






原文地址:
https://towardsdatascience.com/pca-using-python-scikit-learn-e653f8989e60
对于许多机器学习应用程序,它有助于可视化你的数据.可视化2或3维数据并不具有挑战性.但是,即使本教程的这一部分中使用的Iris数据集也是4维的.你可以使用PCA将4维数据缩减为2维或3维,以便你可以绘制并希望更好地理解数据.
加载Iris数据集
Iris数据集是scikit-learn附带的数据集之一,不需要从某个外部网站下载任何文件.下面的代码将加载iris数据集.
#将pandas导入为pd
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
#load dataset into Pandas DataFrame
df = pd.read_csv(url,names = ['sepal length','sepal width','petal length','petal width','target'])
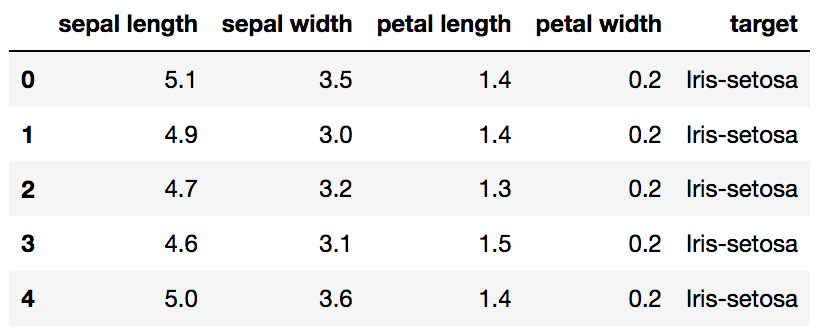
Original Pandas df (features + target)
标准化数据
PCA受比例影响,因此你需要在应用PCA之前缩放数据中的功能.使用StandardScaler可帮助你将数据集的特征标准化为单位比例(均值= 0和方差= 1),这是许多机器学习算法的最佳性能要求.如果你希望看到不会缩放数据的负面影响,scikit-learn会有一节介绍不标准化数据的效果.
#来自sklearn.preprocessing导入StandardScaler
features = ['sepal length', 'sepal width', 'petal length', 'petal width']
#分离出特征
x = df.loc[:,features].values
#分离目标
y = df.loc[:,['target']].values
#标准化特征
x = StandardScaler().fit_transform(x)
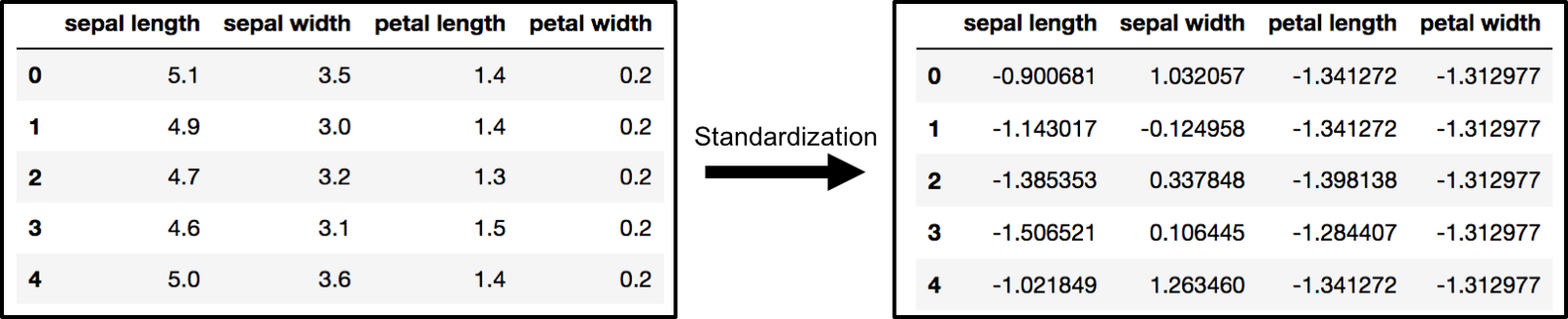
标准化之前和之后的数组x(由pandas数据帧可视化)
PCA投影到2D
原始数据有4列(萼片长度,萼片宽度,花瓣长度和花瓣宽度).在本节中,代码将4维原始数据投影到2维.我应该注意,在减少维数之后,通常没有为每个主成分分配特定含义.新组件只是变体的两个主要维度.
#来自sklearn.decomposition导入PCA
pca = PCA(n_components = 2)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data = principalComponents
,columns = ['principal component 1','principal component 2'])
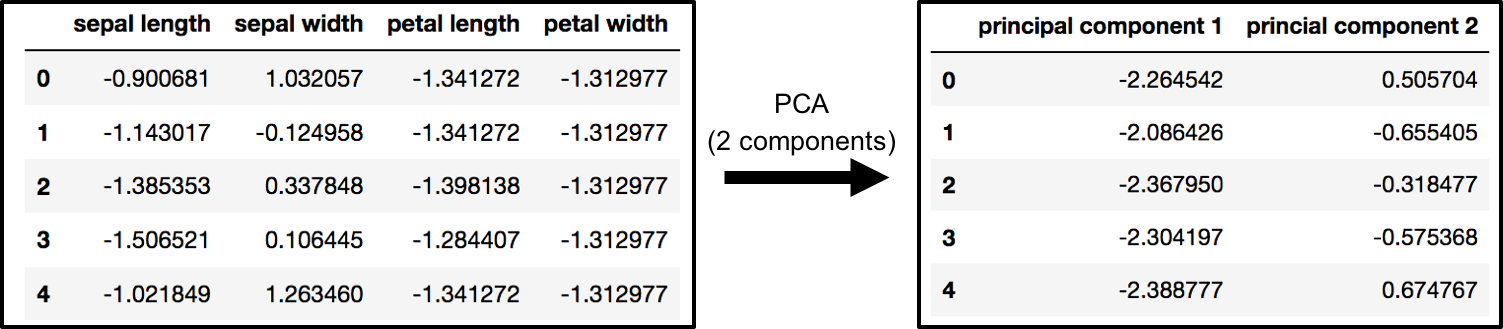
PCA并保持前两大主要组成部分
finalDf = pd.concat([principalDf,df [['target']]],axis = 1)
沿axis = 1连接DataFrame. finalDf是最终的DataFrame.

沿着列连接数据帧以在绘图之前生成finalDf
可视化2D投影
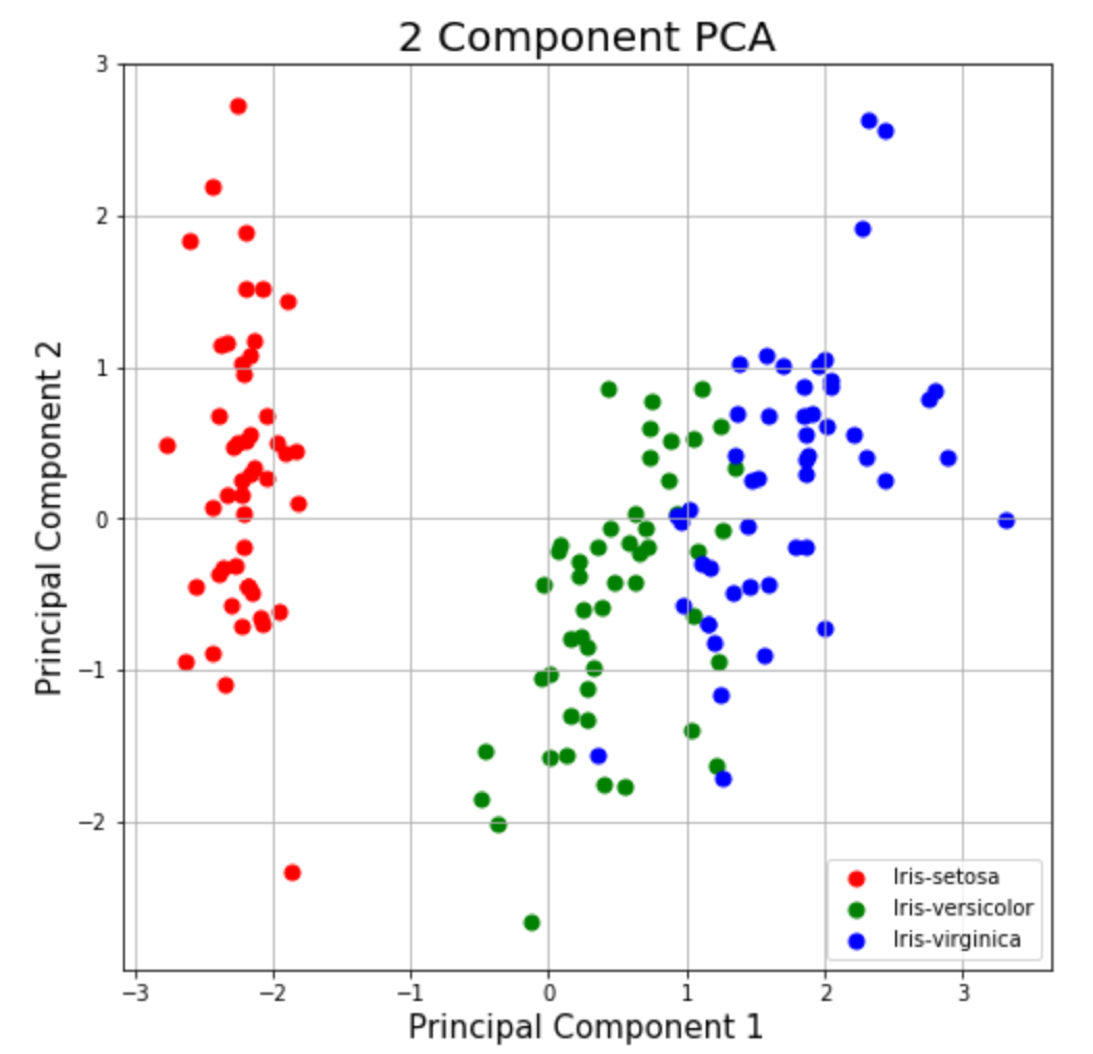
本节仅绘制二维数据.请注意下图中的类似乎彼此分开.
import matplotlib.pyplot as plt
fig = plt.figure(figsize = (8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 15)
ax.set_ylabel('Principal Component 2', fontsize = 15)
ax.set_title('2 component PCA', fontsize = 20)
targets = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
colors = ['r', 'g', 'b']
for target, color in zip(targets,colors):
indicesToKeep = finalDf['target'] == target
ax.scatter(finalDf.loc[indicesToKeep, 'principal component 1']
, finalDf.loc[indicesToKeep, 'principal component 2']
, c = color
, s = 50)
ax.legend(targets)
ax.grid()
plt.show()
解释差异
解释的方差告诉你可以将多少信息(方差)归因于每个主要组件.这很重要,因为当你可以将4维空间转换为2维空间时,在执行此操作时会丢失一些方差(信息).通过使用属性explained_variance_ratio_,可以看到的是,第一主成分含有方差的72.77%和第二主成分含有方差的23.03%.这两个组件一起包含95.80%的信息.
pca.explained_variance_ratio_















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









