






大部分的 python 程序运行都不需要借助调试工具,基本的日志、错误信息已经可以帮助我们发现代码中的问题。再加上许多成熟的框架,让我们只需关心业务代码的逻辑就行了。但使用过程中,偶尔还是会遇到诸如部署在 linux 上后台服务出现了异常卡住、内存高、CPU长时间高占用的问题。如果再加上这些问题是偶现的或者长时间的进程驻留才出现的,排查起来就变的不太容易。这时候,就需要通过一些工具辅助我们进行判断,例如GDB、objgraph等。
GDB 篇
GDB 在调试C语言、C++语言时使用的比较多,对于 Cpython 来说,GDB也支持简单的调试。常用来分析程序堆栈、打断点,方便调试。
1、安装
yum install yum-utils
debuginfo-install glibc
debuginfo-install python3-3.6.8-18.tl2.2.x86_64
yum install gdb python-debuginfo
//下载libpython,放在 python 相同的位置
which python3 // 查看具体python位置,例如 /usr/bin/python3
vi /usr/bin/python3.6-gdb.py // 随便起个名字,文件内容参考https://mirrors.tencent.com/repository/generic/apiTest/xinghai/python3.6-gdb.py
// gdb启动自动加载 python 分析工具
修改 ~/.gdbinit 文件,增加如下行,其中 python3.6-gdb.py 需填写实际位置
add-auto-load-safe-path /usr/bin/python3.6-gdb.py
2、使用
//找到要分析的 python 进程
gdb attach pid // gdb attach 上的进程,如果不通过指令继续运行的话,实际是停下来的,方便卡在某个位置分析现场
//常用的 python 相关的指令
py-list // 查看当前python应用程序上下文
py-bt // 查看当前python应用程序调用堆栈
py-bt-full // 查看当前python应用程序调用堆栈,并且显示每个frame的详细情况
py-print // 查看python变量
py-locals // 查看当前的scope的变量
py-up // 查看上一个frame
py-down // 查看下一个frame
//打断点
b call_function // 暂时没找到直接在python代码上打断点的方式,call_function实际是 c 的代码,调用 python func 时会调用 call_function, 因此这个断点可以帮助我们在每次 python func 调用时断一下,方便捕捉到想调试的 python func,再进行进一步调试
//继续运行代码
n // 单步调试,这个 n 是建立在 c 代码上进行的单步调试,一行 python 代码可能对应很多行 c 代码,所以建议先通过上面的断点找到需要调试的 python func,再通过 n 单步调试,不然 n 的次数会比较多
c // 继续运行代码,直到到达下一个断点。 c 的过程中可以 ctrl+c 直接停下来运行
//线程切换
info thread // 查看当前进程的线程情况
thread 1 // 切换到某个线程,进一步分析具体的线程
//查看断点
info breakpoints // 查看当前所有的断点
d 1 // 删除某个断点
3、简单的例子
3.1 代码
import time
def add(a, b):
c = a + b
print(c)
return c
def main():
for i in range(1000):
time.sleep(10)
add(i, i)
if __name__ == '__main__':
main()
3.2 运行代码,找到对应的进程号

3.3 启动gdb, attach 进程号(建议在代码所在目录运行 gdb, 否则有可能出现 py-list 显示不了代码)

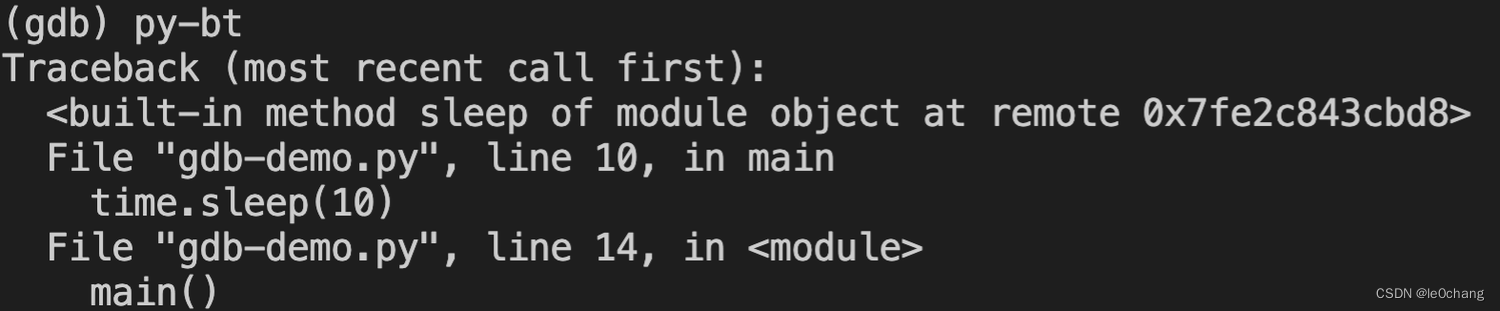
3.4 py-bt 可以看到 python 堆栈
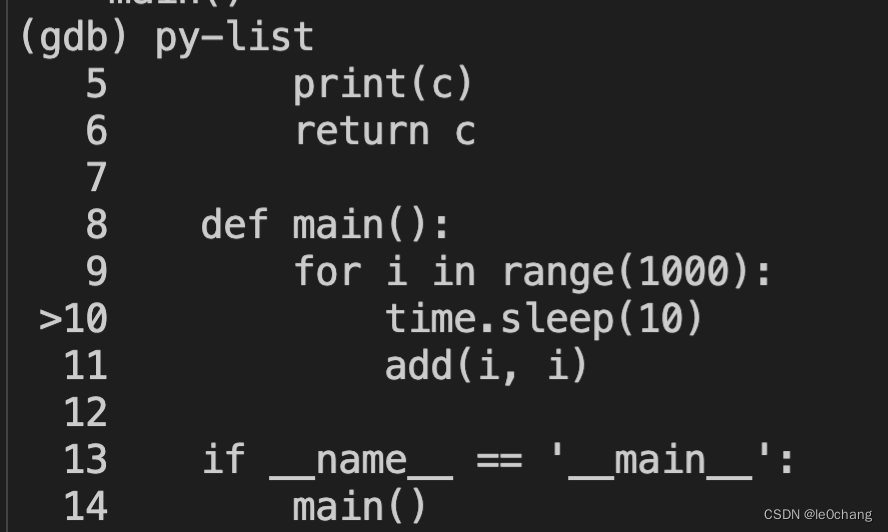
3.5 py-list 可以看到代码位置
3.6 调试 add func
- 通过断点找到 add func 调用开始的位置
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CZplt4nq-1681281973009)(/download/attachments/2108332088/image-1661927666831.png?version=1&modificationDate=1661927667453&api=v2)]](https://img-blog.csdnimg.cn/3e826b002fff428b8f96862f44831bc0.png)
- 如果运行 c 后不是自己想要调试的 func ,可以多 c 几次
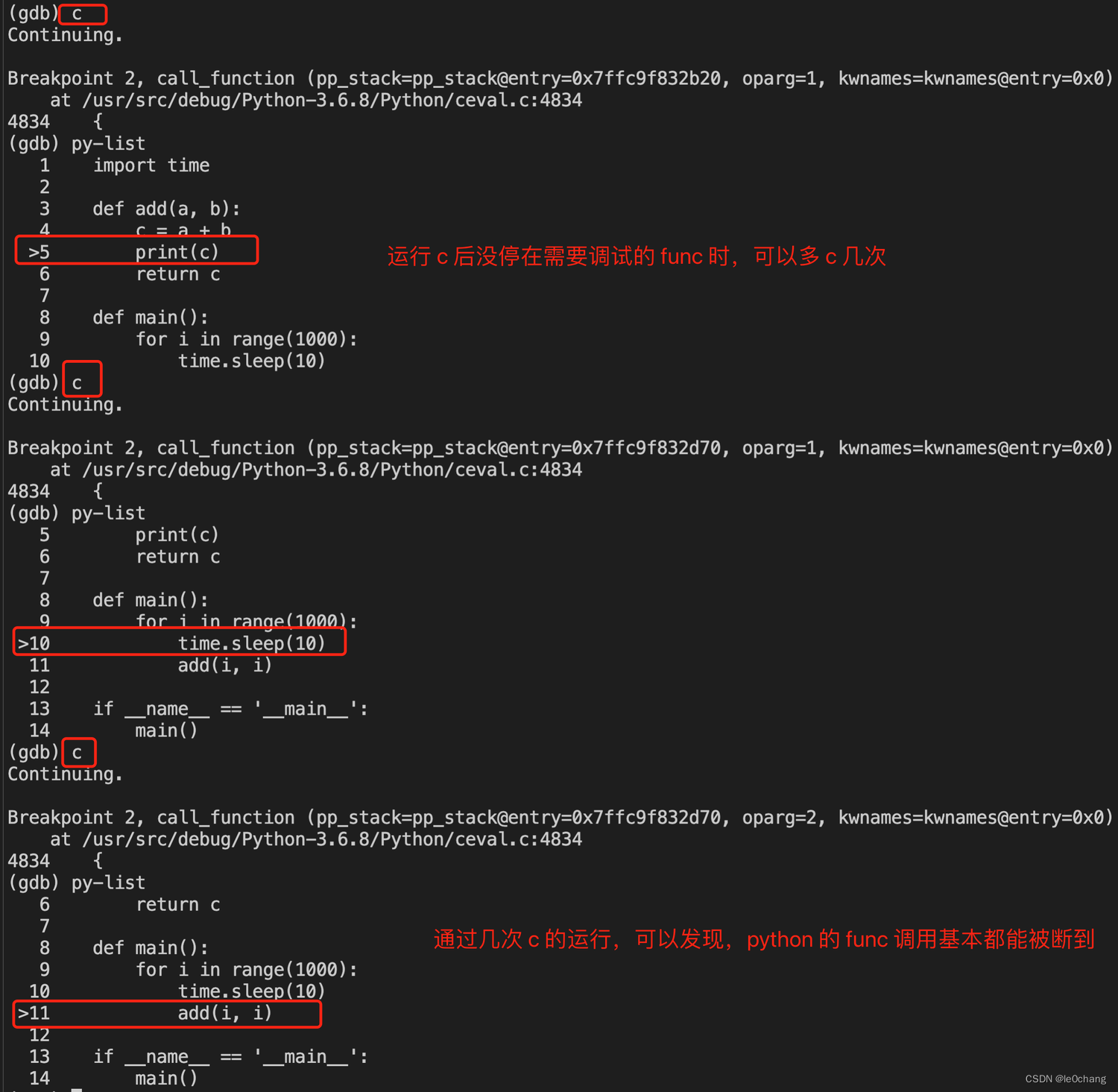
- 找到 func 后可以通过 n 单步调试
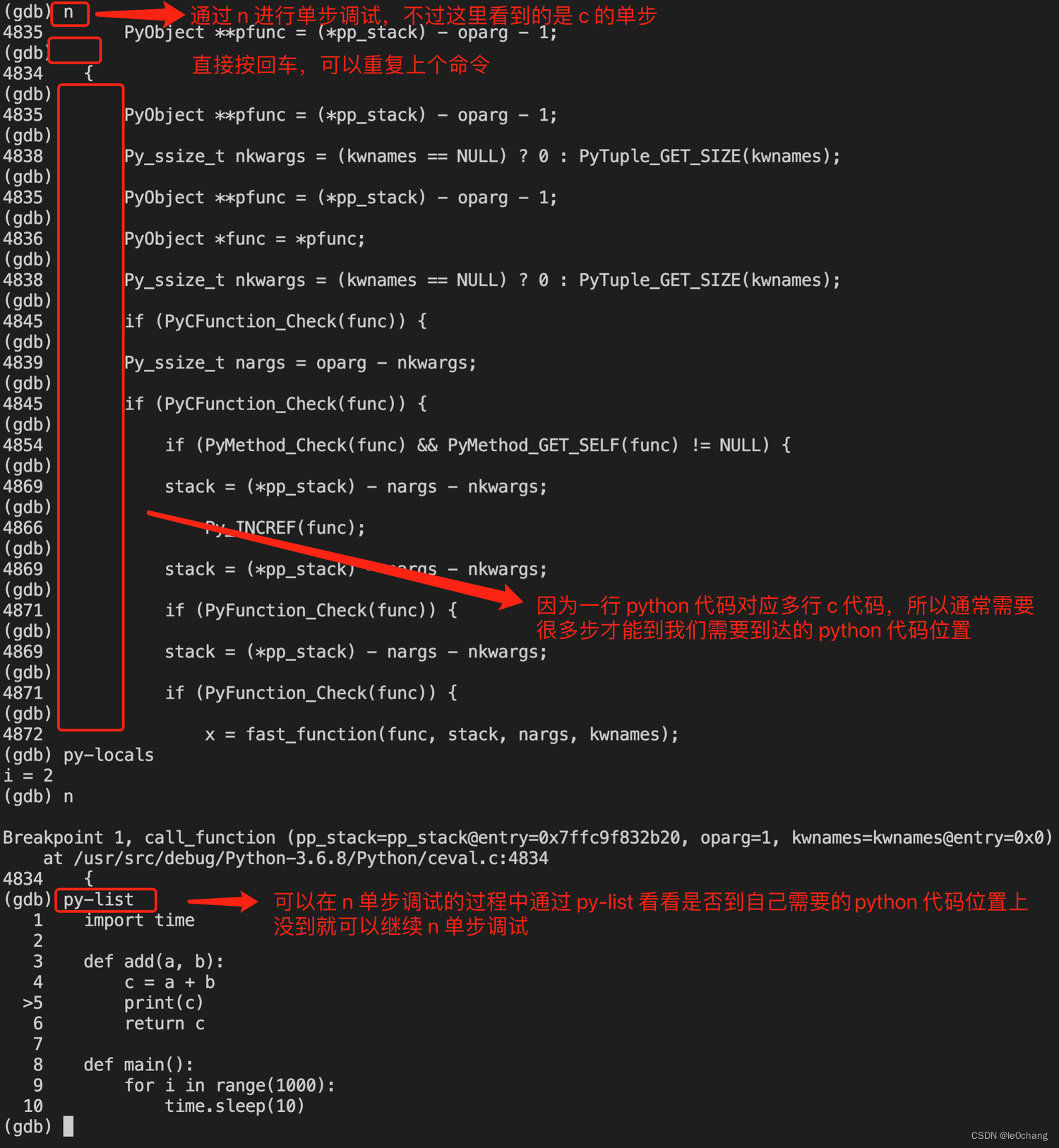
- 然后可以通过现场分析具体变量的值是否正确等

3.7 查看上个 frame 的情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gOz8tREm-1681281973010)(/download/attachments/2108332088/image-1661930658376.png?version=1&modificationDate=1661930658975&api=v2)]](https://img-blog.csdnimg.cn/b2ebc4bb269a456888e00ee1664766e6.png)
3.8 一些其他操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fVc44nwy-1681281973011)(/download/attachments/2108332088/image-1661929263732.png?version=1&modificationDate=1661929264327&api=v2)]](https://img-blog.csdnimg.cn/b24e95db7e6647ca885a33fc071241d6.png)
内存篇
python 的内存通常都是 python 自己管理的,不需要干预。但是偶尔会出现进程内存泄漏、内存长时间占用高的现象,这时候就需要关心了。
1、内存管理机制
python 是通过引用计数和垃圾回收机制来管理对象生命周期的。
- 引用计数:简单的说,当一个 python 对象被引用时,引用计数会加一,取消引用会减一。引用计数为 0 时对象会被销毁,即这块内存被释放。
- 垃圾回收:有时候,对象之间会存在循环应用(对象A引用对象B,对象B反过来引用对象A)。这时候,引用计数无法归零。垃圾回收机制会回收引用计数不为 0 ,但实际已经没用的对象。
- 垃圾回收包括标记-清除和分代回收。
- 标记-清除指的是给对象打上是否有有效引用计数的标签,并清除没有有效引用计数的标签。
- 为了提升垃圾回收的效率,引入了分代回收。分代回收是指把对象分为三代(新建的默认为第一代),第一代对象每次垃圾回收都会清理。如果清理后对象依然存在则将其放入第二代,同理第二代对象清除后还存在则放入第三代。每一代对象的回收都存在阈值,默认情况下,新建对象减去删除对象大与700时触发第一代对象的垃圾回收,每清理 10 次一代对象 触发一次 二代对象回收,每清理 10 次二代对象触发一次三代对象回收。
- 可以通过
gc.get_threshold()看到每一代的阈值,gc.set_threshold()进行修改
2、内存泄漏
- 如果某个对象被另一个生命周期很长的对象(比如全局对象)引用时,可能存在内存泄漏。例如通过全局变量管理连接数,当某个连接断开时没有从全局变量中删除这个对象,就发生了泄漏。
- 关于循环引用的对象中 定义了
__del__函数,那么在循环引用中Python2解释器无法判断析构对象的顺序,因此就不做处理,即回收失败,内存泄漏。这种现象在 python3 未发现,依然可以回收。 - 内存占用高也不等于一定内存泄漏了。比如主进程创建了很多子进程处理事务,在子进程异常卡住,导致驻留的进程越来越多的时候,内存占用会越来越高。(这个虽然会导致内存占用越来越高,但是问题并不出在内存泄漏上,而是进程运行异常)
3、内存工具
这里介绍几个内存工具的用法。(暂时没找到特别好的工具一键分析,只能各工具间迂回)
3.1 pyrasite
-
简介
pyrasite 提供了两个工具,一个是pyrasite-memory-viewer,可以直接用来展示对象类型和占用内存大小以及最大对象内容。另一个是pyrasite-shell,可以进入交互式环境和正在运行的进程交互。 -
安装
pip install gdb meliae urwid pyrasite
- 使用
ps 找到需要分析的进程号 pid
// 分析内存占用
pyrasite-memory-viewer pid
// 进入交互式界面
pyrasite-shell pid
-
pyrasite-memory-viewer 效果展示
- 介绍几个字段的含义
- count:该类型对象个数
- Size: 该类型共占用内存大小
- Max: 该类型所有对象中最大的一个占用的内存大小
- kind: 类型
- 退出方式: q 然后 y
- 方向键上下支持查看不同类型的信息,enter健可显示该类型最大对象的内容
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9puUGgIk-1681281973012)(/download/attachments/2108332088/image-1662001042828.png?version=1&modificationDate=1662001043073&api=v2)]](https://img-blog.csdnimg.cn/e845af2240704e3dacd8a448608de448.png)
- 介绍几个字段的含义
-
pyrasite-shell 效果展示
- 进入 该进程的交互式界面,交互方式同 python 交互式
- 后续介绍的其他内存工具,可以通过这个工具先进入该进程的交互式界面,再运行相应的代码收集具体的进程内存信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vDhJwp6A-1681281973012)(/download/attachments/2108332088/image-1662001384334.png?version=1&modificationDate=1662001384507&api=v2)]](https://img-blog.csdnimg.cn/e2e2125c54f74f6c8466e7d6b248e77d.png)
3.2 meliae
-
简介
meliae 可以把某个时刻的内存 dump 到文件中,然后对该文件进行分析。 -
安装
pip install cython meliae
- 使用
// 进入需要 dump 内存的进程
pyrasite-shell pid
// dump 内存到文件中
from meliae import scanner
scanner.dump_all_objects('/tmp/dump%s.txt' % time.time()) // 参数为文件名,可自定义
// 分析文件
from meliae import loader
om = loader.load('/tmp/dump1662002791.5677857.txt')
om.compute_parents() // 计算各Objects的引用关系
om.collapse_instance_dicts() // 去掉各对象Instance的_dict_属性
om.summarize() // 分析内存占用情况
// 分析对象,得到调用关系
p=om.get_all('str') // 得到所有的 str 对象
p[0] // 查看第一个对象
p[0].c // 查看该对象所有引用的对象
p[0].p // 查看所有引用该对象的对象
- 效果展示
- 比 pyrasite-memory-viewer 得到的信息更加丰富(比如对象地址、简单的引用关系)
- 可以结合 id(变量) 分析具体是哪个变量的地址,更好的判断是哪个变量内存占用高
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Edq5Bwx9-1681281973013)(/download/attachments/2108332088/image-1662013236973.png?version=1&modificationDate=1662013237176&api=v2)]](https://img-blog.csdnimg.cn/20dfe158cdcd4bb3bb00450a4f5e5da5.png)
3.3 objgraph
-
简介
主要用来查看内存中对象的数量,分析某个对象的详细调用关系。 -
安装
pip install objgraph xdot
yum install graphviz
- 使用
// 进入需要分析调用关系的进程
pyrasite-shell pid
// 常用的几个方法
import objgraph
objgraph.show_most_common_types(limit=30) // 打印实例最多的前 30 个对象(30 可修改)
objgraph.show_growth() // 统计自上次调用以来增加最多的对象
objgraph.count('xxx') // 返回该类型对象的数目
p = objgraph.by_type('xxx') // 获取该类型对象列表
p[0] // 第一个对象
objgraph.show_backrefs(p[0], max_depth = 10, filename = 'obj.dot') // 生成p[0]对象的完整详细调用图
// 生成 p[0] 对象的简单调用图
objgraph.show_chain(objgraph.find_backref_chain(p[0],objgraph.is_proper_module),filename='obj_chain.dot')
// 将生成的 dot 转换成 png,方便看
dot -Tpng xxx.dot -o xxx.png
- 示例
- 代码
import time
_cache = []
class OBJ(object):
pass
def func_to_leak():
o = OBJ()
_cache.append(o)
# do something with o, then remove it from _cache
if True: # this seem ugly, but it always exists
return
_cache.remove(o)
def show_cycle_reference():
a, b = OBJ(), OBJ()
a.attr_b = b
b.attr_a = a
if __name__ == '__main__':
func_to_leak()
for _ in range(50):
func_to_leak()
show_cycle_reference()
while(1):
time.sleep(10)
- 效果分析
-
查看实例最多的30个对象
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DLyl4Pvk-1681281973013)(/download/attachments/2108332088/image-1662036440532.png?version=1&modificationDate=1662036440841&api=v2)]](https://img-blog.csdnimg.cn/2b8960826be64fecbc664282dc44b6a5.png)
-
查看某个函数产生的对象变化
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZEjuFF7k-1681281973014)(/download/attachments/2108332088/image-1662036681609.png?version=1&modificationDate=1662036681915&api=v2)]](https://img-blog.csdnimg.cn/25046a7009184b0db509d27eeacdbe16.png)
-
画调用图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9juTUQLG-1681281973015)(/download/attachments/2108332088/image-1662036968004.png?version=1&modificationDate=1662036968127&api=v2)]](https://img-blog.csdnimg.cn/cd74d414fad04710b968930807f101ea.png)
-
转成 png 格式
dot -Tpng obj_chain.dot -o obj_chain.png,dot -Tpng obj.dot -o obj.png -
obj.png(因为是通过pyrasite工具进入进程统计的,所以结果包含了工具带来的调用,比较复杂)
-
obj_chain.png
-
3.4 其他工具
memory_profiler : 可以看具体每行代码使用内存(但需给代码加装饰器),也可以统计一段时间内的内存(但要重新执行),都没法侵入正在执行的进程,所以未介绍。有兴趣可以参考 https://github.com/pythonprofilers/memory_profiler。
4、总结
- 进程内存高占用排查方式
- step1: 使用过程中发现内存占用高,可以先通过
pyrasite-shell进入有问题的进程 - step2:
import gc,gc.collect()先手动进行一次垃圾回收。如果内存减少的话,可能是进程垃圾回收时间设置问题,可以适当修改。修改方式:gc.set_threshold() - step3: 如果内存依然很大,可以进一步通过
pyrasite-memory-viewer看看是不是有特大内存的对象存在 - step4: 如果是大内存对象的话,结合
meliae可以看到最大内存对象的地址,简单调用关系等信息,可以分析出这个大内存对应具体哪个对象,结合代码分析该对象占用内存高原因(可能是大文件,或者某个全局变量一直在增加内容) - step5: 没有大内存的话,可能是某个对象在生命周期结束时没有释放,导致对象数量太多。通过
objgraph分析实例最多的对象当中是否有自定义对象,结合代码分析这个对象的使用,也可以借助objgraph生成对象调用图辅助分析。 - step6: 源码、工具 重复试验。
- step1: 使用过程中发现内存占用高,可以先通过
性能篇
python 性能本身就是较慢的,高性能的很少用 python。虽然也有一些提升性能的手段,但需要使用的场景比较少。可能会遇到的问题是发现某个进程 CPU 一直占用高
1、CPU 占用高排查
通常 CPU 占用高,说明这个程序一直在跑代码,排除业务本身需要,就很有可能是哪里死循环了。
这里可以借用 gdb 工具来帮我们分析。
- step 1:
top -p pid可以找到 cpu 占用高的线程 - step 2:
gdb attach pid进入该进程 - step 3:
info thread、thread 1进入对应的线程 - step 4:
b call_function打断点 - step 5:
c继续运行,每调一个 python 函数 gdb 都会断一下, 可以通过py-bt、py-list查看堆栈以及代码位置 - step 6: 重复 step 5,结合代码分析程序具体在做什么。
- step 7: 找到原因后,如果是 BUG 进行修复,如果是正常的业务现象,可能优化或者上资源。
2、其他工具
例如 perf、pyflame 等工具可以画出 性能火焰图。
Q&A
Q1: meliae 使用,AttributeError: ‘dict’ object has no attribute ‘itervalues’
A2: 找到对应代码,将 itervalues 改成 values
Q2: pyrasite-memory-viewer 使用,TypeError: a bytes-like object is required, not ‘str’
A2: 找到对应代码,split()或者strip() 前加上 decode()














 1472
1472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









