







一、特征提取
1、什么是特征提取?
对某一模式的组测量值进行变换,以突出该模式具有代表性特征的一种方法(百度百科)。或者参考多方面的解释
:
http://www.igi-global.com/dictionary/feature-extraction/10960
特征提取简单来说就是从一堆数据中,提取数据,并变成我们熟悉的数据形式(比如从图片中提取像素点,并变成RGB数字,或者把文档变成我们熟悉的向量空间)
2、TF-IDF
TF-IDF是在文本挖掘中广泛使用的特征向量方法,以反映term(术语)对语料库中的文档的重要性。term的频率是term在文档中出现的次数除以总文档的占比。而文档的频率是包含這个term占除以总体文档的占比。如果单从TF(term频率),很容易出现强调出现很频率的term,百比如英文中,'a',‘the’,'of'。IDF(反向文档频率)就说明该term会不会使用很平凡。
TF-IDF计算公式如下:

对于更多细节,可以参考之前写的:
http://blog.csdn.net/legotime/article/details/51836028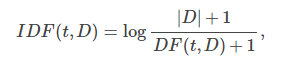
3、TF计算
TF计算Spark提供了HashingTF和CountVectorizer
HashingTF
HashingTF方法用的是hash trick(feature hash).而spark中用的是MurmurHash3 (
https://en.wikipedia.org/wiki/MurmurHash)的算法。为了让大家有一个更深层次的认识。现在来说说什么是hash trick。如下三句话
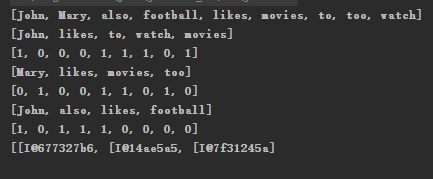
John likes to watch movies.
Mary likes movies too.
John also likes football.
| Term | Index |
|---|---|
| John | 1 |
| likes | 2 |
| to | 3 |
| watch | 4 |
| movies | 5 |
| Mary | 6 |
| too | 7 |
| also | 8 |
| football | 9 |
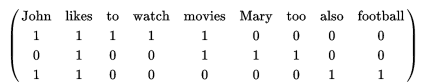
现在用Java来实现:
/**
*
* @param file 文件位置
* @return
* @throws IOException
*/
public static ArrayList<int[]> txt2num(String file) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(file));
String s;
StringBuilder sb = new StringBuilder();
ArrayList<String> strArr = new ArrayList<String>();
while ((s=br.readLine()) != null){
String tmp = s.split("\\.")[0];
strArr.add(tmp);
sb.append(tmp+" ");
}
String[] split = sb.toString().split(" ");
TreeSet<String> strHashSet = new TreeSet<>();
for (String s1 : split) {
strHashSet.add(s1);
}
ArrayList<int[]> txt2Matrix = new ArrayList<int[]>();
System.out.println(Arrays.toString(strHashSet.toArray()));
//填入数据
for (String s1 : strArr) {
int[] txt2IntVec = new int[strHashSet.size()];
String[] ss = s1.split(" ");
ArrayList<String > strs = new ArrayList<String>();
for (String s2 : ss) {
strs.add(s2);
}
System.out.println(Arrays.toString(ss));
for (int i = 0; i < txt2IntVec.length; i++) {
txt2IntVec[i] = strs.contains(strHashSet.toArray()[i]) ? 1 : 0;
}
System.out.println(Arrays.toString(txt2IntVec));
txt2Matrix.add(txt2IntVec);
}
return txt2Matrix;
}
可以看看MLlib下面的MurmurHash3
public final class Murmur3_x86_32 {
private static final int C1 = 0xcc9e2d51;
private static final int C2 = 0x1b873593;
private final int seed;
public Murmur3_x86_32(int seed) {
this.seed = seed;
}
@Override
public String toString() {
return "Murmur3_32(seed=" + seed + ")";
}
public int hashInt(int input) {
return hashInt(input, seed);
}
public static int hashInt(int input, int seed) {
int k1 = mixK1(input);
int h1 = mixH1(seed, k1);
return fmix(h1, 4);
}
public int hashUnsafeWords(Object base, long offset, int lengthInBytes) {
return hashUnsafeWords(base, offset, lengthInBytes, seed);
}
public static int hashUnsafeWords(Object base, long offset, int lengthInBytes, int seed) {
// This is based on Guava's `Murmur32_Hasher.processRemaining(ByteBuffer)` method.
assert (lengthInBytes % 8 == 0): "lengthInBytes must be a multiple of 8 (word-aligned)";
int h1 = hashBytesByInt(base, offset, lengthInBytes, seed);
return fmix(h1, lengthInBytes);
}
public static int hashUnsafeBytes(Object base, long offset, int lengthInBytes, int seed) {
assert (lengthInBytes >= 0): "lengthInBytes cannot be negative";
int lengthAligned = lengthInBytes - lengthInBytes % 4;
int h1 = hashBytesByInt(base, offset, lengthAligned, seed);
for (int i = lengthAligned; i < lengthInBytes; i++) {
int halfWord = Platform.getByte(base, offset + i);
int k1 = mixK1(halfWord);
h1 = mixH1(h1, k1);
}
return fmix(h1, lengthInBytes);
}
private static int hashBytesByInt(Object base, long offset, int lengthInBytes, int seed) {
assert (lengthInBytes % 4 == 0);
int h1 = seed;
for (int i = 0; i < lengthInBytes; i += 4) {
int halfWord = Platform.getInt(base, offset + i);
int k1 = mixK1(halfWord);
h1 = mixH1(h1, k1);
}
return h1;
}
public int hashLong(long input) {
return hashLong(input, seed);
}
public static int hashLong(long input, int seed) {
int low = (int) input;
int high = (int) (input >>> 32);
int k1 = mixK1(low);
int h1 = mixH1(seed, k1);
k1 = mixK1(high);
h1 = mixH1(h1, k1);
return fmix(h1, 8);
}
private static int mixK1(int k1) {
k1 *= C1;
k1 = Integer.rotateLeft(k1, 15);
k1 *= C2;
return k1;
}
private static int mixH1(int h1, int k1) {
h1 ^= k1;
h1 = Integer.rotateLeft(h1, 13);
h1 = h1 * 5 + 0xe6546b64;
return h1;
}
// Finalization mix - force all bits of a hash block to avalanche
private static int fmix(int h1, int length) {
h1 ^= length;
h1 ^= h1 >>> 16;
h1 *= 0x85ebca6b;
h1 ^= h1 >>> 13;
h1 *= 0xc2b2ae35;
h1 ^= h1 >>> 16;
return h1;
}
}
比较简单,可以看看如下:和hash trick区别在于,它是对某个term进行了计算。

二、文本分类
数据
http://qwone.com/~jason/20Newsgroups/
上面已经有数据的属性说明,
选用的数据集是:
导入HDFS如下:

数据预处理
把数据转换为如下格式:
case class LabeledText(item:String,label:Double,doc:String)item:文件名字(类名)
label:标签
doc:从整个文本中提取的单词或者字母
object NewClassifier {
def listSonRoute(path: String): Seq[String] ={
val conf = new Configuration()
val fs = new Path(path).getFileSystem(conf)
val status = fs.listFiles(new Path(path),true)
var res: List[String] = Nil
while (status.hasNext){
res = res++Seq(status.next().getPath.toString)
}
res
}
/**
* 提取英文单词或者字母
* @param content
* @return
*/
def splitStr(content: String): List[String] =("[A-Za-z]+$".r findAllIn content).toList
def rdd2Str(sc:SparkContext,path:String)= {
val rdd = sc.textFile(path)
val myAccumulator = sc.accumulator[String](" ")(StringAccumulatorParam)
rdd.foreach{ part=> splitStr(part).foreach{ word =>
myAccumulator.add(word.toLowerCase)
}}
myAccumulator.value
}
def getDataFromHDFS(sc:SparkContext,path:String): DataFrame ={
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
listSonRoute(path).map(
part =>
LabeledText(part.split("/").apply(8),new Random(100).nextInt(),rdd2Str(sc,part))
).toDF()
}
case class LabeledText(item:String,label:Double,doc:String)
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("new Classifier").setMaster("local")
.set("spark.storage.memoryFraction", "0.1")
val sc = new SparkContext(conf)
// rawData to parquet
val testPath = "hdfs://master:9000/data/studySet/textMining/20news-bydate/20news-bydate-test"
val trainPath = "hdfs://master:9000/data/studySet/textMining/20news-bydate/20news-bydate-train/"
val testDF = getDataFromHDFS(sc,testPath)
val trainDF = getDataFromHDFS(sc,trainPath)
testDF.write.save("hdfs://master:9000/data/studySet/textMining/20news-bydate/test")
trainDF.write.save("hdfs://master:9000/data/studySet/textMining/20news-bydate/train")
}
}
object StringAccumulatorParam extends AccumulatorParam[String] {
override def addInPlace(r1: String, r2: String): String = add(r1,r2)
/**
* 初始化
* @param initialValue 初始值
* @return
*/
override def zero(initialValue: String): String = ""
def add(v1:String,v2:String)={
assert((!v1.isEmpty)|| (!v2.isEmpty))
v1+v2+" "
}
}
贝叶斯分类
下面结合pipeline的处理方式用贝叶斯对文本进行分类,程序如下:
package txtMIning
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs._
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.{DecisionTreeClassifier, NaiveBayes}
import org.apache.spark.ml.feature.{HashingTF, RegexTokenizer}
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{AccumulatorParam, SparkConf, SparkContext}
import scala.util.Random
/**
* 新闻分类
*/
object NewClassifier {
def listSonRoute(path: String): Seq[String] ={
val conf = new Configuration()
val fs = new Path(path).getFileSystem(conf)
val status = fs.listFiles(new Path(path),true)
var res: List[String] = Nil
while (status.hasNext){
res = res++Seq(status.next().getPath.toString)
}
res
}
/**
* 提取英文单词或者字母
* @param content
* @return
*/
def splitStr(content: String): List[String] =("[A-Za-z]+$".r findAllIn content).toList
def rdd2Str(sc:SparkContext,path:String)= {
val rdd = sc.textFile(path)
val myAccumulator = sc.accumulator[String](" ")(StringAccumulatorParam)
rdd.foreach{ part=> splitStr(part).foreach{ word =>
myAccumulator.add(word.toLowerCase)
}}
myAccumulator.value
}
def getDataFromHDFS(sc:SparkContext,path:String): DataFrame ={
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
listSonRoute(path).map(
part =>
LabeledText(part.split("/").apply(8),new Random(100).nextInt(),rdd2Str(sc,part))
).toDF()
}
def readParquetFile(sc:SparkContext,path:String)={
val sqlContext = new SQLContext(sc)
sqlContext.read.parquet(path).toDF()
}
case class LabeledText(item:String,label:Double,doc:String)
/**
*
*
* @param args
*/
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("new Classifier").setMaster("local")
.set("spark.storage.memoryFraction", "0.1")
val sc = new SparkContext(conf)
// // rawData to parquet
// val testPath = "hdfs://master:9000/data/studySet/textMining/20news-bydate/20news-bydate-test"
// val trainPath = "hdfs://master:9000/data/studySet/textMining/20news-bydate/20news-bydate-train/"
// val testDF = getDataFromHDFS(sc,testPath)
// val trainDF = getDataFromHDFS(sc,trainPath)
// testDF.write.save("hdfs://master:9000/data/studySet/textMining/20news-bydate/test")
// trainDF.write.save("hdfs://master:9000/data/studySet/textMining/20news-bydate/train")
//数据增加label(而且这个label必须是Double类型)
val testParquetPath = "hdfs://master:9000/data/studySet/textMining/20news-bydate/test/*"
val trainParquetPath = "hdfs://master:9000/data/studySet/textMining/20news-bydate/train/*"
val testDF: DataFrame = readParquetFile(sc,testParquetPath)//.sample(withReplacement = true,0.002)
val trainDF: DataFrame = readParquetFile(sc,trainParquetPath)//.sample(withReplacement = true,0.002)
// val pre = readParquetFile(sc,"hdfs://master:9000/data/studySet/textMining/20news-bydate/prediction2/*")
// pre.show(200)
// pre.toJavaRDD.saveAsTextFile("hdfs://master:9000/data/studySet/textMining/20news-bydate/prediction3")
//testDF.foreach(println)
//val trainDF: DataFrame = readParquetFile(sc,trainParquetPath)
//trainDF.show()
// testDF.show(5)
//testDF.take(1).foreach(println)
//[alt.atheism, answers t na translator had but determine kaflowitz ]
//use the pipeline
val tokenizer = new RegexTokenizer()
.setInputCol("doc")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
// .setNumFeatures(100000)
val naiveBayes = new NaiveBayes()
.setPredictionCol("prediction")
val decisionTree = new DecisionTreeClassifier()
.setPredictionCol("prediction")
val pipeline = new Pipeline().setStages(Array(tokenizer,hashingTF,decisionTree))
// //???????
val model = pipeline.fit(testDF)
//println(model.explainParams())
val trainPredictions = model.transform(trainDF)
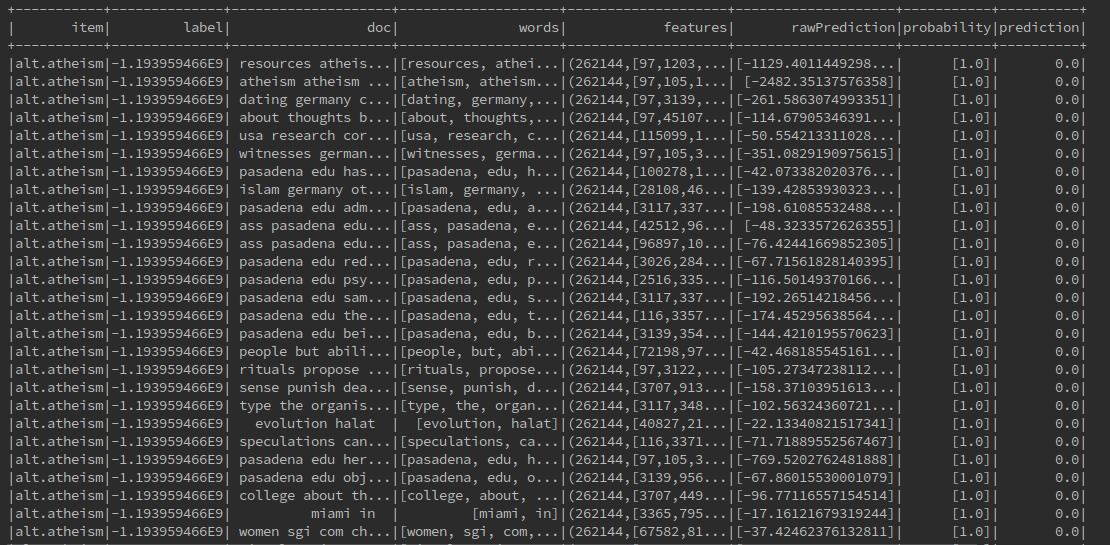
trainPredictions.show(50)
//trainPredictions.write.save("hdfs://master:9000/data/studySet/textMining/20news-bydate/prediction2")
}
}
object StringAccumulatorParam extends AccumulatorParam[String] {
override def addInPlace(r1: String, r2: String): String = add(r1,r2)
/**
* 初始化
* @param initialValue 初始值
* @return
*/
override def zero(initialValue: String): String = ""
def add(v1:String,v2:String)={
assert((!v1.isEmpty)|| (!v2.isEmpty))
v1+v2+" "
}
}
结果如下:















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









