







总结mapreduce运行的三种模式:
1.可以运行在本地,在单机模式情况下,输入输出文件在本地系统中;
2.运行在本地,输入输出的文件在HDFS文件系统之中(开发MapReduce时,常见的一种测试BUG的方式);
3.运行在分布式资源管理系统YARN之上,输入输出的文件存放在HDFS文件系统中。
一个Hadoop伪分布式环境中,服务组件,基本的配置:
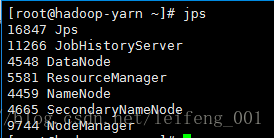
HDFS: NameNode(管理文件系统元数据)
DataNode(实际存储数据)
SecondaryNameNode(辅助NameNode进行工作)
YARN: ResourceManager(管理整个集群的资源)
NodeManager(管理每个节点的资源)
MapReduce: JobHistoryServer(管理监控MapReduce历史服务运行状态)
启动关闭各服务顺序:HDFS->YARN->MapReduce
命令:
[root@hadoop-yarn hadoop-2.6.5]# sbin/hadoop-daemon.sh start namenode/datanode/secondarynode
[root@hadoop-yarn hadoop-2.6.5]# sbin/yarn-daemon.sh start resourcemanager/nodemanager
[root@hadoop-yarn hadoop-2.6.5]# sbin/mr-jobhistory-daemon.sh start historyserver配置hdfs不检查权限
hdfs-site.xml
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>配置web监控HDFS文件系统的用户名
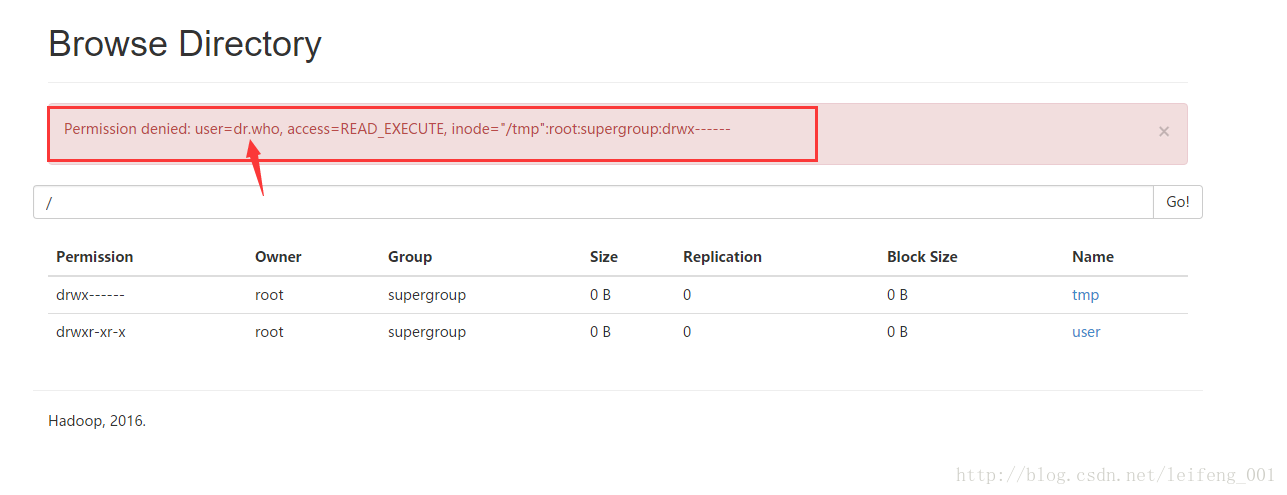
core-site.xml
<property>
<description>
The user name to filter as, on static web filters
while rendering content. An example use is the HDFS
web UI (user to be used for browsing files).
</description>
<name>hadoop.http.staticuser.user</name>
<value>dr.who</value>
</property>以在YARN上运行MapReduce应用为例:
1.当应用在YARN上运行时,每个应用都有一个Application Master进行管理和监控,通过WEB UI界面,点击APP MSTR进行监控应用运行。
2.当运行完成时(成功、失败、kill),如果是MapReduce应用的话,通过JobHistoryServer进行查看应用的运行历史状态。
可以监控:
- Node状况
- MapReduce Application状况
- Container分配















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









