







第一种方式:
利用main中参数args方式,程序如下:
package algorithm import org.apache.spark.{SparkContext, SparkConf} object WordCount { def main(args: Array[String]) { //第一步:spark运行的环境,这个是必须的步骤 val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]") //第二步:创建SparkContext,它是spark程序的唯一入口 val sc = new SparkContext(conf) val count=sc.textFile(args(0)).filter(line => line.contains("Spark")).count() //val count = sc.textFile("E://软件//BigData//spark-1.6.0-bin-hadoop2.6//spark-1.6.0-bin-hadoop2.6//README.md ").filter{ // line =>line.contains("Spark") // }.count() //打印结果 println("count="+count) //结束进程 sc.stop() } }第一步:点击Build 之后make project,把已经写好的程序,成立工程
第二步:点击Run 之后Edit configurations ,设置如下:
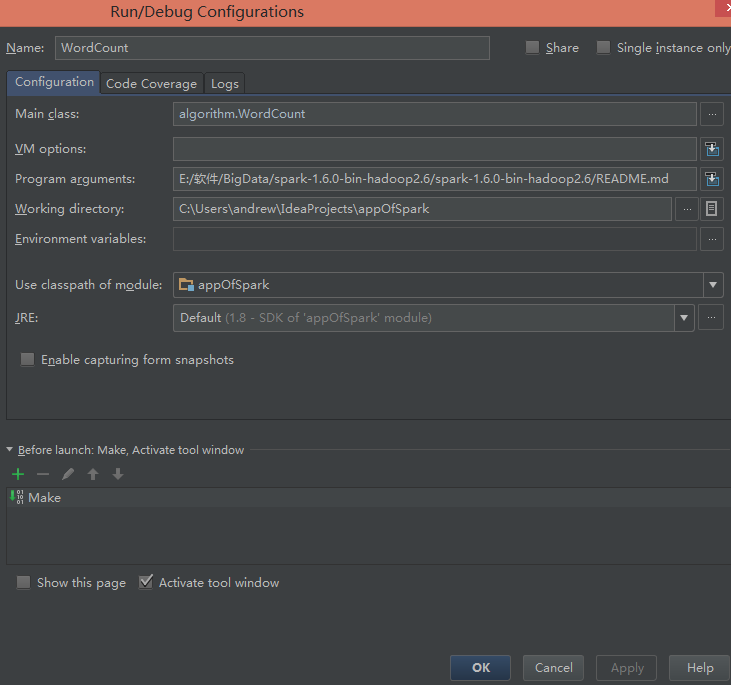
Program arguments:设置为你输入的文件
运行结果为:count=17
第二种方式:
直接调用textFile函数:使用方式为注释部分,特别注意参数文件的格式,之间可以是“//”,也可以是 “/”















 3579
3579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









