







现在我们将进入传输层的分析:
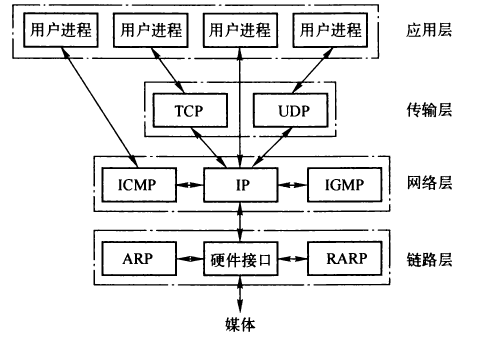
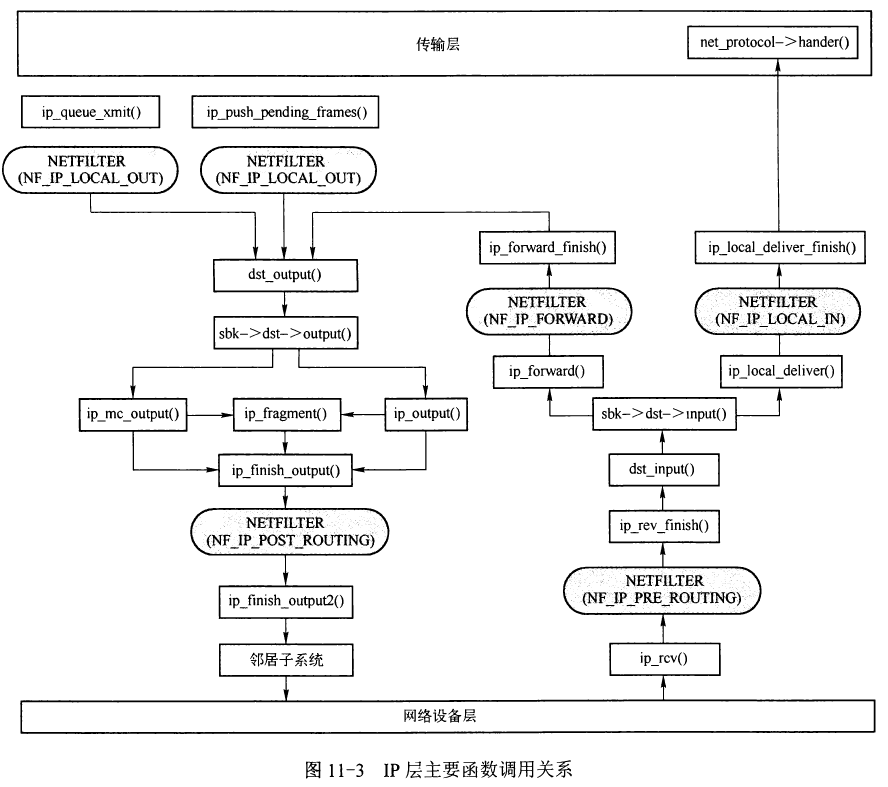
在前面我们知道,数据包到达接口层的时候,它会根据ptype_base来查询包的类型,并根据包的类型交给不同的网络层函数处理,比如ip_recv,icmp_recv等,现在我们就来看看网络层是怎么处理不同类型的包的:
1. IP私有信息控制块

40 struct inet_skb_parm {
41 int iif;
42 struct ip_options opt; /* Compiled IP options */ IP头部的选项都存放在这里
43 u16 flags;
44
45 #define IPSKB_FORWARDED BIT(0)
46 #define IPSKB_XFRM_TUNNEL_SIZE BIT(1)
47 #define IPSKB_XFRM_TRANSFORMED BIT(2)
48 #define IPSKB_FRAG_COMPLETE BIT(3)
49 #define IPSKB_REROUTED BIT(4)
50 #define IPSKB_DOREDIRECT BIT(5)
51 #define IPSKB_FRAG_PMTU BIT(6)
52 #define IPSKB_L3SLAVE BIT(7)
53
54 u16 frag_max_size;
55 };
2. ip_rcv
404 /*
405 * Main IP Receive routine.
406 */
407 int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
408 {
409 const struct iphdr *iph; //用于操作IP头部
410 struct net *net;
411 u32 len;
412
413 /* When the interface is in promisc. mode, drop all the crap
414 * that it receives, do not try to analyse it.
415 */
416 if (skb->pkt_type == PACKET_OTHERHOST) //丢掉不是去往本地的包,比如在抓包模式下有很多包不是到本地的
417 goto drop;
418
419
420 net = dev_net(dev);//获取网络空间
421 __IP_UPD_PO_STATS(net, IPSTATS_MIB_IN, skb->len);
422
423 skb = skb_share_check(skb, GFP_ATOMIC); //如果数据包是一个共享数据包,则需要复制一个备份在作进一步处理,以免在处理过程中数据被修改
424 if (!skb) {
425 __IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
426 goto out;
427 }
428
429 if (!pskb_may_pull(skb, sizeof(struct iphdr)))//通过数据包长度判断数据包是否有效,不能小于IP首部长度
430 goto inhdr_error;
431
432 iph = ip_hdr(skb); //获取IP首部
434 /*
435 * RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
436 *
437 * Is the datagram acceptable?
438 *
439 * 1. Length at least the size of an ip header
440 * 2. Version of 4
441 * 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
442 * 4. Doesn't have a bogus length
443 */
444
445 if (iph->ihl < 5 || iph->version != 4) //IP首部至少20个bit,也就是说至少要2的5次方32才能放下,如果小于5说明头部不对;协议版本号是IPV4
446 goto inhdr_error;
447
448 BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);
449 BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);
450 BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);
451 __IP_ADD_STATS(net,
452 IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),
453 max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));
454
455 if (!pskb_may_pull(skb, iph->ihl*4)) //根据首部长度检测数据包是否有效
456 goto inhdr_error;
457
458 iph = ip_hdr(skb);
459
460 if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))//检测首部的校验和是否有效
461 goto csum_error;
463 len = ntohs(iph->tot_len);
464 if (skb->len < len) { //根据IP头部的总长度检测数据包是否有效
465 __IP_INC_STATS(net, IPSTATS_MIB_INTRUNCATEDPKTS);
466 goto drop;
467 } else if (len < (iph->ihl*4))
468 goto inhdr_error;
469
470 /* Our transport medium may have padded the buffer out. Now we know it
471 * is IP we can trim to the true length of the frame.
472 * Note this now means skb->len holds ntohs(iph->tot_len).
473 */
474 if (pskb_trim_rcsum(skb, len)) { //根据IP数据首部的总长度重新设置skb的长度
475 __IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
476 goto drop;
477 }
478
479 skb->transport_header = skb->network_header + iph->ihl*4;
480
481 /* Remove any debris in the socket control block */
482 memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));
483 IPCB(skb)->iif = skb->skb_iif;//将skb中的IP控制块清0,以便后续对IP选项的处理
484
485 /* Must drop socket now because of tproxy. */
486 skb_orphan(skb);
/*首先调用skb_orphan把skb孤立,使它跟发送socket和协议栈不再有任何联系,也即对本机来说,
**这个skb的数据内容已经发送出去了,而skb相当于已经被释放掉了。对于环回设备接口来说,
**数据的发送工作至此已经全部完成,接下来,只要把这个实际上还未被释放的skb传回给协议栈
**的接收函数即可。
487
488 return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, //通过netfilter处理函数调用ip_rcv_finish
489 net, NULL, skb, dev, NULL,
490 ip_rcv_finish);
491
492 csum_error:
493 __IP_INC_STATS(net, IPSTATS_MIB_CSUMERRORS);
494 inhdr_error:
495 __IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
496 drop:
497 kfree_skb(skb);
498 out:
499 return NET_RX_DROP;
500 }
3. ip_rcv_finish
311 static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
312 {
313 const struct iphdr *iph = ip_hdr(skb); //获取IP头部
314 struct rtable *rt; //管理路由表
315 struct net_device *dev = skb->dev; //获取网络设备信息
316 void (*edemux)(struct sk_buff *skb);
317
318 /* if ingress device is enslaved to an L3 master device pass the
319 * skb to its handler for processing
320 */
321 skb = l3mdev_ip_rcv(skb); //如果这个包隶属于第三层主设备,则交给第三层,并且将SKB设成NULL
322 if (!skb) //如果交给了第三层,则return
323 return NET_RX_SUCCESS;
324
325 if (net->ipv4.sysctl_ip_early_demux &&
326 !skb_dst(skb) &&
327 !skb->sk &&
328 !ip_is_fragment(iph)) {
329 const struct net_protocol *ipprot; //获取协议类型
330 int protocol = iph->protocol;
331
332 ipprot = rcu_dereference(inet_protos[protocol]);
333 if (ipprot && (edemux = READ_ONCE(ipprot->early_demux))) {
334 edemux(skb);
335 /* must reload iph, skb->head might have changed */
336 iph = ip_hdr(skb);
337 }
338 }
340 /*
341 * Initialise the virtual path cache for the packet. It describes
342 * how the packet travels inside Linux networking.
343 */
344 if (!skb_valid_dst(skb)) { //如果还没为该数据查找路由缓存,则调用下列函数为其查找,如果查找失败则丢弃该报文
345 int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
346 iph->tos, dev);
347 if (unlikely(err)) {
348 if (err == -EXDEV)
349 __NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
350 goto drop;
351 }
352 }
353
354 #ifdef CONFIG_IP_ROUTE_CLASSID //与路由表classifier相关
355 if (unlikely(skb_dst(skb)->tclassid)) {
356 struct ip_rt_acct *st = this_cpu_ptr(ip_rt_acct);
357 u32 idx = skb_dst(skb)->tclassid;
358 st[idx&0xFF].o_packets++;
359 st[idx&0xFF].o_bytes += skb->len;
360 st[(idx>>16)&0xFF].i_packets++;
361 st[(idx>>16)&0xFF].i_bytes += skb->len;
362 }
363 #endif
364
365 if (iph->ihl > 5 && ip_rcv_options(skb))//判断IP首部是否有option,如果有则调用option处理函数
366 goto drop;
367
368 rt = skb_rtable(skb);
369 if (rt->rt_type == RTN_MULTICAST) {
370 __IP_UPD_PO_STATS(net, IPSTATS_MIB_INMCAST, skb->len);
371 } else if (rt->rt_type == RTN_BROADCAST) {
372 __IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);
373 } else if (skb->pkt_type == PACKET_BROADCAST ||
374 skb->pkt_type == PACKET_MULTICAST) {
375 struct in_device *in_dev = __in_dev_get_rcu(dev);
376
377 /* RFC 1122 3.3.6:
378 *
379 * When a host sends a datagram to a link-layer broadcast
380 * address, the IP destination address MUST be a legal IP
381 * broadcast or IP multicast address.
382 *
383 * A host SHOULD silently discard a datagram that is received
384 * via a link-layer broadcast (see Section 2.4) but does not
385 * specify an IP multicast or broadcast destination address.
386 *
387 * This doesn't explicitly say L2 *broadcast*, but broadcast is
388 * in a way a form of multicast and the most common use case for
389 * this is 802.11 protecting against cross-station spoofing (the
390 * so-called "hole-196" attack) so do it for both.
391 */
392 if (in_dev &&
393 IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST))
394 goto drop;
395 }
396
397 return dst_input(skb); //根据路由缓存将数据包交给本地处理还是转发出去,本地处理将调用ip_local_deliver,如果要转发出去则调用ip_forward
399 drop:
400 kfree_skb(skb);
401 return NET_RX_DROP;
402 }
4. ip_local_deliver
242 /*
243 * Deliver IP Packets to the higher protocol layers.
244 */
245 int ip_local_deliver(struct sk_buff *skb)
246 {
247 /*
248 * Reassemble IP fragments.
249 */
250 struct net *net = dev_net(skb->dev); //获取网络空间
251
252 if (ip_is_fragment(ip_hdr(skb))) { //如果收到的是分片包,则调用ip_defrag进行重组,对应的标示是IP_DEFRAG_LOCAL_DELIVER
253 if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
254 return 0; //如果返回0表示分片尚未到齐,重组没有完成
255 }
256
257 return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
258 net, NULL, skb, skb->dev, NULL,
259 ip_local_deliver_finish); //如果重组完成,则调用ip_local_deliver_finish将组装完成的数据包交给传输层处理
260 }
5. ip_local_deliver_finish
调用这个函数后,数据包的处理结果有三种:交给raw套接字处理,交给传输层处理,因异常而被丢弃
192 static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
193 {
194 __skb_pull(skb, skb_network_header_len(skb)); //在交给传输层之前先去掉IP头部
195
196 rcu_read_lock();
197 {
198 int protocol = ip_hdr(skb)->protocol; //获取传输层协议号,用于计算哈希值
199 const struct net_protocol *ipprot;
200 int raw;
201
202 resubmit:
203 raw = raw_local_deliver(skb, protocol); //根据protocol得到哈希值,然后查看raw_v4_htable散列表中以该值为关键字
的哈希桶是否为空。如果不为空,则说明创建了RAW套接口,复制该数据包的副本输入到注册该桶中的所有套接口
205 ipprot = rcu_dereference(inet_protos[protocol]);//查找inet_protos数组中是否注册了与IP首部中传输层协议号一致的
传输层协议。如果查找命中则调用对应的传输层接收函数
206 if (ipprot) {
207 int ret;
208
209 if (!ipprot->no_policy) {
210 if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { //数据包安全策略检测,与ipsec相关
211 kfree_skb(skb);
212 goto out;
213 }
214 nf_reset(skb);
215 }
216 ret = ipprot->handler(skb); //这个是传输层的接收函数,包括tcp_protocol, udp_protocol, icmp_protocol
217 if (ret < 0) {
218 protocol = -ret;
219 goto resubmit;
220 }
221 __IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
222 } else {
223 if (!raw) {
224 if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
225 __IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS);
226 icmp_send(skb, ICMP_DEST_UNREACH, //如果raw套接字没有接收或者接收异常,则发送一个协议不可达的报文给对方
227 ICMP_PROT_UNREACH, 0);
228 }
229 kfree_skb(skb); //释放该报文。
230 } else {
231 __IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
232 consume_skb(skb); //如果没有相应的传输层协议接收该报文,则释放该报文。
233 }
234 }
235 }
236 out:
237 rcu_read_unlock();
238
239 return 0;
240 }
6. ip_forward
现在来了解一下数据包被转发出去的情况,执行的是ip_forward:

77 int ip_forward(struct sk_buff *skb)
78 {
79 u32 mtu;
80 struct iphdr *iph; /* Our header */
81 struct rtable *rt; /* Route we use */
82 struct ip_options *opt = &(IPCB(skb)->opt); //获取数据包中IP的option
83 struct net *net;
84
85 /* that should never happen */
86 if (skb->pkt_type != PACKET_HOST) //不是发往本机的包丢弃
87 goto drop;
88
89 if (unlikely(skb->sk))
90 goto drop;
91
92 if (skb_warn_if_lro(skb)) //与GSO相关
93 goto drop;
94
95 if (!xfrm4_policy_check(NULL, XFRM_POLICY_FWD, skb)) //查找IPsec数据库,如果查找失败则丢包
96 goto drop;
97
98 if (IPCB(skb)->opt.router_alert && ip_call_ra_chain(skb)) //如果IP option中存在警告选项,则调用ip_call_ra_chain将数据包输入给对路由警告选项感兴趣的用
户进程。如果成功则不再转发该数据包
99 return NET_RX_SUCCESS;
100
101 skb_forward_csum(skb); //在转发过程中可能会修改IP首部,则调用该函数skb->ip_summed = CHECKSUM_NONE,后面输出时要计算新的校验和
102 net = dev_net(skb->dev);
103
104 /*
105 * According to the RFC, we must first decrease the TTL field. If
106 * that reaches zero, we must reply an ICMP control message telling
107 * that the packet's lifetime expired.
108 */
109 if (ip_hdr(skb)->ttl <= 1) //如果跳数小于或等于1,则不转发,并跳转到发送ICMP报文
110 goto too_many_hops;
111
112 if (!xfrm4_route_forward(skb)) //进行IPsec的路由选择和转发,如果失败则丢包
113 goto drop;
114
115 rt = skb_rtable(skb); //获取路由
116
117 if (opt->is_strictroute && rt->rt_uses_gateway) //如果数据包启动严格路由选项,且路由的下一跳不是网关,则发送超时ICMP报文到发送方
118 goto sr_failed;
119
120 IPCB(skb)->flags |= IPSKB_FORWARDED; //设置IP管理块中的flag为FORWORD
121 mtu = ip_dst_mtu_maybe_forward(&rt->dst, true); //获取当前系统的最小MTU
122 if (ip_exceeds_mtu(skb, mtu)) { //如果该包的大小超过了最新MTU,则发送ICMP给发送端,并且停止转发
123 IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
124 icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
125 htonl(mtu));
126 goto drop;
127 }
128
129 /* We are about to mangle packet. Copy it! */
130 if (skb_cow(skb, LL_RESERVED_SPACE(rt->dst.dev)+rt->dst.header_len)) //确保SKB有指定长度的headroom,当他的headroom小于指定长度或者克隆SKB时,
会新建SKB缓冲,并且释放对原包的引用
131 goto drop;
132 iph = ip_hdr(skb); //获取IP头部
134 /* Decrease ttl after skb cow done */
135 ip_decrease_ttl(iph); //将TTL减1
136
137 /*
138 * We now generate an ICMP HOST REDIRECT giving the route
139 * we calculated.
140 */
141 if (IPCB(skb)->flags & IPSKB_DOREDIRECT && !opt->srr && //如果该数据包的输出路由存在重定向标志,且该数据报中不存在源路由选项,则向发送端发送
142 !skb_sec_path(skb)) //重定向ICMP报文
143 ip_rt_send_redirect(skb);
144
145 skb->priority = rt_tos2priority(iph->tos);
146
147 return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD,
148 net, NULL, skb, skb->dev, rt->dst.dev,
149 ip_forward_finish); //经过netfilter处理后,调用ip_forward_finish进一步处理
150
151 sr_failed:
152 /*
153 * Strict routing permits no gatewaying
154 */
155 icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
156 goto drop;
157
158 too_many_hops:
159 /* Tell the sender its packet died... */
160 __IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
161 icmp_send(skb, ICMP_TIME_EXCEEDED, ICMP_EXC_TTL, 0);
162 drop:
163 kfree_skb(skb);
164 return NET_RX_DROP;
165 }
7. ip_forward_finish
64 static int ip_forward_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
65 {
66 struct ip_options *opt = &(IPCB(skb)->opt);
67
68 __IP_INC_STATS(net, IPSTATS_MIB_OUTFORWDATAGRAMS);
69 __IP_ADD_STATS(net, IPSTATS_MIB_OUTOCTETS, skb->len);
70
71 if (unlikely(opt->optlen)) //如果option的长度不为0
72 ip_forward_options(skb); //处理转发IP数据报中的IP选项,包括记录路由选项和时间戳选项
73
74 return dst_output(net, sk, skb); //通过路由缓存将数据包输出,最终会调用单播的输出函数ip_output或组播的输出函数ip_mc_output
75 }
8. ip_output
395 int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
396 {
397 struct net_device *dev = skb_dst(skb)->dev;
398
399 IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
400
401 skb->dev = dev; //设置数据包的输出网络设备
402 skb->protocol = htons(ETH_P_IP); //设置数据包网络层协议类型
403
404 return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
405 net, sk, skb, NULL, dev,
406 ip_finish_output,
407 !(IPCB(skb)->flags & IPSKB_REROUTED)); //调用ip_finish_output继续IP包的输出
408 }
9. ip_finish_output
291 static int ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
292 {
293 unsigned int mtu;
294 int ret;
295
296 ret = BPF_CGROUP_RUN_PROG_INET_EGRESS(sk, skb);
297 if (ret) {
298 kfree_skb(skb);
299 return ret;
300 }
301
302 #if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM)
303 /* Policy lookup after SNAT yielded a new policy */
304 if (skb_dst(skb)->xfrm) {
305 IPCB(skb)->flags |= IPSKB_REROUTED;
306 return dst_output(net, sk, skb); //根据安全策略需要重传
307 }
308 #endif
309 mtu = ip_skb_dst_mtu(sk, skb); //获取最小MTU的大小
310 if (skb_is_gso(skb))
311 return ip_finish_output_gso(net, sk, skb, mtu); //如果需要支持GSO特性,则进行GSO的组装,关于GSO的特性我们后面分开讲
312
313 if (skb->len > mtu || (IPCB(skb)->flags & IPSKB_FRAG_PMTU))
314 return ip_fragment(net, sk, skb, mtu, ip_finish_output2); //如果长度不满足要求则进行IP包的分段
315
316 return ip_finish_output2(net, sk, skb); //调用该函数继续处理
317 }
10. ip_finish_output2
183 static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
184 {
185 struct dst_entry *dst = skb_dst(skb);
186 struct rtable *rt = (struct rtable *)dst;
187 struct net_device *dev = dst->dev;
188 unsigned int hh_len = LL_RESERVED_SPACE(dev);
189 struct neighbour *neigh;
190 u32 nexthop;
191
192 if (rt->rt_type == RTN_MULTICAST) {
193 IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTMCAST, skb->len);
194 } else if (rt->rt_type == RTN_BROADCAST)
195 IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTBCAST, skb->len);
196
197 /* Be paranoid, rather than too clever. */
198 if (unlikely(skb_headroom(skb) < hh_len && dev->header_ops)) { //检测skb头部空间是否还有空间存放链路层首部,如果不够,则重新分配更大的存储空间,
199 struct sk_buff *skb2; //并释放原来的SKB
200
201 skb2 = skb_realloc_headroom(skb, LL_RESERVED_SPACE(dev));
202 if (!skb2) {
203 kfree_skb(skb);
204 return -ENOMEM;
205 }
206 if (skb->sk)
207 skb_set_owner_w(skb2, skb->sk);
208 consume_skb(skb);
209 skb = skb2;
210 }
211
212 if (lwtunnel_xmit_redirect(dst->lwtstate)) {
213 int res = lwtunnel_xmit(skb);
214
215 if (res < 0 || res == LWTUNNEL_XMIT_DONE)
216 return res;
217 }
219 rcu_read_lock_bh();
220 nexthop = (__force u32) rt_nexthop(rt, ip_hdr(skb)->daddr); //获取下一跳路由
221 neigh = __ipv4_neigh_lookup_noref(dev, nexthop); //查找邻居子系统
222 if (unlikely(!neigh))
223 neigh = __neigh_create(&arp_tbl, &nexthop, dev, false); //如果没有查到,则根据下一跳路由创建一跳新的记录
224 if (!IS_ERR(neigh)) { //如果创建成功
225 int res;
226
227 sock_confirm_neigh(skb, neigh); //确认路由,如果不能确认则设置对应的标识
228 res = neigh_output(neigh, skb); //调用该函数交给邻居子系统
229
230 rcu_read_unlock_bh();
231 return res;
232 }
233 rcu_read_unlock_bh();
234
235 net_dbg_ratelimited("%s: No header cache and no neighbour!\n",
236 __func__);
237 kfree_skb(skb);
238 return -EINVAL;
239 }
472 static inline int neigh_output(struct neighbour *n, struct sk_buff *skb)
473 {
474 const struct hh_cache *hh = &n->hh;
475
476 if ((n->nud_state & NUD_CONNECTED) && hh->hh_len) //如果缓存了链路层的首部,则调用neigh_hh_output,否则调用邻居项的输出方法输出
477 return neigh_hh_output(hh, skb); //调用该函数输出数据包
478 else
479 return n->output(n, skb); //使用邻居项的输出方法
480 }
450 static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb)
451 {
452 unsigned int seq;
453 unsigned int hh_len;
454
455 do {
456 seq = read_seqbegin(&hh->hh_lock);
457 hh_len = hh->hh_len;
458 if (likely(hh_len <= HH_DATA_MOD)) {
459 /* this is inlined by gcc */
460 memcpy(skb->data - HH_DATA_MOD, hh->hh_data, HH_DATA_MOD);
461 } else {
462 unsigned int hh_alen = HH_DATA_ALIGN(hh_len);
463
464 memcpy(skb->data - hh_alen, hh->hh_data, hh_alen);
465 }
466 } while (read_seqretry(&hh->hh_lock, seq));
467
468 skb_push(skb, hh_len);
469 return dev_queue_xmit(skb); //到这里将包从网络层发送给接口层
470 }















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









