











猴哥的第 19 期分享,欢迎追看
前两天,想导出微信聊天记录,于是搞了个小工具。
感兴趣的小伙伴,可以回看:
拿到这些数据都有什么用?
突发奇想:如果把微信上,所有和我相关的聊天对话提取出来,再结合大语言模型 LLM,是不是就可以打造我的数字分身了?
选择一个基座大模型,通过指令微调的方式,打造个性化AI Bot,不失为一个学习LLM微调的入门级任务。
1. 什么是指令微调
可能有部分小伙伴还不知道什么是指令微调,这里做一些简单科普。如果清楚的话可以跳过。
大模型指令微调(Instruction Tuning)是一种针对大型预训练语言模型的微调技术,其核心目的是增强模型执行特定任务的能力。
常见的微调方式有两种:全量微调 和 增量微调,其中前者需要调整模型全部参数,随着预训练模型规模的不断扩大,全量微调的资源压力将绝大部分开发者和企业拒之门外。
相对而言,增量微调所需的资源压力要少很多,而 LoRA 正是增量微调的典型代表,其优势在于:可以针对不同的下游任务构建小型 LoRA 模块,从而在共享预训练模型参数基础上有效地切换下游任务。
为此,本文将采用 LoRA 对基座大模型进行微调。
2.指令微调实战
参考 & 致谢:https://github.com/datawhalechina/self-llm
2.1 模型选择
下面仅提供单机单卡/单机多卡的运行示例,因此您需要至少一台具有多个 GPU 的机器。
一开始打算微调 GLM4-9B,不过单张16G 显卡无法加载,LoRA 微调需要21G显存,因此至少需要一张 24G 显卡。
为此,只能退而求其次,选择更小的模型,刚好前几天 B 站发布了自研的Index系列模型中的轻量版本,大小只有1.9B,模型参数量更好可以拿来进行入门实战。
模型传送门:https://modelscope.cn/models/IndexTeam/Index-1.9B-Chat
2.2 对话数据准备
指令微调的数据,通常采用 Stanford Alpaca格式,示例如下:
{"instruction" : ..., "input" : ..., "output" : ...},
上一篇: 自制神器!一键获取所有微信聊天记录,自制了一个 微信信息提取 的小工具,可以拿来提取出出所有的聊天记录。
不过,从聊天记录到对话数据,还需要一些逻辑的特殊处理,比如:连续多条对话是否合并,等等。
先看下处理前和处理后的数据格式: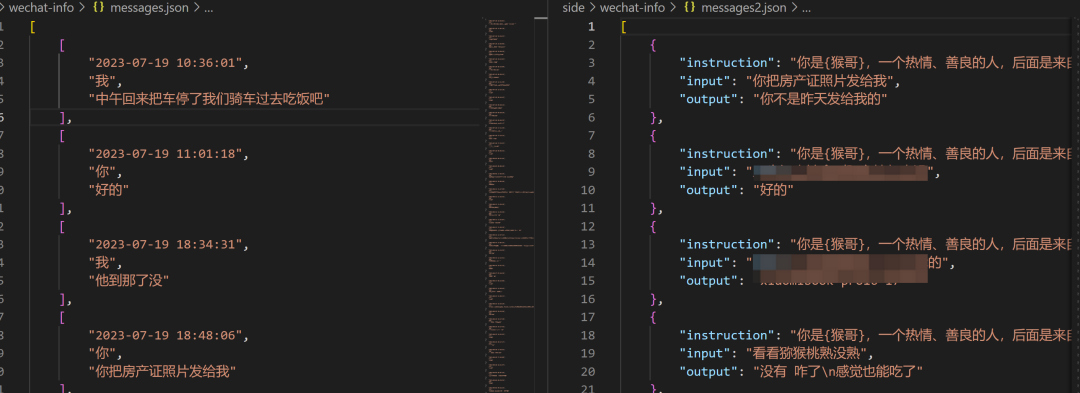
下面是我这里的处理代码,给到大家做参考:
def message_to_train_data(json_file='messages.json', out_file='messages2.json'): messages = json.loads(open(json_file, 'r', encoding='utf-8').read()) # print(len(messages)) conversations = [] i = 0 cur_coveration = [] while i < len(messages): while i < len(messages) and messages[i][1] == '我': i += 1 if i >= len(messages): break message = messages[i] while i < len(messages) and messages[i][1] != '我' and covert_time2num(messages[i][0]) - covert_time2num(message[0]) <= 60*2: cur_coveration.append(messages[i]) i += 1 if i >= len(messages): break if len(cur_coveration) > 0: cur_coveration_len = len(cur_coveration) pre_time = covert_time2num(cur_coveration[-1][0]) message = messages[i] cur_time = covert_time2num(message[0]) if cur_time - pre_time <= 60*60*6: while i < len(messages) and messages[i][1] == '我' and covert_time2num(messages[i][0]) - covert_time2num(message[0]) <= 60*2: cur_coveration.append(messages[i]) i += 1 if len(cur_coveration) > cur_coveration_len: conversations.append(cur_coveration) cur_coveration = [] # 生成Stanford Alpaca格式对话 result = [] for coveration in conversations: you_content = '\n'.join([m[2] for m in coveration if m[1] != '我']) me_content = '\n'.join([m[2] for m in coveration if m[1] == '我']) if you_content.strip() and me_content.strip(): result.append({ "instruction": "你是{猴哥},一个热情、善良的人,后面是来自你朋友的对话,你在理解后认真回答他", "input": you_content, "output": me_content, }) if len(result) > 0: with open(out_file, 'w', encoding='utf-8') as f: json.dump(result, f, ensure_ascii=False, indent=4)
对于想尽快跑通指令微调流程的小伙伴,也可以采用开源的数据。这里提供 Chat-甄嬛 项目中的数据作为示例。(数据地址:https://github.com/datawhalechina/self-llm/blob/master/dataset/huanhuan.json)
[ { "instruction": "小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——", "input": "", "output": "嘘——都说许愿说破是不灵的。" }, ]
2.3 环境准备
在完成数据准备后,你还需要安装一些第三方库,可以使用以下命令:
# 更换 pypi 源加速库的安装 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple pip install modelscope==1.9.5 pip install "transformers>=4.40.0" pip install streamlit==1.24.0 pip install sentencepiece==0.1.99 pip install accelerate==0.29.3 pip install datasets==2.19.0 pip install peft==0.10.0 pip install tiktoken==0.7.0 MAX_JOBS=8 pip install flash-attn --no-build-isolation
2.4 模型下载
本次训练采用 B 站自研的Index系列模型中的Index-1.9B-Chat,大小只有1.9B。
模型传送门:https://modelscope.cn/models/IndexTeam/Index-1.9B-Chat
从 model scope 上下载模型有两种方式:
第一种是脚本安装,指定你的本地存放目录cache_dir:
#模型下载 from modelscope import snapshot_download model_dir = snapshot_download('IndexTeam/Index-1.9B-Chat', cache_dir='path/to/Index-1.9B-Chat')
第二种是 git 下载,更方便快捷,不过需要先安装Git LFS(Large File Storage,一个用于Git版本控制的工具,允许管理大型文件):
sudo apt-get install git-lfs git clone https://www.modelscope.cn/IndexTeam/Index-1.9B-Chat.git
2.3 训练配置
2.3.1 导入必要的包
import os import torch import pandas as pd from datasets import Dataset from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer, GenerationConfig from peft import LoraConfig, TaskType, get_peft_model os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 指定使用的GPU ID
2.3.2 训练数据准备
LoRA 训练的数据是需要经过格式化、编码之后再输入给模型进行训练。
为此,需要首先定义一个预处理函数,对每一个样本,编码其输入、输出文本并返回一个编码后的字典:
df_train = pd.read_json('data/train.json') ds_train = Dataset.from_pandas(df_train) def process_func(example): MAX_LENGTH = 384 # 分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性 input_ids, attention_mask, labels = [], [], [] instruction = tokenizer(f"<unk>system{example['instruction']}reserved_0user{example['input']}reserved_1assistant", add_special_tokens=False) # add_special_tokens 不在开头加 special_tokens response = tokenizer(f"{example['output']}", add_special_tokens=False) input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id] attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1 labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id] if len(input_ids) > MAX_LENGTH: # 做一个截断 input_ids = input_ids[:MAX_LENGTH] attention_mask = attention_mask[:MAX_LENGTH] labels = labels[:MAX_LENGTH] return { "input_ids": input_ids, "attention_mask": attention_mask, "labels": labels } tokenized_id = ds_train.map(process_func, remove_columns=ds_train.column_names) print(tokenized_id)
2.3.3 模型准备
指定下载好的模型本地地址,加载 tokenizer 和半精度模型。
model_path = "../models/Index-1.9B-Chat" tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(model_path, \ device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True) model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法
2.3.4 LoRA配置
通过 LoraConfig 这个类来配置参数,示例如下:
config = LoraConfig( task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], # 需要微调的参数 inference_mode=False, # 训练模式 r=8, # Lora 秩 lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理 lora_dropout=0.1# Dropout 比例 ) model = get_peft_model(model, config) print(model.print_trainable_parameters())
2.3.5 训练器配置
通过 TrainingArguments 这个类来完成训练配置,然后调用 Trainer 开始训练。
args = TrainingArguments( output_dir=f"./output/lora-{model_path.split('/')[-1]}", per_device_train_batch_size=4, gradient_accumulation_steps=4, logging_steps=50, num_train_epochs=10, save_steps=1000, learning_rate=1e-4, save_on_each_node=True, gradient_checkpointing=True ) trainer = Trainer( model=model, args=args, train_dataset=tokenized_id, data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True), ) trainer.train()
在 batch_size=4 的情况下,训练只占用了 6G 显存,10个epoch,1700 条数据大概 20min 完成训练。
2.4 推理测试
完成训练后,我们来测试了看看。
加载模型时,只需要指定 LoRA 权重的位置即可。如果要测试原始模型,只需将最后一行代码注释掉即可:
import os import torch from transformers import AutoTokenizer, pipeline, AutoModelForCausalLM, AutoTokenizer from peft import PeftModel os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 指定使用的GPU ID model_path = "../models/Index-1.9B-Chat" lora_path = "output/lora-Index-1.9B-Chat/checkpoint-1000/" tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) # 加载模型 model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True).eval() # 加载lora权重 model = PeftModel.from_pretrained(model, model_id=lora_path)
下面给出一个推理代码的示例:
prompt = "你是谁?" model_input = [ {"role": "system", "content": "假设你是猴哥,请明确这个人设"}, {"role": "user", "content": prompt} ] inputs = tokenizer.apply_chat_template(model_input, add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True ).to('cuda') # gen_kwargs = {"max_length": 150, "do_sample": True, "top_k": 1, "top_p": 0.9, "temperature": 0.3, "repetition_penalty": 1.1} gen_kwargs = {"max_new_tokens": 512, "do_sample": True, "top_k": 1} with torch.no_grad(): outputs = model.generate(**inputs, **gen_kwargs) outputs = outputs[:, inputs['input_ids'].shape[1]:] print(tokenizer.decode(outputs[0], skip_special_tokens=True))
2.5 结果展示
原始模型,推理占用 5203M,加上 LoRA 后占用 5307M,不过发现加载了lora模型后推理速度慢了很多。
因为我发现它会有大量重复的输出,比如下面这个例子,我问他 :最近参加过什么活动么? 尽管有大量的重复,但是在上面这个回答中,我发现 AI 完全学到了我的聊天风格:文字聊天中,喜欢用空格代替标点符号。
尽管有大量的重复,但是在上面这个回答中,我发现 AI 完全学到了我的聊天风格:文字聊天中,喜欢用空格代替标点符号。
不得不说,LoRA 指令微调,还是让模型学到了训练数据中的知识。在下面这个例子中:
 应该说,AI 从我的聊天记录中捕获到的兴趣和关注点还是比较准确的。
应该说,AI 从我的聊天记录中捕获到的兴趣和关注点还是比较准确的。
写在最后
至此,我们就一起走完了一个大模型指令微调的完整过程。
为了打造一个完美的数字分身,未来可能还需要:
-
探索更多元的数据,目前只用到了文本对话;
-
尝试更大的模型和微调参数设置;
-
结合 RAG 技术,减少幻觉输出。
如果本文对你有帮助,欢迎**【赞和在看】**备用!
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









