






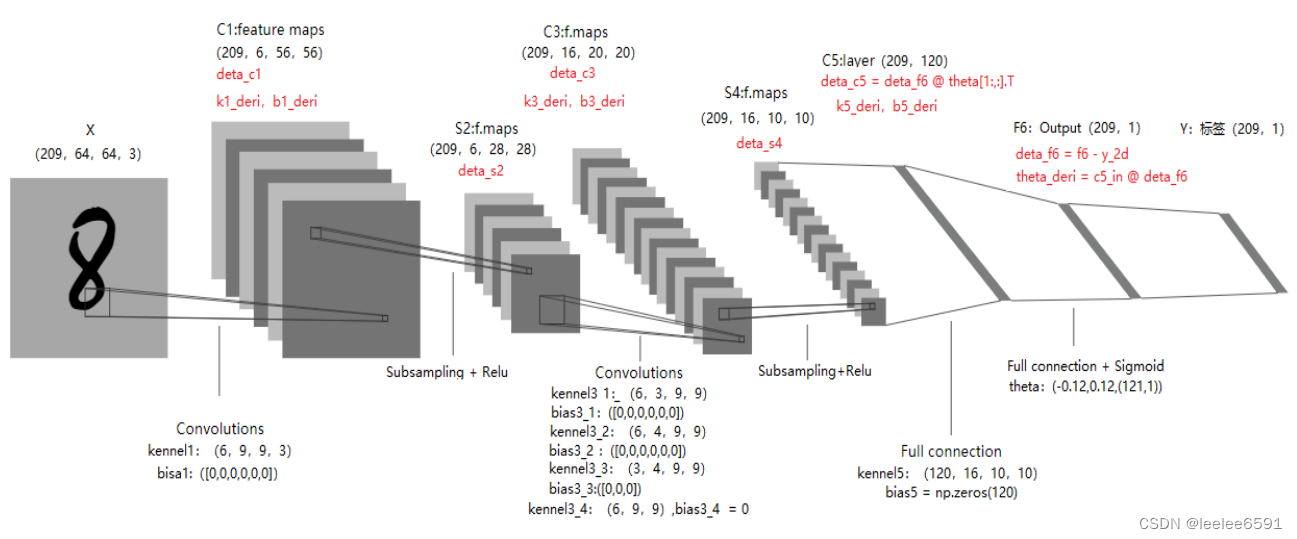
LeNet是Yann LeCun于1988年提出的用于数字识别的网络结构,是深度CNN网络的基石,理解和掌握LeNet对于学习现在主流深度学习框架有很大的帮助。本文结合吴恩达老师深度学习课程的数据集(train_catvnoncat.h5),采用python+numpy硬编码实现LeNet-5算法以识别图片中的猫。网络结构和各层参数的命名、形状如下图所示:
import numpy as np
import matplotlib.pyplot as plt
import h5py
from time import time1 查看数据及前向计算各层模型
1.1 导入并查看数据
def load_dataset():
train_data = h5py.File('datasets/train_catvnoncat.h5', "r")
train_x = np.array(train_data["train_set_x"][:]) # 209 张图片
train_y = np.array(train_data["train_set_y"][:]) # 向量
test_data = h5py.File('datasets/test_catvnoncat.h5', "r")
test_x = np.array(test_data["test_set_x"][:]) # 50 张图片
test_y = np.array(test_data["test_set_y"][:]) # 向量
return train_x, train_y, test_x, test_y
train_x, train_y, test_x, test_y = load_dataset()
print(train_x.shape, train_y.shape, test_x.shape, test_y.shape)
train_x = train_x/255 # 归一化的2维训练集图片
train_y_2d = train_y.reshape(len(train_y),-1) # y 是两维标签 (209, 1)
test_x = test_x/255 # 归一化的2维测试集图片
test_y_2d = test_y.reshape(len(test_y),-1) # y 是两维标签 (50, 1)输出:(209, 64, 64, 3) (209,) (50, 64, 64, 3) (50,)
# 随机显示8张图片
def plot_8_image(data):
indx = np.random.choice(data.shape[0],8,replace=False)
img = data[indx,:]
fig, ax_array = plt.subplots(nrows=2,ncols=4,sharex=True,sharey=True,figsize=(10,5))
for r in range(2):
for c in range(4):
ax_array[r,c].matshow(img[4*r+c])
plt.xticks([])
plt.yticks([])
plt.show()
plot_8_image(train_x)
1.2 C1卷积层前向计算
第1次卷积, 过滤器共6个,每个9 * 9 * 3,得到56*56 的特征平面图(64 - 9 + 1 = 56)
# 2维卷积函数
def corr2d(x_2d,ken,s=1):
rows, cols = ken.shape
h = int((x_2d.shape[0]-rows)/s + 1)
w = int((x_2d.shape[1]-cols)/s + 1)
Y = np.zeros((h,w))
r,c = 0,0
for i in range(h):
for j in range(w):
Y[i,j]=(x_2d[r:r+rows,c:c+cols]*ken).sum()
c=c+s
r=r+s
c=0
return Y
# 4维卷积函数
# 输入:X(x_numb,h, w, chanel), k(k_numb, h, w, chanel) ,bia,长度=k_numb;
# 输出:特征图:(x_numb, k_numb, h, w),即(样本号,特征号-对应过滤器号, h, w)
def corr4d_c1(x,ken,bia,stride=1):
x_numb,_,_,chanel = x.shape
k_numb = ken.shape[0]
c1 = [] # 存储所有样本卷积后的特征,4维数组(x_num, 6,56,56)
for m in range(x_numb):
feature = [] # 存储一个样本卷积后的特征,6个2维数组,组装成3维数组(6,56,56)
for n in range(k_numb):
y = 0
for c in range(chanel):
y_temp = corr2d(x[m,:,:,c],ken[n,:,:,c],s=stride)
y = y+y_temp
y = y+bia[n]
feature.append(y)
c1.append(feature)
return np.array(c1)1.3 S2层:池化层+rule激活层前向计算(最大池化)
# 2维池化函数
def pooling2d(Y):
h,w = int(Y.shape[0]/2),int(Y.shape[1]/2)
y = np.zeros((h,w))
for i in range(h):
for j in range(w):
y[i,j] = Y[2*i:2*i+2,2*j:2*j+2].max()
return y
# 4维池化 + relu激活
# 输入:样本数,特征平面数(每个样本的),2维平面
# 输出:样本数,特征平面数(每个样本的),池化后的2维平面
def pooling4d(c1):
x_numb, k_numb = c1.shape[0], c1.shape[1]
s2 = []
for m in range(x_numb):
pool = []
for n in range(k_numb):
pl = pooling2d(c1[m,n]) # 2维平面特征的最大池化
pl = np.where(pl>0,pl,0) # 2维平面特征的relu激活
pool.append(pl)
s2.append(pool)
return np.array(s2)1.4 C3卷积层前向计算
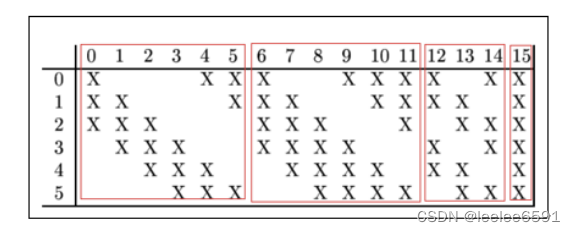
第2次卷积, 共16个过滤器,分4种:第(1)种6个,每个3 * 9 * 9 + 1;第(2)种6个,每个4 * 9 * 9 + 1;第(3)种3个,每个4 * 9 * 9 + 1;第(4)种1个,6 * 9 * 9 + 1。得到(m,16,20,20)特征平面图。
# c3 的卷积计算函数
def corr4d_c3(s2, k3_1,b3_1, k3_2,b3_2, k3_3,b3_3, k3_4,b3_4, stride=1):
s_num = s2.shape[0]
c3 = []
for m in range(s_num):
c3_m = []
# 第(1)种卷积
s21 = []
s2_0 = s2[m,[0,1,2]]
s2_1 = s2[m,[1,2,3]]
s2_2 = s2[m,[2,3,4]]
s2_3 = s2[m,[3,4,5]]
s2_4 = s2[m,[4,5,0]]
s2_5 = s2[m,[5,0,1]]
s21.append(s2_0)
s21.append(s2_1)
s21.append(s2_2)
s21.append(s2_3)
s21.append(s2_4)
s21.append(s2_5)
s21 = np.array(s21)
for i in range(6):
c3_i = 0
for j in range(3):
temp = corr2d(s21[i,j],k3_1[i,j],s=stride)
c3_i = c3_i + temp
c3_i = c3_i + b3_1[i]
c3_m.append(c3_i)
# 第(2)种卷积
s22 = []
s2_6 = s2[m,[0,1,2,3]]
s2_7 = s2[m,[1,2,3,4]]
s2_8 = s2[m,[2,3,4,5]]
s2_9 = s2[m,[3,4,5,0]]
s2_10 = s2[m,[4,5,0,1]]
s2_11 = s2[m,[5,0,1,2]]
s22.append(s2_6)
s22.append(s2_7)
s22.append(s2_8)
s22.append(s2_9)
s22.append(s2_10)
s22.append(s2_11)
s22 = np.array(s22)
for i in range(6):
c3_i = 0
for j in range(4):
temp = corr2d(s22[i,j],k3_2[i,j],s=stride)
c3_i = c3_i + temp
c3_i = c3_i + b3_2[i]
c3_m.append(c3_i)
# 第(3)种卷积
s23 = []
s2_12 = s2[m,[0,1,3,4]]
s2_13 = s2[m,[1,2,4,5]]
s2_14 = s2[m,[0,2,3,5]]
s23.append(s2_12)
s23.append(s2_13)
s23.append(s2_14)
s23 = np.array(s23)
for i in range(3):
c3_i = 0
for j in range(4):
temp = corr2d(s23[i,j],k3_3[i,j],s=stride)
c3_i = c3_i + temp
c3_i = c3_i + b3_3[i]
c3_m.append(c3_i)
# 第(4)种卷积
s2_15 = s2[m]
c3_i = 0
for j in range(6):
temp = corr2d(s2_15[j],k3_4[j],s=stride)
c3_i = c3_i + temp
c3_i = c3_i + b3_4
c3_m.append(c3_i)
c3.append(c3_m)
c3 = np.array(c3)
return c31.5 S4层:池化层+rule激活层前向计算(最大池化)
计算方法与s2相同
1.6 C5卷积层前向计算
def corr4d_c5(s4,k5,b5):
c_num = s4.shape[0]
c5 = []
for m in range(c_num):
feature = []
for i in range(120):
temp = np.sum(s4[m]*k5[i])+b5[i]
feature.append(temp)
c5.append(feature)
c5=np.array(c5)
return c51.7 F6全连接层前向计算
def hypoth_sigmoid_f6(theta,c5):
m = len(c5)
c5_in = np.c_[np.ones(m),c5]
f6 = 1/(1+np.exp(-c5_in@theta))
f6 = f6.reshape(-1,1) # 转化为二维输出,以免引起向量广播问题
return c5_in,f62 总估前向计算和代价函数
# 总体前向计算函数
def feedword_cnn(x,k1,b1,
k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,
k5,b5,
theta,
strides=1):
m = len(x)
c1 = corr4d_c1(x,k1,b1,stride=strides)
s2 = pooling4d(c1)
c3 = corr4d_c3(s2,k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,stride=strides)
s4 = pooling4d(c3)
c5 = corr4d_c5(s4,k5,b5)
c5_in,f6 = hypoth_sigmoid_f6(theta,c5)
return c1,s2,c3,s4,c5,c5_in,f6
# 代价函数
def costfun_cnn(f6,y_2d):
m = len(f6)
J = (-1/m) * np.sum(y_2d*np.log(f6) + (1-y_2d)*np.log(1-f6))
return J3 梯度函数
3.1 c3之后各层的误差和梯度函数
# deta_f6 = f6 - y_2d (209,1)
# theta_deri = (1/m)*(c5_in.T @ deta_f6) (121,209)@ (209,1) = (121,1)
# deta_c5 = deta_f6 @ theta[1:,:].T (209,1)@ (1,120) = (209,120)
# k5_deri 的计算函数
def comput_k5deri(s4,deta_c5):
m=len(s4)
k_numb = deta_c5.shape[1]
k5_deri = []
for n in range(k_numb):
k5_sect = 0
for i in range(m):
temp = s4[i]*deta_c5[i,n]
k5_sect = k5_sect + temp
k5_sect = (1/m)*k5_sect
k5_deri.append(k5_sect)
k5_deri = np.array(k5_deri)
return k5_deri
# deta_s4 的计算函数
def comput_detas4(k5,deta_c5): # k5 (120,16,10,10); deta_c5(209, 120)
m = deta_c5.shape[0]
n = deta_c5.shape[1]
deta_s4 = []
for i in range(m):
deta = 0
for j in range(n):
temp = k5[j]*deta_c5[i,j]
deta = deta + temp
deta_s4.append(deta)
deta_s4 = np.array(deta_s4)
deta_s4 = np.where(deta_s4>0,deta_s4,0) # 相关当于乘以 rule函数的导数
return deta_s4
# deta_c3,deta_c1 池化源的梯度计算函数
def comput_detapooling(cx,deta_sx):
deta_cx = cx.copy()
m_num,n_num,dim = deta_cx.shape[0],deta_cx.shape[1],deta_cx.shape[2]
for m in range(m_num):
for n in range(0,n_num):
for i in range(0,dim,2):
for j in range(0,dim,2):
idx = np.argmax(deta_cx[m,n,i:i+2,j:j+2])
if idx == 0:
p,q = 0,0
elif idx == 1:
p,q = 0,1
elif idx == 2:
p,q = 1,0
else:
p,q = 1,1
deta_cx[m,n,i:i+2,j:j+2] = 0
deta_cx[m,n,i+p,j+q] = deta_sx[m,n,int(i/2),int(j/2)]
return deta_cx3.2 S2的误差及K3的梯度
# 误差周边扩展 pads 个零
def deta_padding(deta_cx, pads):
m_num, k_num = deta_cx.shape[0],deta_cx.shape[1]
deta_cx_padded = []
for i in range(m_num):
padded = []
for j in range(k_num):
temp = np.pad(deta_cx[i,j],((pads,pads),(pads,pads)),'constant', constant_values=(0,0))
padded.append(temp)
deta_cx_padded.append(padded)
deta_cx_padded = np.array(deta_cx_padded)
return deta_cx_padded
# deta_c3_padded = deta_padding(deta_c3,8)
# print(deta_c3_padded.shape)
# 4维的ken旋转180度
def dim4_rotting(ken):
ken_rotted = []
dim1,dim2 = ken.shape[0],ken.shape[1]
for i in range(dim1):
rotted = []
for j in range(dim2):
temp = np.rot90(ken[i,j],2)
rotted.append(temp)
ken_rotted.append(rotted)
ken_rotted = np.array(ken_rotted)
return ken_rotted# deta_s2 的计算
def comput_detas2_dim4(deta_c3_padded, k3_1_rotted, k3_2_rotted, k3_3_rotted, k3_4_rotted):
m_numb = deta_c3_padded.shape[0]
deta_s2 = []
for m in range(m_numb):
deta_s2_m = []
# 第(1)种卷积核的反向误差计算 ,(6, 3, 28, 28)
deta_s21 = []
for i in range(6):
deta_s21_i = []
for j in range(3):
temp = corr2d(deta_c3_padded[m,i], k3_1_rotted[i,j])
deta_s21_i.append(temp)
deta_s21.append(deta_s21_i)
deta_s21 = np.array(deta_s21)
# 第(2)种卷积核的反向误差计算 , (6, 4, 28, 28)
deta_s22 = []
for i in range(6):
deta_s22_i = []
for j in range(4):
temp = corr2d(deta_c3_padded[m,i+6],k3_2_rotted[i,j])
deta_s22_i.append(temp)
deta_s22.append(deta_s22_i)
deta_s22 = np.array(deta_s22)
# 第(3)种卷积核的反向误差计算 , (3, 4, 28, 28)
deta_s23 = []
for i in range(3):
deta_s23_i = []
for j in range(4):
temp = corr2d(deta_c3_padded[m,i+12],k3_3_rotted[i,j])
deta_s23_i.append(temp)
deta_s23.append(deta_s23_i)
deta_s23 = np.array(deta_s23)
# 第(4)种卷积核的反向误差计算 , (6, 28, 28)
deta_s24 = []
for i in range(6):
temp = corr2d(deta_c3_padded[m,15],k3_4_rotted[i])
deta_s24.append(temp)
deta_s24 = np.array(deta_s24)
# 计算deta_s2
deta_s2_m0 = (deta_s21[0,0] + deta_s21[4,2] + deta_s21[5,1] +
deta_s22[0,0] + deta_s22[3,3] + deta_s22[4,2] + deta_s22[5,1] +
deta_s23[0,0] + deta_s23[2,0] +
deta_s24[0])
deta_s2_m.append(deta_s2_m0)
deta_s2_m1 = (deta_s21[0,1] + deta_s21[1,0] + deta_s21[5,2] +
deta_s22[0,1] + deta_s22[1,0] + deta_s22[4,3] + deta_s22[5,2] +
deta_s23[0,1] + deta_s23[1,0] +
deta_s24[1])
deta_s2_m.append(deta_s2_m1)
deta_s2_m2 = (deta_s21[0,2] + deta_s21[1,1] + deta_s21[2,0] +
deta_s22[0,2] + deta_s22[1,1] + deta_s22[2,0] + deta_s22[5,3] +
deta_s23[1,1] + deta_s23[2,1] +
deta_s24[2])
deta_s2_m.append(deta_s2_m2)
deta_s2_m3 = (deta_s21[1,2] + deta_s21[2,1] + deta_s21[3,0] +
deta_s22[0,3] + deta_s22[1,2] + deta_s22[2,1] + deta_s22[3,0] +
deta_s23[0,2] + deta_s23[2,2] +
deta_s24[3])
deta_s2_m.append(deta_s2_m3)
deta_s2_m4 = (deta_s21[2,2] + deta_s21[3,1] + deta_s21[4,0] +
deta_s22[1,3] + deta_s22[2,2] + deta_s22[3,1] + deta_s22[4,0] +
deta_s23[0,3] + deta_s23[1,2] +
deta_s24[4])
deta_s2_m.append(deta_s2_m4)
deta_s2_m5 = (deta_s21[3,2] + deta_s21[4,1] + deta_s21[5,0] +
deta_s22[2,3] + deta_s22[3,2] + deta_s22[4,1] + deta_s22[5,0] +
deta_s23[1,3] + deta_s23[2,3] +
deta_s24[5])
deta_s2_m.append(deta_s2_m5)
deta_s2.append(deta_s2_m)
deta_s2 = np.array(deta_s2)
return deta_s2# K3_deri 的计算
# 将deta_c3(209, 16, 20, 20)作为核,与s2对应的四种源进行卷积;(1/m)* k3_deri
def compute_K3deri(s2,deta_c3):
k31_deri_sum,k32_deri_sum,k33_deri_sum,k34_deri_sum = 0,0,0,0
b31_deri_sum,b32_deri_sum,b33_deri_sum,b34_deri_sum = 0,0,0,0
m_num = s2.shape[0]
for m in range(m_num):
# 第(1)种 k31_deri (6,3,9,9)
k31_deri = []
b31_deri = []
s21 = []
s2_0 = s2[m,[0,1,2]]
s2_1 = s2[m,[1,2,3]]
s2_2 = s2[m,[2,3,4]]
s2_3 = s2[m,[3,4,5]]
s2_4 = s2[m,[4,5,0]]
s2_5 = s2[m,[5,0,1]]
s21.append(s2_0)
s21.append(s2_1)
s21.append(s2_2)
s21.append(s2_3)
s21.append(s2_4)
s21.append(s2_5)
s21 = np.array(s21) # (6,3,28,28)
for i in range(6): # 计算 k31_deri_sum
k31_deri_i = []
for j in range(3):
tempk = corr2d(s21[i,j],deta_c3[m,i])
k31_deri_i.append(tempk)
k31_deri.append(k31_deri_i)
k31_deri = np.array(k31_deri)
k31_deri_sum = k31_deri_sum + k31_deri
for i in range(6): # 计算 b31_deri_sum
tempb = np.sum(deta_c3[m,i])
b31_deri.append(tempb)
b31_deri = np.array(b31_deri)
b31_deri_sum = b31_deri_sum + b31_deri
# 第(2)种 k32_deri (6,4,9,9)
k32_deri = []
b32_deri = []
s22 = []
s2_6 = s2[m,[0,1,2,3]]
s2_7 = s2[m,[1,2,3,4]]
s2_8 = s2[m,[2,3,4,5]]
s2_9 = s2[m,[3,4,5,0]]
s2_10 = s2[m,[4,5,0,1]]
s2_11 = s2[m,[5,0,1,2]]
s22.append(s2_6)
s22.append(s2_7)
s22.append(s2_8)
s22.append(s2_9)
s22.append(s2_10)
s22.append(s2_11)
s22 = np.array(s22) # (6,4,28,28)
for i in range(6): # 计算 k32_deri_sum
k32_deri_i = []
for j in range(4):
tempk = corr2d(s22[i,j],deta_c3[m,i+6])
k32_deri_i.append(tempk)
k32_deri.append(k32_deri_i)
k32_deri = np.array(k32_deri)
k32_deri_sum = k32_deri_sum + k32_deri
for i in range(6): # 计算 b32_deri_sum
tempb = np.sum(deta_c3[m,i+6])
b32_deri.append(tempb)
b32_deri = np.array(b32_deri)
b32_deri_sum = b32_deri_sum + b32_deri
# 第(3)种卷积 k33_deri (3,4,9,9)
k33_deri = []
b33_deri = []
s23 = []
s2_12 = s2[m,[0,1,3,4]]
s2_13 = s2[m,[1,2,4,5]]
s2_14 = s2[m,[0,2,3,5]]
s23.append(s2_12)
s23.append(s2_13)
s23.append(s2_14)
s23 = np.array(s23) # (3,4,28,28)
for i in range(3): # 计算 k33_deri_sum
k33_deri_i = []
for j in range(4):
tempk = corr2d(s23[i,j],deta_c3[m,i+12])
k33_deri_i.append(tempk)
k33_deri.append(k33_deri_i)
k33_deri = np.array(k33_deri)
k33_deri_sum = k33_deri_sum + k33_deri
for i in range(3): # 计算 b33_deri_sum
tempb = np.sum(deta_c3[m,i+12])
b33_deri.append(tempb)
b33_deri = np.array(b33_deri)
b33_deri_sum = b33_deri_sum + b33_deri
# 第(4)种卷积
k34_deri = []
s24 = s2[m] # (6,28,28)
for i in range(6): # 计算 k34_deri_sum
tempk = corr2d(s24[i],deta_c3[m,15])
k34_deri.append(tempk)
k34_deri = np.array(k34_deri)
k34_deri_sum = k34_deri_sum + k34_deri
b34_deri = np.sum(deta_c3[m,15])
b34_deri_sum = b34_deri_sum + b34_deri
return ( (1/m_num)*k31_deri_sum, (1/m_num)*k32_deri_sum, (1/m_num)*k33_deri_sum, (1/m_num)*k34_deri_sum,
(1/m_num)*b31_deri_sum, (1/m_num)*b32_deri_sum, (1/m_num)*b33_deri_sum, (1/m_num)*b34_deri_sum )3.3 k1_deri、b1_deri的计算函数
def comput_k1deri(x,deta_c1):
m_numb = len(x)
k1_deri_sum = 0
b1_deri_sum = 0
for m in range(m_numb):
tempk = np.zeros((6,9,9,3)) # 以numpy数组形式,更为简洁
for i in range(6):
for j in range(3):
tempk[i,:,:,j] = corr2d(x[m,:,:,j],deta_c1[m,i])
k1_deri_sum = k1_deri_sum + tempk
tempb = np.zeros(6)
for i in range(6):
tempb[i] = np.sum(deta_c1[m,i])
b1_deri_sum = b1_deri_sum + tempb
return (1/m_numb)*k1_deri_sum, (1/m_numb)*b1_deri_sum3.4 总梯度函数
# 总体梯度函数 **************暂时未使用********************
def gradient_cnn(x,y_2d,k1,b1,
k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,
k5,b5,
theta,
strideses=1):
m = len(x) # 209
c1,s2,c3,s4,c5,c5_in,f6 = feedword_cnn(x,k1,b1,
k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,
k5,b5,
theta,
strides=strideses)
deta_f6 = f6 - y_2d # f6 的误差, (209,1)
theta_deri = (1/m)*(c5_in.T @ deta_f6) # theta 的导数,(121,209)@ (209,1) = (121,1)
deta_c5 = deta_f6 @ theta[1:,:].T # c5 的误差,(209,1)@ (1,120) = (209,120)
k5_deri = comput_k5deri(s4,deta_c5) # k5 的导数,(120,16,10,10)
b5_deri = np.mean(deta_c5,axis=0) # b5 的导数,(120,)
deta_s4 = comput_detas4(k5,deta_c5) # s4 的导数 (209,16,10,10)
deta_c3 = comput_detapooling(c3,deta_s4) # c3 的导数 (209,16,20,20)
deta_c3_padded = deta_padding(deta_c3,8) # c3 扩展为 (209,16,36,36)
k3_1_rotted = dim4_rotting(k3_1)
k3_2_rotted = dim4_rotting(k3_2)
k3_3_rotted = dim4_rotting(k3_3)
# k3_4 的旋转
k3_4_rotted = []
for i in range(6):
temp = np.rot90(k3_4[i],2)
k3_4_rotted.append(temp)
k3_4_rotted = np.array(k3_4_rotted)
# s2 的导数(209,6,28,28);k31(6,3,9,9), k32(6,4,9,9), k33(3,4,9,9), k34(6,9,9)
deta_s2 = comput_detas2_dim4(deta_c3_padded, k3_1_rotted, k3_2_rotted, k3_3_rotted, k3_4_rotted)
k31_deri,k32_deri,k33_deri,k34_deri,b31_deri,b32_deri,b33_deri,b34_deri = compute_K3deri(s2,deta_c3)
deta_c1 = comput_detapooling(c1,deta_s2) # c1 的导数 (209,6,56,56)
k1_deri, b1_deri = comput_k1deri(train_x,deta_c1) # k1 的导数 (6,9,9,3)
return (k1_deri,b1_deri,
k31_deri,b31_deri, k32_deri,b32_deri, k33_deri,b33_deri,k34_deri,b34_deri,
k5_deri,b5_deri,
theta_deri)4 训练
# 自定义梯度下降函数
def gradientDescent_cnn(x,y_2d,
k1,b1,k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,k5,b5,theta,
sts=1,alpa=0.003,iters=1000):
m_numb = len(x)
costs = []
for i in range(iters):
c1,s2,c3,s4,c5,c5_in,f6 = feedword_cnn(x,k1,b1,k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,k5,b5,theta,strides=sts)
cost = costfun_cnn(f6,y_2d)
costs.append(cost)
deta_f6 = f6 - y_2d # f6 的误差, (209,1)
theta_deri = (1/m_numb)*(c5_in.T @ deta_f6) # theta 的导数,(121,209)@ (209,1) = (121,1)
deta_c5 = deta_f6 @ theta[1:,:].T # c5 的误差,(209,1)@ (1,120) = (209,120)
k5_deri = comput_k5deri(s4,deta_c5) # k5 的导数,(120,16,10,10)
b5_deri = np.mean(deta_c5,axis=0) # b5 的导数,(120,)
deta_s4 = comput_detas4(k5,deta_c5) # s4 的导数 (209,16,10,10)
deta_c3 = comput_detapooling(c3,deta_s4) # c3 的导数 (209,16,20,20)
deta_c3_padded = deta_padding(deta_c3,8) # c3 扩展为 (209,16,36,36)
k3_1_rotted = dim4_rotting(k3_1)
k3_2_rotted = dim4_rotting(k3_2)
k3_3_rotted = dim4_rotting(k3_3)
# k3_4 的旋转
k3_4_rotted = []
for i in range(6):
temp = np.rot90(k3_4[i],2)
k3_4_rotted.append(temp)
k3_4_rotted = np.array(k3_4_rotted)
# s2 的导数(209,6,28,28);k31(6,3,9,9), k32(6,4,9,9), k33(3,4,9,9), k34(6,9,9)
deta_s2 = comput_detas2_dim4(deta_c3_padded, k3_1_rotted, k3_2_rotted, k3_3_rotted, k3_4_rotted)
k31_deri,k32_deri,k33_deri,k34_deri,b31_deri,b32_deri,b33_deri,b34_deri = compute_K3deri(s2,deta_c3)
deta_c1 = comput_detapooling(c1,deta_s2) # c1 的导数 (209,6,56,56)
k1_deri, b1_deri = comput_k1deri(train_x,deta_c1) # k1 的导数 (6,9,9,3)
k1 = k1 - alpa*k1_deri
b1 = b1 - alpa*b1_deri
k3_1 = k3_1 - alpa*k31_deri
b3_1 = b3_1 - alpa*b31_deri
k3_2 = k3_2 - alpa*k32_deri
b3_2 = b3_2 - alpa*b32_deri
k3_3 = k3_3 - alpa*k33_deri
b3_3 = b3_3 - alpa*b33_deri
k3_4 = k3_4 - alpa*k34_deri
b3_4 = b3_4 - alpa*b34_deri
k5 = k5 - alpa*k5_deri
b5 = b5 - alpa*b5_deri
theta = theta - alpa*theta_deri
return costs,k1,b1,k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,k5,b5,theta# 初始化参数
k1 = np.random.uniform(-0.12,0.12,(6,9,9,3))
b1 = np.array([0,0,0,0,0,0])
k3_1 = np.random.uniform(-0.12,0.12,(6,3,9,9))
b3_1 = np.array([0,0,0,0,0,0])
k3_2 = np.random.uniform(-0.12,0.12,(6,4,9,9))
b3_2 = np.array([0,0,0,0,0,0])
k3_3 = np.random.uniform(-0.12,0.12,(3,4,9,9))
b3_3 = np.array([0,0,0])
k3_4 = np.random.uniform(-0.12,0.12,(6,9,9))
b3_4 = 0
k5 = np.random.uniform(-0.12,0.12,(120,16,10,10))
b5 = np.zeros(120)
theta = np.random.uniform(-0.12,0.12,(121,1))
# 训练
costs,k1,b1,k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,k5,b5,theta = gradientDescent_cnn(train_x,train_y_2d,
k1,b1,k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,k5,b5,theta,
sts=1,alpa=0.03,iters=500)硬件配置:笔记本Intel(R) Core(TM) i7-10875H CPU @ 2.30GHz,内存16.0 GB。python环境:python3.8+numpy1.21.5。训练耗时10多个小时,要有心理准备。
# 图示梯度下降和精度
c1,s2,c3,s4,c5,c5_in,f6 = feedword_cnn(train_x,k1,b1,k3_1,b3_1,k3_2,b3_2,k3_3,b3_3,k3_4,b3_4,k5,b5,theta)
pre_out_train = np.array([1 if i>=0.5 else 0 for i in f6])
train_acc = np.mean(pre_out_train==train_y)
train_acc = round(train_acc,3)
iters = np.arange(0,500)
plt.figure(figsize=(8,6),dpi=80)
plt.plot(iters,costs)
plt.title('学习率:{}, 迭代次数:{}, 精度:{}'.format(0.03,500,train_acc))
plt.show()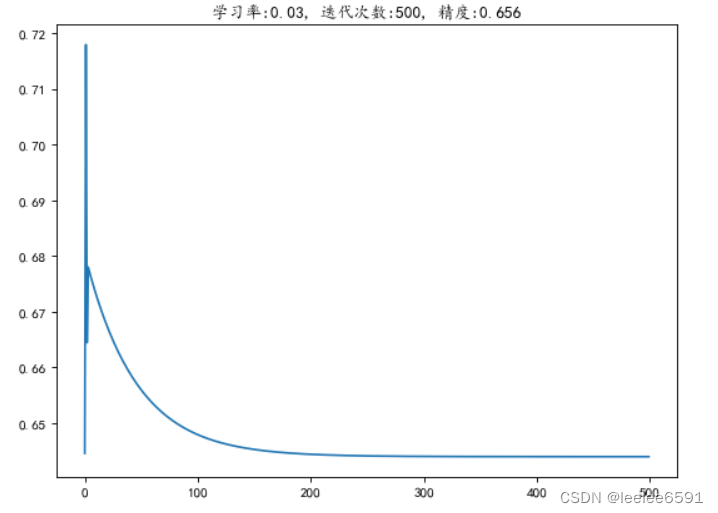
结论:学习率设为0.03,迭代次数500,得到训练精度并不理想,可调整相关参数重新训练。
















 1651
1651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











