







问题
在开发DPDK应用的时候,我们可以通过rte_eth_stats_get函数获取网卡统计信息中的imissed计数来判断网卡是否出现丢包。


注:对于ixgbe 驱动,则DPDK中 rte_eth_stats_get 调用的是 ixgbe_dev_stats_get;
基础
imiss 的定义
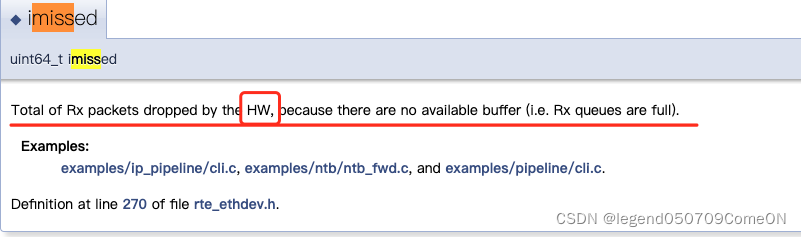
Q: imiss 是 网卡的接收队列满吗?还是 ring_buffer 满?
A: 根据上面的定义,是被硬件丢弃,应该是网卡的接收队列满。不应该是 ring_buffer 满,ring_buffer 是内核使用的,应该是一个软件的概念。

Q: imiss 统计是否可以基于队列?
A: imiss统计,是全局的。
ixgbe_dev_stats_get 中的实现如下。
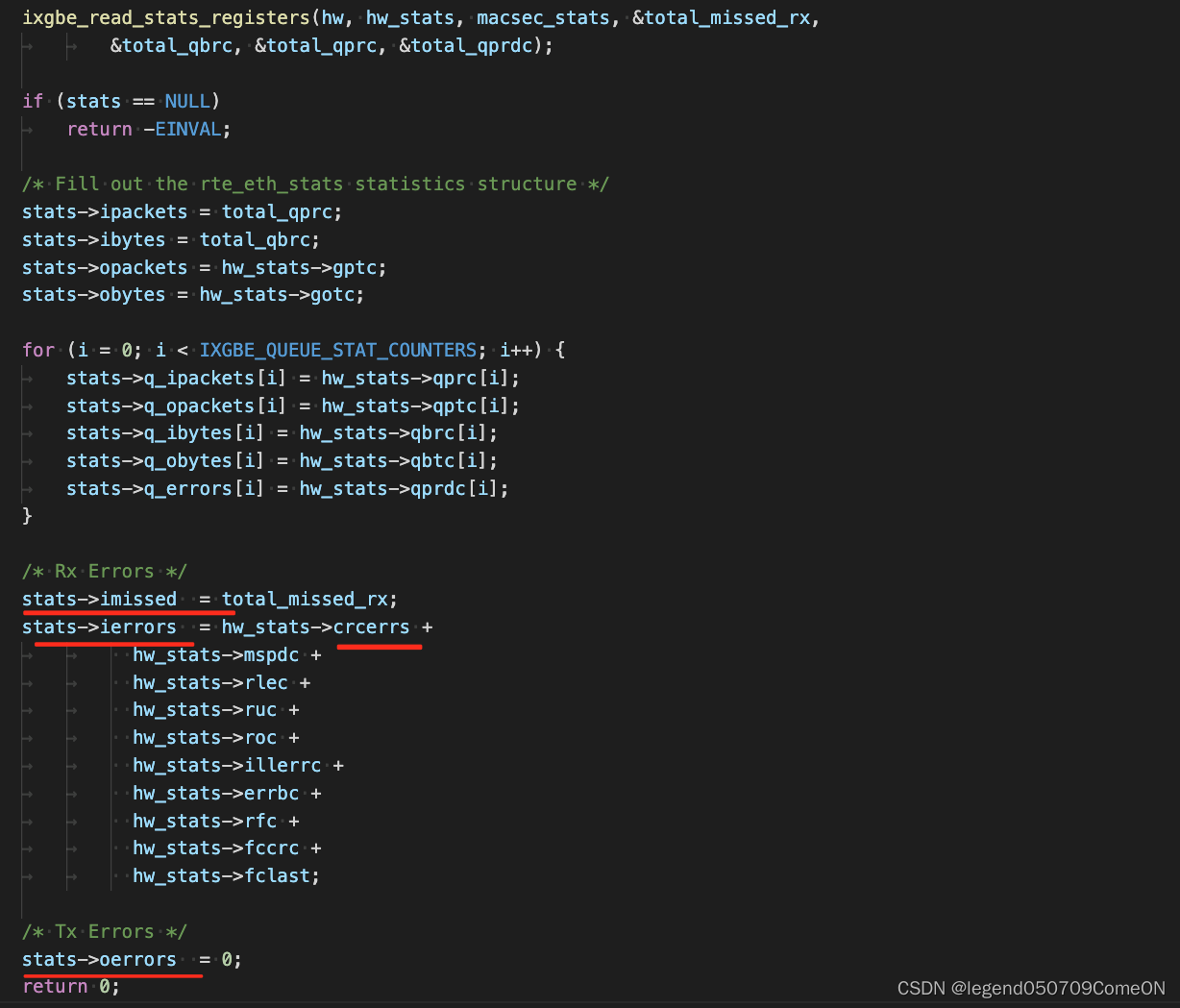
如上:ixgbe 驱动的网卡的 oerror 一直是0。
其他统计
rx-errors/ierrors

ierrors: 表示该数据包存在错误,被网卡丢弃。此时该包不会存在于物理网卡的RX FIFO中,更不会存在于内存中的rte_rx_queue(ring buffer)中。
比如:packets with incorrect checksum, runts, giants etc.
rx-nombuf
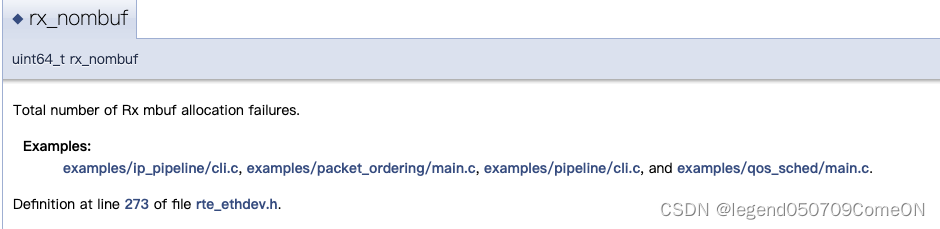
rx_nombuf记录在读取数据包时分配mbuf错误的次数,一般情况下不会影响网卡的丢包(imissed、ierrors)。
比如:RX packet was drop due to lack of free mbufs in the mempool.
- 解决
直接增大mempool的大小。
rx_discards_phy
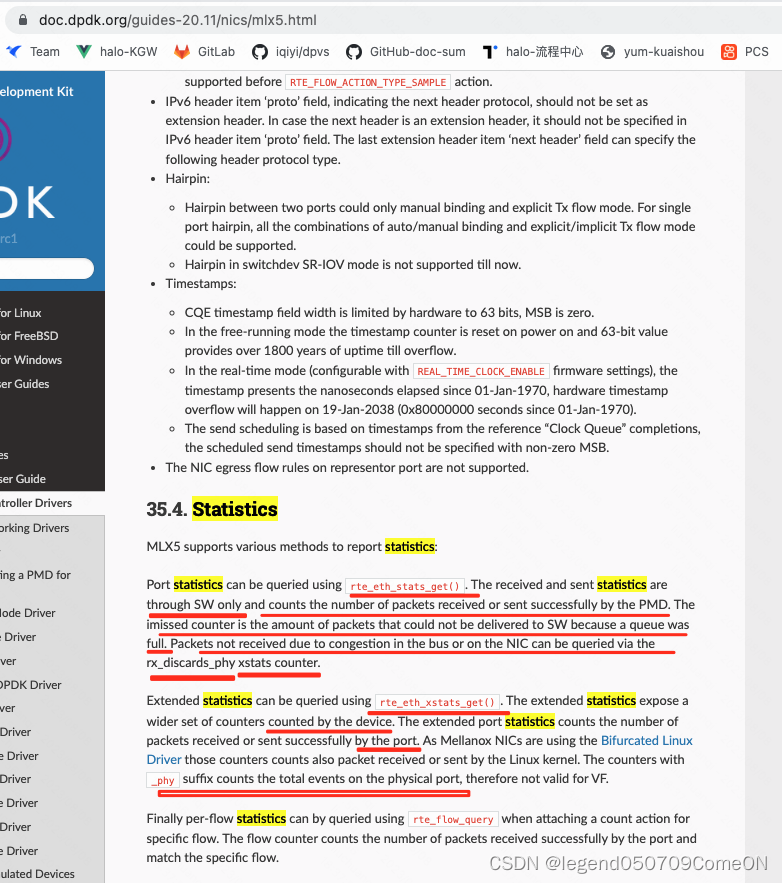
SW: software
按照上面的理解:
rte_eth_stats_get 指的是软件的技术,那么imiss就是ring buffer满的统计;
rte_eth_xstats_get 展示了物理端口的一些统计计数(通过寄存器),rx_discards_phy 的统计应该是网卡的硬件缓存满或者PCIe 总线阻塞导致无法把包发送给内核的内存中。
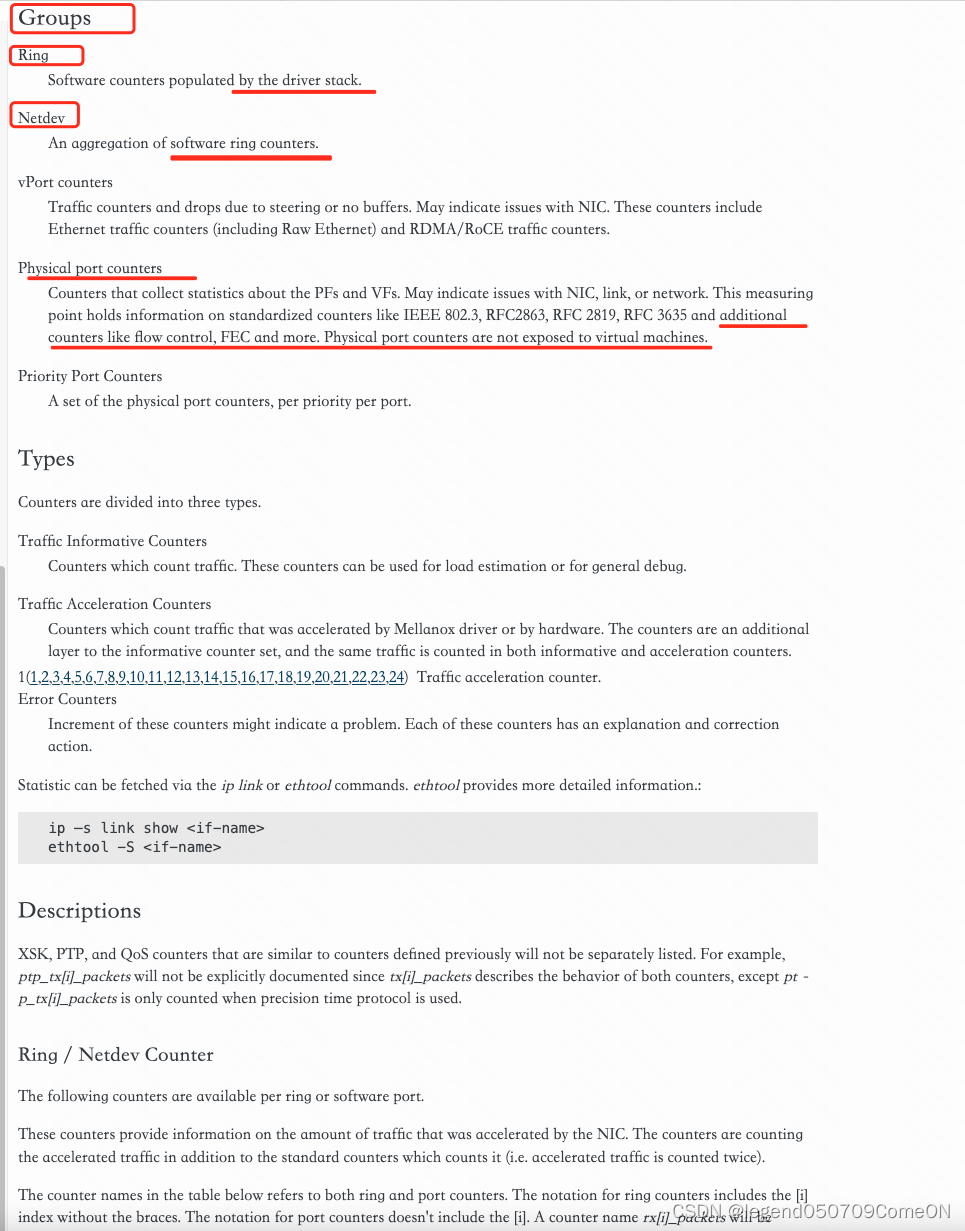
感觉:Physical Port Counters 是网卡和外面网络互联通信时,网卡的硬件计数器。
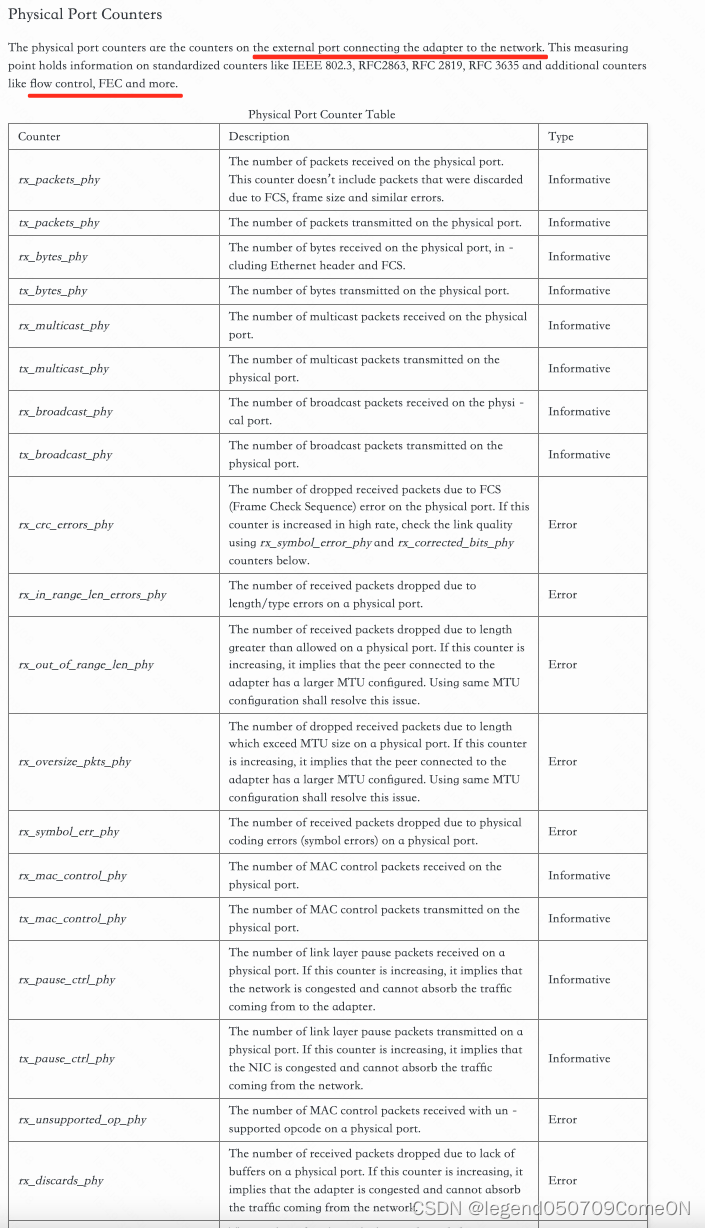
感觉:Device Counters 是网卡和内部设备通信(PCIe协议)的硬件的计数器。
我的理解
Most drivers interchange their use of the counters rx_missed_errors, rx_fifo_errors, and rx_over_errors,
but they typically set one or more of these counters to the MPC (missed packet count) counter, which is incremented when a packet arrives and is lost because the card's FIFO queue is full.
上面这段话就是说,ethtool的输出中,不同网卡,不同固件版本,其输出可能都不一样,有rx_dropped,rx_fifo_error, rx_missed_errors, rx_discards_phy 等等。这些MPC (missed packet count) counter都应该代表的是网卡的Rx FIFO queue满了。
对于Ixgbe网卡:
$ grep rx_missed_errors drivers/net/ixgbe/*
drivers/net/ixgbe/ixgbe_ethtool.c: {"rx_missed_errors", IXGBE_STAT(net_stats.rx_missed_errors)},
drivers/net/ixgbe/ixgbe_main.c: adapter->net_stats.rx_missed_errors = total_mpc;
FIFO指的是网卡上实现的硬件「先进先出」队列;
整个包收发流程为:[ 网卡硬件 FIFO 队列 ] <---- PCIe Bus —> [ Rx Ring Buffer: host memory ]。
对应的丢包计数有两个:
一个是 Missed Packet Count,指的是 [ 网卡硬件 FIFO 队列 ] 满了导致的丢包;
一个是 Receive No Buffer Count,指的是 [ Rx Ring Buffer ] 满了导致的丢包。
- 理解一:rx_fifo error就理解为硬件的队列满了
分为两种情况:
情况一:程序性能或者内核的软中断处理的比较慢,导致ring buffer满,ring buffer 满了之后,dma无法获取到可用的描述符,那么也会导致网卡的硬件队列堆积,进而满了,导致有丢包。
情况二:pcie性能不足,比如带宽宽度,速率不足,或者mps,mrrs不够,导致dma通过pcie填充报文性能不足,进而导致硬件队列满,然后丢包。
- 理解二:ethtool查看队列大小以及队列个数,可能就是ring buffer的大小以及个数。
实际上多队列的网卡硬件队列和ring buffer应该也有一个映射关系吧。可能是多个队列对应一个ring buffer。或者一个硬件的接收缓冲区,然后通过RSS、FDIR给映射到指定的 内核的 ring buffer中。
查看
# ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 18811
RX Mini: 0
RX Jumbo: 0
TX: 2560
Current hardware settings:
RX: 10486
RX Mini: 0
RX Jumbo: 0
TX: 192
设置
# ethtool -G eth0 rx 18000 tx 2500
AIGC回复
intel 82599 10G网卡的统计:
# ethtool -S eth03 | grep -i -e miss -e out_of -e disca -e fifo
fdir_miss: 0
rx_fifo_errors: 0
rx_missed_errors: 0
tx_fifo_errors: 0
Mellanox Cx4-Lx 25G网卡的统计:
# ethtool -S eth03 | grep -i -e disc -e fifo -e out_of
rx_out_of_buffer: 0
rx_out_of_range_len_phy: 0
rx_discards_phy: 394989
tx_discards_phy: 0
rx_prio0_discards: 394989
rx_prio1_discards: 0
rx_prio2_discards: 0
rx_prio3_discards: 0
rx_prio4_discards: 0
rx_prio5_discards: 0
rx_prio6_discards: 0
rx_prio7_discards: 0


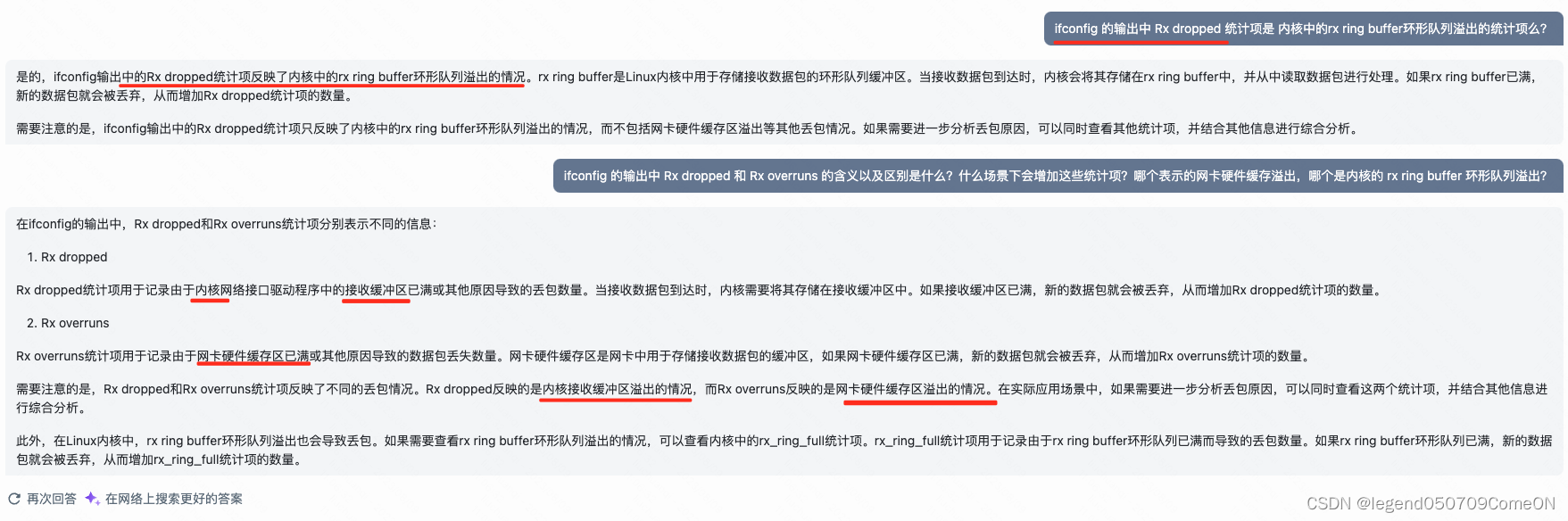
PCIe版本以及速率
为什么需要Pcie
在电脑里,不同的设备要想交互数据,就必须要经过一定的通道。
- 总线
总线就是计算机里,用于走数据的“路”。 - 内部总线
CPU核心和cache缓存交互数据的时候,使用的就是内部总线,这个总线只在CPU内交互数据。 - 外部总线
但是CPU不可能就自己在那空算数吧,他总要和其他设备交互数据,就需要用到外部总线了,CPU会通过外部总线和其他的设备比如硬盘,网卡,声卡,USB设备沟通,我们这个文章想要介绍的PCI-E就是外部总线的一种。 - pcie的作用

PCI-E既是通道,也是接口,当他以接口形式存在的时候,就是我们主板上那长长的槽。
- pcie 通道
PCIe用于系统中的不同模块之间的通信。 网络适配器(网卡)需要与CPU和内存(以及其他模块)进行通信。 这意味着为了处理网络流量,应正确配置PCIe为不同设备进行通信。 将网络适配器连接到PCIe时,它将自动协商网络适配器和CPU之间支持的最大功能。- pcie 接口
目前的声卡和网卡都是主板集成了,不需要我们额外再插,所以PCI-E接口目前最大的作用就是插显卡,除了显卡还有无线网卡,万兆有线网卡这些高带宽设备,除了这些,PCI-E接口也可以转接成很多接口,比如USB3.0,Type-c。
pcie属性之宽度
PCIe宽度确定设备可以并行使用以进行通信的PCIe通道数。 宽度标记为xA,其中A是通道数(例如8通道为x8)。
Mellanox适配器支持x8和x16配置,具体取决于它们的类型。
# lspci -s 04:00.0 -vvv | grep Width
LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM not supported, Exit Latency L0s unlimited, L1 unlimited
LnkSta: Speed 8GT/s, Width x8, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
pcie属性之速度
速度以GT / s表示,表示“每秒十亿笔传输”。
连同PCIe宽度一起,确定最大PCIe带宽(速度*宽度)。
PCIe速度被标识为“generations”,其中2.5GT / s被称为“ gen1”,5GT / s被称为“ gen2”,而8GT / s被称为“ gen3”。
# lspci -s 04:00.0 -vvv | grep PCIeGen
[V0] Vendor specific: PCIeGen3 x8
pcie 速率表
PCIE有不同的规格,通过下图来了解下PCIE的其中2种规格:
- 查看主板上的PCI插槽’
# dmidecode | grep -i "PCI"
- 不同PCIe版本对应的传输速率
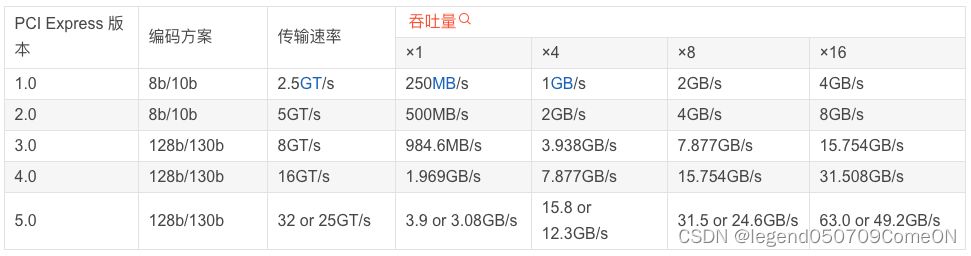
传输速率为每秒传输量GT/s,而不是每秒位数Gbps,因为传输量包括开销位; 比如 PCIe 1.x和PCIe 2.x使用8b / 10b编码方案,导致占用了20% (= 2/10)的原始信道带宽。
- GT/s —— Giga transation per second (千兆传输/秒
即每一秒内传输的次数。重点在于描述物理层通信协议的速率属性,可以不和链路宽度等关联。- Gbps —— Giga Bits Per Second (千兆位/秒)。
GT/s 与Gbps 之间不存在成比例的换算关系。- PCIe 吞吐量(可用带宽)计算方法:
吞吐量 = 传输速率 * 编码方案
例如:PCI-e2.0 协议支持 5.0 GT/s,即每一条Lane 上支持每秒钟内传输 5G次;但这并不意味着 PCIe 2.0协议的每一条Lane支持 5Gbps 的速率。
因为PCIe 2.0 的物理层协议中使用的是 8b/10b 的编码方案。 即每传输8个Bit,需要发送10个Bit;这多出的2个Bit并不是对上层有意义的信息。
那么, PCIe 2.0协议的每一条Lane支持 5 * 8 / 10 = 4 Gbitps = 500 MB/s 的速率。
以一个PCIe 2.0 x8的通道为例,x8的可用带宽为 4 * 8 = 32 Gbps = 4 GB/s。
查看 pcie 设备带宽(带宽上限和实际带宽)
lspci -vv | grep -i PCI-ID -A 40

- LnkCap: 链路能力;
LnkCap 代表的是卡片本身支持的最高速度。- LnkSta: 链路状态;
LnkSta 代表是实际跑的的速度, 如果正常应该要和 LnkCap 一样, 才能获得最大的带宽。如果发现 LnkSta 的速度比LnkCap 小, 那就要追一下是不是插槽本身的速度就有限制。
pcie 插槽插入单卡双口/单卡四口网卡
早期的网卡,一个芯片只能处理一个通道,所以,都是单口的。后来,由于总线带宽的提高, 加上芯片性能的提高,所以出现了双口以上的网卡。
其实原因很简单:
PCI槽有限。所以, 单个槽里的网口越多,机器上能接的网卡越多。
所以:Pcie 插槽的带宽 要 大于 单卡两口/多口的带宽之和。



分析
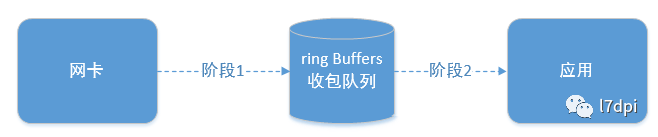
一个网络报文从网卡接收到被应用处理,中间主要需要经历两个阶段:
- 阶段一:网卡通过其DMA硬件将收到的报文写入到收包队列中(入队)
如果入队道路拥塞将会导致报文无法入队(入队)
- 阶段二:应用从收包队列中读取报文(出队)
如果出队慢将导致队列溢出(出队)
注:DMA是硬件,目的将数据包从网卡送到操作系统(ring buffer),期间不需要CPU的参与,节省了CPU。
网卡初始化与收包
整体流程
- DPDK对数据包的处理流程
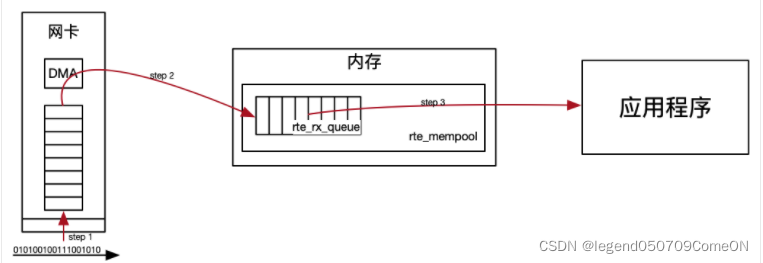
物理网卡监听物理链路上的信息号,解析得到数据包,并将其存放在物理网卡上的RX FIFO中(Rx fifo : 网卡的内存);
物理网卡上的DMA将数据包写入到内存(系统内存)中的 rte_rx_queue(ring buffer);
应用程序通过PMD的形式轮询从rte_rx_queue读取数据包。
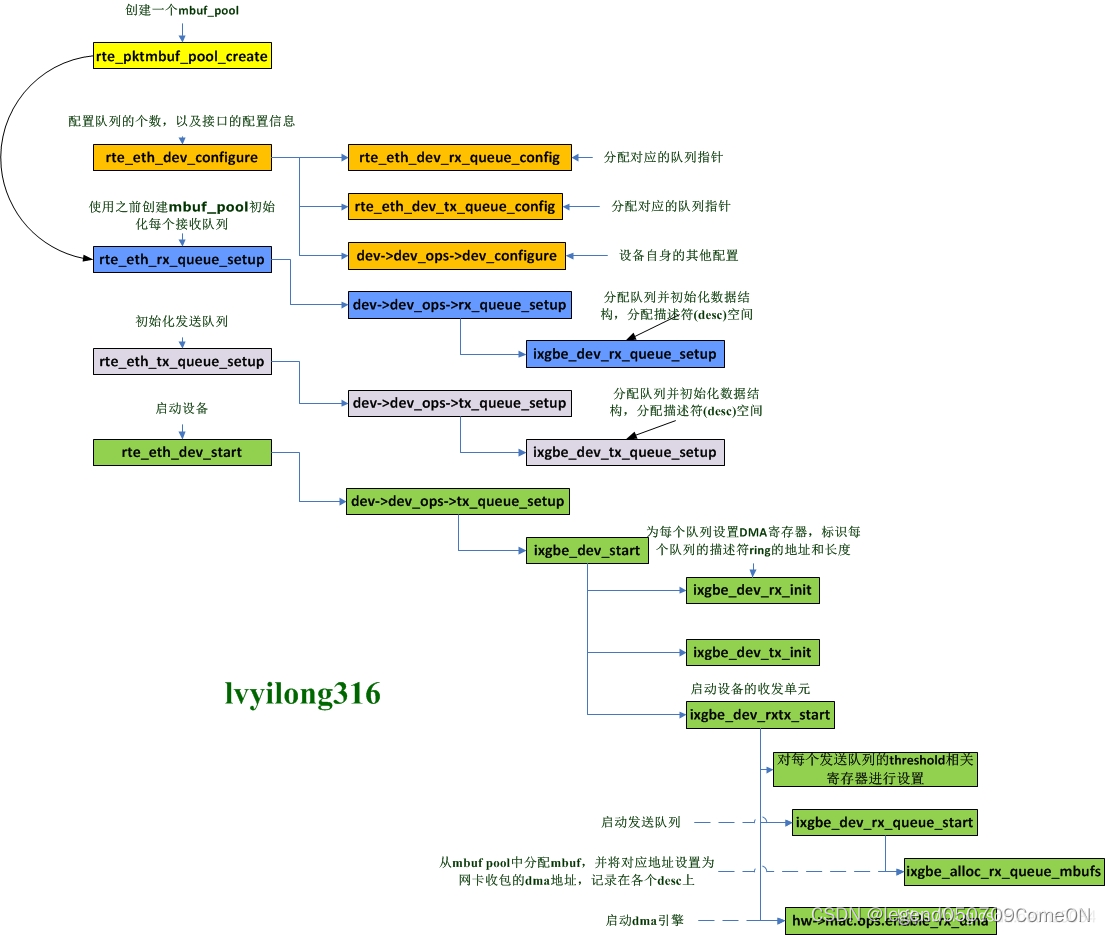
收包队列的构造
下面以ixgbe网卡在dpdk框架下工作为例,分别介绍下收包队列的构造、启动和收包三个流程。

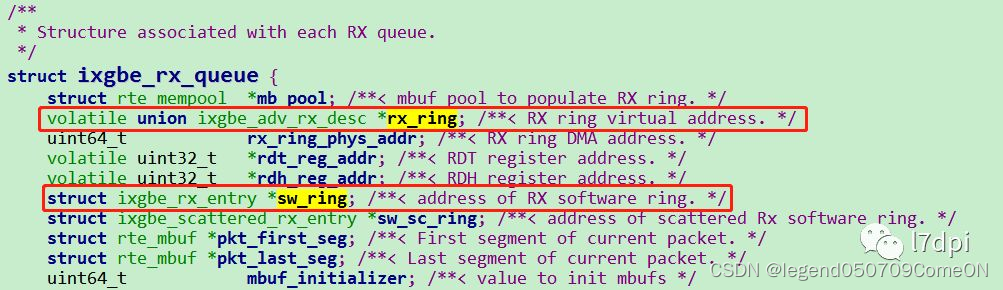
收包队列的构造主要是通过调用网卡队列设置函数rte_eth_rx_queue_setup(dpdk rte_ethdev.h)来完成。
收包队列的结构体为ixgbe_rx_queue,该结构体里包含两个重要的环形队列rx_ring和sw_ring,rx_ring和sw_ring的关系可以简单如下:
rx_ring
主要存储报文数据的物理地址,物理地址供网卡DMA使用,也称为DMA地址(硬件使用物理地址,将报文copy到报文物理位置上)。
sw_ring
sw_ring主要存储报文数据的虚拟地址,虚拟地址供应用使用(软件使用虚拟地址,读取报文)。
其中,报文数据的物理地址可以由报文数据的虚拟地址转化得到。
rx_ring

rx_ring是由一个动态申请的数组构建的环形队列,队列的元素是ixgbe_adv_rx_desc类型,队列的长度为(4096+4-1)。

pkt_addr:报文数据的物理地址,网卡DMA将报文数据通过该物理地址写入对应的内存空间。
hdr_addr:报文的头信息。
注:status_error的最后一个bit也对应DD位。
DD位(Descriptor Done Status)用于标志标识一个描述符buf是否可用。
- 放入队列
网卡每次来了新的数据包,就检查rx_ring当前这个buf的DD位是否为0,如果为0那么表示当前buf可以使用,就让DMA将数据包copy到这个buf中,然后设置DD为1。如果为1,即最上面的buf都不可用,那么网卡就认为rx_ring队列满了,直接会将这个包给丢弃掉(0->1)。
- 从队列中取
对于应用而言,DD位使用恰恰相反,在读取数据包时,先检查DD位是否为1,如果为1,表示网卡已经把数据包放到了内存中,可以读取,读取完后,再放入一个新的buf并把对应DD位设置为0。如果为0,就表示没有数据包可读。(1->0)
sw_ring

sw_ring是由一个动态申请的数组构建的环形队列,队列的元素是ixgbe_rx_entry类型,队列的大小可配,一般最大可配4096。

mbuf:报文mbuf结构指针,mbuf用于管理一个报文,主要包含报文相关信息和报文数据。
网卡启动
收包队列的启动主要是通过调用 rte_eth_dev_start(dpdk rte_ethdev.h)函数完成,收包队列初始化的核心流程如下。
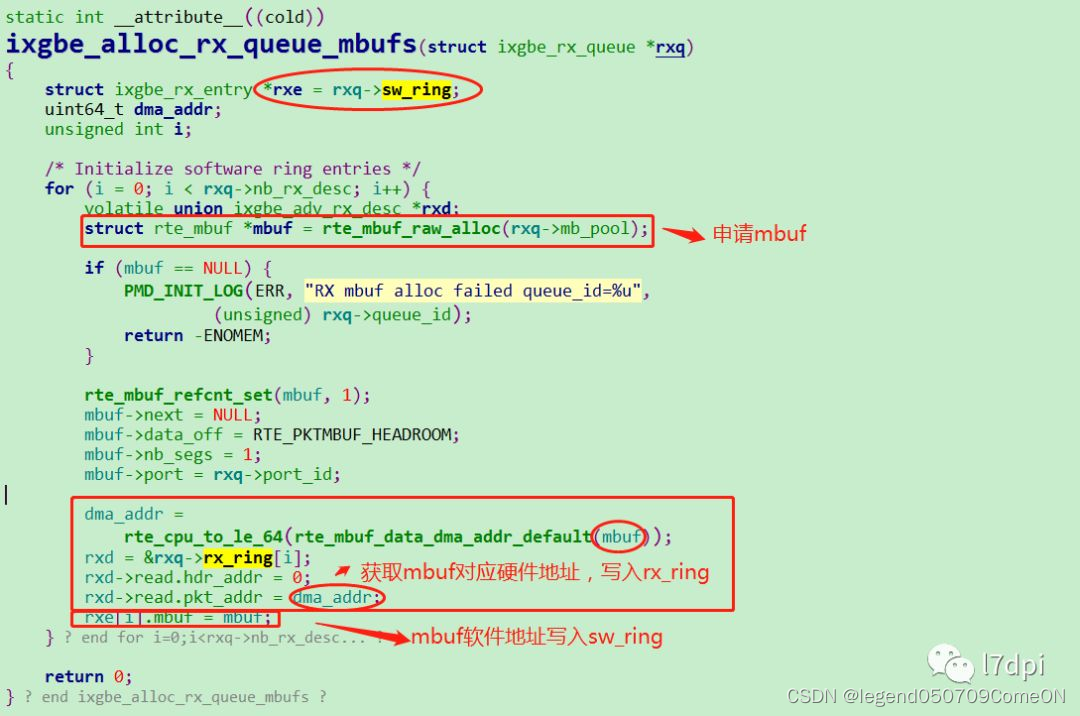
循环从mbuf pool中申请mbuf,从mbuf中得到报文数据对应的物理地址,物理地址存入rx_ring中,mbuf指针存入sw_ring中。其中通过rxd->read.hdr_addr = 0,完成了DD位设置为0。
收包流程
收包由网卡入队和应用出队两个操作完成。
1、网卡使用DMA写Rx FIFO中的Frame到Rx Ring Buffer中的mbuf,设置desc的DD为1;
2、网卡驱动取走mbuf后,设置desc的DD为0;
入队

入队的操作是由网卡DMA来完成的。
DMA(Direct Memory Access,直接存储器访问)是系统和网卡(外设)打交道的一种方式,该种方式允许在网卡(外部设备)和系统内存之间通过PCIe总线直接读写数据,这样能有效减轻CPU的工作。
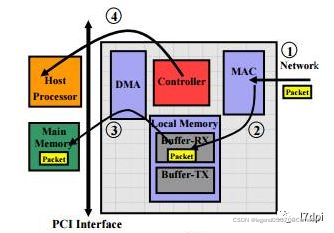
网卡收到报文后,先存于网卡本地的buffer-Rx(Rx FIFO)中,然后由DMA通过PCI总线将报文数据写入操作系统的内存中,即数据报文完成入队操作。(PS:PCIe总线可能成为网卡带宽的瓶颈)
出队
应用调用rte_eth_rx_burst(dpdk rte_ethdev.h)函数开始批量收包,最大收包数量由参数nb_pkts决定(比如设置为64)。其核心流程由ixgbe_recv_pkts(dpdk ixgbe_rxtx.c)实现。
从接口的收包队列rxq->rx_ring 的 rx_tail位置开始收,循环读取一个报文、填空一个报文(空报文数据),读取64个后,重新标记rx_tail的位置,完成出队操作,将收取的报文作返回供应用处理。
入队丢包可能性
入队问题主要集中在PCIe异常“降速”方面。因为报文从网卡到系统是通过DMA经过PCIe总线来传输的,PCIe总线的吞吐将直接影响入队的速率。
pcie 实际带宽和理论带宽不符合
若网口出现imissed,可通过lspci -vv命令查看PCIe理论能力与实际使用是否一致。
情况1:
网口能力是传输速率5GT/s,总线宽带x8(LnkCap),实际使用的是传输速率5GT/s,总线宽带x4(LnkSta)。吞吐能力从4GB/s下降到2GB/s。
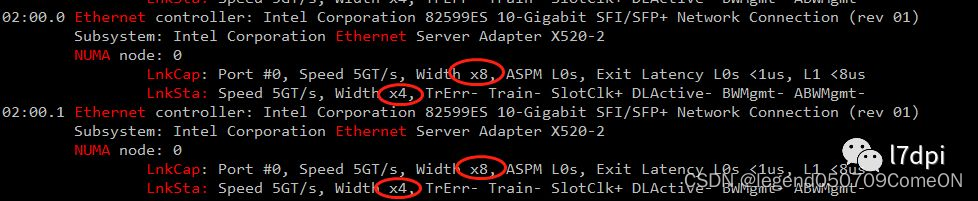
情况2:
网口能力是传输速率8GT/s,总线宽带x8(LnkCap),实际使用的是传输速率5GT/s,总线宽带x8(LnkSta)。吞吐能力从7.877GB/s下降到4GB/s。

解决
一般是服务器PCIe插槽与网卡兼容性问题,可以更换网卡或者更换服务器PCIe插槽。如果有条件,可以找服务器厂商从bios等方面进行详细定位解决兼容性问题。
出队丢包可能性
出队问题主要集中在应用程序性能不高、程序设计不优和CPU错误降频等方面。
DPDK程序性能不高
DPDK程序的实际CPU使用率达到100%,不能及时处理队列报文,导致队列报文溢出,持续imissed++,此时出队平均速率是小于入队平均速率。
解决
inux系统下可以使用perf性能分析工具,做热点函数分析,perf安装命令yum install perf。perf常用的热点函数定位命令如下:
- 进程级:perf top -p
- 线程级:perf top -t
线程tid可以通过pidstat -t -p 或者 top -p PID -H 获取。
DPDK程序设计不优
DPDK程序的实际CPU使用率没有达到100%,但依然偶尔会丢包,断续imissed++。一般这是因为出队速率抖动引发溢出,即出队最低速率小于入队平均速率,而收包队列的规格(几K)不足以缓存拥塞的报文。
解决
偶尔丢包有时不容易从热点函数中发现,需要分析代码流程进行调优。
比如:某个报文会触发密集cpu计算,需要更长处理时间,如收到fin报文流结束,对流内容进行复杂处理。针对这种情况,我们可以从以下两个方面进行调优:
- 异步处理
将复杂处理由同步处理(Run-to-completion)改为异步处理(Pipeline),降低抖动。
- 加软队列
增加一级容量更大的软队列,缓存抖动(一般业务有按规则分发的需要也需要构建一级软队列,软队列可能会或多或少增加报文处理的延时)。
比如:DPVS中设置单独的KNI处理线程来处理本机的流量。之前是Slave收到包,交给了Master来处理,而本身Master的任务就比较重,可能master正在进行大量配置的查询或者下发,此时可能影响到本机流量的处理。
CPU错误降频
如果CPU被降频,将直接影响出队性能。
现象
查看系统日志,出现CPU被错误降频。

分析

解决

查看当前的CPU频率 与运行模式
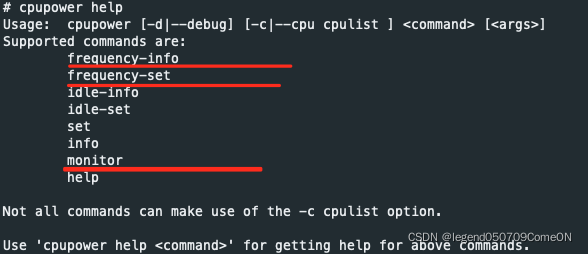
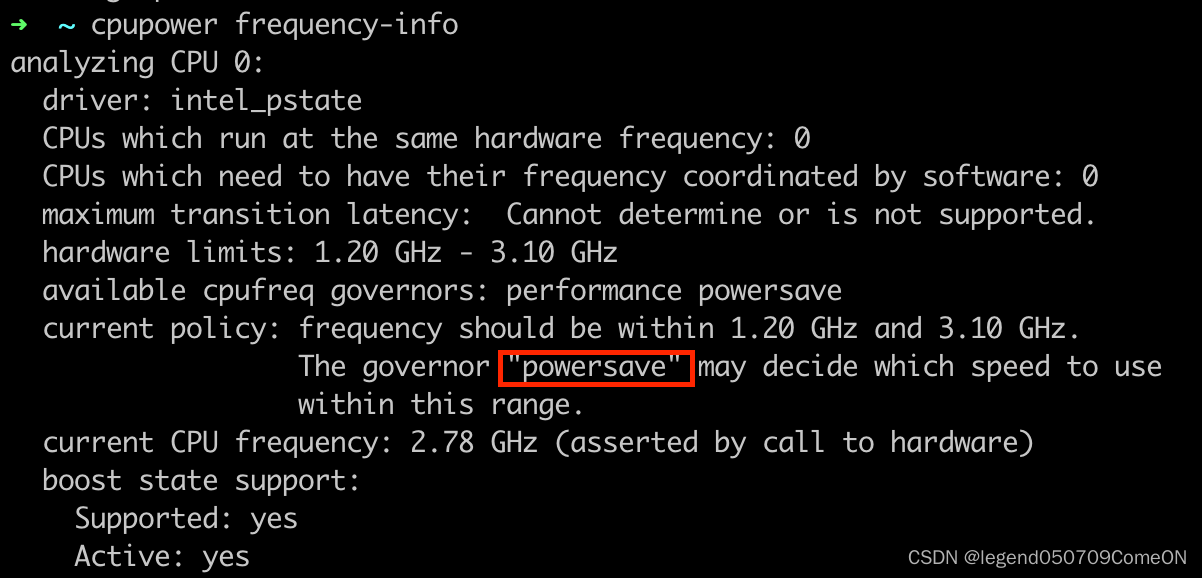
查看cpu的每个core的频率:
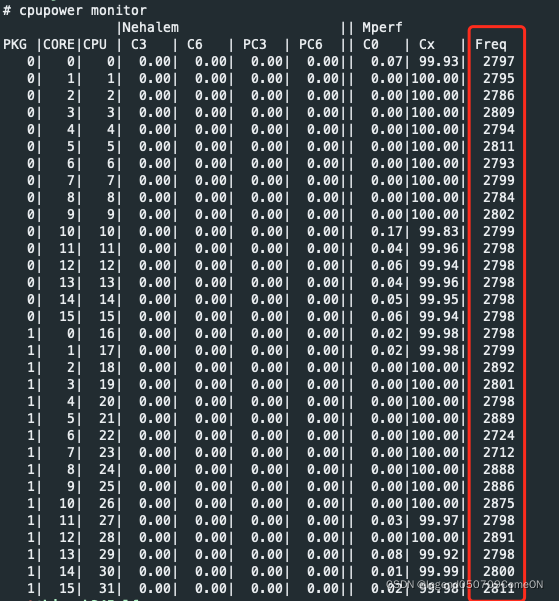
如果当前运行在powersave模式下,可以将其修改为performance,提升CPU频率。
cpupower frequency-set -g performance。
总结
出现 imiss,主要是由于 数据包被硬件丢弃。可能性分析如下:
- 入队慢:
pci-e 实际带宽慢。- 出队慢:
1》程序性能不行;
2》程序设计缺陷;
3》cpu降频
参考
https://mp.weixin.qq.com/s/jM7R-LXsLWbGqqXLlowxSw

















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









