







Flink程序加载数据源(1)集合与文件
flink可以从集合以及文件中读取数据源
下面进行代码演示
首先,我们需要先获取执行环境,设置处理模式 并行度等
//准备环境 env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置自动识别数据流类型(有界(流)/无界(批))
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
(1)从集合加载数据源
// 方式一
DataStream<String> fromCollectionSource = env.fromCollection(Arrays.asList("java", "php", "scala", "c", "c++", "python", "java", "c#", "go"));
// 方式二
DataStream<String> fromElementsSource = env.fromElements("篮球", "排球", "足球", "乒乓球", "保龄球");
// 方式三 此方法是获取1-10的数据
DataStream<Long> fromSequenceSource = env.fromSequence(1L, 10L);
(2)从文件中加载数据
env.readTextFile(本地 文件、文件夹/压缩文件(目录下所有内容都会读取)、甚至HDFS等)
DataStream<String> source = env.readTextFile("E:\\aa\\flink-learn-1.12\\flink-learn-2-source\\src\\main\\java\\com\\leilei\\source\\file\\books.md");
文件内容如下:

读取结果打印:

注意点1:文件读取时一行一行进行读取的,一行内容视为一个元素
注意点2:如果指定的文件路径是一个文件夹,那么flink会读取该文件夹下所有文件中的数据(依然每一行视为一个元素)
ex:
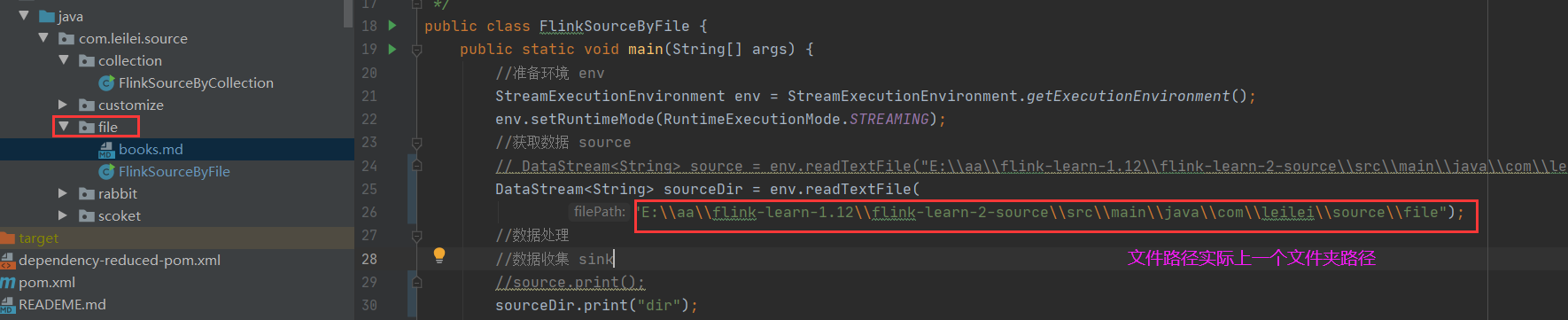
执行输出:为了执行结果更加清晰,我们给当前执行环境设置一个并行度(类似于控制线程数)
//设置环境并行度
env.setParallelism(1);
打印输出:
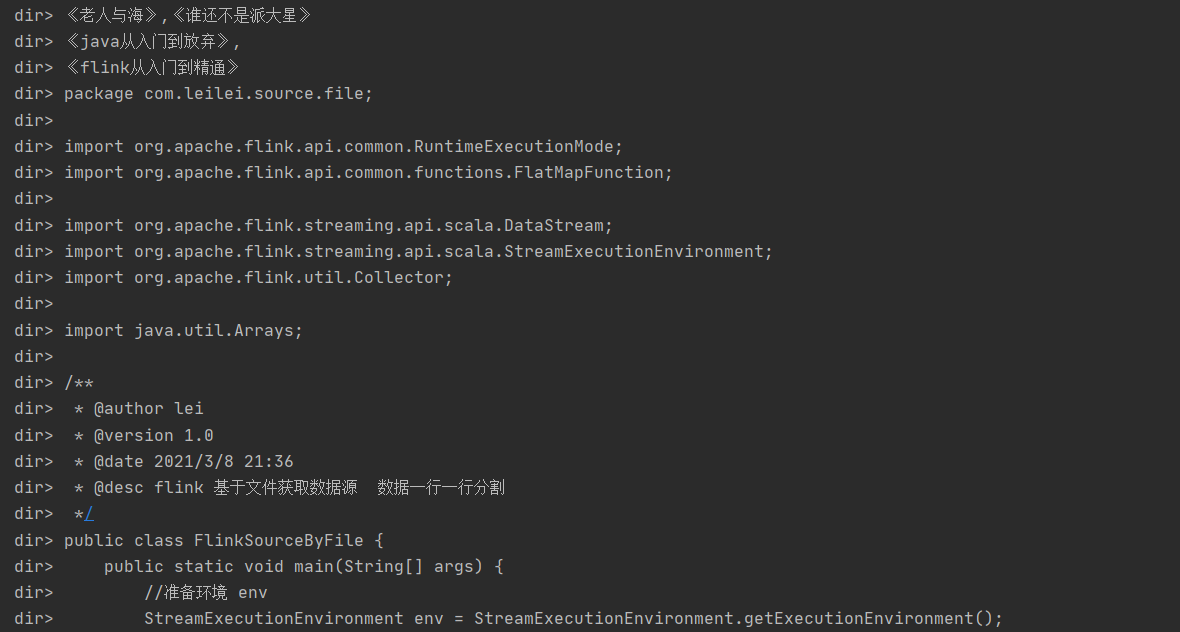
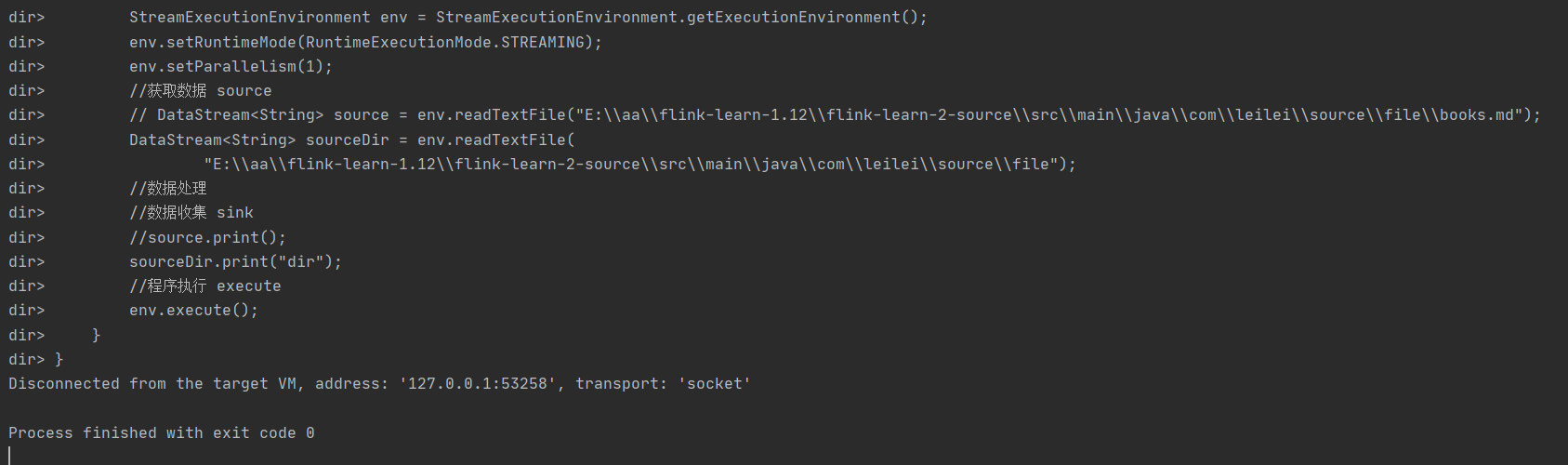















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









