









文章目录
前言
本文参考源码版本为
redis6.2
我们常说 redis 是单线程模型,一般是指正常的 请求处理+周期任务。其中:
- 处理请求包括:包括接收连接、IO监听/读/写以及命令执行。
- 周期任务,如删除过期key、字典 rehash 等。
其实,还有一些非常耗时的操作,redis 通过专用的线程来处理,这里的专用线程,便是我们这篇文章的主角,我们接着往下看~
一、还有谁?
截止到目前,redis 共有三个后台线程,分别是 close_file、aof_fsync和lazy_free:
- close_file 表示关闭相应文件描述符对应的文件(释放套接字、数据空间等)。
- aof_fsync 表示 AOF 刷盘
- lazy_free 表示惰性释放空间
截止 redis6.0 之前,关于 redis 的线程模型,我画了张图,你可以看下:

为了方便,我们将处理用户连接相关的线程称为主线程,反之为后台线程。
换句话说,目前 redis 中存在两种线程(先不谈 redis 6.0 出现的 IO 线程);即,主线程和后台线程。
由于之前系列文章已经介绍了很多主线程相关东西(如果不清楚的话,可以找来看看),本文将主要介绍后台线程。
二、后台线程
1. 初始化
在 server.c#main 函数启动最后阶段,调用了方法 InitServerLast:
// server.c#InitServerLast
void InitServerLast() {
bioInit();
initThreadedIO();
set_jemalloc_bg_thread(server.jemalloc_bg_thread);
server.initial_memory_usage = zmalloc_used_memory();
}
其中,bioInit() 则是后台线程初始化,bio 全名叫 Background I/O ,即后台IO:
void bioInit(void) {
pthread_attr_t attr;
pthread_t thread;
size_t stacksize;
int j;
// 变量初始化
for (j = 0; j < BIO_NUM_OPS; j++) {
pthread_mutex_init(&bio_mutex[j],NULL);
pthread_cond_init(&bio_newjob_cond[j],NULL);
pthread_cond_init(&bio_step_cond[j],NULL);
bio_jobs[j] = listCreate();
bio_pending[j] = 0;
}
// 初始化线程栈大小
pthread_attr_init(&attr);
pthread_attr_getstacksize(&attr,&stacksize);
if (!stacksize) stacksize = 1; /* The world is full of Solaris Fixes */
while (stacksize < REDIS_THREAD_STACK_SIZE) stacksize *= 2;
pthread_attr_setstacksize(&attr, stacksize);
// 创建线程,下标 0,1,2 代表不同的线程
for (j = 0; j < BIO_NUM_OPS; j++) {
void *arg = (void*)(unsigned long) j;
if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize Background Jobs.");
exit(1);
}
bio_threads[j] = thread;
}
}
注意到,这里有个宏定义:
#define BIO_NUM_OPS 3
表示后台线程的数量,也就是说,总共定义了3个后台线程。
另外,有几个参数值得说明:
static pthread_t bio_threads[BIO_NUM_OPS];
static pthread_mutex_t bio_mutex[BIO_NUM_OPS];
static pthread_cond_t bio_newjob_cond[BIO_NUM_OPS];
static pthread_cond_t bio_step_cond[BIO_NUM_OPS];
static list *bio_jobs[BIO_NUM_OPS];
static unsigned long long bio_pending[BIO_NUM_OPS];
- bio_threads 表示后台线程数组
- bio_mutex 互斥量,防止并发
- bio_newjob_cond 新任务条件
- bio_step_cond 停止条件
- bio_jobs 每个线程对应的事件列表(队列)
- bio_pending 表示各后台线程待处理事件数量
注意,以上所有数组都是通过下标对应起来,每一个下标代表一个不同的线程。
接着,我们看到线程创建时指定了处理方法 bioProcessBackgroundJobs,即后台线程执行的主体,我们稍后具体看看。
2. 真面目?
上一步已经创建了 3 个线程,并在创建时指定了一个名叫 bioProcessBackgroundJobs 的处理方法,该方法是3个线程的执行主体,根据 type (数组下标)选择不同的底层处理逻辑:
// bio.c#bioProcessBackgroundJobs
void *bioProcessBackgroundJobs(void *arg) {
struct bio_job *job;
unsigned long type = (unsigned long) arg;
sigset_t sigset;
// 这里的type就是前面说的代表线程的下标:0,1,2
if (type >= BIO_NUM_OPS) {
serverLog(LL_WARNING,
"Warning: bio thread started with wrong type %lu",type);
return NULL;
}
// 设置线程名,方便做监控
switch (type) {
case BIO_CLOSE_FILE:
redis_set_thread_title("bio_close_file");
break;
case BIO_AOF_FSYNC:
redis_set_thread_title("bio_aof_fsync");
break;
case BIO_LAZY_FREE:
redis_set_thread_title("bio_lazy_free");
break;
}
redisSetCpuAffinity(server.bio_cpulist);
makeThreadKillable();
// 给对应的线程上锁
pthread_mutex_lock(&bio_mutex[type]);
/* Block SIGALRM so we are sure that only the main thread will
* receive the watchdog signal. */
sigemptyset(&sigset);
sigaddset(&sigset, SIGALRM);
if (pthread_sigmask(SIG_BLOCK, &sigset, NULL))
serverLog(LL_WARNING,
"Warning: can't mask SIGALRM in bio.c thread: %s", strerror(errno));
// 当线程进入start之后,会通过轮询判断消费队列是否有事件待处理。
while(1) {
listNode *ln;
// 如果没有待处理事件,就通过 wait 进入等待状态(sleep)
if (listLength(bio_jobs[type]) == 0) {
pthread_cond_wait(&bio_newjob_cond[type],&bio_mutex[type]);
continue;
}
// 弹出队首元素
ln = listFirst(bio_jobs[type]);
job = ln->value;
// 我们已经取出了一个任务,可以把锁放开,让主线程继续投递任务事件
pthread_mutex_unlock(&bio_mutex[type]);
// 这里是关键,根据 type 选择该线程要执行的业务逻辑
if (type == BIO_CLOSE_FILE) {
close((long)job->arg1);
} else if (type == BIO_AOF_FSYNC) {
redis_fsync((long)job->arg1);
} else if (type == BIO_LAZY_FREE) {
/* What we free changes depending on what arguments are set:
* arg1 -> free the object at pointer.
* arg2 & arg3 -> free two dictionaries (a Redis DB).
* only arg3 -> free the radix tree. */
if (job->arg1)
lazyfreeFreeObjectFromBioThread(job->arg1);
else if (job->arg2 && job->arg3)
lazyfreeFreeDatabaseFromBioThread(job->arg2,job->arg3);
else if (job->arg3)
lazyfreeFreeSlotsMapFromBioThread(job->arg3);
} else {
serverPanic("Wrong job type in bioProcessBackgroundJobs().");
}
zfree(job);
// 即将进入下一轮处理,加锁控制并发
pthread_mutex_lock(&bio_mutex[type]);
listDelNode(bio_jobs[type],ln);
// 待处理总数减1
bio_pending[type]--;
/* Unblock threads blocked on bioWaitStepOfType() if any. */
pthread_cond_broadcast(&bio_step_cond[type]);
}
}
这个方法逻辑本身并不复杂,每个线程启动后,进入该执行主体(该方法),然后通过无限 while 轮询处理队列中的事件,直到线程被挂起或者服务终止。
细心的你可能已经发现了,这就是典型的 生产者-消费者 模式,主线程负责生产任务事件,然后投递到 队列;后台线程就是我们的消费者,负责从队列取出任务事件并处理。
在 生产者-消费者 模式下,我们需要关注的是共享变量(队列),面临多线程的临界问题,所以就用了 bio_mutex 临界变量(互斥量)来控制并发。
在以上代码中的体现就是:
- 消费者:从队列取任务之前,先上锁,取到之后,立即释放锁;
- 生产者:往队列投递任务之前,先上锁,投递之后,立即释放锁。
3. 触发机制
前面说到,这里使用了典型的 生产者-消费者模式,每一个后台线程都有其对应事件列表(队列),当有事件需要处理时,会发送到对应的后台线程队列,再唤醒后台线程(如果对应线程处于休眠状态),然后执行。
我画了一张图来展示其处理流程,你可以看下:

现在,我们开始溯源,看看生产者(主线程)何时会投递任务事件。
首先,redis 作为典型的事件型驱动框架,信息交流是以事件为媒介,因此,任务事件也做了一层封装:
// bio.c#bio_job
struct bio_job {
time_t time; // job 的创建时间
// 任务参数,如果有超过3个参数的话,可以定义一个指向结构体的指针
void *arg1, *arg2, *arg3;
};
并提供了统一创建任务事件的方法 bioCreateBackgroundJob:
// bio.c#bioCreateBackgroundJob
void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3) {
struct bio_job *job = zmalloc(sizeof(*job));
job->time = time(NULL);
job->arg1 = arg1;
job->arg2 = arg2;
job->arg3 = arg3;
// 往队列投递任务之前先上锁,保证并发安全性
pthread_mutex_lock(&bio_mutex[type]);
listAddNodeTail(bio_jobs[type],job);
bio_pending[type]++;
pthread_cond_signal(&bio_newjob_cond[type]);
// 投递完成后,释放锁
pthread_mutex_unlock(&bio_mutex[type]);
}
然后,通过 bioCreateBackgroundJob 往上找调用方:
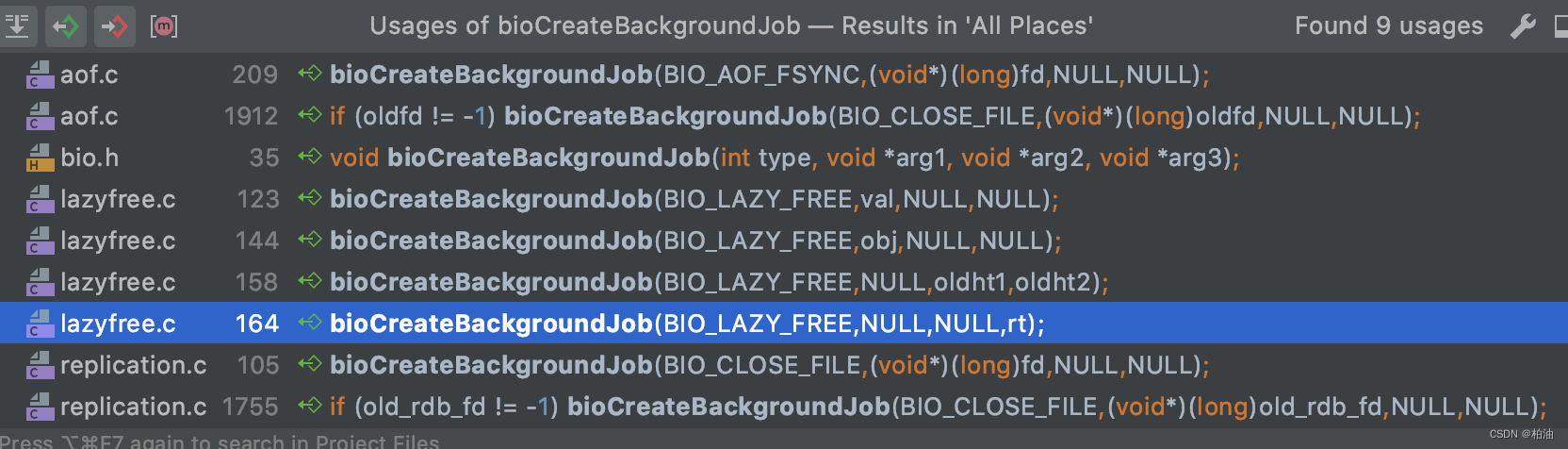
可以清晰的看到,主要有以下几个调用:
1)aof 调用:
- 文件追加写之后刷盘(磁盘)
- 文件 rewrite(重写)之后刷盘
2)lazyfree 删除空间:
- DEL 命令
- FLUSHALL / FLUSHDB 命令
3)关闭文件:
- AOF / RDB 产生的临时文件
- 副本数据同步过程中的临时文件(比如 RDB 文件)
4. 慢操作(blocking)
一个大型应用系统的正常运转需要协调多方资源,网络、磁盘、内存甚至还要处理客户端特性化的需求等等,每个模块都有各自的长短处,速度协调上往往会做出各种妥协。
redis 这种纯内存操作,其瓶颈往往在于网络和内存,而不是 CPU。我们需要一些额外的线程来 分担 主线程的压力,在这些模块之间做一些 适配 工作。
因此,单靠一个线程来处理所有事情,变成了一种奢求。redis 中先后出现了一系列的后台线程,比如 close_file、aof_fsync 以及 lazy_free 都是为了解决这些问题。
这样的处理方式,让主线程专心处理 主营业务 (客户端请求),减少了其后顾之忧!
4.1. close_file
close 是一个系统调用,用来关闭已打开的文件、TCP 套接字等等。具体会释放文件描述符、内存空间或者磁盘空间等等。
我们知道,redis 提供了 AOF 和 RDB持久化功能,以及 replication 副本等机制来保障服务的高可用。
当然,这个过程中会有 数据刷盘、数据传输 以及 数据重写 等一系列操作,其中就会产生空间占用较大的临时文件,这种大临时文件的资源释放,非常适合用专门的线程来处理。
这种专用线程,redis 中取了个名字叫做 bio_close_file,我们来看看源码中的位置:
// bio.c#bioProcessBackgroundJobs
switch (type) {
case BIO_CLOSE_FILE:
redis_set_thread_title("bio_close_file");
break;
case BIO_AOF_FSYNC:
redis_set_thread_title("bio_aof_fsync");
break;
case BIO_LAZY_FREE:
redis_set_thread_title("bio_lazy_free");
break;
}
当然,这段代码是后面才加上的,主要是为了更方便的做一些监控。
4.2. aof_fsync
由于磁盘和内存之间较大的速度差异,一般情况下,操作系统内核设有高速缓冲区(内核缓冲区),通过 write 等系统调用写入的数据都是暂存于缓冲区。
因此,真正的磁盘 IO 操作都是从内核缓冲区读取数据,然后执行真正的刷盘操作;一般情况下,根据系统内核自身的刷盘机制即可,当然,也可以通过 fsync 这种手动调用,直接进行数据刷盘。
fsync 函数只对由文件描述符 fd 指定的文件起作用,并且等待写磁盘操作结束才返回。fsync 可用于数据库这样的应用程序,这种应用程序需要确保修改过的块理解写到磁盘上。
redis 提供了 3 种刷盘策略,其宏定义如下:
#define AOF_FSYNC_NO 0
#define AOF_FSYNC_ALWAYS 1
#define AOF_FSYNC_EVERYSEC 2
其中:
- AOF_FSYNC_NO: 表示不显示调用 fsync 进行刷盘,具体刷盘策略由操作系统内核自身策略决定。
效率最高,但丢数据的风险也最高 - AOF_FSYNC_ALWAYS: 每条命令执行后都尝试通过 fsync 刷盘。
效率最低,但丢失数据的风险最低 - AOF_FSYNC_EVERYSEC:表示 1s 执行一次刷盘。
效率和丢数据风险都属于中等,一般情况下都采用这种方式。
4.3. lazy_free
在应用程序中,为了提高这些删除操作的执行速度,一般情况下的删除操作都是直接将引用设置为 null,然后由另外独立的操作(线程)去释放真正占用的内存空间。
当然,redis 中也有些操作是这样做的,删除一个大对象的操作是,先将变量引用设置为 null, 然后释放内存空间。
可以想象下,如果删除操作要同时执行释放空间的操作,整个操作的效率将会有多么不可控,比如,我们要删除一个百万级的哈希字典(GB级别),要将空间完全释放,这个时间消耗对于一般的操作来说将是多么恐怖!!!
同时,在 redis 的实现中,会评估具体命令的损耗来判断究竟是选择立即处理还是延迟处理。
#define LAZYFREE_THRESHOLD 64
比如,对于 set, zset, hash 等等,元素个数超过 LAZYFREE_THRESHOLD 阀值才会使用 lazy_free。
当然,对于 FLUSHALL 或 FLUSHDB 等命令如果指定了async 异步命令的情况下,将会直接通过惰性去清空整个数据库。
FLUSHALL [ ASYNC | SYNC]
值得注意的是,惰性删除也会带来一些问题,具体可以看看这篇 issues#1748
三、总结
本文主要围绕 redis 的后台线程展开,主要分析了:
- 通过
bio_close_file线程来释放 AOF / RDB 等过程中产生的临时文件资源。 - 通过
aof_fsync线程将追加至 AOF 内存缓存中的数据写入磁盘。 - 通过
lazy_free线程释放大对象(已删除)占用的内存空间.
参考文献:















 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











