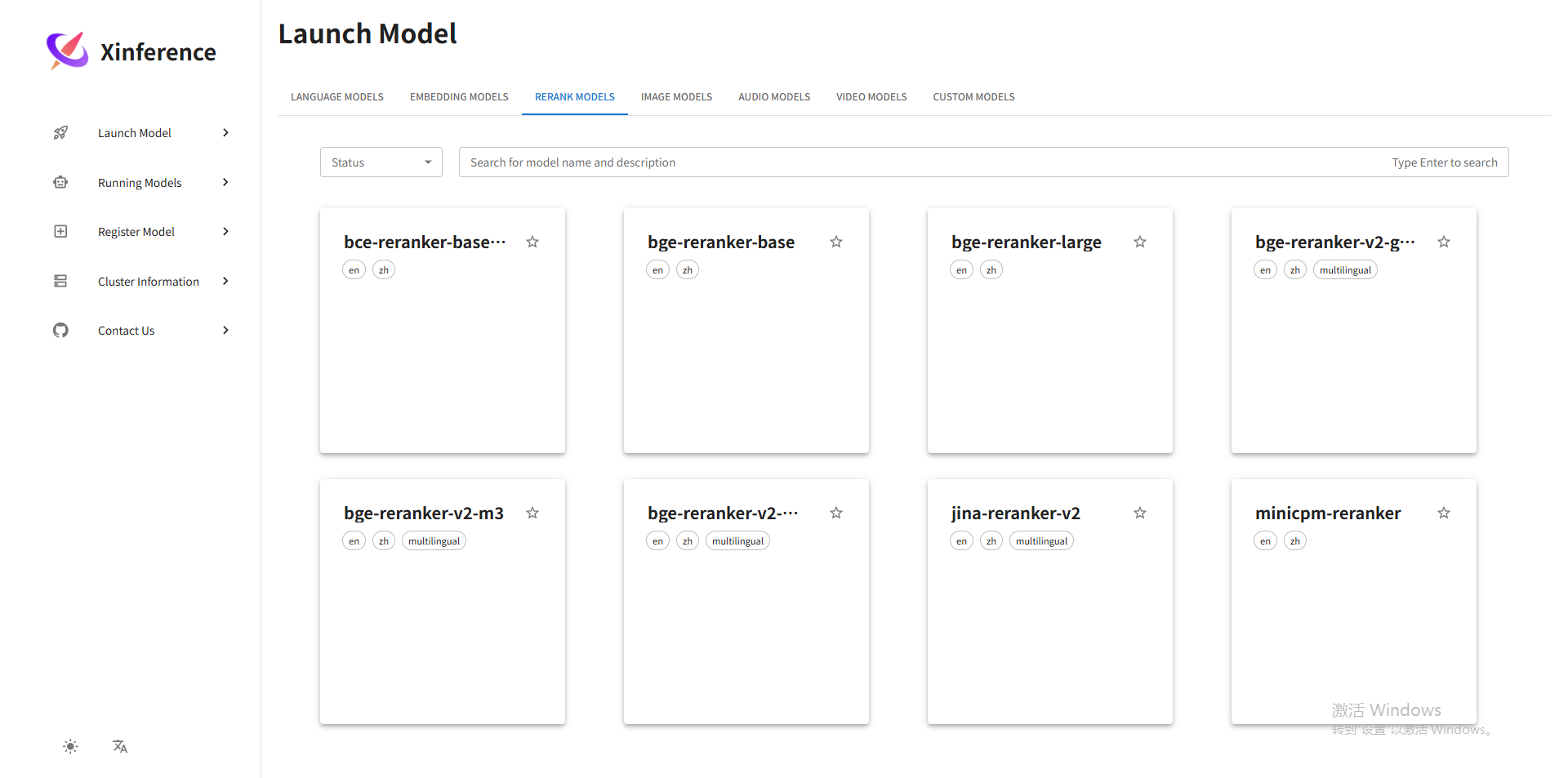
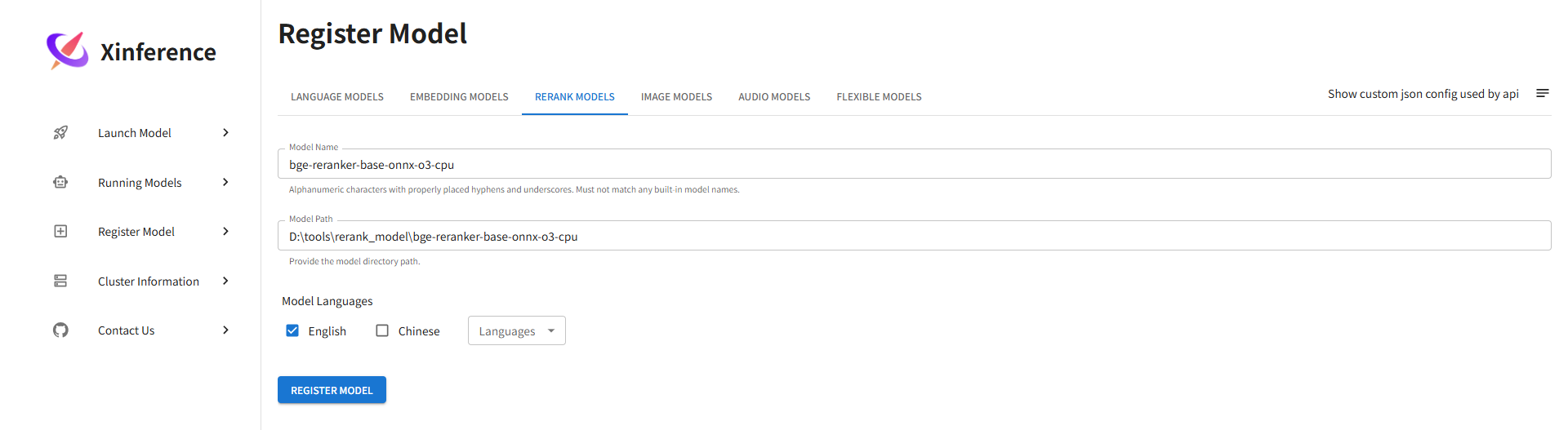
② 也可以用从Hugging Face下载的CPU版本的reranker模型bge-reranker-base-onnx-o3-cpu:
进入xinference的WebUI界面:http://(替换为你的IP):9999/ui/#/register_model/rerank添加下载的模型:
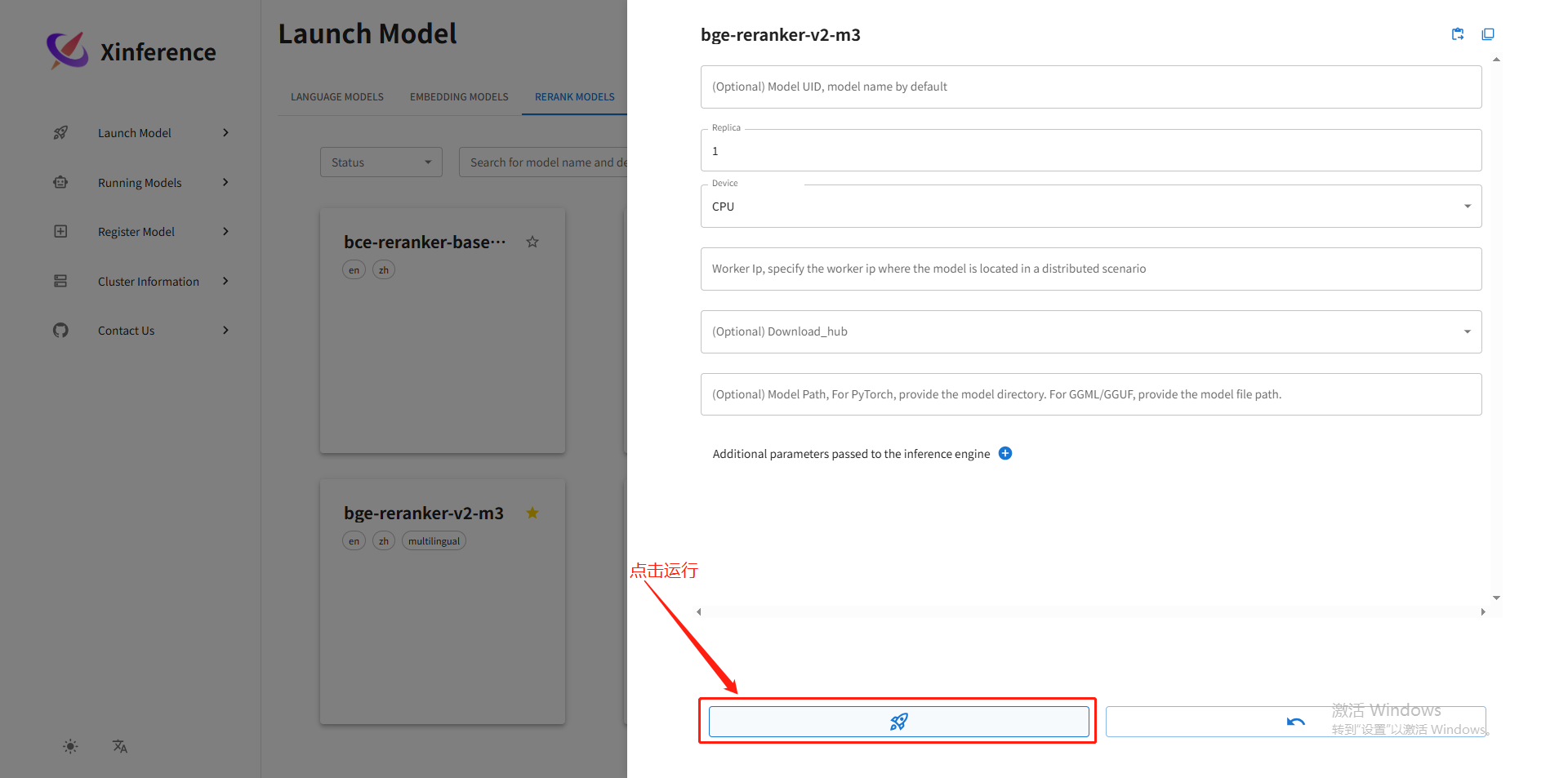
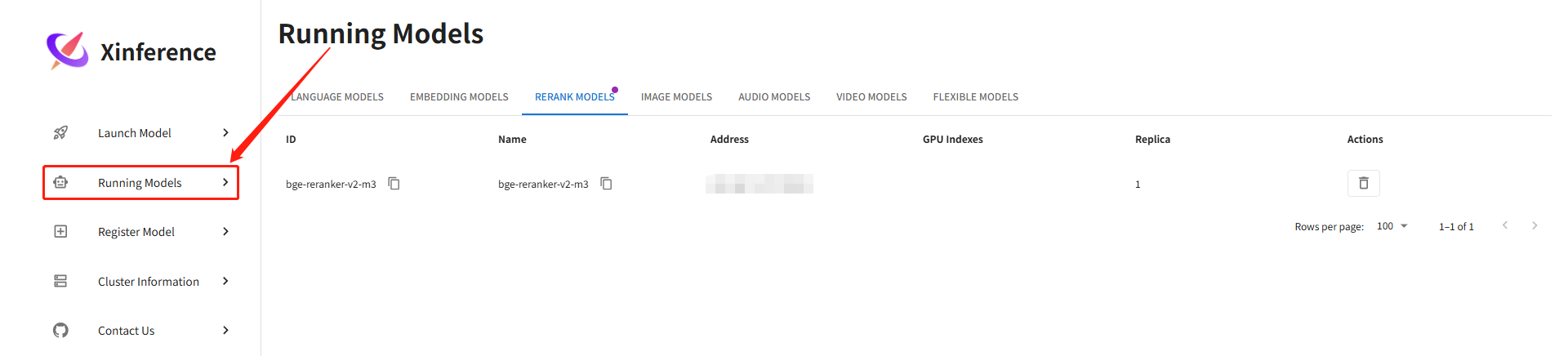
点击Running Models,可以看到模型已经启动:
配置步骤同上,在Dify中将Rerank模型配置为xinference服务:

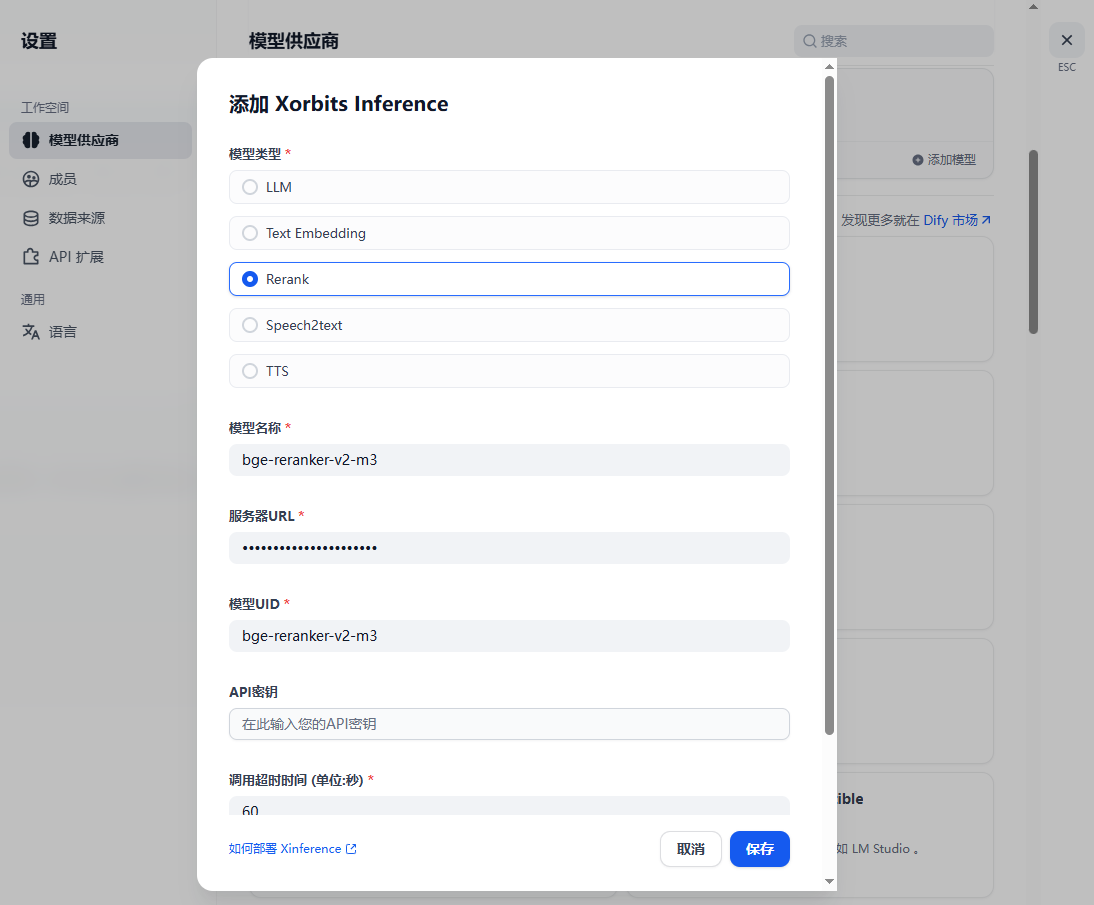
展开后可以看到Rerank模型已经配置成功:
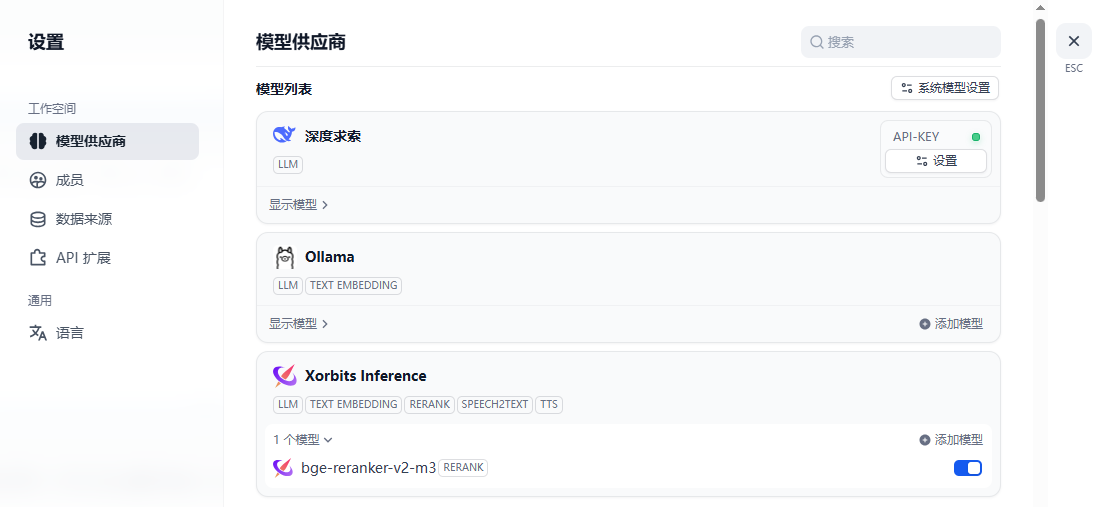
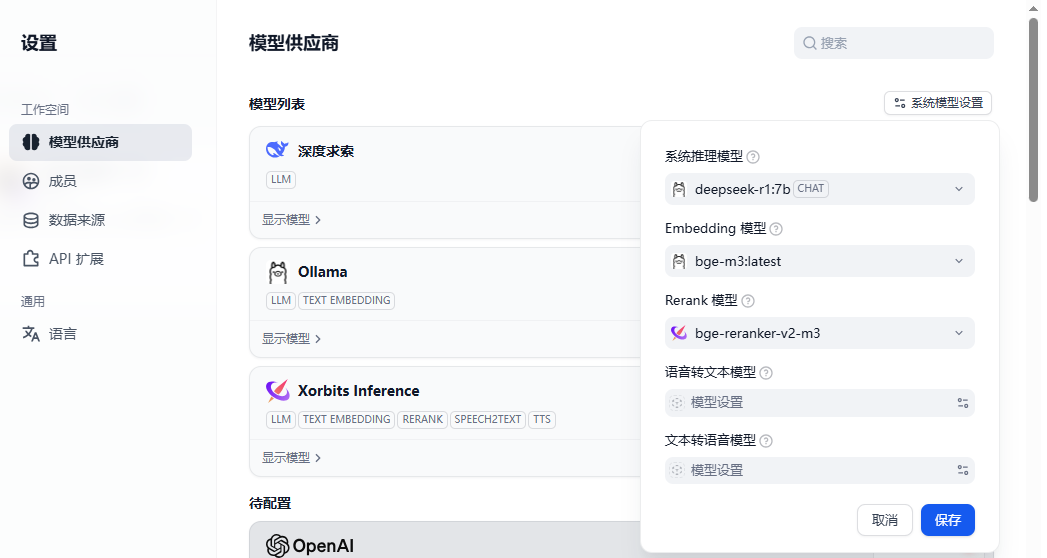
硬件要求
CPU推理:支持x86_64或ARM64架构。
GPU推理:需要NVIDIA GPU,建议使用CUDA兼容的显卡,如RTX 30系列或A100等。Jetson Nano等边缘设备也可运行,但性能受限。
参考:
Dify模型集成白皮书:https://inference.readthedocs.io/zh-cn/latest/models/custom.html
bge-reranker-base和bge-reranker-large: https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker
Cohere: https://txt.cohere.com/rerank/
ERROR while importing the reranker model using xinference #7558:https://github.com/langgenius/dify/issues/7558
Xinference自定义模型指南:https://inference.readthedocs.io/zh-cn/latest/models/custom.html




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











