







在linux 系统中,当有剩余内存,系统会尽可能的使用内存作为文件缓存(page cache)。文件缓存页面会加入到LRU 链表,当内存紧张,会将修改的文件缓存写入磁盘,释放缓存页面回收内存。linux 系统也会将磁盘等存储设备当做交换分区,内核将很少使用的内存换出到交换区,释放出物理内存,称之为页交换(swapping)。这些获取内存的机制统称页面回收(page reclaim)。
页表
ARM32 页表映射
使用单层段映射:
内存中有一个段映射表,4096 个表项,每个表项4B ,占用 4K *4 =16K (可以当作PGD ,地址位数[31~20] ),可以寻址1M 空间;PTE 有256 项,地址位数[19~12] ,对应空间大小 256 * 4K([11~0] 对应页4K) = 1M;
cpu 访问内存,虚拟地址高12位用于段(section)索引找到对应表项,每个表项提供12位的物理段地址,以及相应的标志位,如何读、写等标志位。这个12位物理地址和虚拟地址低20位一起得到32位物理地址。
采用页表映射,段映射表就变成一级映射表,称PGD,其表项提供的不再是物理段地址,而是二级页表的基地址;根据32 位虚拟地址的高12 位,确定PGD 一级页表的索引,确定对应的页表项,而页表项存储的是二级页表的地址,再根据32位虚拟地址的[19~12] 8 位确定在二级页表的索引,得到对应的二级页表中的页表项,这个页表项中找到20位的物理页面地址,再跟虚拟地址中低12位[11~0] 一起确定最终32 位物理地址。这个arm32中由mmu 硬件完成。
ARM64页表映射
假设页表映射层级是4,即配置CONFIG_ARM64_PGTABLE_LEVELS=4。地址宽度是48,即配置CONFIG_ARM64_VA_BITS=48,页大小4K,每个页表项占 8字节
PGD [47,39] 512*512G=256T
PUD [38,30] 512G
PMD [29,21] 512*2M = 1G
PTE [20,12] 4K/8=512 项,512*4K = 2M
PAGE_SHIFT [11~0]
当bit[63] 为1 表明是内核空间地址,页表的基地址寄存器用TTBR1_EL1 (Translation Table Base Register 1);如果为0 ,表示用户空间地址使用TTBR0 ;寄存器保存了PGD页表基地址(Table base address)
PTE 页表项含有最终的物理地址[47~12],再跟虚拟地址[11~0]合并成最终的物理地址。
内核虚拟地址起点:VA_START = 0xffff_0000_0000_0000
PAGE_OFFSET =0xffff_1000_0000_0000
PAGE_OFFSET - the virtual address of the start of the linear map (top(VA_BITS - 1))
对于48位虚拟地址,从PAGE_OFFSET 开始的往大地址的区域是线性区域,跟物理地址就是一个PHYS_OFFSET 偏差;如果不是线性区域,这个时候是 kimage_voffset 偏移;
页面回收
在linux 系统中,当有剩余内存,系统会尽可能的使用内存作为文件缓存(page cache)。文件缓存页面会加入到LRU 链表,当内存紧张,会将修改的文件缓存写入磁盘,释放缓存页面回收内存。linux 系统也会将磁盘等存储设备当做交换分区(或zram压缩),内核将很少使用的内存换出到交换区,释放出物理内存,称之为页交换(swapping)。这些获取内存的机制统称页面回收(page reclaim)。
每个zone 有一套LRU,LRU对应5个类型双向链表,分别表示匿名不活跃页面、匿名活跃页面、文件不活跃页面、文件活跃页面、不可回收页面。匿名页面总是需要写入交换区才能被换出,因此内存紧张时,优先换出page cache 页面。
参考
https://www.ngui.cc/51cto/show-723765.html?action=onClick
MM 事件 - 历史内存统计信息 | Android 开源项目 | Android Open Source Project
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask){
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
goto out;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
}
快速内存回收触发在get_page_from_freelist()函数中,在遍历zonelist的过程中,每个zone在分配内存前都会进行一次内存检查,当内存分配后zone的空闲内存小于该zone的low水线阈值和保留页框数量,这个时候该zone所在节点通过node_reclaim进行快速内存回收。
快速内存分配失败,就进入到__alloc_pages_slowpath,将水位设置为min ,并唤醒kswapd0,调用get_page_from_freelist(),如果还是失败就会__alloc_pages_direct_compact函数对内存进行压缩规整后,再进行内存分配,再次失败就会进入直接内存回收及slab 回收,最后可能触发oom killer。
LRU链表
LRU是最近最少使用,在内存不足,这些页面就会被候选换出。
kernel-4.19/include/linux/mmzone.h
206/*
207 * We do arithmetic on the LRU lists in various places in the code,
208 * so it is important to keep the active lists LRU_ACTIVE higher in
209 * the array than the corresponding inactive lists, and to keep
210 * the *_FILE lists LRU_FILE higher than the corresponding _ANON lists.
211 *
212 * This has to be kept in sync with the statistics in zone_stat_item
213 * above and the descriptions in vmstat_text in mm/vmstat.c
214 */
215#define LRU_BASE 0
216#define LRU_ACTIVE 1
217#define LRU_FILE 2
218
219enum lru_list {
220 LRU_INACTIVE_ANON = LRU_BASE,
221 LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
222 LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
223 LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
224 LRU_UNEVICTABLE,
225 NR_LRU_LISTS
226};
255struct lruvec {
256 struct list_head lists[NR_LRU_LISTS];
257 struct zone_reclaim_stat reclaim_stat;
258 /* Evictions & activations on the inactive file list */
259 atomic_long_t inactive_age;
260 /* Refaults at the time of last reclaim cycle */
261 unsigned long refaults;
262#ifdef CONFIG_MEMCG
263 struct pglist_data *pgdat;
264#endif
265};
每个zone (后面内核node)有一套LRU,LRU对应5个类型双向链表,分别表示匿名不活跃页面、匿名活跃页面、文件不活跃页面、文件活跃页面、不可回收页面。匿名页面总是需要写入交换区才能被换出,因此内存紧张时,优先换出page cache 页面,除非page cache 页面被修改了才需要写回磁盘。
LRU 链表里面添加页面
kernel-4.19/mm/swap.c
428/**
429 * lru_cache_add - add a page to a page list
430 * @page: the page to be added to the LRU.
431 *
432 * Queue the page for addition to the LRU via pagevec. The decision on whether
433 * to add the page to the [in]active [file|anon] list is deferred until the
434 * pagevec is drained. This gives a chance for the caller of lru_cache_add()
435 * have the page added to the active list using mark_page_accessed().
436 */
437void lru_cache_add(struct page *page)
438{
439 VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page);
440 VM_BUG_ON_PAGE(PageLRU(page), page);
441 __lru_cache_add(page);
442}
399static void __lru_cache_add(struct page *page)
400{
401 struct pagevec *pvec = &get_cpu_var(lru_add_pvec);
402
403 get_page(page);
404 if (!pagevec_add(pvec, page) || PageCompound(page))
405 __pagevec_lru_add(pvec);
406 put_cpu_var(lru_add_pvec);
407}
先获取pagevec 是否有空闲,如果空闲就加入pagerec,如果没有空闲就将之前加入pagevec 的页面加入lru ,将新的页面加入pagevec。
lru 使用FIFO,另外在活跃跟不活跃lru 链表间切换,不活跃lru 链表尾最可能被换出。
在lru 算法上,对即将换出的一个页面使用第二次机会算法,即根据页面PG_activi 、PG_referenced、PG_yong(硬件)再次判断是否换出。
kswapd 内核线程
kernel-4.19/mm/vmscan.c
4299static int __init kswapd_init(void)
4300{
4301 int nid, ret;
4302
4303 swap_setup();
4304 for_each_node_state(nid, N_MEMORY)
4305 kswapd_run(nid);
4306 ret = cpuhp_setup_state_nocalls(CPUHP_AP_ONLINE_DYN,
4307 "mm/vmscan:online", kswapd_cpu_online,
4308 NULL);
4309 WARN_ON(ret < 0);
4310 return 0;
4311}
4312
4313module_init(kswapd_init)
1
4262/*
4263 * This kswapd start function will be called by init and node-hot-add.
4264 * On node-hot-add, kswapd will moved to proper cpus if cpus are hot-added.
4265 */
4266int kswapd_run(int nid)
4267{
4268 pg_data_t *pgdat = NODE_DATA(nid);
4269 int ret = 0;
4270
4271 if (pgdat->kswapd)
4272 return 0;
4273
4274 pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);
4275 if (IS_ERR(pgdat->kswapd)) {
4276 /* failure at boot is fatal */
4277 BUG_ON(system_state < SYSTEM_RUNNING);
4278 pr_err("Failed to start kswapd on node %d\n", nid);
4279 ret = PTR_ERR(pgdat->kswapd);
4280 pgdat->kswapd = NULL;
4281 }
4282 return ret;
4283}
alloc_page 在分配页面失败(ALLOC_WMARK_LOW),会通过wakeup_kswapd() 唤醒kswapd ,将zone_id 和 页面2^order 传递给kswapd。kswapd 对特定node 下 zone 进行扫描,在zone free 水位达到WMARK_HIGH,就会停止扫描。
kswapd->balance_pgdat->pgdat_balanced
3815/*
3816 * For kswapd, balance_pgdat() will reclaim pages across a node from zones
3817 * that are eligible for use by the caller until at least one zone is
3818 * balanced.
3819 *
3820 * Returns the order kswapd finished reclaiming at.
3821 *
3822 * kswapd scans the zones in the highmem->normal->dma direction. It skips
3823 * zones which have free_pages > high_wmark_pages(zone), but once a zone is
3824 * found to have free_pages <= high_wmark_pages(zone), any page is that zone
3825 * or lower is eligible for reclaim until at least one usable zone is
3826 * balanced.
3827 */
3828static int balance_pgdat(pg_data_t *pgdat, int order, int classzone_idx)
3829{
3830 int i;
3831 unsigned long nr_soft_reclaimed;
3832 unsigned long nr_soft_scanned;
3833 unsigned long pflags;
3834 struct zone *zone;
3835 struct scan_control sc = {
3836 .gfp_mask = GFP_KERNEL,
3837 .order = order,
3838 .priority = DEF_PRIORITY,
3839 .may_writepage = !laptop_mode,
3840 .may_unmap = 1,
3841 .may_swap = 1,
3842 };
3843
kswapd scans the zones in the highmem->normal->dma direction
kswap 按照这个方向(buddy 系统分配方向),找到内存不平衡的zone,这里balanced_pages 平衡页面数大于zone 管理的页面managed_pages 的25% ,就认为平衡。
再从相反的方向向不平衡zone,这样避免buddy 系统分配和回收锁竞争,调用kswap_shrink_zone 进行页面回收。
最后调到shrink_zone 对lru 和 slab 交换和回收。
页面迁移和内存规整
migrate_pages 函数用于页面迁移,可以将一个进程的页面迁移到另外node 或地方,通常只对用户进程空间,修改页面映射表。
在内存低于WMARK_LOW 分配失败,就会触发kswapd,如果还不能分配出需要内存,就会触发compact_zone 对页面迁移规整;
内存规整:有两个方向扫描,一个从zone 头部向尾部zone 扫描,查找哪些是可以迁移的;另一个是从zone 尾部向zone 头部扫描,查找哪些页面是空闲的;当两个方向扫描在zone 中间碰头或者已经满足一个大块连续内存,就退出扫描。
KSM
kernel samepage merging ,将内容相同的页面合并,这样就可以多份避免冗余物理内存。ksm 允许合并通一个进程或者不同进程内容相同的页面,合并到一个自读页面,从而释放物理内存,当修改页面内容时使用copy-on-write 复制。
kernel-4.19/mm/ksm.c
3143static int __init ksm_init(void)
3144{
3145 struct task_struct *ksm_thread;
3146 int err;
3147
3148 /* The correct value depends on page size and endianness */
3149 zero_checksum = calc_checksum(ZERO_PAGE(0));
3150 /* Default to false for backwards compatibility */
3151 ksm_use_zero_pages = false;
3152
3153 err = ksm_slab_init();
3154 if (err)
3155 goto out;
3156
3157 ksm_thread = kthread_run(ksm_scan_thread, NULL, "ksmd");
3158 if (IS_ERR(ksm_thread)) {
3159 pr_err("ksm: creating kthread failed\n");
3160 err = PTR_ERR(ksm_thread);
3161 goto out_free;
3162 }
3163
3164#ifdef CONFIG_SYSFS
3165 err = sysfs_create_group(mm_kobj, &ksm_attr_group);
3166 if (err) {
3167 pr_err("ksm: register sysfs failed\n");
3168 kthread_stop(ksm_thread);
3169 goto out_free;
3170 }
3171#else
3172 ksm_run = KSM_RUN_MERGE; /* no way for user to start it */
3173
3174#endif /* CONFIG_SYSFS */
3175
3176#ifdef CONFIG_MEMORY_HOTREMOVE
3177 /* There is no significance to this priority 100 */
3178 hotplug_memory_notifier(ksm_memory_callback, 100);
3179#endif
3180 return 0;
3181
3182out_free:
3183 ksm_slab_free();
3184out:
3185 return err;
3186}
3187subsys_initcall(ksm_init);
bionic/libc/bionic/mmap.cpp
static bool kernel_has_MADV_MERGEABLE = true;
int rc = madvise(result, size, MADV_MERGEABLE);#加入ksm
madvise(result, size, MADV_UNMERGEABLE); #解除
对应匿名页面分配或者mmap 分配私有页面,通过madvise 将分配的页面加入到ksm 系统,会唤醒ksmd 内核线程。ksm 当前不考虑 page cache 。
一个典型程序可以由5 部分内存组成:
可执行文件的内存映射 (page cache)
程序分配的匿名页(如共享库)
进程打开的文件映射
进程访问文件系统产生的cache
进程访问内核产生的内核buffer (如slab)
/proc/meminfo
深入理解Linux内存管理(十)meminfo详解 - 知乎
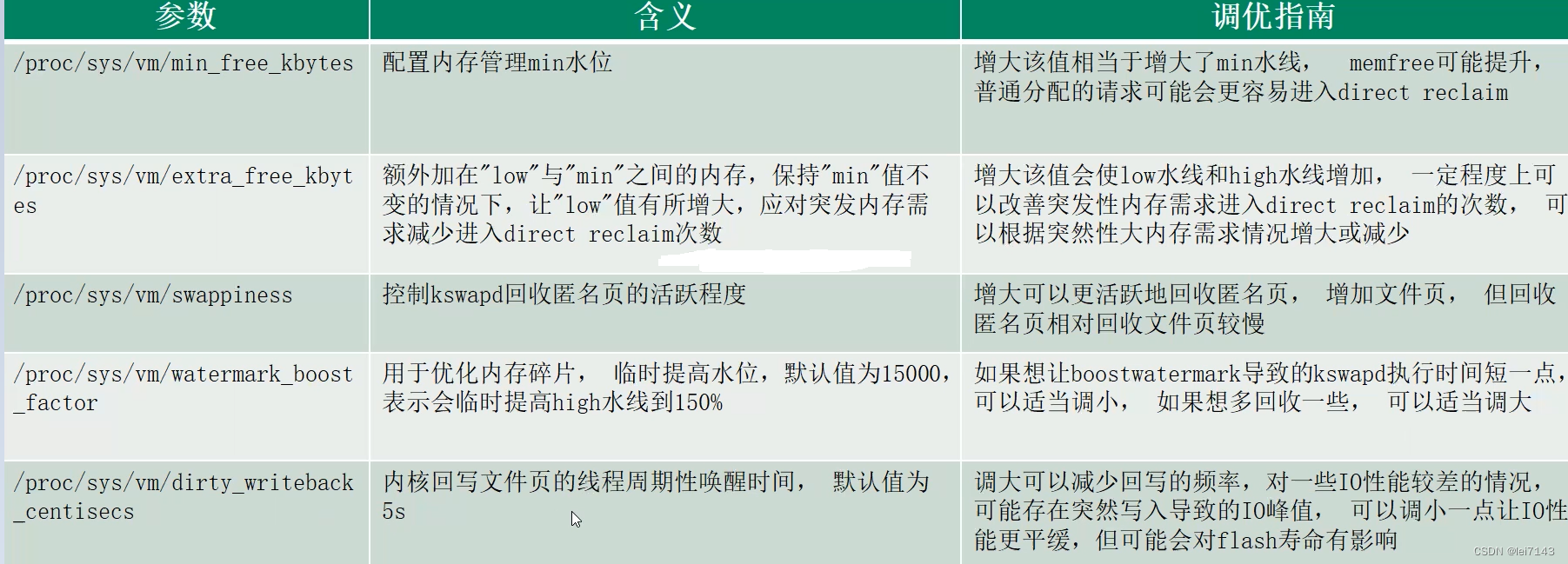
内存优化
内存分配
ION cache pool 、mempool 短时间分配次数多,分配慢,3阶内存使用vmalloc
内存碎片
kernel stack ,2阶内存,不可以移动页污染大内存快;可移动页移动耗时;
减少大内存分配次数,专用slab
内存压缩、内存回收
在一步kswapd 和 同步direct_reclaim 时会触发shrink_node 进行匿名、shmem 压缩到zram
kswapd 场景更深度的内存压缩,direct_reclaim 更快的回收,多回收文件页,kswap回收匿名也较文件页慢
文件缓存
在低内存时手机卡顿,trace 上面很多blockio 在wait_on_page_bit_common,这个时候filecache 被回收了,需要重新加载,从而文件‘颠簸’
后台查杀
zram
 深入理解Linux内存管理(十)meminfo详解 - 知乎
深入理解Linux内存管理(十)meminfo详解 - 知乎
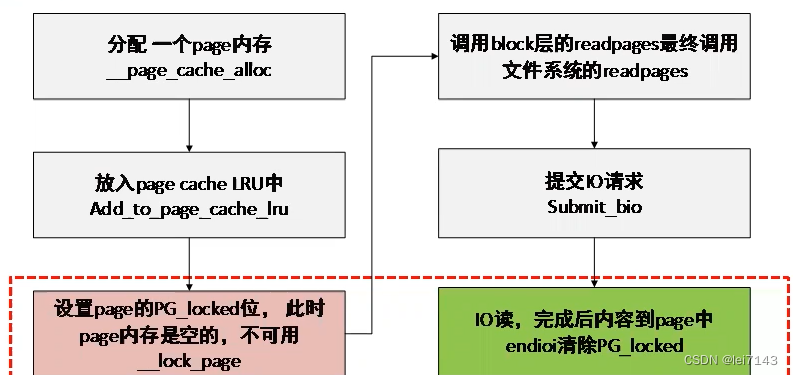
page cache
读取的文件不在内存,就需要从磁盘读入内存;
在低内存时手机卡顿,trace 上面很多blockio 在wait_on_page_bit_common,这个时候filecache 被回收了,需要重新加载,从而文件‘颠簸’
















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









