







Transformations on DStreams
和RDDs一样,各种转换允许数据从inputDstream得到之后进行各种改造。DStreams支持各种转换,他们是基于Spark的RDD的,一些常规的转换如下:
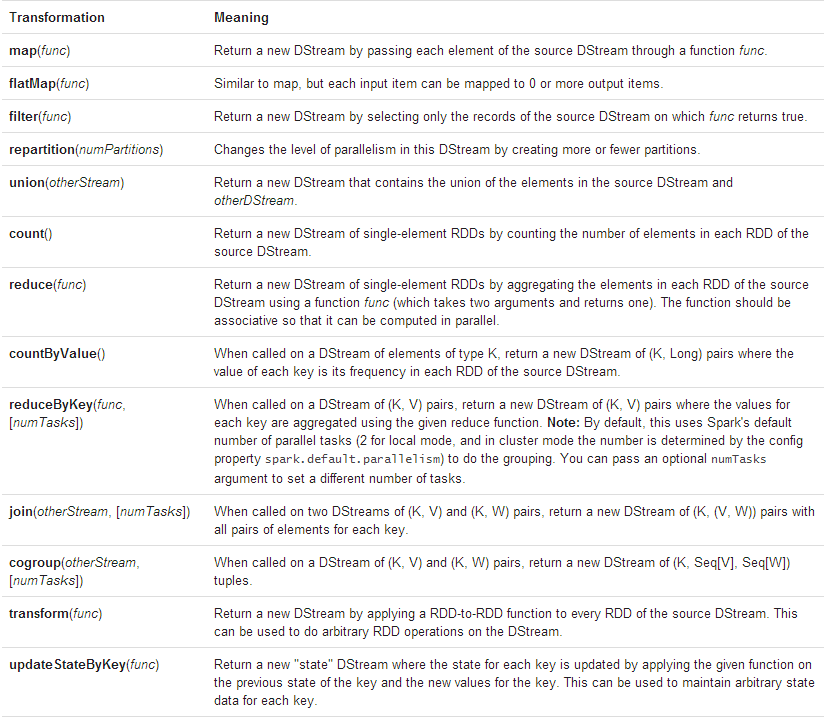
但是和和RDD有点区别,那就是DStream是内部含有多个RDD,它是用HashMap接受流进来的RDD
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]]()
而DStream是如下:
大部分的操作在RDD中是有的,下面讲解transform和updateStateByKey
(1)transform函数
先看一下源码
/**
* Return a new DStream in which each RDD is generated by applying a function
* on each RDD of 'this' DStream.
*/
def transform[U: ClassTag](transformFunc: (RDD[T], Time) => RDD[U]): DStream[U] = ssc.withScope {
// because the DStream is reachable from the outer object here, and because
// DStreams can't be serialized with closures, we can't proactively check
// it for serializability and so we pass the optional false to SparkContext.clean
val cleanedF = context.sparkContext.clean(transformFunc, false)
val realTransformFunc = (rdds: Seq[RDD[_]], time: Time) => {
assert(rdds.length == 1)
cleanedF(rdds.head.asInstanceOf[RDD[T]], time)
}
new TransformedDStream[U](Seq(this), realTransformFunc)
}
函数的作用,程序如下:
//use the transform to sort the top N
hottestDStream.transform(hottestItemRDD => {
val top3 = hottestItemRDD.map(pair => (pair._2, pair._1)).sortByKey(false).
map(pair => (pair._2, pair._1)).
take(3) //选出前3个
for (item <- top3) {
println(item)
}
hottestItemRDD
}).print(2)updateStateByKey
当新的信息流进来的时候,更新状态时,updateStateByKey运算允许你保留任何状态时候的数据。为了用它,你必须要有两个操作
1、定义状态,這个状态可以是任何类型的
2、定义状态更新函数,指定一个函数,這个函数可以用之前状态和新输入的流的数据
对于每个批次,Spark会对所有存在的keys,进行应用状态更新函数。在实时计算的时候,有时候我们需要对全部
1、定义状态,這个状态可以是任何类型的
2、定义状态更新函数,指定一个函数,這个函数可以用之前状态和新输入的流的数据
对于每个批次,Spark会对所有存在的keys,进行应用状态更新函数。在实时计算的时候,有时候我们需要对全部
的数据进行统计,不管是否有新的数据进入。如果状态更新函数返回None,那么就会消除key-value pair.源码如下:
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* org.apache.spark.Partitioner is used to control the partitioning of each RDD.
* @param updateFunc State update function. Note, that this function may generate a different
* tuple with a different key than the input key. Therefore keys may be removed
* or added in this way. It is up to the developer to decide whether to
* remember the partitioner despite the key being changed.
* @param partitioner Partitioner for controlling the partitioning of each RDD in the new
* DStream
* @param rememberPartitioner Whether to remember the partitioner object in the generated RDDs.
* @param initialRDD initial state value of each key.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)],
partitioner: Partitioner,
rememberPartitioner: Boolean,
initialRDD: RDD[(K, S)]
): DStream[(K, S)] = ssc.withScope {
new StateDStream(self, ssc.sc.clean(updateFunc), partitioner,
rememberPartitioner, Some(initialRDD))
}(1)updateFunc: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)]
更新函数是 输入(Iterator[(K, Seq[V], Option[S])])类型,返回Iterator[(K, S)]类型
(Iterator[(K, Seq[V], Option[S])])是一个三元Iterator,分别表示
K: key
Seq[v]:一个时间间隔产生Key对应的Value集合
Option[S]是上个函数的累加值。
Iterator[(K, S)]是一个二元的Iterator,分别表示:
K:key
S:是当前时间结束后得到的累加值
(2) partitioner
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
分区进行hash分区算法,默认是sparkContext.defaultParallelism也就是不设置就跟你的core有关
(3)rememberPartitioner: Whether to remember the partitioner object in the generated RDDs.
(4)initialRDD: RDD[(K, S)]
记录的是 每个key对应的状态(State),S是State type在StreamingContext中初始值为:private var state: StreamingContextState = INITIALIZED
继续找下去 发现是用Option进行了封装。也它可以是Int,String這样的类型
在把 new StateDStream分析下去,内部是有computeUsingPreviousRDD(进行 cogroup)和
compute(得到之前状态的RDD)
updateStateByKey的效果:
1:在socket端每秒产生一个单词,单词如下:
spark
Streaming
better
than
storm
you
need
it
yes
do
it
Streaming
better
than
storm
you
need
it
yes
do
it
2、SparkStreaming程序:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
object statefulNetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: StatefulNetworkWordCount <hostname> <port>")
System.exit(1)
}
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val sparkConf = new SparkConf().setAppName("StatefulNetworkWordCount").setMaster("local[2]")
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint(".")
// Initial state RDD for mapWithState operation
val initialRDD = ssc.sparkContext.parallelize(List(("hello", 1), ("world", 1)))
// Create a ReceiverInputDStream on target ip:port and count the
// words in input stream of \n delimited test (eg. generated by 'nc')
val lines = ssc.socketTextStream(args(0), args(1).toInt)
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
// Update the cumulative count using mapWithState
// This will give a DStream made of state (which is the cumulative count of the words)
val mappingFunc = (word: String, one: Option[Int], state: State[Int]) => {
val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
val output = (word, sum)
state.update(sum)
output
}
val stateDstream = wordDstream.mapWithState(
StateSpec.function(mappingFunc).initialState(initialRDD))
stateDstream.print()
ssc.start()
ssc.awaitTermination()
}
}
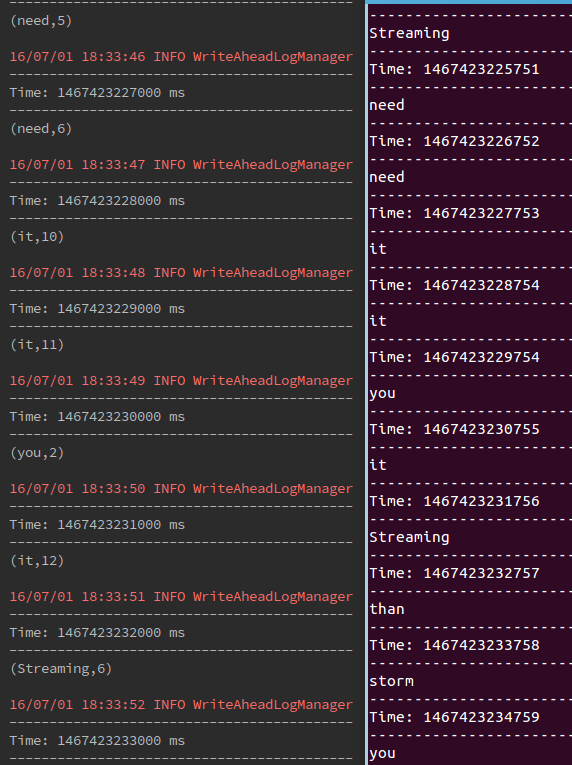
总结:我们在进行实时监控的时候,我们可以看利用updateStateByKey,来整个监控时间段的流过的每个item。
从而来进行全局的分析。















 2758
2758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









