










问题:
void foo(void)
{
unsigned int a = 6;
int b = -20;
(a+b > 6) ? puts("> 6") : puts(" <= 6");
}
结果:>6
无符号整型问题的答案是输出是
">6"。原因是当表达式中存在有符号类型和无符号类型时所有的操作数都自动转换为无符号类型。因此-20变成了一个非常大的正整数,所以该表达式
计算出的结果大于6。
——————————
原因
就如同int a;一样,int 也能被其它的修饰符修饰。除void类型外,基本数据类型之前都可以加各种类型修饰符,类型修饰符有如下四种:
1.signed----有符号,可修饰char、int。Int是默认有符号的。
2.unsigned-----无符号,修饰int 、char
3.long------长型,修饰int 、double
4.short------短型,修饰int
我们主要来看一下signed和unsigned与int之间的联系与区别。
什么叫做有符号,什么叫做无符号
这个问题其实很简单,比如:5和-5,5没有符号,-5有符号。简单吧。但是在计算机中的这种符号可不简单。我们分别来看一下:
在说明有符号和无符号的区别之前,我们必须先知道溢出是怎么回事,因为有无符号的根本原因可以说就是因为数据出现了溢出现象导致的。
溢出:
我们知道数据在计算机中以二进制存储,并且占据一定的空间,而这个空间属于计算机分配的空间。
计算机给int分配32位或者16位(不同电脑可能不同)的空间,既然空间有限,那么数值就会有限制,就会存在最大值与最小值这一说,比如:假设int类型的分配16位,无符号类型的最大值为1111 1111 1111 1111(16个1),也就是65535,如果超过了65535,这就叫做溢出,那该怎么办? 如果要输出65536,那将会输出个什么东西呢? 下面和大家一起看一下:
疑问:有的读者会问:65535这么小啊,我记得自己在输出比65535大好多的数也能够输出啊。
解答: 那就是有无符号的定义和你电脑编译器的原因了。64位的电脑和32的电脑可是不一样的哦。而且int占几个字节是与电脑编译器有关的。不过现在大部分电脑int占4个字节,即32位,那么他的最大值可是32个1(二进制)左右的数量级,你实验过这么大的数吗?
1.无符号整型(unsigned int)
(1)我们都知道整型是4个字节(有些编译器不同,可能会是2个),即32位,无符号整型当然也为32位。
(2)既然是32位,无符号整型的取值是32个0~32个1,即:0~4294967295
(3) 我们举个例子:32位有点长,所以我们拿16位的unsigned short int 来举例。
short int 是16位的,无符号的范围是0~65535
就拿十进制的32767(以下的所有举例均拿这个数字来说事了)来说,它的二进制为:
0111 1111 1111 1111
对于无符号的整型32767来说,它的二进制的最高位称为数据位,即那个0就是数据位,数据位是要参与运算的,如果我们把0改成1,即16个1,它的十进制就是65535(就是2的15次方+2的14次方...一直加到2的0次方),这是不同于有符号整型的。
(4) 为了进行理解(3)中的含义,做一个程序说明:
#include<iostream>
using namespace std;
int main(int argc, char* argv[])
{
unsigned short int a = 32767, b = a + 1;//定义短型无符号
cout << "a......" << a << "--------" << "b......" << b << endl;
cout << endl;
cout<<"hello world"<<endl;
system("pause");
return 0;
}定义的时候a=32767,也就是0111 1111 1111 1111,输出的依然是32767,
a+1=32768, 二进制为1000 0000 0000 0000,输入依然为32768。
根据(3)中讲解的,无符号整型的二进制最高位为数据位,数据位为0为1都是按照正常来算的。
2.有符号整型((signed)int)
(1)int类型默认是有符号的,所以int实际上是signed int ,我们通常省略signed
(2)有符号整型也是32位。
(3)它的取值范围就与无符号整型不同了。它的范围是-2147483648~2147483647这个范围可以理解为无符号整型的一半变成了负数。
32位有点长,所以我们拿16位的short int 来举例。
short int 是16位的,有符号的范围是-32768~32767
这个时候可能就有人发问了,32768用二进制表示为1000 0000 0000 0000,那么这个负的32768的负号又怎么理解呢?看下面
(4)举个例子;
还是以32767为例子,它的二进制为:
0111 1111 1111 1111
对于有符号整型32767来说,它的二进制最高位称为符号位(而不是数据位了),符号位顾名思义就是决定正负号的,规则:0是正,1为负。
(5)列举一个程序理解(4)的内容
#include<iostream>
using namespace std;
int main(int argc, char* argv[])
{
short int m = 32767, l, o, p;
l = m+1;
o = m+2;
p = m+3;
cout<< "l......" << l << endl;
cout << "o......" << o << endl;
cout << "p......" << p << endl;
cout<<"hello world"<<endl;
system("pause");
return 0;
}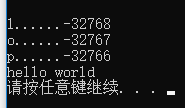
可以看出此时的结果竟然是这个样子的。为什么呢?怎么回事?
其实在计算机中,负数是并不存在的,它是以二进制补码的形式表示和存放。什么是补码呢?
(6)什么是补码,补码的运算。
我们还是列举一个简单的例子吧!就用-6.
我们经过以上的学习已经知道负数的符号位为1,所以:
(1)-6的二进制: 1000 0000 0000 0110(称为原码,原码是计算机显示给我的)
(2)对原码求反码:1111 1111 1111 1001(称为反码,保持符号位不变,将原码中的0变1,1变0)
(3)对反码加1:1111 1111 1111 1010(称为补码,补码是计算机中存储负数的形式)
在计算机中,如果存储的二进制是1111 1111 1111 1010,那么显示在我们前台的十进制数字就是-6。即:负数在计算机中是以该负数的二进制的补码形式存储的。
(7)了解了什么是补码后,再来看我们上述说的那个程序:
32767的二进制为:0111 1111 1111 1111
我们来计算一下c的值为什么会等于-32767。
c=32767+2,c的二进制为:1000 0000 0000 0001(32767的二进制+2),c的这个二进制是在计算机中存储的补码,需要将它转换为原码,也就是将c的二进制数减一再取反。得到的二进制原码为:1111 1111 1111 1111。我们已经说过,符号位为1,表示负值,并不参加运算,所以此二进制的十进制为:-32767。
但是,上述中,c的原码的确是1111 1111 1111 1111,c在计算机中存储的补码也的确是1000 0000 0000 00010。但是-32767的由来却有另一种理解,c的补码是16位,32位编译器中有32位的二进制,也就是说在16位补码的前面还有(32-16=16)位的虚位数,并不属于计算机给short int分配的空间,但是这16位的位数当数表示正时为0,当数表示负数时为1。并且前16位的数字全部都与二进制倒数第8位的数字一致。也就是说:
c 的补码是 1...1 1000 0000 0000 0010(1..1表示16个1)
我们可以这样计算:-2的7次方+2的1次方=-32767,这种理解普遍被大众所接受,而且避免了原码的概念。
(8)通过程序也可以发现一个规律,int的取值范围是-32768~32767,把头尾连接起来形成一个环就可以了。














 2231
2231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









