








问题描述:
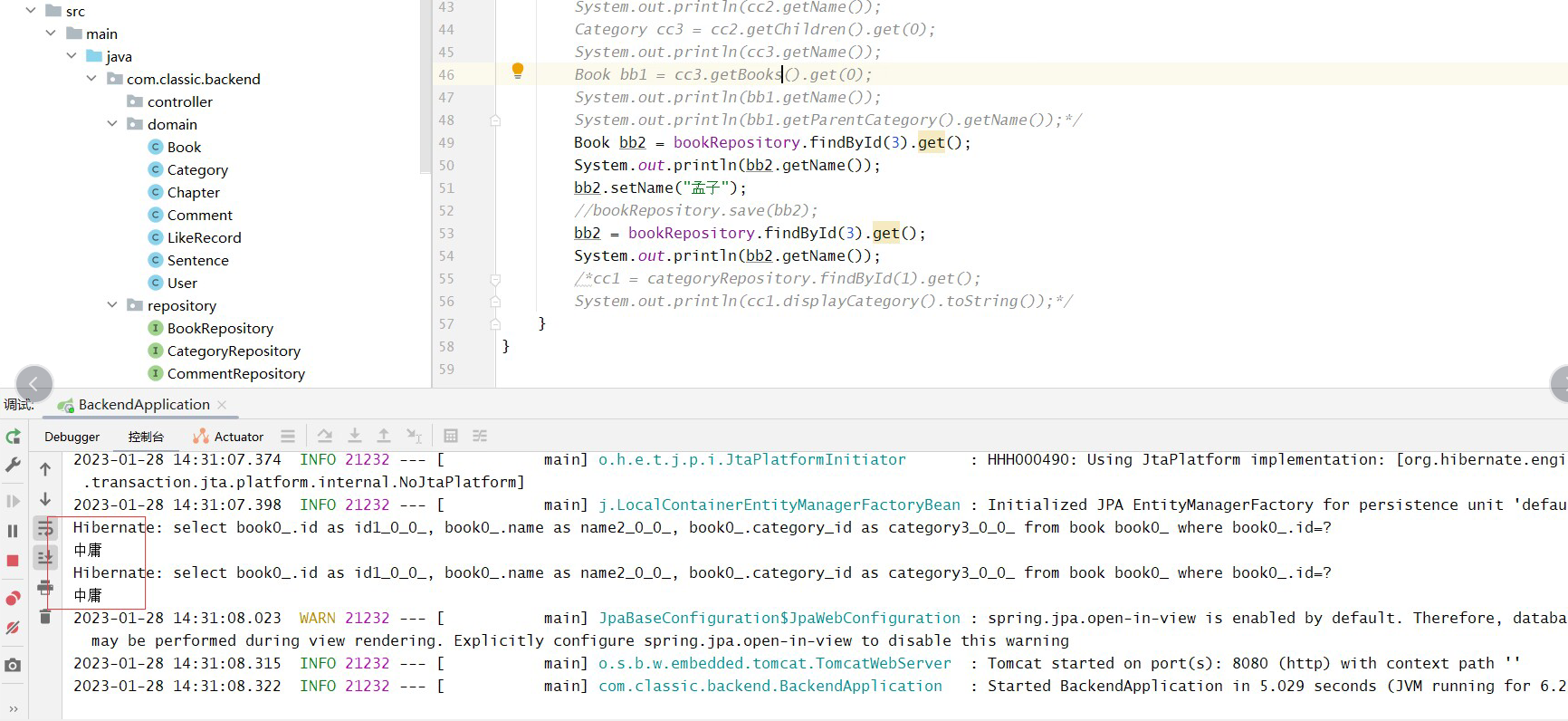
springdatajpa支持直接操作对象设置属性进行更新数据库记录的方式,正常情况下,get()得到的对象直接进行set后,即使不进行save操作,也将自动更新数据记录,将改动持久化到数据库中,但这里可以看到并没有生效。
问题分析:
根据问题分析可推测,大概有几种可能导致不生效:
对象不属于托管态,所以set后不生效
字段设置了@Transient注解
设置了readOnly=true,导致不生效
未flush缓存,导致不生效
- 对象不属于托管态,所以set后不生效
首先需要了解springdatajpa自动保存的原理,这里涉及到springdatajpa中对象的几种存在状态以及jpa的缓存机制。感兴趣的可以自己详细了解一下。这里不展开说了,
Heibernate 中对象分为以下几种状态:

一、瞬时状态
瞬时状态的实体就是一个普通的java对象,和持久化上下文无关联,数据库中也没有数据与之对应。
二、托管状态
使用EntityManager进行find或者persist操作返回的对象即处于托管状态,此时该对象已经处于持久化上下文中,因此任何对于该实体的更新都会同步到数据库中。JavaBean与EntityManager发生关系后将被持久化,该Bean的任何属性改动都会牵涉到数据库记录的改动。也就是说只要我们改动这个Bean的属性,无需我们去调用其他方法,数据库的数据会自动同步。
表现为 :对 Jpa 对象进行set,但是不save,数据库也能自动更新。
三、游离状态
当事务提交后,处于托管状态的对象就转变为了游离状态。此时该对象已经不处于持久化上下文中,因此任何对于该对象的修改都不会同步到数据库中。
四、删除状态
当调用EntityManger对实体进行delete后,该实体对象就处于删除状态。其本质也就是一个瞬时状态的对象。
不同状态之间,可通过编码调用不同方法或执行相关操作触发进行转换,如刚new出来的对象是瞬时态,瞬时态可通过调用persist方法转变成托管状态,当处在托管状态的实体 Bean 被管理器 flush 了,那么就在极短暂的时间进入了持久化状态,持久态的对象属性的更改都会牵涉到数据库记录的改动。
五、持久化状态
当处在托管状态的实体Bean被管理器flush了,那么就在极短暂的时间进入了持久化状态,事务提交之后,立刻变为了游离状态。可以把持久化状态当做实实在在的数据库记录。
回到问题:
book对象为从数据库中查询得到,属于托管态,正常情况下,此时对book对象进行set操作,修改name后,应该会改变数据库中的name,但实际上执行后却并未生效。手动执行save操作后发现生效了。
第二种情况:设置了@Transient注解

查看代码可知,name字段并未设置@Transient注解
三、设置了readOnly=true,flush不刷新,导致不生效
这里需要了解jpa的缓存机制

一级缓存
Spring Data JPA的一级缓存就是当使用自定义Repository的find()或者findxx()方法去查询记录时,第一次会去查询数据库,然后会把查询结果存放到内存中作为缓存,后面再查询相同的记录时会直接把缓存中的结果返回,不再去查询数据库。此后对查询出来的实体进行属性修改时,均会修改缓存中的数据。
flush()方法将缓存中所有发生修改的实体的状态信息同步到数据库中。当在一个事务内通过save()方法去update一个从数据库中查询出来的实体时,Spring Data JPA并不会马上执行Update SQL语句,将修改同步到数据库,而是等到事务提交时才会通过某种机制(下面会对该机制进行描述)决定是否调用flush()方法将缓存中的实体信息同步到数据库中,当调用 flush()方法时才会执行Update SQL语句。
快照区
Spring Data JPA除了一级缓存外,还有一个快照区,当将查询结果放到一级缓存中时,会同时复制一份数据放入快照区中,Spring Data JPA通过快照区与缓存中的数据是否一致来判断数据从数据库查询出来后是否发生过修改。
Spring Data JPA在事务提交时,为了保持数据库和缓存的数据同步,会清理一级缓存并根据主键字段值判断一级缓存中的对象属性值和快照中的对象属性值是否一致,如果两个对象的属性值不一致,则调用flush()方法执行Update SQL语句,将缓存的内容同步到数据库,并更新快照;如果一致,则不调用flush()方法。

在设置了@Transactional(readOnly = true)不会进行自动flush操作
设置了@Transactional(readOnly = false)会在事务commit时触发flush方法,所以在图中第二部分执行结果中,Flushing session 在Initiating transaction commit之后
而对于手动执行flush操作的,也就是图中第三部分执行结果中,Flushing session会在Flushing session 在Initiating transaction commit之前。
Flush与事务Commit的关系
在当前的事务执行commit时会触发flush方法
在当前的事务执行完commit时,如果隔离级别是可重复度,flush之后执行的update,insert,delete的操作会被其他的新事物看到最新的结果。
假设当前的事务是可重复度,手动执行flush方法之后,没有执行commit,那么其他事务是看不到最新值的变化的。但最新值变化对当前没有commit的事务是有效的。
如果执行了flush之后,当前事务发生了rollback操作,那么数据将会被回滚(数据库的机制)
Flush的自动机制
前面讲到了当前的事务执行commit时会触发flush方法,那么除此之外还有什么情况下会自动触发flush呢?
1.事务commit之前,即指执行transactionManager.commit()之前都会触发
2.执行任何的JPQL或者nativeSQL(代替直接操作Entity的方法)都会触发flush(可以理解为不走一级缓存,所以这个时候拿到的可能是旧数据,所以在此之前需要把当前的最新改动flush到DB)
回到问题:

检查代码发现并没有设置readOnly。
4、未flush缓存,导致不生效
根据上面的排查,基本可以判断是因为没有触发flush操作,导致数据未自动更新到数据库,结合flush的刷新机制可知,事务执行commit时会触发flush方法,那么既然没有flush,说明事务有问题,这里的事务失效了,方法是使用@Postconstruct注解标识,启动后自动执行方法,这样的方式,无法通过注解方式生成代理类,事务不会生效,自然也不会触发flush操作从而导致set方法自动更新数据库记录失效。
解决办法:将方法放到service中,使用注解事务。在上层controller中去调用,保证事务生效即可。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









