







Kafka控制器Controller即Broker,是Kafka的核心组件,其主要作用是在Zookeeper的帮助下管理和协调整个Kafka集群。集群中任意一台Broker都能充当控制器的角色,但是在运行过程中,只能有一个Broker成为控制器,来执行管理和协调的职责,也就是说每个正常运转的Kafka集群,在任意时刻都有且只有一个控制器。
1、Kafka Broker之控制器机制
Kafka是依赖Zookeeper来维护集群成员的信息:Kafka使用Zookeeper的临时节点来选举Controller,Zookeeper在Broker加入集群或退出集群时通知Controller,Controller负责在Broker加入或离开集群时进行分区Leader选举。
Kafka控制器是起协调作用的组件,那么控制器的作用大致分为以下5种:
-
Topic管理
Topic管理,是指控制器帮助完成对Kafka主题的创建、删除以及分区增加的操作,大部分的后台工作都是控制器来完成的。 -
分区重分配
当一个新的broker刚加入集群时,不会自动地分担已有Topic的负载,它只会对后续新增的Topic生效。如果要让新增broker为已有的Topic服务,用户必须手动调整现有的Topic的分区分布,将一部分分区迁移到新增broker上,这就是所谓的分区重分配reassignment操作。除了处理broker扩容导致的不均衡之外,再均衡还能用于处理broker存储负载不均衡的情况,在单个或多个broker之间的日志目录之间重新分配分区,用于解决多个代理之间的存储负载不平衡。 -
Leader选举
触发分区Leader选举的几种场景:Offline,创建新分区或分区失去现有leader;Reassign,用户执行重分配操作;PreferredReplica,将Leader迁移回首选副本;
当上述几种情况发生时,控制器会遍历所有相关的主题分区并为其指定新的Leader,然后向所有包含该主题分区的broker发送更新请求,其中包含了最新的Leader与Follower副本分配信息。待更新完成后,新Leader会开始处理来自生产者和消费者的请求,而Follower开始从新Leader那里复制消息。 -
集群成员管理
集群成员管理功能主要包括自动监测新增broker、broker主动关闭及被动宕机,而这种自动监测主要是依赖于watch通知功能和Zookeeper临时节点组合实现的。 -
提供数据服务
控制器会向其他broker提供数据服务,控制器上保存了最全的集群元数据信息,其他所有broker会定期接收控制器发来的数据更新请求,从而更新其内存中的缓存数据。
控制器存储的数据大概有3类:所有topic信息,包括具体的分区信息;所有broker信息,包括当前都有哪些运行中的broker,哪些正在关闭中的broker;涉及运维任务的副本分区,包括当前正在进行PreferredLeader选举及分区重分配的分区列表等;
控制器故障转移,在Kafka集群运行过程中,只能由一台broker充当控制器角色,这就会存在单点故障的风险,为此Kafka为控制器提供故障转移功能,即Failover。故障转移是指当运行中的控制器突然宕机时,Kafka能够快速感知到,并立即启用备用控制器来代替之前失败的控制器,这个过程称为Failover,该过程是自动完成的,无需人工干预。
2、Kafka Broker之HW和LEO机制
首先这里有两个Broker,也就是两台服务器,然后他们的分区中分别存储了两个p0的副本,一个是Leader,一个是Follower,此时生产者开始往Leader Partition发送数据,数据最终写到磁盘上的,然后Follower会从Leader那里去同步数据,Follower上的数据也会写到磁盘上,可是Follower是先从Leader那去同步然后再写入磁盘的,所以它磁盘上面的数据肯定会比Leader那块少一些。
接下来了解一下日志复制中的一些重要偏移offset概念:
- 起始位移base offset:副本中所含第一条消息的offset;
- 高水位high watermark:副本最新一条已提交消息的offset;
- 日志末端位移log end offset:副本中下一条待写入消息的offset;
在Kafka中高水位HW的作用主要有两个:用来标识分区下的哪些消息是可以被消费者消费的;协助Kafka完成副本数据同步。
而LEO的一个重要作用就是用来更新HW:如果Follower和Leader的LEO数据同步了,那么HW就可以更新了,HW之前的消息数据对消费者是可见的,属于commited状态,HW之后的消息数据对消费者是不可见的。
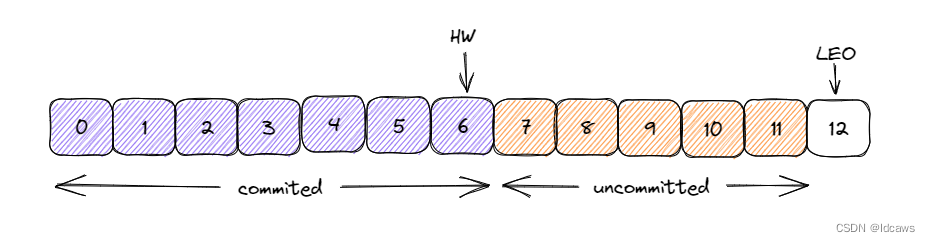
如图所示,每个副本会同时维护HW与LEO值,Leader保证只有HW及其之前的消息才对消费者可见;Follower宕机后重启时会对其日志截断,只保留HW及其之前的日志消息;对应日志末端位移LEO,它表示副本写入下一条消息的位移值;HW和LEO是副本对象的两个重要属性,Kafka使用Leader副本的HW来定义所在分区的高水位,及分区的高水位就是其Leader副本的高水位。
3、Kafka Broker之LeaderEpoch机制
数据同步依托于HW和LEO,Kafka既完美实现了消息的对外可见性,又实现了异步的副本同步机制,但Follower副本的HW更新需要一轮额外的拉取请求才能实现。
Leader副本HW更新和Follower副本HW更新在时间上是存在错配的,这种错配是很多数据丢失或数据不一致问题的根源,因此社区在0.11版本正式引入了Leader Epoch概念,来规避HW更新错配导致的各种不一致问题。
所谓Leader Epoch,大致任务是Leader版本,由两部分数据组成:
Epoch,一个单调递增的版本号,每当副本Leader权发生变更时,都会增加该版本号,小版本号的Leader被认为是过期Leader,不能再行使Leader权力;
起始位移Start Offset,Leader副本在该Epoch值写入的首条消息的位移;
Kafka Broker会在内存中每个分区都缓存Leader Epoch数据,同时它还会定期将这些信息持久化到一个checkpoint文件中。当Leader Partition写入消息到磁盘时,Broker会尝试更新这部分缓存。如果该Leader是首次写入消息,那么Broker会向缓存中增加一个Leader Epoch条目,否则就不做更新。这样,每次由Leader变更时,新的Leader副本会查询这部分缓存,取出对应的Leader Epoch的起始位移,以避免数据丢失和不一致的情况,
4、Kafka Broker之延迟任务时间轮机制
在Kafka中存在着大量的延时操作,必然延迟生产,延迟拉取,延迟删除等,这些延时操作并不是基于JDk自带的Timer或DelayQueue实现,而是基于时间轮的概念自己实现了一个延时定时器,JDK中Timer和DelayQueue的插入和删除操作的平均时间复杂度为O(nlogn),并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度将为O(1)。
Kafka中的时间轮是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表TimerTaskList,TimerTaskList是一个环形的双向链表,链表中的每个元素TimerTaskEntry封装了一个真正的定时任务TimerTask。时间轮由固定格数wheelSize的时间格组成,每一格都代表当前时间轮的基本时间跨度tickMs,整个时间轮的总体时间跨度interval就是wheeSize*tickMs。时间轮还有一个表盘指针currentTime,其值是tickMs的整数倍,用来表示时间轮当前所处的时间,表示当前需要处理的时间格对应的TimerTaskList中的所有任务。
在Kafka中引入层级时间轮的概念,当任务到期时间远远超过当前时间轮所表示的时间范围是,就会尝试添加到上层时间轮中。
后续还需继续深入理解其机制原理~















 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









