









前言
Mycat的应用场景之一就是实现多租户,多租户应用,每个应用一个库,但应用程序只连接 Mycat,从而不改造程序本身,实现多租户化;接下来我们使用mycat,结合druid拦截sql添加注释头,利用zk修改mycat配置文件中的schema、dataNode节点等信息,来实现多租户。
三种实现方案
多租户在数据存储上存在三种主要的方案,分别是:
独立数据库
这种方案一个租户一个数据库,这种方案的用户数据隔离级别最高,安全性最好,但成本也高。
优点:
为不同的租户提供独立的数据库,有助于简化数据模型的扩展设计,满足不同租户的独特需求;
如果出现故障,恢复数据比较简单。
缺点:
增大了数据库的安装数量,随之带来维护成本和购置成本的增加。
共享数据库,独立Schema
这是方案即多个或所有租户共享 Database,但是每个租户一个 Schema。
优点:
为安全性要求较高的租户提供了一定程度的逻辑数据隔离,并不是完全隔离;
每个数据库可以支持更多的租 户数量。
缺点:
如果出现故障,数据恢复比较困难,因为恢复数据库将牵扯到其他租户的数据;
如果需要跨租户统计数据,存在一定困难。
共享数据库,共享Schema,共享数据表
这种方案即租户共享同一个 Database、同一个 Schema,但在表中通过 TenantID 区分租户的数据。 这是共享程度最高、隔离级别最低的模式。
优点:
三种方案比较,第三种方案的维护和购置成本最低,允许每个数据库支持的租户数量最多。
缺点:
隔离级别最低,安全性最低,需要在设计开发时加大对安全的开发量;
数据备份和恢复最困难,需要逐表逐条备份和还原;
如果希望以最少的服务器为最多的租户提供服务,并且租户接受以牺牲隔离级别换取降低成本,这种方案最 适合。
如何选择
首先,mysql数据库中没有schema的概念,所以对于mysql用户来说,只有两种方案:独立数据库和共享数据库,共享数据表。
独立数据库可以做到各租户数据互不影响,所以我们选择的是独立数据库。
而对于上面的三种方案来说:
如果想有较好的隔离性,选择方案一或方案二,但是设计和实现的难度和成本较高。
如果想有较好的共享性,选择方案三或方案二,这时运行成本较低,并且同一运行成本下支持的用户较多。
如果租户数量较多,可以选择方案三或方案二,这样可以降低成本
如果想针对每一租户提供附加的服务,比如数据备份和恢复等,可以选择方案一,这样有更好的隔离性
独立数据库架构实现多租户
选用技术
mycat + druid + zk
实现方式
mycat实现分库,拦截带有注释头的sql流向不同的数据库;druid拦截初始sql,添加注释头;程序通过zk修改mycat的配置文件,比如添加新租户时,通过zk添加新的schema和datanode节点,然后同步到mycat的schema.xml文件。
注解
MyCat对自身不支持的Sql语句提供了一种解决方案——在要执行的SQL语句前添加额外的一段由注解SQL组织的代码,这样Sql就能正确执行,这段代码称之为“注解”。
注解的使用相当于对mycat不支持的sql语句做了一层透明代理转发,直接交给目标的数据节点进行sql语句执行,其中注解SQL用于确定最终执行SQL的schema或DB。
注解格式
/*!mycat:schema=[schemaName] */
schema.xml配置文件
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
//每个租户对应一个schema节点
<schema name="667078BnaL7HrFBqYVsLude4MNVd" checkSQLschema="false" sqlMaxLimit="100" dataNode="auth_667078_integral_dev"/>
<schema name="111222BnaL7HrFBqYVsLude4MNVd" checkSQLschema="false" sqlMaxLimit="100" dataNode="auth_111222_integral_dev"/>
<schema name="667098BnaL7HrFBqYVsLude4MNVd" checkSQLschema="false" sqlMaxLimit="100" dataNode="auth_667098_integral_dev"/>
<schema name="667108BnaL7HrFBqYVsLude4MNVd" checkSQLschema="false" sqlMaxLimit="100" dataNode="auth_667108_integral_dev"/>
//auth服务器中的四个库,是四个租户的数据库
<dataNode name="auth_667078_integral_dev" dataHost="auth" database="667078_integral_dev"/>
<dataNode name="auth_111222_integral_dev" dataHost="auth" database="111222_integral_dev"/>
<dataNode name="auth_667098_integral_dev" dataHost="auth" database="667098_integral_dev"/>
<dataNode name="auth_667108_integral_dev" dataHost="auth" database="667108_integral_dev"/>
<dataHost balance="0" maxCon="1000" minCon="10" name="auth" writeType="0" switchType="1" slaveThreshold="100" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.25.54:3306" password="XXX" user="XXX"/>
</dataHost>
</mycat:schema>
server.xml
在server.xml配置文件的user用户配置节点,将所有的schema节点的name属性值配置在property属性中。
<user name="root">
<property name="password">123456</property>
<property name="schemas">667108BnaL7HrFBqYVsLude4MNVd,667098BnaL7HrFBqYVsLude4MNVd,111222BnaL7HrFBqYVsLude4MNVd,667078BnaL7HrFBqYVsLude4MNVd</property>
</user>说明
对SQL加注解的实现则交由druid的插件功能完成,通过自定义druid的Interceptor类,拦截要执行的sql语句加上对应注解,实现方式见下边的 2.2、过滤sql语句。这样就实现了数据库的多租户改造。下面分几个部分来说明。
前提说明
公司旗下,有权限项目和多个其他项目,权限项目实现了多租户的配置,其他项目如果接入多租户,只需要按步骤配置即可实现多租户。
springBoot实现场景图
接下来的配置以springBoot的项目为例,使用场景图如下:

步骤1到步骤2,不涉及到服务间调用,需要配置两个过滤器,步骤1到步骤3到步骤4,需要服务间调用,除了配置两个过滤器外,还需要维护租户id的传递工作,接下来我们就看看如果一个项目想引入多租户,需要配置哪些方面。
项目引入多租户代码实现
1.引入依赖项
公司封装了工具服务itoo-tool,工具服务中包括多租户的一个文件,所以需要引入该服务,使用其中的配置文件,需要使用的主要配置文件就是场景图中的两个过滤器。

2、过滤器配置
2.1、过滤request请求
拦截浏览器发来的请求,获取租户id,并放到ThreadLocal中
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest)servletRequest;
String companyId = request.getHeader("companyId");
TenancyContext.TenancyID.set(companyId);
chain.doFilter(servletRequest, servletResponse);
}2.2、过滤sql语句
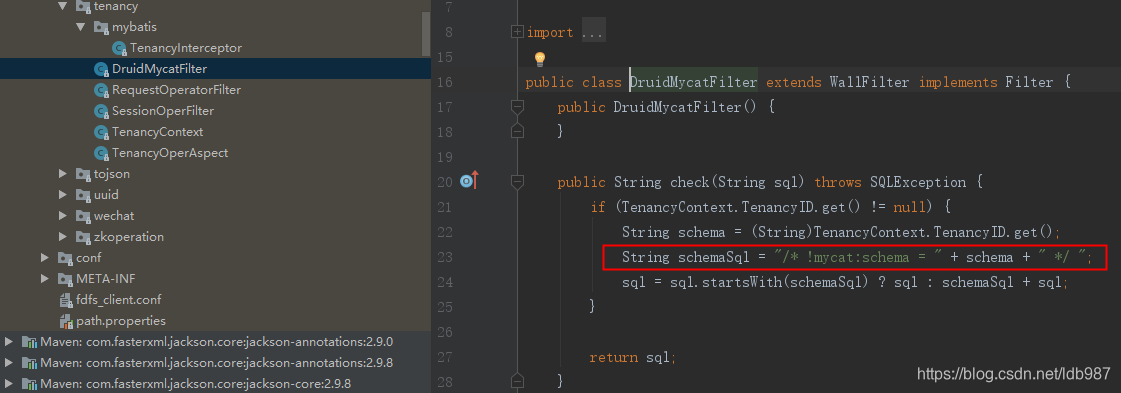
数据库连接池使用的是druid,所以过滤sql,添加mycat注释头,也用druid拦截实现。首先自定义DruidMycatFilter,继承durid的WallFilter,重写check方法,拦截sql,添加注释头,然后流到数据库的sql就是带着注释头的。然后配置mycatFilter Bean,实例化自定义的DruidMycatFilter,注册到spring容器。
@Configuration
public class DruidMycatConfig {
private static final String FILTER_MYCAT_PREFIX = "spring.datasource.druid.filter.mycat";
@Bean
@ConfigurationProperties(FILTER_MYCAT_PREFIX)
@ConditionalOnProperty(prefix = FILTER_MYCAT_PREFIX, name = "enabled", matchIfMissing = true)
@ConditionalOnMissingBean
public DruidMycatFilter mycatFilter(){
//指向第一步中依赖项中的DruidMycatFilter文件
return new DruidMycatFilter();
}
}DruidMycatFilter文件主要是重写了Druid的拦截器方法,拦截到sql后,在sql前边添加了上边提到的注解,用于指定相应的逻辑库。
3、服务间调用配置
服务间调用大致分两种情况,一种就是前段请求后端,后端连接mycat;另一种就是设计服务A服务B,这时就需要服务A将租户id传给服务B,然后服务B进行连接mycat。
但服务A调用服务B时,首先我们会在服务A的@EnableFeignClient注解的请求头中加入服务B的api,
@EnableFeignClients(basePackages ={"com.dmsdbj.integral.training.api"})然后通过拦截器拦截请求,获取租户idcompanyId,然后将其放到ThreadLocal中。
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
this.initUserInfo((HttpServletRequest)request);
chain.doFilter(request, response);
}
private void initUserInfo(HttpServletRequest request) {
//拦截请求,获取租户id
String companyId = request.getHeader("companyId");
String token = request.getHeader("Authorization");
try {
UserInfoModel userInfoModel = new UserInfoModel();
if (StringUtils.isNotBlank(companyId)) {
companyId = URLDecoder.decode(companyId, "UTF-8");
//将租户id放到userInfoModel
userInfoModel.setCompanyId(companyId);
}
if (StringUtils.isNotBlank(token)) {
token = URLDecoder.decode(token, "UTF-8");
userInfoModel.setToken(token);
}
//将userInfoModel放到TheadLocal中
UserInfoContext.setUser(userInfoModel);
} catch (UnsupportedEncodingException var5) {
log.error("init userInfo error", var5);
}
}4、前端拦截器配置
项目是前后端分离的,需要在前端连接器中配置租户id,然后传到后端。
5、最后就是数据库连接
如果之前该接入多租户的项目没有用到mycat,那么只需要把之前连接musql的地方换成mycat,端口由mysql默认的3306编程mycat的8066即可。
权限项目实现多租户
公司的其他项目如果想引入多租户,需要在权限项目提供的审批界面发申请,然后权限项目在审批申请的时候,如果申请通过,项目会做两件事:一件是创建该租户的数据库、表结构;另一件事修改mycat的配置文件,主要是schemal.xml。接下来我们主要介绍这两件事儿,如何自动实现。
创建租户的数据库及表结构
- 首先创建一个租户id
- 接着利用租户id+项目id+环境,拼接层数据库名
- 然后创建数据库及数据库表,项目数据表sql在权限项目中都有存储,读取相应的sql文件,然后执行就可以
//1.创建租户id
if (StringUtils.isEmpty(companyProjectModel.getSchoolNo())) {
schoolNo = companyService.queryMaxDbNum();
if (schoolNo == 0) {
schoolNo = dbSchoolNo;
} else {
schoolNo = schoolNo + 10;
}
}else {
schoolNo = Integer.parseInt(companyProjectModel.getSchoolNo());
}
String dataBaseName = schoolNo + "_" + companyProjectModel.getProjectNameEn()+"_"+env;
//2.查询该注册用户的详细信息,方便以后存储
CompanyExample example = new CompanyExample();
CompanyCriteria criteria = example.createCriteria();
criteria.andIsDeleteEqualTo((byte) 0);
criteria.andIdEqualTo(id);
List<CompanyEntity> companyEntities = companyService.selectByExample(example);
CompanyEntity companyEntity = new CompanyEntity();
if (!CollectionUtils.isEmpty(companyEntities)) {
companyEntity = companyEntities.get(0);
}
//3.根据生成的schoolNo创建数据库并执行SQL创建数据表等
String userId = BaseUuidUtils.base58Uuid();
if (createDatabase(dataBaseName)){
if (createDbTable(dataBaseName, companyEntity, userId,companyProjectModel.getProjectNameEn())){
..........
}
}创建数据库表的代码如下:
private boolean createDbTable(String dataBaseName, CompanyEntity companyEntity, String userId,String projectNameEn) {
boolean flag=true;
Connection conn = null;
PreparedStatement pstmt = null;
try {
//执行SQL脚本创建数据库表
Class.forName(dbDriver);
String newDbUrl = dbUrl + dataBaseName + "?useUnicode=true&characterEncoding=UTF-8";
conn = DriverManager.getConnection(newDbUrl, dbUserName, dbPassWord);
ClassPathResource rc = new ClassPathResource("sqlfile/"+projectNameEn+dbenv);
EncodedResource er = new EncodedResource(rc, "utf-8");
boolean exists = rc.exists();
if (exists==true) {
try {
ScriptUtils.executeSqlScript(conn, er);
} catch (Exception e) {
logger.error("创建数据表失败!", e);
flag=false;
}
}else{
flag=false;
}
} catch (Exception e) {}项目各环境对应的数据库表sql

修改mycat的schemal.xml配置文件
执行完上边的步骤,表示该租户已创建成功。然后我们需要修改mycat的schemal.xml文件,添加新的schemal,我们选择的是通过zookeeper来添加节点,为什么选择zk呢 ?因为mycat支持通过zk来修改配置文件信息,配置简单,使用方便。
配置zk管理mycat集群
只需要配置myid.properties文件,zk即可管理mycat。
loadZk=true
zkURL=192.168.152.130:2181
clusterId=mycat-cluster-1
myid=mycat_fz_01
clusterNodes=mycat_fz_01,mycat_fz_02,mycat_fz_04
#server booster ; booster install on db same server,will reset all minCon to 1
type=server
boosterDataHosts=dn2,dn3
//myid.properties配置说明:
//loadZk:默认值false。代表mycat集群是否使用ZK,true表示使用
//zkURL:zk集群的地址
//clusterId:mycat集群名字
//myid:当前的mycat服务器名称
//clusterNodes:把所有集群中的所有mycat服务器罗列进行以逗号隔开,比如:clusterNodes=mycat_fz_01,mycat_fz_02,mycat_fz_03使用zookeeper的客户端工具ZooInspector连接zookeeper,即可看到mycat的树节点和mycat的conf目录下的schema.xml和rule.xml文件是对应的,这样就可以通过修改zk中的mycat配置文件中的schema、dataNode节点信息。
代码实现:
//修改zk的配置:租户id,数据库名称
if (zkOperation.createSchema(companyId,database)){
//记录发送邮件应该成功的次数标志
sendFlag=true;
}
package com.dmsdbj.itoo.tool.zkoperation;
@Component
public class ZkOperation {
private static final Logger logger = LoggerFactory.getLogger(ZkOperation.class);
@Value("${ZK_IP}")
private String zkIp;
@Value("${ZK_Nodes}")
private String zkNodes;
@Value("${dataHost}")
private String dataHost;
private static final String SCHEMA_JSON = "schemaJson";
private static final String USER_JSON = "userJson";
private static final String DATA_NODE_JSON = "dataNodeJson";
public ZkOperation() {
}
//传入租户id和数据库名
public boolean createSchema(String companyId, String databaseName) {
boolean flag = false;
List<String> nodesList = this.getZkNodes();
Iterator var5 = nodesList.iterator();
while(var5.hasNext()) {
String aNodesList = (String)var5.next();
flag = this.create(companyId, databaseName, aNodesList);
if (!flag) {
break;
}
}
return flag;
}
//创建新的节点信息
private boolean create(String companyId, String databaseName, String path) {
String dnName1 = this.dataHost;
//读取配置文件已有的信息
Map<String, String> jsonMap = this.readSchemaData(path);
if (jsonMap.isEmpty()) {
return false;
} else {
//获取配置文件中的schema、datanode、user三部分信息
String schemaJson = (String)jsonMap.get("schemaJson");
List<eSchema> schemasList = JSON.parseArray(schemaJson, eSchema.class);
String userJson = (String)jsonMap.get("userJson");
List<eUser> userList = JSON.parseArray(userJson, eUser.class);
String dataNodeJson = (String)jsonMap.get("dataNodeJson");
List<eDataNode> dataNodeList = JSON.parseArray(dataNodeJson, eDataNode.class);
eProperty prope = new eProperty();
StringBuilder sbSchema = new StringBuilder();
eUser user = this.getUser(userList);
if (user != null) {
prope = this.getProperty(user.getProperty());
}
//将新的节点信息插入
String dnName = dnName1 + "_" + databaseName;
eSchema schema = new eSchema();
schema.setName(companyId);
schema.setDataNode(dnName);
schemasList.add(schema);
eDataNode node = new eDataNode();
node.setName(dnName);
node.setDataHost(this.dataHost);
node.setDatabase(databaseName);
dataNodeList.add(node);
sbSchema.append(companyId).append(",");
if (prope != null) {
prope.setValue(sbSchema + prope.getValue());
}
Map<String, String> newJsonMap = new HashMap(16);
newJsonMap.put("userJson", JSON.toJSON(userList).toString());
newJsonMap.put("schemaJson", JSON.toJSON(schemasList).toString());
newJsonMap.put("dataNodeJson", JSON.toJSON(dataNodeList).toString());
boolean flag = this.writeSchemaData(newJsonMap, path);
return flag;
}
}
private List<String> getDataBase() {
List<String> list = new ArrayList();
String str = this.getProperties("DataBases");
String[] arr = str.split(",");
list.addAll(Arrays.asList(arr));
return list;
}
private List<String> getZkNodes() {
List<String> list = new ArrayList();
String str = this.zkNodes;
String[] arr = str.split(",");
list.addAll(Arrays.asList(arr));
return list;
}
private String getProperties(String key) {
Properties pro = new Properties();
try {
System.out.println((new File(".")).getAbsolutePath());
FileInputStream in = new FileInputStream("src/profiles/conf.properties");
pro.load(in);
} catch (FileNotFoundException var5) {
logger.error("ZkOperation.getProperties():path.properties文件未找到");
} catch (IOException var6) {
logger.error("ZkOperation.getProperties():文件加载异常");
}
return pro.getProperty(key);
}
//读取配置文件中已有信息
private Map<String, String> readSchemaData(String path) {
Map<String, String> jsonMap = new HashMap(16);
ZkClient zc = this.getZkConnection();
if (zc == null) {
return jsonMap;
} else {
String schemaJson = (String)zc.readData(path + "/schema/schema");
String dataNodeJson = (String)zc.readData(path + "/schema/dataNode");
String userJson = (String)zc.readData(path + "/server/user");
jsonMap.put("schemaJson", schemaJson);
jsonMap.put("dataNodeJson", dataNodeJson);
jsonMap.put("userJson", userJson);
return jsonMap;
}
}
public boolean writeSchemaData(Map<String, String> newJsonMap, String path) {
boolean flag;
try {
ZkClient zc = this.getZkConnection();
if (zc == null) {
return false;
}
zc.writeData(path + "/schema/schema", newJsonMap.get("schemaJson"));
zc.writeData(path + "/schema/dataNode", newJsonMap.get("dataNodeJson"));
zc.writeData(path + "/server/user", newJsonMap.get("userJson"));
flag = true;
} catch (Exception var5) {
flag = false;
}
return flag;
}
private ZkClient getZkConnection() {
String ipAddress = this.zkIp;
ZkClient zc = null;
try {
zc = new ZkClient(ipAddress, 10000, 10000, new ItooZkClient());
} catch (Exception var4) {
logger.error("ZkOperation.getZkConnection():连接zk失败");
}
return zc;
}
private eUser getUser(List<eUser> userList) {
Iterator var2 = userList.iterator();
eUser user;
do {
if (!var2.hasNext()) {
logger.debug(" the method of getUser don't get 'eUser' to return");
return null;
}
user = (eUser)var2.next();
} while(!"root".equals(user.getName()));
return user;
}
private eProperty getProperty(List<eProperty> propList) {
Iterator var2 = propList.iterator();
eProperty p;
do {
if (!var2.hasNext()) {
logger.debug(" the method of getProperty don't get 'eProperty' to return");
return null;
}
p = (eProperty)var2.next();
} while(!e_enum_user.schemas.equals(p.getName()));
return p;
}
}
结语
到此,多租户利用mycat+druid+zk就可以实现多租户了,有不正确之处望各位指正。















 6064
6064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











