









最近产品大大提出一个需求“统计上周全国商场的uv、商场内每个商户的uv、商场uv在相应城市、商区的排名。访问商场用户的一些信息例如男女比例、年龄分布、用户常居地距离商区范围分布等”。至于入口是在商家后台中,用户(商场市场部人员)想看这些数据是要付费的哟。
显而易见,这种数据不是实时计算,通过Hadoop一套机制离线计算出来的。原来这个任务应该由公司专门负责数据处理的BI团队来做的,恰不巧我们组对应的BI同事要离职了。最终这个任务落到本人身上,之前完全没有接触过Hadoop的东西。即使公司已经搭建一套完整的框架,实现具体功能只是在框架基础之上去做而已,但是一整套流程下来还是很繁琐的。经过两周时间的摸索,终于把数据全部算出来并且同步到mysql表上。
做完任务之余,本文想借此机会初步了解Hadoop。
什么是Hadoop?
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。—摘自《百度百科》
分布式文件系统简单的理解就是把原来单台机器文件系统的概念放大到集群的范围内。而上层接口无异于普通的文件系统。分布式文件系统原理复杂,个人简单理解操作系统中的文件系统的组件在分布式文件系统中都有,整体原理架构类似。建议读者在深究分布式文件系统之前先了解操作系统中的文件系统原理。本文主要关注点是MapReduce,对Hadoop运行机制有个初步的了解。
场景
假设我们有10个文件,每个文件大小是10M。文件内容是商户账户流水信息,格式为 shopId ‘空格’ 销售额,要求是统计每个商户的总营业额。
| shopId | sales |
|---|---|
| 50001 | 546 |
| 50002 | 2421 |
方案一
遍历10个文件,以shopId为key映射存储在一个Map里面统计Map<Integer,Integer> result =new HashMap<Integer,Integer>(); int sumSales = result.get(shopId); if( sumSales != null){ result.put(shopId,sumSales+sale); }else{ result.put(shopId,sale); }方案二
分两个阶段完成任务,第一阶段先收集shopId所有的销售额,第二阶段再统计。
一种方式实现是遍历十个文件,通过Map<Integer,List<Integer>>数据结构存储.
另一种则是MapReduce方式。
MapReduce
MapReduce分成两个阶段,Mapper和Reduce。
Map阶段主要是处理源数据,例如上面的场景。一个Mapper任务的输入是一个文件,输出是
Map<ShopId,Iterator<Sale>>
十个文件则对应十个Mapper任务.
Reduce阶段是收集10个Mapper任务的结果,并且合并成一个
Map<ShopId,Iterator<Sale>>
并计算。
pom依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>数据Mock代码
public class TestDataProvider {
private static final int ROW_NUM = 100000;
private static final int FILE_NUM = 10;
private static Random random = new Random();
public static void main(String[] args) {
for (int i = 0; i < FILE_NUM; i++) {
try {
produceData();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("produce data success!");
}
private static void produceData() throws IOException {
String filePath = "/Users/lepdou/Documents/hadoop/" + random(10000) + ".txt";
FileWriter fileWriter = null;
fileWriter = new FileWriter(filePath);
int shopId = 0;
int sales = 0;
for (int i = 0; i < ROW_NUM; i++) {
shopId = 50000 + random(10);
sales = random(1000);
fileWriter.write(shopId + " " + sales + "\n");
}
if (fileWriter != null) {
try {
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static int random(int max) {
return random.nextInt(max);
}
}Mapper代码
public class ShopSalesMapper extends MapReduceBase implements Mapper<LongWritable,Text,Text, IntWritable> {
@Override
public void map(LongWritable num, Text line,
OutputCollector<Text, IntWritable> outputCollector, Reporter reporter) throws IOException {
String[] data = line.toString().split(" ");
String shopId = data[0];
int sales = Integer.parseInt(data[1]);
outputCollector.collect(new Text(shopId), new IntWritable(sales));
}
}Mapper接口说明:K1, V1, K2, V2 分别对应输入的k,v和输出的k,v.在本例中则分别对应数据在文本中的行,行文本,shopId,销售额
Mapper<K1, V1, K2, V2>
Reducer代码
public class ShopSalesReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text shopId, Iterator<IntWritable> sales,
OutputCollector<Text, IntWritable> outputCollector, Reporter reporter) throws IOException {
int salesSum = 0;
while (sales.hasNext()){
salesSum += sales.next().get();
}
outputCollector.collect(shopId, new IntWritable(salesSum));
}
}Reducer接口说明:K1, V1, K2, V2 分别对应输入的k,v和输出的k,v.在本例中则分别对应:shopId,销售额iterator,shopId,总销售额
Mapper<K1, V1, K2, V2>
Job控制代码
public class ShopSalesCounter {
public static void main(String[] args) throws IOException {
JobConf jobConf = new JobConf(ShopSalesCounter.class);
jobConf.setJobName(" count shop sales");
FileInputFormat.addInputPaths(jobConf, "/Users/lepdou/Documents/hadoop/");//10个文件路径
FileOutputFormat.setOutputPath(jobConf, new Path("/Users/lepdou/Documents/result"));//最终结果输出路径
jobConf.setMapperClass(ShopSalesMapper.class);
jobConf.setReducerClass(ShopSalesReducer.class);
jobConf.setOutputKeyClass(Text.class);
jobConf.setOutputValueClass(IntWritable.class);
JobClient.runJob(jobConf);
}
}
核心日志输出
Total input paths to process : 10
Running job: job_local916373742_0001 ==> job 开始运行
Waiting for map tasks
Starting task: attempt_local916373742_0001_m_000000_0 ==> 开始第一个Mapper任务
org.apache.hadoop.mapred.MapTask updateJobWithSplit
Processing split: file:/Users/lepdou/Documents/hadoop/9851.txt:0+989143 ==> 处理第一个分块,以文件为单位。在HDFS一般是64M一个分区
numReduceTasks: 1 ==>只有一个reduce任务
io.sort.mb = 100 ==> 排序结果并缓存到本地的文件系统中
data buffer = 79691776/99614720
record buffer = 262144/327680
Starting flush of map output ==> Mapper结束并输出
map 0% reduce 0%
Finished spill 0
Task:attempt_local916373742_0001_m_000000_0 is done. ==>第一个任务结束
file:/Users/lepdou/Documents/hadoop/9851.txt ==> 重复第二到第九个任务
......
map 20% reduce 0%
......
map 50% reduce 0%
......
map 100% reduce 0%
Merging 10 sorted segments ==>mapper阶段结束,mege10个mapper的结果,输出一个最终数据作为reducer的输入
Down to the last merge-pass, with 10 segments left of total size: 1220 bytes
reduce > reduce ==> reduce任务开始
map 100% reduce 100%
Job complete: job_local916373742_0001 ==>整个job任务结束
=====以下是这个任务的统计信息(源数据:10个文件,一个文件10,000条数据)=======
File Input Format Counters
Bytes Read=9889768
File Output Format Counters
Bytes Written=162
FileSystemCounters
FILE_BYTES_READ=64347821
FILE_BYTES_WRITTEN=575986
Map-Reduce Framework
Reduce input groups=10
Map output materialized bytes=1260
Combine output records=100
Map input records=1000000
Reduce shuffle bytes=0
Reduce output records=10
Spilled Records=200
Map output bytes=10000000
Total committed heap usage (bytes)=8961654784
Map input bytes=9889768
Combine input records=1000000
Map output records=1000000
SPLIT_RAW_BYTES=967
Reduce input records=100
从整个日志输出中可以清晰的看出整个任务的过程。以图表示则更为清晰,如下图。
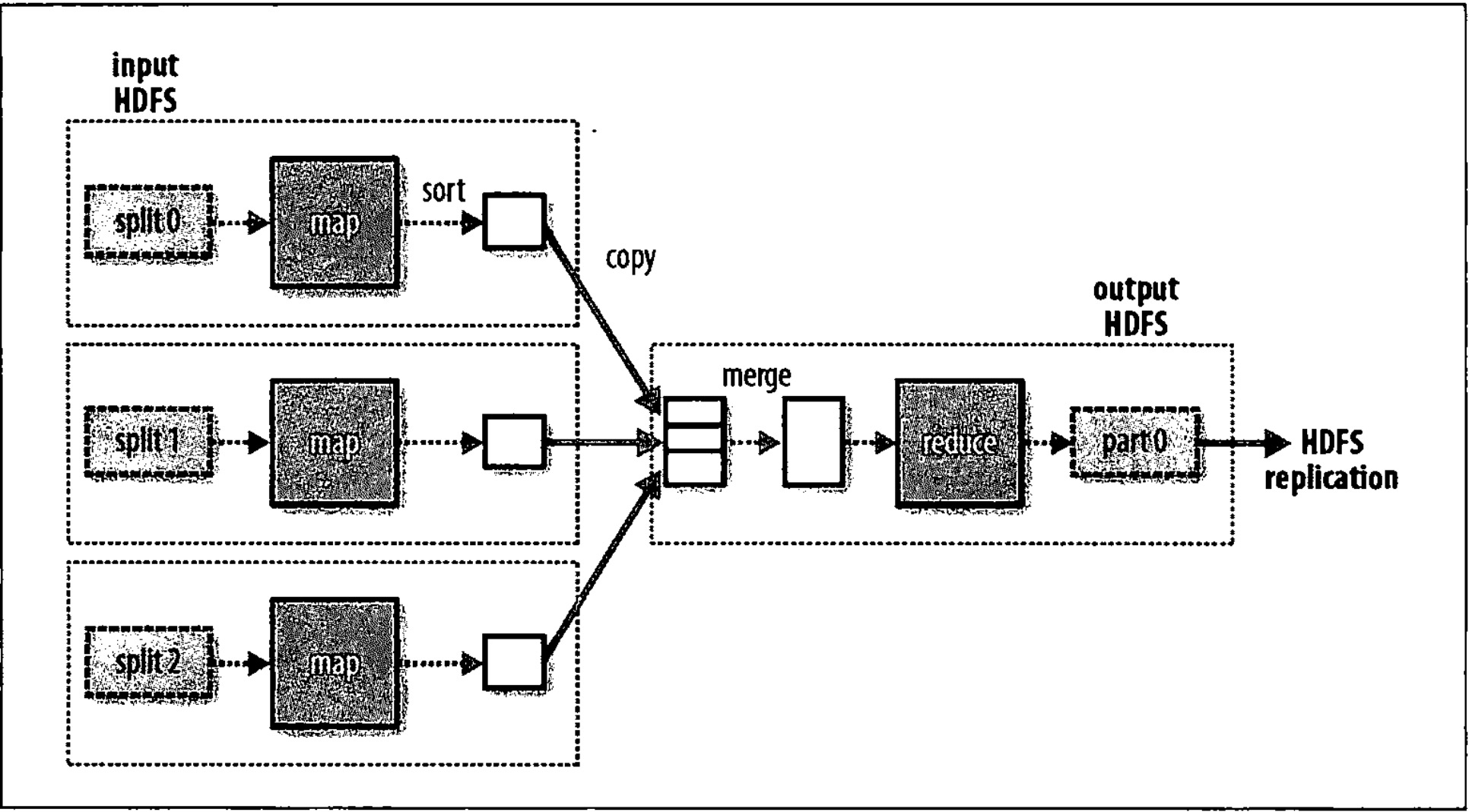
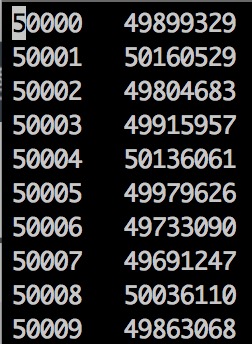
job执行结果,在result目录中生成part-00000文件,
cat part-00000
则看到
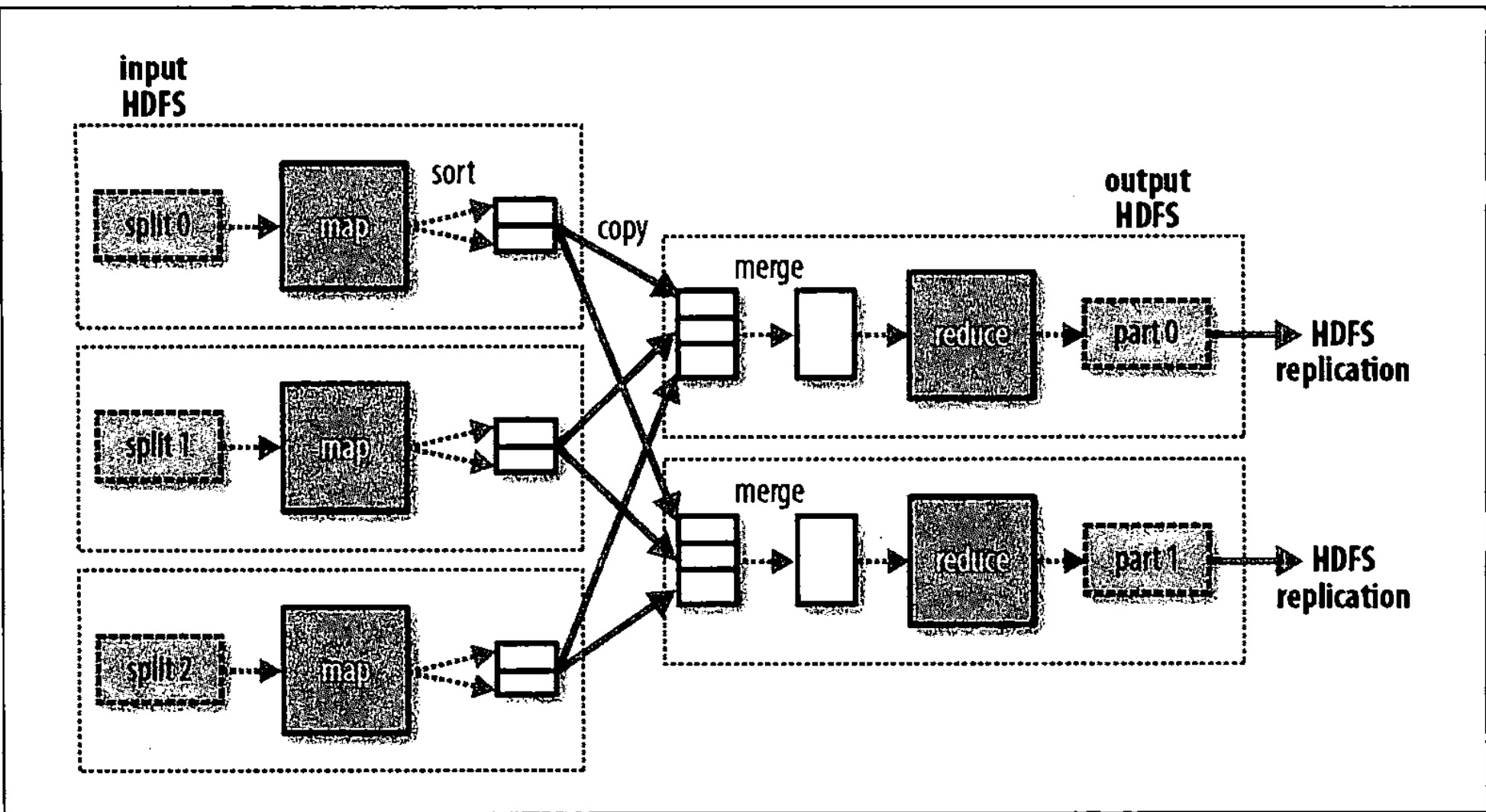
如果有多个reducer任务,则每个Mapper任务的输出则相应的等分,一个reducer任务从每个Mapper输出中取一份,如下图
在实际生产环境中,各个Mapper之间,Mapper和Reduce之前都是在不用的机器中运行,所以难免会有网络传输,且主要在Mapper向Reduce传送数据,如果数据量大的话延迟就会增加。MapReduce框架,提供了一种机制可以对mapper的结果先combine处理,压缩数据量。但是并不是所有的任务都可以先combine,在本例中是可以的。因为
sum(file1+file2+……file10)=sum(file1)+sum(file2)+…..sum(file3)
combiner代码
public class ShopSalesCombiner extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text shopId, Iterator<IntWritable> sales,
OutputCollector<Text, IntWritable> outputCollector, Reporter reporter) throws IOException {
int salesSum = 0;
while (sales.hasNext()){
salesSum += sales.next().get();
}
outputCollector.collect(shopId, new IntWritable(salesSum));
}
}发现接口,代码和reduce组件一致。通过 以下代码设置combiner。
jobConf.setCombinerClass(ShopSalesCombiner.class);
有无combiner情况下Mapper向reduce传输量对比:
shopId:list size
| 无combiner | 有combiner |
|---|---|
| file1:99967 | file1:10 |
| file2:100197 | file2:10 |
| …… | …… |
因为一共只有10个shopId,所以每个Mapper结果就是10个shopid对应的在该mapper任务中的sum。
实际应用中的模型
实际中公司hadoop集群中商户的pv表大小为1T左右,假设分布在100台机器上,统计一个shopId为500000的商户一周之内的pv。假设只有一个reduce任务,100个mapper任务分别运行在100台机器上,那么处理流程就如上demo一致。
利用hadoop的HDFS可以方便线性扩展机器,所以数据量再大都无妨,利用mapper之间并发的分布式计算可以大大提高运算速度。实际中,一般很少直接写Mapper Reduce代码,利用Hive之类的框架大大方便编写复杂任务的成本。hive对开发者的接口是sql脚本,hive框架通过编译,解析sql脚本生成Mapper,Reduce代码。打包成jar包,分发到hadoop集群中运行。另外帮我们生成最优Mapper和reduce任务数使计算速度最快。也就是说,我们可以把hadoop当做普通开发者最熟悉的mysql之类的RDBMS工具去使用。上面hive的理解只是个人初步的判断,并没有详细去了解。之后通过学习会详细的介绍Hive。















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









