







RDD子类
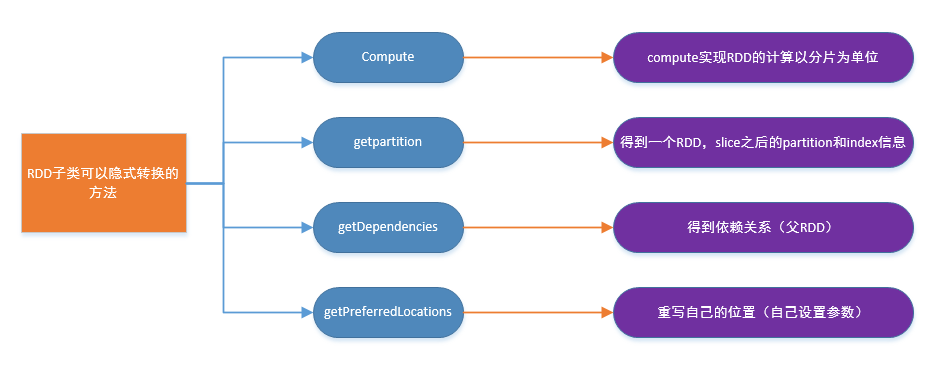
// ======================================================================= // Methods that should be implemented by subclasses of RDD // ======================================================================= /** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T] /** * compute:用来计算RDD的subclass的partition * Scala中的Iterator,可用来依次取下一个数据 * 它有一个特点,叫TraversableOnce,就像单行道,只能向前走,不能回头 */ /** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. *得到子类的 partition和index的信息 * The partitions in this array must satisfy the following property: * `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }` */ protected def getPartitions: Array[Partition] /** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * 得到父RDD的信息 * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependency[_]] = deps /** * Optionally overridden by subclasses to specify placement preferences.由子类重写指定位置偏好。 */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil /** Optionally overridden by subclasses to specify how they are partitioned. */@transient val partitioner: Option[Partitioner] = None
// ======================================================================= // Methods and fields available on all RDDs // ======================================================================= /** The SparkContext that created this RDD. 每个RDD都可以包含创建时候关于环境的信息*/ def sparkContext: SparkContext = sc /** A unique ID for this RDD (within its SparkContext). */ val id: Int = sc.newRddId() /** A friendly name for this RDD */ @transient var name: String = null /** Assign a name to this RDD */ def setName(_name: String): this.type = { name = _name this }















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









