






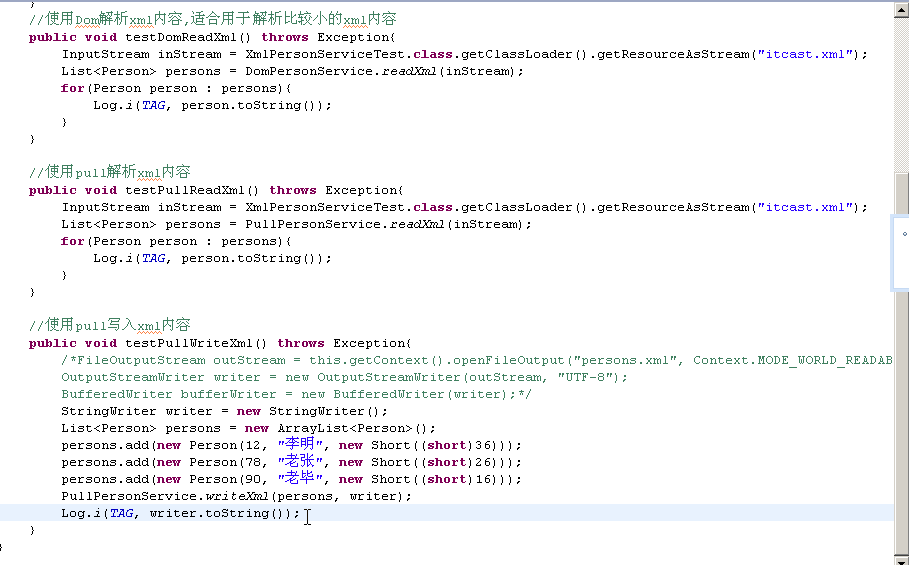
除了可以使用 SAX解析XML文件,大家也可以使用熟悉的DOM来解析XML文件。 DOM解析XML文件时,会将XML文件的所有内容读取到内存中,然后允许您使用DOM API遍历XML树、检索所需的数据。使用DOM操作XML的代码看起来比较直观,并且,在某些方面比基于SAX的实现更加简单。但是,因为DOM需要将XML文件的所有内容读取到内存中,所以内存的消耗比较大,特别对于运行Android的移动设备来说,因为设备的资源比较宝贵,所以建议还是采用SAX来解析XML文件,当然,如果XML文件的内容比较小采用DOM是可行的。
1 使用SAX读取XML文件
SAX是一个解析速度快并且占用内存少的xml解析器,非常适合用于Android等移动设备。 SAX解析XML文件采用的是事件驱动,也就是说,它并不需要解析完整个文档,在按内容顺序解析文档的过程中,SAX会判断当前读到的字符是否合法XML语法中的某部分,如果符合就会触发事件。所谓事件,其实就是一些回调(callback)方法,这些方法(事件)定义在ContentHandler接口。下面是一些ContentHandler接口常用的方法:
startDocument()
当遇到文档的开头的时候,调用这个方法,可以在其中做一些预处理的工作。
endDocument()
和上面的方法相对应,当文档结束的时候,调用这个方法,可以在其中做一些善后的工作。
startElement(String namespaceURI, String localName, String qName, Attributes atts)
当读到一个开始标签的时候,会触发这个方法。namespaceURI就是命名空间,localName是不带命名空间前缀的标签名,qName是带命名空间前缀的标签名。通过atts可以得到所有的属性名和相应的值。要注意的是SAX中一个重要的特点就是它的流式处理,当遇到一个标签的时候,它并不会纪录下以前所碰到的标签,也就是说,在startElement()方法中,所有你所知道的信息,就是标签的名字和属性,至于标签的嵌套结构,上层标签的名字,是否有子元属等等其它与结构相关的信息,都是不得而知的,都需要你的程序来完成。这使得SAX在编程处理上没有DOM来得那么方便。
endElement(String uri, String localName, String name)
这个方法和上面的方法相对应,在遇到结束标签的时候,调用这个方法。
characters(char[] ch, int start, int length)
这个方法用来处理在XML文件中读到的内容,第一个参数用于存放文件的内容,后面两个参数是读到的字符串在这个数组中的起始位置和长度,使用new String(ch,start,length)就可以获取内容。
只要为SAX提供实现ContentHandler接口的类,那么该类就可以得到通知事件(实际上就是SAX调用了该类中的回调方法)。因为ContentHandler是一个接口,在使用的时候可能会有些不方便,因此,SAX还为其制定了一个Helper类:DefaultHandler,它实现了这个接口,但是其所有的方法体都为空,在实现的时候,你只需要继承这个类,然后重载相应的方法即可。使用SAX解析itcast.xml的代码如下
inStream 可以使用inStream = this.getClassLoader().getResourceAsStream(文件名),或用字符串new InputSource(new StringReader(字符串))
SAX 支持已内置到JDK1.5中,你无需添加任何的jar文件。关于XMLContentHandler的代码实现请看本页下面备注。
2. 采用dom解析xml文件
3. 采用pull解析xml
除了可以使用 SAX和DOM解析XML文件,大家也可以使用Android内置的Pull解析器解析XML文件。 Pull解析器的运行方式与 SAX 解析器相似。它提供了类似的事件,如:开始元素和结束元素事件,使用parser.next()可以进入下一个元素并触发相应事件。事件将作为数值代码被发送,因此可以使用一个switch对感兴趣的事件进行处理。当元素开始解析时,调用parser.nextText()方法可以获取下一个Text类型元素的值。
调用地方
或者
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









