







一、UDF
UDF(User-Defined Function)
Hive环境下
1、准备数据
Michael, 29
Andy, 30
Justin, 192、上传HDFS

3、创建Hive表
CREATE EXTERNAL TABLE PeopleTable(name STRING,age INT)
COMMENT 'this is a test'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '
STORED AS TEXTFILE
LOCATION '/library/people';4、编写自定义函数
public class myUpper extends UDF {
public Text evaluate(Text t, String lowerOrUpper) {
assert (lowerOrUpper == null)
if ("lower".equals(lowerOrUpper)) {
return new Text(t.toString().toLowerCase());
} else if ("upper".equals(lowerOrUpper)) {
return new Text(t.toString().toUpperCase());
}else{
throw new IllegalArgumentException();
}
return t;
}
}5、打包成jar文件,同时加入hive中
hive> add jar /root/Desktop/legotime-0.0.1.jar;6、调用函数
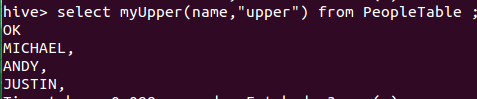
spark环境下
1、编写函数
scala编写:
package UDF
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions.udf
object SparkUDFByScala {
case class Person(name: String, age: Long)
def upper:String => String = _.toUpperCase
def upperUDF: UserDefinedFunction = udf(upper)
def main(args: Array[String]) {
val sparkSession = SparkSession.builder().appName("data set example")
.master("local").getOrCreate()
import sparkSession.implicits._
val rdd = sparkSession.sparkContext.textFile("hdfs://master:9000/src/main/resources/people.txt")
val dataSet = rdd.map(_.split(",")).map(p =>Person(p(0),p(1).trim.toLong)).toDS()
dataSet.withColumn("upper", upperUDF('name)).show
}
}

Java编写:
import java.io.Serializable;
public class Person implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.JavaRDD;
public class SparkUDFByJava {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession
.builder()
.appName("Java API Test for UDF")
.master("local")
.getOrCreate();
//定义一个函数,名字叫upper
sparkSession.udf().register("upper",new UDF1<String,String>(){
//输入的是一个String类型,输出的也是一个String类型
public String call(String o) throws Exception {
return o.toUpperCase();
}
}, DataTypes.StringType);
JavaRDD<Person> perpleRDD = sparkSession.read()
.textFile("hdfs://master:9000/src/main/resources/people.txt")
.javaRDD()
.map(new Function<String, Person>() {
public Person call(String line) throws Exception {
String[] parts = line.split(",");
Person person = new Person();
person.setName(parts[0]);
person.setAge(Integer.parseInt(parts[1].trim()));
return person;
}
});
Dataset<Row> peopleDF = sparkSession.createDataFrame(perpleRDD, Person.class);
peopleDF.createOrReplaceTempView("people");
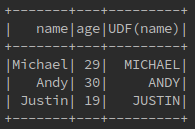
Dataset<Row> upper = sparkSession.sql("SELECT name,age,upper(name) from people");
upper.show();
}
}
一、UDAF
支持多个输入,一个输出
Hive环境下:
由于Hive技术比较成熟,理论篇幅也比较多,省去麻烦,可以参考:
http://beekeeperdata.com/posts/hadoop/2015/08/17/hive-udaf-tutorial.html
Spark环境下:
package UDF
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
class MyUDAFMean extends UserDefinedAggregateFunction{
//输入的数据类型的Schema
override def inputSchema: StructType = StructType(Array(StructField("类型1", DoubleType)))
/**
* 初始化操作
* @param buffer
*/
override def initialize(buffer: MutableAggregationBuffer) = {
//也可以做一些初始化安全判断的操作
assert(buffer.length==2)
//MutableAggregationBuffer初始化接受的两个参数,这个根据你的需要来决定参数的个数
//最多可以延长22个,可以看看MutableAggregationBuffer的的实现
buffer(0) = 0.0
buffer(1) = 0L
}
/**
* 初始化之后,每次迭代的计算
* 思想:让每次数据的Row和我们初始化的MutableAggregationBuffer做一些我们设计好的操作
* @param buffer 我们初始化的MutableAggregationBuffer,是用来接受数值的
* @param input 每次迭代输入的ROw
*/
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//这个input就是我们调用自定义函数输入的参数
buffer(0) = buffer.getDouble(0)+input.getDouble(0)
buffer(1) = buffer.getLong(1)+1
}
//中间计算时候的模式
override def bufferSchema: StructType = StructType(Array(
//根据你update中的数据类型,来设置
StructField("sum",DoubleType),
StructField("count",LongType)
))
//局部聚合操作
/**
* 局部聚合操作,这部分就相当于map-reduce中的combine,有map-reduce程序中的设置:job.setCombinerClass(Some.class)
* @param buffer1 局部buffer1
* @param buffer2 局部buffer2
*/
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
//buffer1和buffer2都是update函数中的结果,操作的时候根据需求才操作,因为我们的操作是单纯的叠加
buffer1(0) = buffer1.getDouble(0) + buffer2.getDouble(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
/**
* Returns true iff this function is deterministic, i.e. given the same input,
* always return the same output.
*/
override def deterministic: Boolean = true
/**
* 最终平均值
* @param buffer 就是我们merge函数的中结果
* @return 我们想要的数值
*/
override def evaluate(buffer: Row): Any = {
buffer.getDouble(0)/buffer.getLong(1)
}
//返回的数据类型
override def dataType: DataType = DoubleType
}
package UDF
import org.apache.spark.sql.{Dataset, SparkSession}
object SparkUDAFByScala {
case class Person(name: String, age: Long)
def main(args: Array[String]) {
val sparkSession = SparkSession.builder().appName("data set example")
.master("local").getOrCreate()
import sparkSession.implicits._
val rdd = sparkSession.sparkContext.textFile("hdfs://master:9000/src/main/resources/people.txt")
val dataSet: Dataset[Person] = rdd.map(_.split(",")).map(p =>Person(p(0),p(1).trim.toLong)).toDS()
val myUDAFMean = new MyUDAFMean()
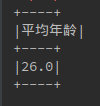
dataSet.agg(myUDAFMean(dataSet.col("age")).as("平均年龄")).show()
}
}
结果:















 112
112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









