






lession_2:梯度下降算法(GD)
注意,至此,我们都是讲解线性结构
针对上期的与门结构模型,我们引入一个最简单的误差衡量函数:
其中,y'表示计算值,y为真值,m表示样本量(即输入-训练数据个数)。显然误差函数J(w)【cost function】为一个凸二次型函数,即意味着J(w)存在最小值。而此时我们的主要目的就是找到这个最小值对应的权重参数w。此处变量是w不是x(x为输入样本,即已知量)《误差越小,即模型模仿越成功》
GD
1 什么是梯度?
在单变量的实值函数中,梯度就可以简单地理解为只是导数。对单变量线性函数而言,梯度就是线的斜率。但对于多维变量的函数,梯度为偏导,暗示着多个方向的陡峭程度。在向量微积分中,标量场的梯度其实是一个向量场(vector field)。对于特定函数的某个特定点,它的梯度就表示从该点出发,该函数值增长最为迅猛的方向(direction of greatest increase of a function)。梯度最明显的应用,就是快速找到多维变量函数的极(大/小)值,“梯度递减”的问题所在,那就是它很容易收敛到局部最小值。
2 梯度几何解释
这里讲解最简易的二维几何解释,高维常用等高线形式模拟。
3 数学描述 GD(Gradient Descent,梯度下降:求损失函数最小值:梯度下降;求损失函数最大值:梯度上升。)
假设线性模型:目标函数
y'=wT*x
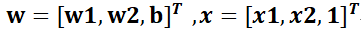
损失函数为:
Update 参数:需要给出w初值与学习率
Realize
现在,我们通过GD来获取最佳参数。(可以思考,为什么最佳参数与给定初值有关)


Code
1 人工设定
import numpy as np
"""
感知机与门实现
x1 x2 y
0 0 0
0 1 0
1 0 0
1 1 1
input x=[x1,x2] w=[w1,w2] b
y=w*xT+b
线性可分,定义阈值为0,y<=0 输出0;y>0,输出1.
w=[0.5,0.5,-0.7]
"""
def And(x1,x2):
x=np.array([x1,x2])
w=np.array([0.5,0.5])
b=-0.7
y=np.sum(w*x)+b
# print (w)
# print (y)
if y<=0 :
y=0
else :
y=1
print(x, y)
return 0
print("与门:")
And(0,0)
And(0,1)
And(1,0)
And(1,1)
2 GD学习
import numpy as np
'''
感知机与门实现
x1 x2 y
0 0 0
0 1 0
1 0 0
1 1 1
input x=[x1,x2] w=[w1,w2] b
y=w*xT+b
线性可分,定义阈值为0,y<0 输出0;y>=0,输出1.
比如w=(8,1,-9)
利用GD训练得到权重参数.
定义一个人NeuralNetwork类
'''
class Neuralnetwork():
def __init__(self):
self.synaptic_weights=np.array([10.0,3.0,-5.0])
self.synaptic_weights=self.synaptic_weights.astype(float)
self.synaptic_weights=self.synaptic_weights.reshape((3,1))
def train(self,train_inputs,train_outputs,train_iterations):
for iteration in range(train_iterations):
#定义一个预测函数,得到预测值
output=self.predict(train_inputs)
#print(output)
#
error=output-train_outputs
g1=np.sum(error*train_inputs[:,0])
g2 = np.sum(error * train_inputs[:, 1])
g3 = np.sum(error * train_inputs[:, 2])
grad=np.array([g1,g2,g3])
grad=grad.reshape((3,1))
print(grad)
print()
self.synaptic_weights-=0.5*grad #step=2
print(self.synaptic_weights)
def predict(self,inputs):
inputs=inputs.astype(float)
output=np.dot(inputs,self.synaptic_weights)
for i in range(4):
if output[i]>0 or output[i]==0:
output[i]=1.0
else :
output[i]=0.0
return output
if __name__=="__main__":
nn=Neuralnetwork()
print("打印初始随机权重:")
print(nn.synaptic_weights)
t_inputs=np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
t_outputs=np.array([[0,0,0,1]]).T
nn.train(t_inputs,t_outputs,20)
print("打印迭代后的权重")
print(nn.synaptic_weights)
#测试
print(nn.predict(t_inputs))















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









