






实验2 分支循环程序设计
分支程序设计一般要依靠条件跳转指令,根据上一步操作的结果来决定下一步的动作;而循环程序设计需要使用LOOP等指令,使循环体能够反复执行。
2.1 冒泡法排序
数组的冒泡排序算法,需要用两层循环来实现。冒泡排序对一个7个元素的数组(n=7)进行升序排序的例子如图2-1所示。
| 位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 执行该轮排序后的效果 |
| 数组初值 | 20 | 15 | 70 | 30 | 32 | 89 | 12 |
|
|
|
|
|
|
|
|
|
|
|
| 第1轮排序 | 15 | 20 | 30 | 32 | 70 | 12 | 89 | 将89放在正确的位置 |
|
|
|
|
|
|
|
|
|
|
| 第2轮排序 | 15 | 20 | 30 | 32 | 12 | 70 | 89 | 将70放在正确的位置 |
|
|
|
|
|
|
|
|
|
|
| 第3轮排序 | 15 | 20 | 30 | 12 | 32 | 70 | 89 | 将32放在正确的位置 |
|
|
|
|
|
|
|
|
|
|
| 第4轮排序 | 15 | 20 | 12 | 30 | 32 | 70 | 89 | 将30放在正确的位置 |
|
|
|
|
|
|
|
|
|
|
| 第5轮排序 | 15 | 12 | 20 | 30 | 32 | 70 | 89 | 将20放在正确的位置 |
|
|
|
|
|
|
|
|
|
|
| 第6轮排序 | 12 | 15 | 20 | 30 | 32 | 70 | 89 | 将15放在正确的位置 |
图2-1 冒泡排序的过程
显示中带阴影的部分是已经排序好的部分,不必再进行“比较、交换”操作。
在设计冒泡排序的程序时,就需要两层循环。外层循环的循环次数是n-1,以第0次、第1次……第n-2次循环表示。第i次外循环中,内层循环对数组下标为0至n-i-1的元素依次“比较、交换”。内层循环的循环次数是n-i-1。
;程序清单:bubble.asm(冒泡排序算法)
.386
.model flat,stdcall
option casemap:none
includelib msvcrt.lib
printf PROTO C :dword,:vararg
.data
dArray dword 20, 15, 70, 30, 32, 89, 12
ITEMS equ ($-dArray)/4 ; 数组中元素的个数
szFmt byte 'dArray[%d]=%d', 0ah, 0 ; 输出结果格式字符串
.code
start:
mov ecx, ITEMS-1
i10:
xor esi, esi
i20:
mov eax, dArray[esi*4]
mov ebx, dArray[esi*4+4]
cmp eax, ebx
jl i30
mov dArray[esi*4], ebx
mov dArray[esi*4+4], eax
i30:
inc esi
cmp esi, ecx
jb i20
loop i10
xor edi, edi
i40:
invoke printf, offset szFmt, edi, dArray[edi*4]
inc edi
cmp edi, ITEMS
jb i40
ret
end start
2.2 折半查找
要在数组中查找一个数,最简单的做法是循环比较数组的每一个元素,即顺序查找。设数组长度为n,那么顺序查找的平均比较次数为n/2。
在一个有序数组中,各元素已按照大小排序,从小到大排序的称为升序;从大到下排序的称为降序。在有序数组中查找,使用折半查找的效率最高,平均比较次数为log2n,比顺序查找的次数要少得多。
如图2-2所示,以升序数组为例来说明折半查找算法。数组为R,元素个数为n,要查找的数为a。
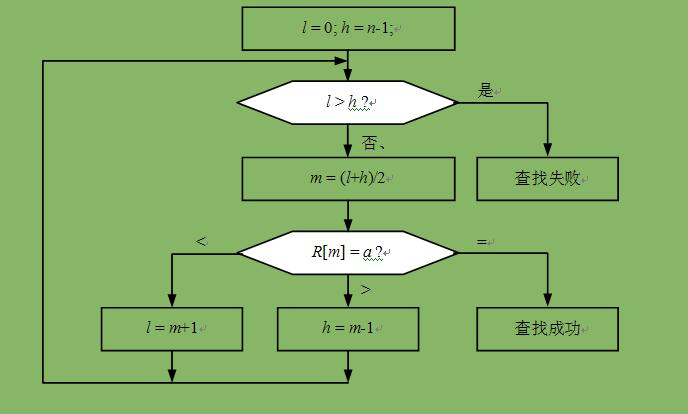
图2-2 折半查找算法的流程
执行过程为:
(1) 先设定一个查找范围,以下界l和上界h表示。l和h是数组下标。初始时,下界为0,上界为n-1,即查找范围是整个数组。
(2) 如果下界l大于上界h,则查找范围为空,查找结束。在这种情况下,数组中没有a,算法结束。
(3) 取下界l和上界h的中点m:m=(l+h)/2。
(4) 从数组的中点m处取出一个数R[m],和a进行比较。
(5) 如果R[m]等于a,则在数组中找到a,下标为m。算法结束。
(6) 如果R[m]大于a,中点上的数比a大,从中点到上界中的所有数都比a大,修改上界h为m-1。然后跳转到第2步。
(7) 如果R[m]小于a,中点上的数比a小,从下届到中点中的所有数都比a小,修改下界l为m+1。然后跳转到第2步。
缩小查找范围的过程如图2-3所示。
| 取中点 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| l |
|
|
|
|
| m |
|
|
|
|
| h | |
| R[m] > a |
|
|
|
|
|
|
|
|
|
|
|
|
|
| l |
|
|
|
| h |
|
|
|
|
|
|
| |
| R[m] < a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| l |
|
|
|
| h |
图2-3 折半查找算法缩小查找范围的过程
每经过一次比较,查找范围就缩小一半,最后有两种可能的结果:
l 在第5步找到;
l 查找范围为空(l>h)。
l=h时,查找范围只包含1个元素。算法继续执行,要么是上面第1种情况,要么是上面第2种情况。所以算法一定能结束。
实现折半查找的程序附后。数组定义为dArray,每个元素占4字节,下标为ESI,在程序中用dArray[ESI*4]来表示下标为ESI的元素。注意,dArray是一个双字型的数组,不能用dArray[ESI]来表示下标为ESI的元素。
;程序清单:split.asm(折半查找算法)
.386
.model flat,stdcall
option casemap:none
includelib msvcrt.lib
printf PROTO C :dword,:vararg
.data
dArray dword 50, 78, 99, 200, 451, 680, 718, 820, 1000, 2000
ITEMS equ ($-dArray)/4 ; 数组中元素的个数
Element dword 680 ; 在数组中查找的数字
Index dword ? ; 在数组中的序号
Count dword ? ; 查找的次数
szFmt byte 'Index=%d Count=%d Element=%d', 0ah, 0 ; 格式字符串
szErrMsg byte 'Not found, Count=%d Element=%d', 0ah, 0
.code
start:
mov Index, -1 ; 赋初值, 假设找不到
mov Count, 0 ; 赋初值, 查找次数为0
mov ecx, 0 ; ECX表示查找范围的下界
mov edx, ITEMS-1 ; EDX表示查找范围的上界
mov eax, Element ; EAX是要在数组中查找的数字
b10:
cmp ecx, edx ; 下界是否超过上界
jg b40 ; 如果下界超过上界, 未找到
mov esi, ecx ; 取下界和上界的中点
add esi, edx ; ESI=(ECX+EDX)
shr esi, 1 ; ESI=(ECX+EDX)/2
inc Count ; 查找次数加1
cmp eax, dArray[esi*4] ; 与中点上的元素比较
jz b30 ; 相等, 查找结束
jg b20 ; 较大, 移动下界
mov edx, esi ; 较小, 移动上界
dec edx ; ESI元素已比较过, 不再比较
jmp b10 ; 范围缩小后, 继续查找
b20:
mov ecx, esi ; 较大, 移动下界
inc ecx ; ESI元素已比较过, 不再比较
jmp b10 ; 范围缩小后, 继续查找
b30:
mov Index, esi ; 找到, ESI是下标
; printf("Index=%d Count=%d Element=%d/n",
; Index, Count, dArray[Index]);
invoke printf, offset szFmt, Index, Count, dArray[esi*4]
jmp b50
b40:
; printf("Not found, Count=%d Element=%d/n", Count, Element);
invoke printf, offset szErrMsg, Count, Element
b50:
ret
end start
为计算ESI=(ECX+EDX)/2,程序中采用了“shr esi, 1”指令。但是,如果ECX+EDX产生了溢出,“shr esi, 1”所得到的结果ESI≠(ECX+EDX)/2。正确的指令应该是“rcr esi, 1”。
2.3 插入数组元素
要插入一个数到有序表中,必须要找到正确的插入位置。插入这个数之前,先要把数组的元素逐个向后移动,腾出一个元素的位置后,再将这个数写到空出的位置。
升序数组为R,元素个数为n,要插入的数为a。如图2-3所示,m是要插入的位置。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
|
|
|
| m |
|
|
|
|
| n-1 |
|
图2-3 有序表插入的位置
m必须满足:R[m-1]<a且R[m]>a。特例的情况有两个:①m=0,即R[0]>a;②m=n,即R[n]<a。
找到m后,要将R[m..n-1]向后移动一个元素的位置,再执行a→R[m]。
图2-4表示了移动数组元素的过程。必须先从数组的尾部开始移动,即首先执行R[n-1]→R[n],再执行R[n-2]→R[n-1],一直到R[m]→R[m+1]。如果首先执行R[m]→R[m+1],…,R[n-2]→R[n-1],R[n-1]→R[n],则R[m]元素会依次复制到R[m+1]、R[m+2]……R[n-1]、R[n]中,造成错误结果。
|
首先执行 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
| m |
|
|
|
|
| n-1 |
|
图2-4 向后移动数组元素
最后令R[m]=a,即插入元素a到数组中。
实现有序表插入的程序如下。这里的dArray是一个数组,其中的元素是无符号数。
;程序清单:insert.asm(有序表插入算法)
.386
.model flat,stdcall
option casemap:none
includelib msvcrt.lib
printf PROTO C :dword,:vararg
.data
dArray dword 50, 78, 99, 200, 451, 680, 718, 820, 1000, 2000
ITEMS equ ($-dArray)/4 ; 数组中元素的个数
dword ? ; 插入一个元素后,dArray要延长,要占用这个双字
Element dword 500 ; 要插入数组的数字
szFmt byte 'dArray[%d]=%d', 0ah, 0 ; 输出结果格式字符串
.code
start:
mov eax, Element ; EAX是要在数组中插入的数字
mov esi, 0 ; ESI是要比较的元素的下标
c10:
cmp dArray[esi*4], eax ; 比较数组元素和要插入的数
ja c20 ; 数组中的元素较大,不再比较
inc esi ; 下标加1
cmp esi, ITEMS ; 是否数组元素全部已比较过
jb c10 ; 没有,继续比较
; 全部比较过,则ESI=ITEMS
c20: ; 插入位置为ESI, 从数组尾开始移动
mov edi, ITEMS-1 ; EDI是要移动的元素下标
c30:
cmp edi, esi ; EDI和ESI比较
jl c40 ; EDI<ESI, 已移动完成
mov ebx, dArray[edi*4] ; 先取出这个元素
mov dArray[edi*4+4], ebx ; 向后移动1个位置
dec edi ; EDI指向上一个元素
jmp c30 ; 继续移动
c40:
mov dArray[esi*4], eax ; 插入元素到下标为ESI的位置
xor edi, edi ; 显示出各元素的值
c50:
invoke printf, offset szFmt, edi, dArray[edi*4] ; 显示
inc edi ; EDI下标加1
cmp edi, ITEMS ; 是否已全部显示完
jbe c50 ; 继续显示
ret
end start
2.4 删除数组元素
要从一个数组中删除一个元素,先要找到被删元素的位置。将被删元素后面的全部元素向前移动一个位置,该元素被删除后,数组的元素仍然保持顺序存放。
如图2-4所示,数组为R,元素个数为n,要删除的数为a。m是被删元素的下标。
|
|
|
|
|
|
| a |
|
|
|
|
|
|
| 0 |
|
|
|
|
| m |
|
|
|
|
| n-1 |
图2-4 数组元素删除的位置
找到m后,要将R[m+1..n-1]向前移动一个元素的位置,再将n(数组元素个数)减一。
图2-5表示了移动数组元素的过程。必须先从R[m+1]元素开始移动,即首先执行R[m+1]→R[m],再执行R[m+2]→R[m+1],一直到R[n-1]→R[n-2]。
|
首先执行 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
| m |
|
|
|
|
| n-1 |
|
图2-5 向前移动数组元素
;程序清单:delete.asm(删除数组元素)
.386
.model flat,stdcall
option casemap:none
includelib msvcrt.lib
printf PROTO C :dword,:vararg
scanf PROTO C :dword,:vararg
.data
dArray dword 850, 7, 39, 200, 13, 60, 47, 0, 600, 240
nItems dword ($-dArray)/4 ; 数组中元素的个数
Element dword ? ; 要删除的元素
szFmt byte 'dArray[%d]=%d', 0ah, 0 ; 输出结果格式字符串
dElement dword ?
szPrompt byte 'Input the element to delete: ', 0 ; 提示字符串
szScanfIn byte '%d', 0
szNotFound byte '%d is not found.', 0
.code
start:
invoke printf, offset szPrompt
invoke scanf, offset szScanfIn, offset Element
mov eax, Element ; EAX是要在数组中删除的元素
mov esi, 0 ; ESI是要比较的元素的下标
c10:
cmp dArray[esi*4], eax ; 是否要删除?
jz c20 ; 相等,删除之
inc esi ; 下标加1
cmp esi, nItems ; 是否数组元素全部已比较过
jb c10 ; 没有,继续比较
invoke printf, offset szNotFound, Element
jmp c60 ; 全部比较过, 没有找到
c20:
dec nItems
mov edi, esi ; EDI是被覆盖的元素下标
c30:
cmp edi, nItems ; EDI和nItems比较
jae c40 ; EDI>=nItems, 已移动完成
mov ebx, dArray[edi*4+4] ; 先取出下一个元素
mov dArray[edi*4], ebx ; 向前移动1个位置
inc edi ; EDI指向下一个元素
jmp c30 ; 继续移动
c40:
xor edi, edi ; 显示出各元素的值
c50:
invoke printf, offset szFmt, edi, dArray[edi*4] ; 显示
inc edi ; EDI下标加1
cmp edi, nItems ; 是否已全部显示完
jb c50 ; 继续显示
c60:
ret
end start
上述程序可以进一步完善:(1) 如果数组是一个有序表,如何减少查找次数;(2) 处理被删的元素在数组中出现多次的情况。
2.5 实验题:两个有序数组的合并实验
将2个升序数组合并为1个数组,计算合并所需时间,比较不同程序所需时间之间的差异。
要求:
1. 2个升序数组及结果数组定义如下:
dArray1 dword 80, 100, 500, 600, 700, 1500, 1600, 2200, 2400
ITEMS1 equ ($-dArray1)/4 ; 数组1中元素的个数
dArray2 dword 50, 78, 99, 200, 451, 680, 718, 820, 1000, 2000
ITEMS2 equ ($-dArray2)/4 ; 数组2中元素的个数
dArray dword ITEMS1+ITEMS2 dup(0)
ITEMS equ ($-dArray)/4 ; 结果数组中元素的个数
2. 为测试合并程序的正确性,应怎样设定dArray1、dArray2中的内容?可以考虑从键盘输入dArray1、dArray2各元素,以方便测试。
3. 每一次合并操作所需的时间极短,应该使合并操作重复循环多次。在循环执行前、后分别调用time函数,二者之间的差就是循环的执行时间。显示出循环的次数和执行时间。time函数的原型为:
_CRTIMP time_t __cdecl time(time_t *);
4. 多份程序之间的对比。在同一计算机(或者配置相同的计算机)上运行程序,比较程序运行所需时间。分析运行时间较短的程序的优点,找出缩短程序运行时间的方法。
5. 如果dArray1、dArray2为降序排序,应如何改动程序?















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









