






1、线性表的链式存储结构
线性表采用链式存储结构,称为线性链表(Linked List),逻辑上相邻的元素是分散存储的,因此必须采用指针变量记载前驱或者后继元素的地址,来存储元素之间的线性关系。
存储一个元素的存储单元叫做结点(Node)。结构如下
结点(结点域,地址域)
一个结点存储一个数据元素,通过地址将节点链接起来,结点之间的链接关系就可以体现线性表中数据元素的次序关系(逻辑结构)。一条线性链表表头必须使用头指针记住元素的结点地址。
每个结点只有一个地址域的线性链表成为单链表(singly linked list)
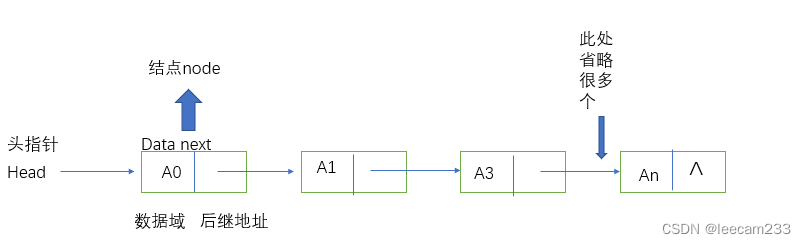
单链表中结点的存储空间是在插入和删除过程中动态申请和释放的,不需要预先给单链表分配存储空间,这也就避免了顺序表因为存储空间不足需要扩充空间和复制元素的过程,提高了运行效率和存储空间利用率。对单链表进行插入删除操作只要改变少量节点的链,不需要移动元素。
2、单链表
单链表是由一个个结点链接而成。
2.1单链表结点
声明Node<T>单链表节点类如下,成员变量data表示数据域,存储数据元素,数据类型是T;next表示地址域,存储后继结点的引用信息。
public class Node <T>{ //结点类,T指定结点数据类型
public T data; //数据域
public Node next; //地址域
public Node(T data,Node next){ //构造结点 data指定数据元素,next指定后继结点
this.data=data; //T对象引用赋值
this.next=next; //Node<T>对象引用赋值
}
public Node(){
this(null,null);
}
public String toString() { //返回结点数据域的描述字符串
return this.data.toString();
}
}Node<T>是自引用的类,它的成员变量next的数据类型是Node<T>类自己。自引用的类是指一个类声明包含引用当前类实例的成员变量。
Node<T>类的一个实例表示单链表的一个结点。若干结点通过next链指定相互之间的顺序关系,形成一条单链表。为了方便更改结点之间的链接关系,将Node类中的两个成员变量声明为public,允许被其他类访问。
单链表的头指针head是一个结点引用,声明如下:
Node<T> head=null;
当head=null时,表示空链表。
2、单链表的遍历操作
遍历单链表时从第0个结点开始,沿着结点的next链,依次访问单链表中每个结点,并且每个结点只访问一次。
设已创建一条单链表,遍历操作不能改变单链表头指针head,因此需要声明一个变量p(指针含义)指向当前访问结点。p从head引用结点开始访问,沿着next链到达后继结点,逐个访问,直到最后一个结点,完成一次遍历操作。
Node<T> p=head;
while(p!=null){
System.out.println(p.data.toString());
p=p.next;
}3、单链表的插入操作
在单链表中插入一个结点,根据不同的插入位置,分四种情况讨论,如下图所示:
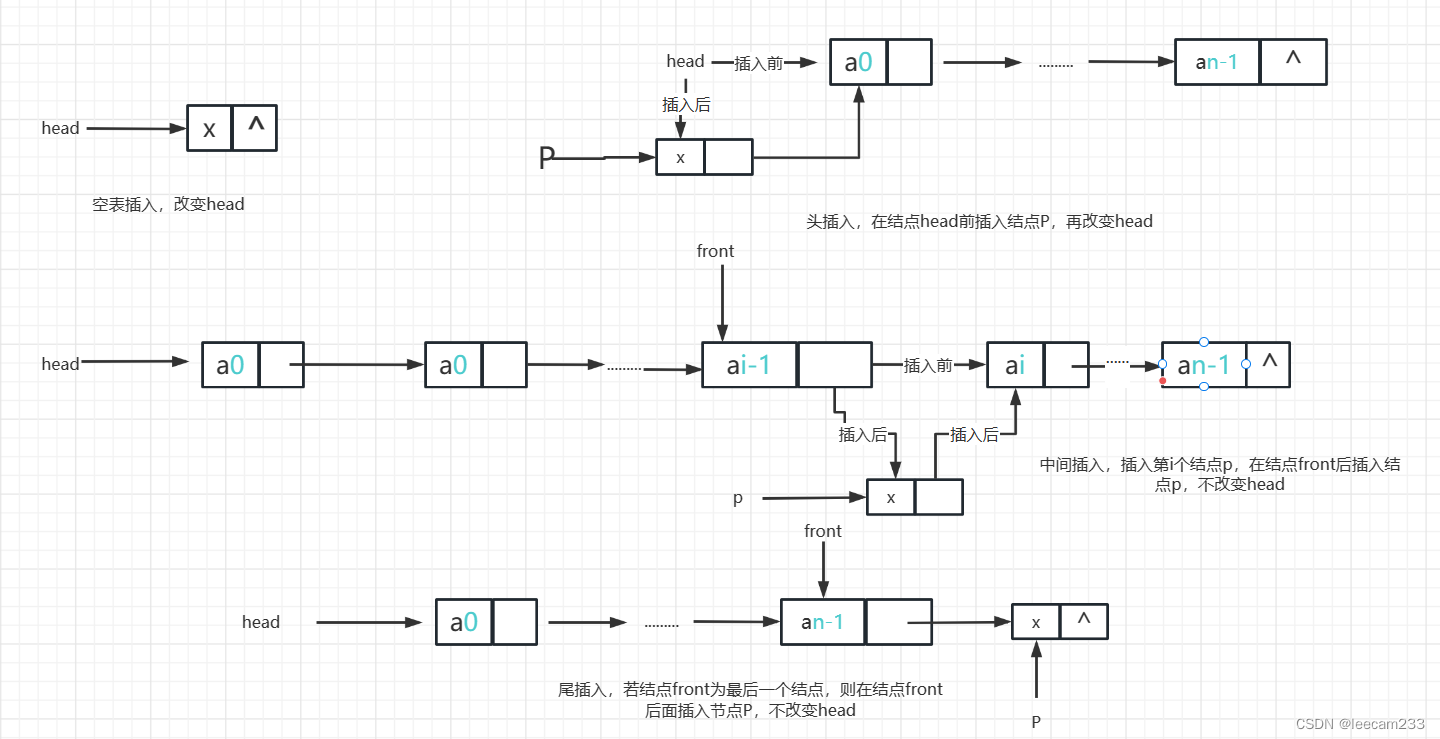
1)空表插入。若单链表为空(head=null),则插入值为x的结点语句如下:
head=new Node<T> (x,null); //使head指向创建的值为x的结点2)头插入。若单链表非空(head!=null),在head结点前插入值为x的结点语句为:
Node<T> p=new Node<T>(x,null); //p指向创建的值为x的结点
p.next=head; //建立p.next指向head的链,即插入p结点在head结点前
head=p; //使head指向p结点,则P结点成为第0个结点上述两种都会改变单链表的head,合并两段为以下一条语句:
head=new Node<T>(x,head); //创建值为x的结点,后继为head,head指向该结点3)中间插入。设front指向单链表中某个结点,在front结点后插入值为x的结点的语句为:
Node<T> p=new Node<T>(x,null); //p指向创建的值为x的结点
p.next=front.next; //p的后继结点时front的后继节点
front.next=p; //front新的后继结点为P可以合并为:
//创建值为x的结点,其后继为front的后继结点,再使该节点成为front的后继节点
front.next = new Node<T>(x,front.next);














 2918
2918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









