







与SAX和PULL解析不同,Dom解析是将XML文件全部载入,组装成一颗Dom树,然后通过节点以及节点之间的关系来解析XML文件,占用内存比较大,一般比较推荐用SAX和PULL来解析。和前面一样用同样的例子来分析一下。
首先自定义一个XML文件:Student.xml,注意是新建file而不是xml。
<?xml version="1.0" encoding="utf-8"?>
<students>
<student id="1">
<name>张三</name>
<sex>男</sex>
<age>18</age>
</student>
<student id="2">
<name>李四</name>
<sex>女</sex>
<age>19</age>
</student>
<student id="3">
<name>王五</name>
<sex>男</sex>
<age>20</age>
</student>
</students>
package com.example.xml_sax_demo_1;
public class Student {
private int id;
private String name;
private int age;
private String sex;
public Student() {
// TODO Auto-generated constructor stub
}
public int getId() {
return id;
}
public Student(int id, String name, int age) {
super();
this.id = id;
this.name = name;
this.age = age;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ",sex=" + sex
+ ", age=" + age + "]";
}
}
package com.example.xml_sax_demo_1;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document; //注意使用的包都是org.w3c.dom.*的
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import android.os.Bundle;
import android.support.v7.app.ActionBarActivity;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
public class MainActivity extends ActionBarActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Button button = (Button) findViewById(R.id.button);
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View arg0) {
// TODO Auto-generated method stub
try {
readXML();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
});
}
private void readXML() throws Exception {
List<Student> list = new ArrayList<Student>();
InputStream stream = this.getClass().getClassLoader()
.getResourceAsStream("Student.xml"); // 获得输入流
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //一步步下去
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(stream);
Element element = document.getDocumentElement(); //实例化元素
NodeList nodeList = element.getElementsByTagName("student"); //获得节点名为student的节点列表
for (int i = 0; i < nodeList.getLength(); i++) {
Element studentElement = (Element) nodeList.item(i); //对应上面取得的列表
Student student = new Student(); //每个节点实例化一个student元素
student.setId(Integer.parseInt(studentElement.getAttribute("id"))); //取得属性
NodeList childNodeList = studentElement.getChildNodes(); //取得子节点列表
for (int j = 0; j < childNodeList.getLength(); j++) {
// if (childNodeList.item(j).getNodeType() == Node.ELEMENT_NODE)
// {
if (childNodeList.item(j).getNodeName().equals("name")) { //如果子节点名为name
student.setName(childNodeList.item(j).getFirstChild() //将文本数据存储起来
.getNodeValue());
} else if (childNodeList.item(j).getNodeName().equals("sex")) {
student.setSex(childNodeList.item(j).getFirstChild()
.getNodeValue());
} else if (childNodeList.item(j).getNodeName().equals("age")) {
student.setAge(Integer.parseInt(childNodeList.item(j)
.getFirstChild().getNodeValue()));
}
// }
}
list.add(student); //在列表中添加一个student对象
}
for (Student stu : list) {
System.out.println(stu.toString());
}
}
}
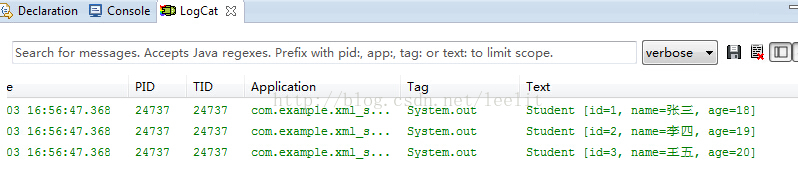
小结:从代码可以看出,Dom解析是将XML文件全部载入,组装成一颗Dom树,然后通过节点以及节点之间的关系来解析XML文件的,一般是不断的循环遍历,占用内存比较大。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









