







由中国科学院自动化研究所和中科闻歌联合推出DeepSeek-V3/R1满血版671B全参数微调的开源解决方案【1】。包括了硬件、环境、部署等细节。另外,从这个项目中,一些常用的知识也值得我们去学习,相关知识点也列出了6个,方便后面一起学习。
1. 硬件配置
32台相同配置的机器构成集群,共享100TB存储空间,具体的硬件配置为:
-
GPU:8 x NVIDIA H100 80GB HBM3
-
CPU:Intel(R) Xeon(R) Platinum 8463B (96 Cores)
-
内存:2.0TB DDR4
-
存储:100TB NVMe SSD
-
网络:InfiniBand 400G
-
操作系统:Ubuntu 22.04
-
CUDA:CUDA 12.6
2. 训练环境
基于xtuner框架进行训练,具体为:
-
基于xtuner框架的扩展和改进
支持 DeepSeek V3/R1(即 `DeepseekV3ForCausalLM` 模型架构)的全参数微调。
支持数据并行(DeepSpeed ZeRO based DP)和序列并行(Sequence Parallel, SP)。
-
Python 环境
创建环境:conda create -n ds_env python=3.10
激活环境:conda activate ds_env
安装依赖:pip install -r requirements.txt
3. 数据
数据格式:
<|begin▁of▁sentence|>You are a helpful assistant.<|User|>用户问题<|Assistant|><think>\n思考过程\n</think>\n\n最终回答<|end▁of▁sentence|>4. 不同并行策略等配置下模型训练的可行性
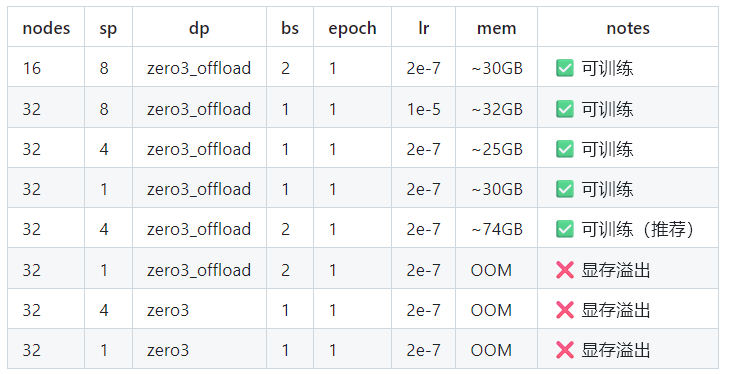
注:nodes:每次实验使用的机器数量,sp:序列并行度,dp:数据并行方式,bs:单卡 batch size,epoch:迭代轮次,lr:学习率,mem:单卡显存,notes:实验记录和备注
5. 模型推理部署
环境准备: 确保已创建名为vllm的环境。
部署方式:
Slurm集群部署:使用sbatch提交作业脚本vllm_deploy_slurm.sh,适合集群环境。
pdsh启动部署:适用于特定机器部署,需手动设置环境变量并启动Ray和 vLLM 服务。
测试接口:
部署完成后,通过 `curl` 请求测试接口是否正常响应。示例请求:
http://[HEAD_NODE]:8000/v1/chat/completions如果返回预期结果,说明部署成功。
关注点:
使用vLLM进行推理部署。
部署支持半精度(bf16/fp16),推荐 4 台机器、32 张 GPU 卡。
需配置 Ray 服务和 vLLM 参数。
通过 `curl` 测试接口验证部署是否成功。
6. 知识点
知识点1: XTuner
XTuner是一个高效、灵活、全能的轻量化大模型微调工具库。【2】支持模型:

知识点2: 序列并行(Sequence Parallelism, SP)
序列并行(Sequence Parallelism, SP)是一种针对长序列输入优化的并行策略,主要用于解决大规模语言模型(LLM)在处理长序列时面临的显存瓶颈问题。
它是一种将输入序列切分为多个子序列,并将这些子序列分配到不同设备(如 GPU)上进行并行计算的方法。它通过减少单个设备需要存储的激活状态(activations)和中间结果,显著降低了显存需求,从而支持更长序列的训练。
从实现方法来看,最主流有Ring-Attention和DeepSpeed Ulysess。
Ring-Attention是一种用于扩展Transformer模型上下文长度的并行计算方法,核心思想是将输入序列分割成多个块,并通过环形通信策略在多个设备上并行处理。核心思想是通过环形通信实现全局上下文的传递,同时将计算分散到多个设备上,降低单设备的显存需求。
Ring-Attention算法流程1. 序列切分:将输入序列沿时间维度切分成多个小块,每个块分配到不同的设备(如 GPU)上。2. 局部计算:每个设备独立计算其子序列的自注意力(局部注意力),生成中间结果(如 key-value 对)。3. 环形通信:将每个设备生成的 key-value 对传递给下一个设备,形成一个环形通信链路。4. 全局聚合:每个设备在收到前一个设备的 key-value 对后,将其与本地的查询(query)进行全局注意力计算。5. 输出合并:最终将所有设备的计算结果合并,得到完整的注意力输出。
DeepSpeed-Ulysses通过 All-to-All通信和序列切分实现高效的序列并行,适合大规模模型训练,且对 GPU 数量扩展友好。
DeepSpeed-Ulysses算法流程1. 序列切分:将输入序列沿时间维度切分成多个子序列,每个子序列分配到不同的 GPU 上。2. All-to-All通信:在注意力计算之前,对每个子序列的Q、K、V进行All-to-All通信,使每个GPU收到完整的序列长度,但仅处理部分注意力头。3. 局部注意力计算:每个GPU在本地计算其分配的注意力头的输出。4. 结果合并:将所有GPU上的局部计算结果合并,得到完整的注意力输出。5. 与ZeRO-3结合:通过ZeRO-3的优化技术进一步降低显存需求,支持超长序列和超大模型的训练。
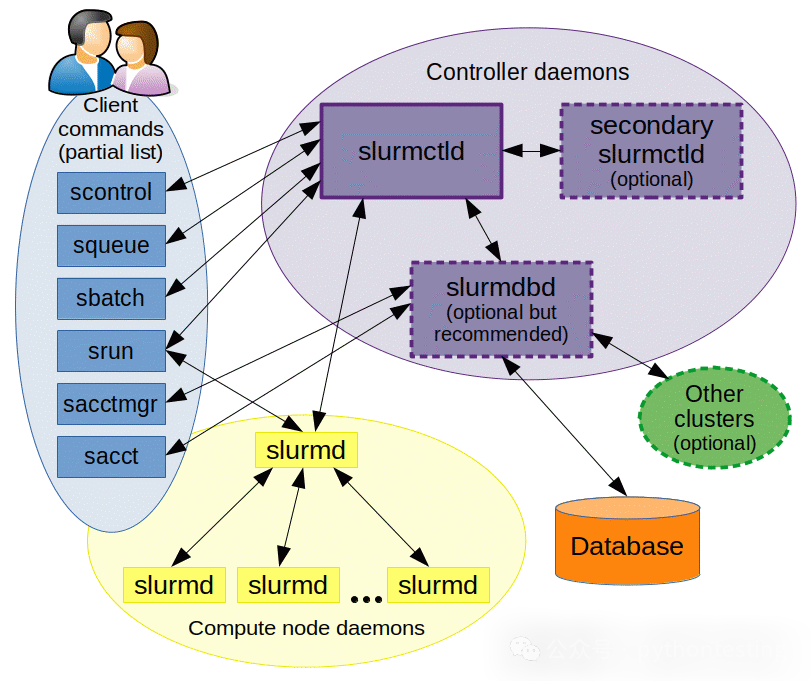
知识点3:Slurm
参考文献【4】,Slurm是一个开源的、容错的、高度可扩展的集群管理和作业调度系统,适用于大型和小型 Linux 集群。它不需要修改内核即可运行,相对独立。
Slurm的三大功能:
第一,分配计算节点资源(独占或非独占)给用户,供其在一定时间内使用。
第二,提供框架以启动、执行和监控分配节点上的工作(通常是并行作业)。
第三,通过管理待处理作业队列来仲裁资源争用。
Slurm 由两部分组成:
slurmd:在每个计算节点上运行的守护进程,提供容错的分层通信。
slurmctld:在管理节点上运行的中央守护进程(可选故障转移副本)。
Slurm 管理的实体包括:
节点:计算资源。
分区:将节点分组成逻辑(可能重叠)集合。
作业:分配给用户的资源分配,持续特定时间。
作业步骤:作业内的一组(可能并行)任务。
Slurm组件:
知识点4: pdsh工具
pdsh是并行分布式运维工具。全称是parallel distributed shell,与pssh类似,pdsh可并行执行对远程目标主机的操作。
pdsh的应用场景与pssh基本相同,都用于大批量服务器的配置、部署、文件复制等运维操作。在使用pdsh时,仍需要配置本地主机和远程主机间的单向SSH信任。另外,pdsh还附带了pdcp命令,此命令可以将本地文件批量复制到远程的多台主机上,这在大规模的文件分发环境下是非常有用的。
它方便集群管理、软件部署与配置、分布式计算环境、日志和监控等相关管理与命令的执行。例如在DeepSeek-V3/R1-617B中的pdsh启动部署。
知识点6: Ray集群
参考【5】,Ray集群是一个分布式计算环境,支持从单机到大规模集群的无缝扩展,Ray集群的组件:
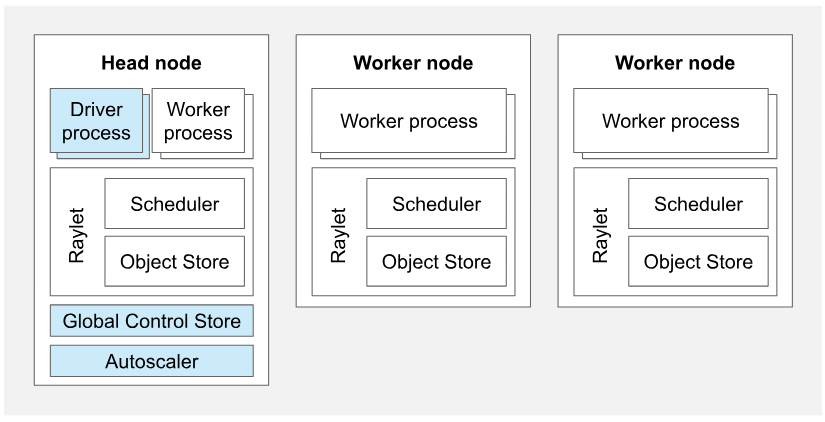
| 概念 | 描述 | 关键点 |
|---|---|---|
| Ray 集群 | 由一个头节点和多个工作节点组成,支持动态扩展。 |
|
| 头节点 | 负责集群管理和调度的特殊节点。 |
|
| 工作节点 | 执行用户代码的普通节点。 |
|
7. 参考
【1】github:https://github.com/ScienceOne-AI/DeepSeek-671B-SFT-Guide/tree/main
【2】Xtuner: https://github.com/InternLM/xtuner
【3】DeepSpeed: https://github.com/deepspeedai/DeepSpeed
【4】slurm, https://slurm.schedmd.com/
【5】Ray:https://www.ray.io/,https://github.com/ray-project/ray
更多内容,请关注公众号“快乐王子AI说”。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









