







============目录================================================
本地向量(local vector)
标记点(Labeled point)
本地矩阵(Local matrix)
---------------------------------------------------------------------------------------------------------------
本地向量:
本地向量是由从0开始的整数下标和Double类型的数值组成。它有稠密向量(dense vector)和稀疏向量(sparse vertor)两种
下面是官网上导入向量[1 0 3]的导入方式
import org.apache.spark.mllib.linalg.{Vector, Vectors}
// Create a dense vector (1.0, 0.0, 3.0).
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its indices and values corresponding to nonzero entries.
val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its nonzero entries.
val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))分析:一个稠密矩阵是double类型的数组,而稠密矩阵的形式是(size ,Array1,Array2)size是矩阵的大小,
平行矩阵Array1和Array2中Array1是标记,而Array2是对应的数值,当然也可以用seq((index,value),(index,value),....)的形式
标记点(Labeled point):
标记点是指一个向量加上一个标记值p组成的特殊的本地向量,它的存储格式是LIBSVM和LIBLINEAR(by林智仁),专门用于有监督
的机器学习,这个标记值P可以是任何值,但是大部分为0和1
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
// Create a labeled point with a positive label and a dense feature vector.
val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
// Create a labeled point with a negative label and a sparse feature vector.
val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))1、从它导入的数据包就知道属于regression(回归)部分
2、导入之后的形式是:label index1:value1 index2:value2 ...
本地矩阵(Local matrix)
本地矩阵是包含行和列都是整数的指标,加上Double类型的数值.它有稠密矩阵(dense matrix)和稀疏矩阵(sparse matrix)两种matrix,下面是官网
对矩阵
import org.apache.spark.mllib.linalg.{Matrix, Matrices}
// Create a dense matrix ((1.0, 2.0), (3.0, 4.0), (5.0, 6.0))
val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
// Create a sparse matrix ((9.0, 0.0), (0.0, 8.0), (0.0, 6.0))
val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8))
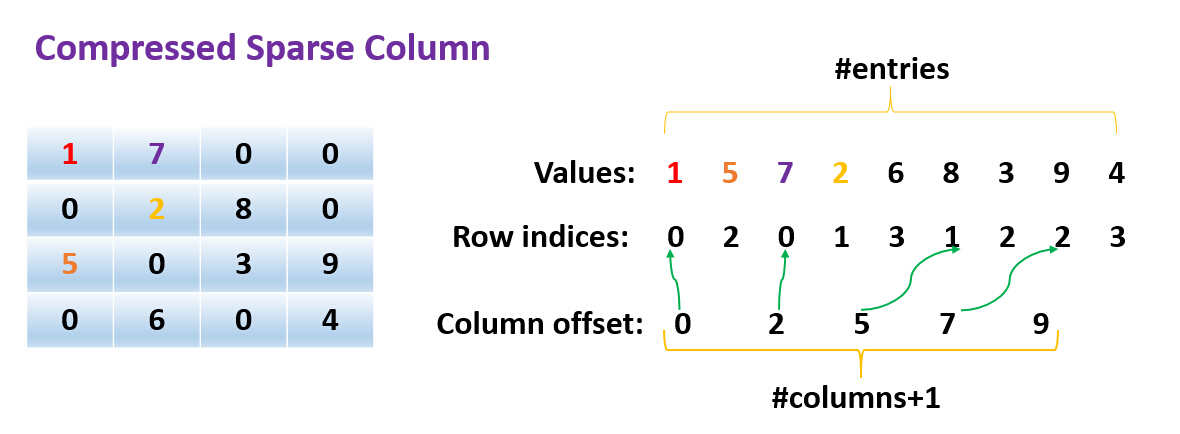
CSC(Compressed Sparse Column):是Spark稀疏矩阵的存储方式。比如这个矩阵在Spark的表达形式:
Matrices.sparse(4, 4, Array(0,2, 5, 7,9), Array(0,2, 0,1,3, 1,2, 2,3), Array(1.0, 5.0, 7.0, 2.0, 6.0, 8.0 , 3.0 , 9.0 , 4.0))
第一列0 偏移第二列 2 偏移Row indices有2个属于第一列(0,0)=1,(2,0)=5
第三列有5个偏移,那么有3个(5-2)属于第二列(0,1)=7 ,(1,1)=2,(3,1)=6
第四列有7个偏移,那么有2个(7-5)属于第三列(1,2)=8,(2,2)=3
一共有9个,那么有2个(9-7)属于第四列(2,3)=9,(3,3)=4
参考文献:
http://spark.apache.org/docs/latest/mllib-data-types.html
http://www.cnblogs.com/xbinworld/p/4273506.html?utm_source=tuicool&utm_medium=referral
感谢















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









