







转自:http://www.cnblogs.com/panweishadow/p/3454320.html
正如“深度优先搜索”这一名词所示,这种搜索算法是尽可能“深”地搜索一个图。在深度优先搜索中,对于最新发现的顶点,如果它还有以此为起点而未探测到的边,就要沿此边继续探测下去。深度优先搜索的先辈子图形成了一个由深度优先树组成的深度优先森林。
除了创建一个深度优先森林外,深度优先搜索还为每个顶点加盖时间戳。每个顶点有两个时间戳:当顶点第一次被发现(并置成灰色)时,记录下第一个时间戳d[v];当结束检查v时,记录下第二个时间戳f[v]。
顶点v在d[v]时间之前是白色(WHITE),在d[v]到f[v]时间之间是灰色(GRAY),在f[v]时间之后是黑色(BLACK).下面的伪代码就是一个基本的深度优先搜索算法,输入图G可以是有向图或无向图,变量time是一个全局变量,用于记录时间戳。
procedure DFS(G);
begin
for 每个顶点u∈V[G] do
begin
color[u]←White;
π[u]←NIL;
end;
time←0;
for 每个顶点u∈V[G] do
if color[u]=White
then DFS_Visit(G,u);
end;
procedure DFS_Visit(G,u);
begin
color[u]←Gray; Δ白色结点u已被发现
d[u]←time←time+1;
for 每个顶点v∈Adj[u] do Δ探寻边(u,v)
if color[v]=White
then begin
π[v]←u;
DFS_Visit(G,v);
end;
color[u]←Black; Δ完成后置u为黑色
f[u]←time←time+1;
end;下图说明了DFS在图G上的执行过程。
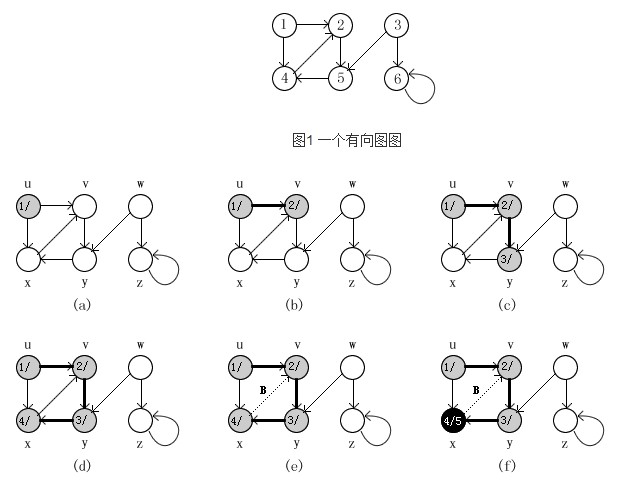
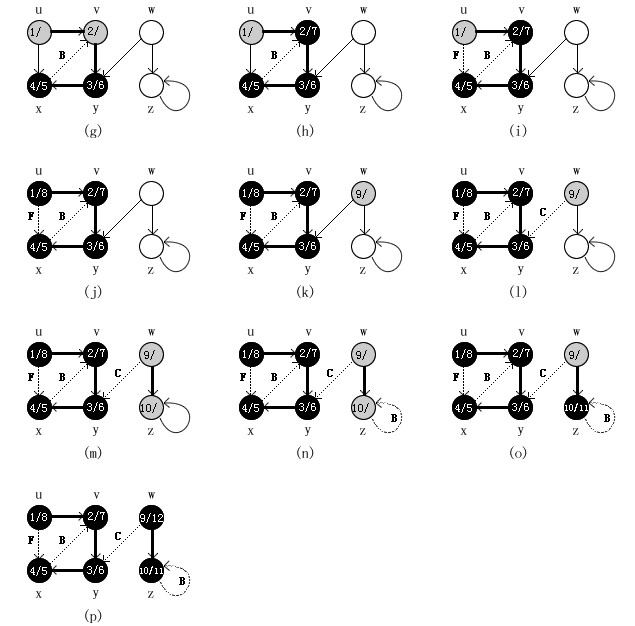
下图是具体实现的一个简单实例:














 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









