







文章目录
前言

从官网中,我们可以得知,Flink是一个可针对于有限流与无限流数据做有状态计算的处理引擎。
什么叫无状态计算
计算过程不需要考虑历史数据历史结果,相同的输入得到相同的输出,每一次计算都是独立的
ex:flink中的map算子 、FlatMap算子等等
什么叫有状态计算
有状态计算就是指,我们对一个数据计算过程中,可以拿到上一次计算的结果,在上一次计算结果中进行累积或逻辑处理。
比如,计算一个小时内用户成交总金额,那么Flink在计算一个小时内的用户支付信息的时候,就需要对支付信息进行一个不断的累积,然后输出最后的计算结果。
Ex:现在一个小时内用户成交信息有五条,其中每条中金额如下
1 2 1 3 4
那么一个小时内的总金额则为1+2+1+3+4
那么,如果想要不断的数据进行累积,我们要做的便是对数据进行状态管理,因为既然要累积,那自然要找个地方存储计算结果,以便于下一个元素来到时可以取出上一次计算结果进行累加处理
这样一来,便涉及到了中间状态(上一次结果)的管理维护了!
自己设计的状态管理
(1)内存管理,使用原生java工具包 Map、List等
flink集群部署下存在问题
(2)借助第三方组件 Redis
频繁需要与Redis交互(频繁网络IO)
Flink中的有状态计算
Flink中已经对需要进行有状态计算的API,做了封装,底层已经维护好了状态!
示例
一起回到梦开始的地方=========Flink-World-Count
package com.leilei;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author lei
* @version 1.0
* @date 2021/3/7 15:51
* @desc 单词计数 DataStream 匿名内部类
*/
public class WordCountDataStream1 {
public static void main(String[] args) throws Exception {
// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.准备数据源
DataStreamSource<String> elementsSource = env.fromElements(
"java,scala,php,c++",
"java,scala,php", "java,scala", "java");
// 3.数据处理转换
KeyedStream<Tuple2<String, Integer>, String> streamResult = elementsSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String element, Collector<String> out) throws Exception {
String[] wordArr = element.split(",");
for (String word : wordArr) {
out.collect(word);
}
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = streamResult.sum(1);
// 4.数据输出
sum.print();
// 5.执行程序
env.execute("flink-hello-world");
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OH8dixra-1623161719085)(C:\Users\leile\AppData\Roaming\Typora\typora-user-images\image-20210607210126177.png)]
Flink自动为我们对数据做了状态累计, java这个词出现了4次、scala出现了三次…
为什么 Flink 知道之前已经处理过一次 java 或者scala了呢?实际上这里是state 发挥作用了,在这里,数据被称为 keyed state 存储了计算结果,当有了相同数据时,在对应结果中继续进行数据累计
Flink状态分类
Managed State & Raw State
从状态的托管类型(是否由Flink来管理)来区分,Flink分为ManagedState 和Raw State
ManagedState :
Managed State (托管状态):由 Flink Runtime 管理,自动存储,自动恢复,在内存管理上有优化,Managed State 支持已知的数据结构,如 Value、List、Map 等等,在大多数场景下均可使用
RawState:
RawState(原始状态):需要用户自己管理,需要自己序列化,Flink 不知道 State 中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构,数据结构只支持字节数组 ,所有状态都要转换为二进制字节数组;一般作用在当 Managed State 不够用时,比如需要自定义 Operator 时,才会使用 Raw State
在实际生产环境中,我们一般都是由Flink来为我们做状态管理,我们只需要测住关注自己的计算逻辑(即大多数情况下使用的是托管状态ManagedState)
Managed State 分为两种,Keyed State 和 Operator State

Keyed State(键控状态)
Keyed State基于KeyedStream(数据流使用keyBy()算子)基础上才可使用。
Keyed State由数据流中定义的每个具体的键(key) 来维护和访问,每个key维护一个状态实例,flink会将具有相同键的数据分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态(会自动将状态的访问范围限定为当前数据的key,一个key只能访问它自己的状态,不同key之间也不能互相访问) 当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key
键控状态Keyed State 数据结构:由于每个键属于 keyed operator 的一个并行实例,可将其简单地视为 <parallel-operator-instance, key>

键控状态Keyed State 数据结构:
① 值状态(ValueState),将状态表示为单个值;(直接.value获取,Set操作是.update)
- get操作: ValueState.value()
- set操作: ValueState.update(T value)
② 列表状态(ListState),将状态表示为一组数据的列表(存多个状态);(.get,.update,.add)
- ListState.add(T value)
- ListState.addAll(List values)
- ListState.get()返回Iterable
- ListState.update(List values)
③ 映射状态(MapState<K, V>),将状态表示为一组Key-Value对;(.get,.put ,类似HashMap)
- MapState.get(UK key)
- MapState.put(UK key, UV value)
- MapState.contains(UK key)
- MapState.remove(UK key)
④ 聚合状态(ReducingState & AggregatingState<I, O>),将状态表示为一个用于聚合操作的列表;(.add不像之前添加到列表,它是直接聚合到之前的结果中)
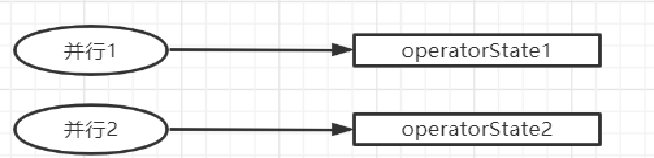
Operator State(算子状态)
作用范围限定为算子任务,同一任务状态共享(每一个并行的子任务共享一个状态),由同一并行任务所处理的所有数据都可以访问到相同的状态,算子状态不能由相同或不同算子的另一个任务访问(相同算子的不同任务之间也不能访问)
算子状态提供三种数据结构:
① 列表状态(List state),将状态表示为一组数据的列表;(会根据并行度的调整把之前的状态重新分组重新分配)
② 联合列表状态(Union list state),也将状态表示为数据的列表,它常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复(把之前的每一个状态广播到对应的每个算子中)。
③ 广播状态(Broadcast state),如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态(把同一个状态广播给所有算子子任务);















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









