







Java中的==和equals的区别
“==”操作符专门用来比较两个变量的值是否相等,也就是用于比较变量所对应的内存中所存储的数值是否相同。
equals方法是用于比较两个独立对象的内容是否相同,就好比去比较两个人的长相是否相同,它比较的两个对象是独立的。
String str1 = "hello";
String str2 = "he" + new String("llo");
System.err.println(str1==str2);
String str3 = "he" + "llo";
System.err.println(str1==str3);
System.err.println(str1.equals(str2));
System.err.println(str1.equals(str3));String str1 = “hello”;这里的str1指的是方法区的字符串常量池中的“hello”,编译时期就知道的; String str2 = “he” + new String(“llo”);这里的str2必须在运行时才知道str2是什么,所以它是指向的是堆里定义的字符串“hello”,所以这两个引用是不一样的。
如果用str1.equal(str2),那么返回的是True;因为两个字符串的内容一样。
内联函数
内联函数是使用inline关键字声明的函数,也成内嵌函数,它主要的作用是解决程序的运行效率。
使用内联函数的时候要注意:
1.递归函数不能定义为内联函数
2.内联函数一般适合于不存在while和switch等复杂的结构且只有1~5条语句的小函数上,否则编译系统将该函数视为普通函数。
3.内联函数只能先定义后使用,否则编译系统也会把它认为是普通函数。
4.对内联函数不能进行异常的接口声明。
不同数据类型对应的所占内存空间大小
32位编译器:
- char 1个字节
- char* 4个字节 (32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
- short int 2个字节
- int 4个字节
- unsigned int 4个字节
- float 4个字节
- double 8个字节
- long 4个字节
- long long 8个字节
- unsigned long 4个字节
64位编译器:
- char 1个字节
- char* 8个字节
- short int 2个字节
- int 4个字节
- unsigned int 4个字节
- float 4个字节
- double 8个字节
- long 8个字节
- long long 8个字节
- unsigned long 8个字节
在计算结构体所占空间大小的时候,要注意内存对齐。
析构函数
析构函数名与类名相同,只是在函数名前面加一个位取反符~,以区别于构造函数 。它不能带任何参数,也没有返回值(包括void类型)。只能有一个析构函数,不能重载 。如果用户没有编写析构函数,编译器 自动生成一个缺省的析构函数(即使自定义了析构函数,编译器 也总是会为我们合成一个析构函数,并且如果自定义了析构函数,编译器在执行时会先调用自定义的析构函数再调用合成的析构函数),它也不进行任何操作。所以许多简单的类中没有用显式的析构函数。
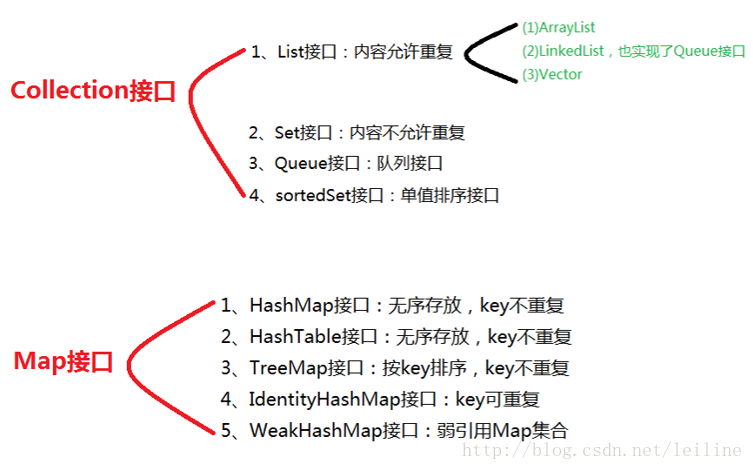
集合常考点
C++中不能重载的运算符:“ ?: ”、 “ . ”、“ :: ” 、“ sizeof ”和“.*”.
const修饰离它最近的对象
const int *x; //①
int * const x; //②1)语句,const修饰的是const,指针变量x指向整型常数,x的值可以改变,但不能试图改变指向的整型常数;
2)语句,const修饰的是x,指针变量x的值不能改变。
内存泄漏
内存泄漏也称作“存储渗漏”,用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元。直到程序结束。(其实说白了就是该内存空间使用完毕之后未回收)即所谓内存泄漏。
free释放的内存不一定直接还给操作系统,可能要到进程结束才释放。
malloc不能直接申请物理内存,它申请的是虚拟内存。
Java 中修饰符的权限
private, default, protected, public

B树
B树的定义
一棵m阶的B树满足下列条件:
- 树中每个结点至多有m个孩子。
- 除根结点和叶子结点外,其它每个结点至少有m/2个孩子。
- 根结点至少有2个孩子(如果B树只有一个结点除外)。
- 所有叶结点在同一层,B树的叶结点可以看成一种外部节点,不包含任何信息。
- 有k个关键字(关键字按递增次序排列)的非叶结点恰好有k+1个孩子。
B树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树,与红黑树很相似。
B树与红黑树最大的不同在于,B树的结点可以有多个子女,从几个到上千个。那为什么又说B树与红黑树很相似呢?因为与红黑树一样,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,应为它的分支因子比较大。所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
堆排序
二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。
当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。
堆的插入
每次插入都是将新数据放在数组最后。
可以发现从这个新数据的父结点到根结点必然为一个有序的数列,现在的任务是将这个新数据插入到这个有序数据中——这就类似于直接插入排序中将一个数据并入到有序区间中。
堆化数组
如何对一个数组进行堆化。
首先对数组按照完全二叉树的方式进行初始化。
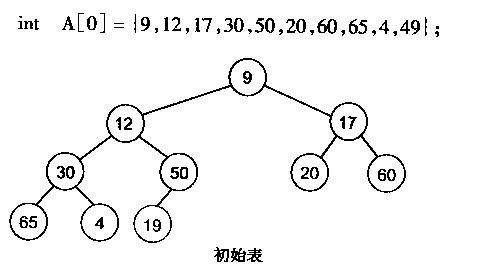
对每个子树进行变换,使每个子树都是一个堆的形式。
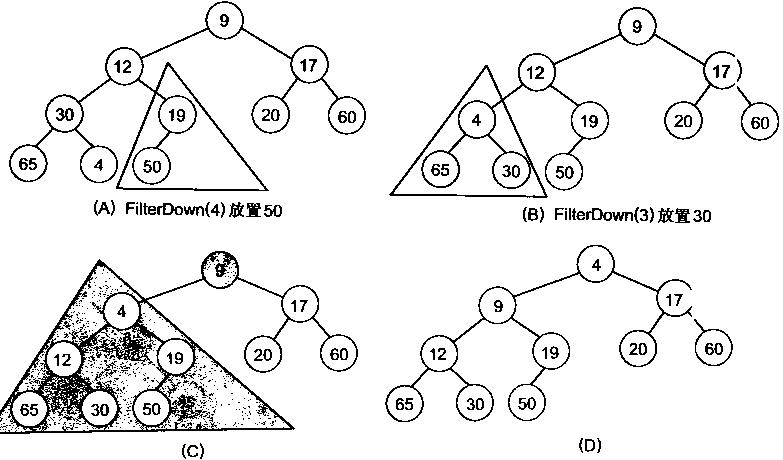
堆排序
首先可以看到堆建好之后堆中第0个数据是堆中最小的数据。取出这个数据再执行下堆的删除操作。这样堆中第0个数据又是堆中最小的数据,重复上述步骤直至堆中只有一个数据时就直接取出这个数据。
由于堆也是用数组模拟的,故堆化数组后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n - 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。
堆排序方法对记录数较少的文件并不值得提倡,但对n较大的文件还是很有效的。因为其运行时间主要耗费在建初始堆和调整建新堆时进行的反复“筛选”上。
折半查找
折半查找是一种快速查找的有序数组的方法。
public static int binarySearch(int a[], int goal){
int high=a.length-1;
int low = 0;
while(low<=high){
int middle = (low+high)/2;
if(a[middle]==goal){
return middle;
}
else if(a[middle]>goal){
high = middle-1;
} else{
low = middle+1;
}
}
return -1;
}这里要注意的是,当goal!=a[middle]的时候,low和high只有一个是变动的,如果两个都变动的话则会出现没有遍历到的情况。
用正则化来解决过拟合问题
正则化的一些概念
1)概念
L0正则化的值是模型参数中非零参数的个数。
L1正则化表示各个参数绝对值之和。
L2正则化标识各个参数的平方的和的开方值。
2)正则化后会导致参数稀疏,一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能呵呵了。另一个好处是参数变少可以使整个模型获得更好的可解释性。
且参数越小,模型就会越简单,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
3)三种正则概述
-》L0正则化
根据上面的讨论,稀疏的参数可以防止过拟合,因此用L0范数(非零参数的个数)来做正则化项是可以防止过拟合的。
从直观上看,利用非零参数的个数,可以很好的来选择特征,实现特征稀疏的效果,具体操作时选择参数非零的特征即可。但因为L0正则化很难求解,是个NP难问题,因此一般采用L1正则化。L1正则化是L0正则化的最优凸近似,比L0容易求解,并且也可以实现稀疏的效果。
-》L1正则化
L1正则化在实际中往往替代L0正则化,来防止过拟合。在江湖中也人称Lasso。
L1正则化之所以可以防止过拟合,是因为L1范数就是各个参数的绝对值相加得到的,我们前面讨论了,参数值大小和模型复杂度是成正比的。因此复杂的模型,其L1范数就大,最终导致损失函数就大,说明这个模型就不够好。
-》L2正则化
L2正则化可以防止过拟合的原因和L1正则化一样,只是形式不太一样。
L2范数是各参数的平方和再求平方根,我们让L2范数的正则项最小,可以使W的每个元素都很小,都接近于0。但与L1范数不一样的是,它不会是每个元素为0,而只是接近于0。越小的参数说明模型越简单,越简单的模型越不容易产生过拟合现象。
L2正则化江湖人称Ridge,也称“岭回归”
4)几何解释

我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解:

可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,有很大的几率等高线会和L1-ball在四个角,也就是坐标轴上相遇,坐标轴上就可以产生稀疏,因为某一维可以表示为0。而等高线与L2-ball在坐标轴上相遇的概率就比较小了。
总结:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。在所有特征中只有少数特征起重要作用的情况下,选择Lasso比较合适,因为它能自动选择特征。而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,那么使用Ridge也许更合适。
常用的降维方法
线性降维方法:PCA ICA LDA LFA LPP(LE的线性表示)
基于核函数的非线性降维方法:KPCA KICA KDA
基于特征值的非线性降维方法(流型学习):ISOMAP LLE LE LPP LTSA MVU
Java 的重载和重写
重载:
1) 方法重载是让类以统一的方式处理不同类型数据的一种手段。多个同名函数同时存在,具有不同的参数个数/类型。重载是一个类中多态性的一种表现。
2) Java的方法重载,就是在类中可以创建多个方法,它们具有相同的名字,但具有不同的参数和不同的定义。调用方法时通过传递给它们的不同参数个数和参数类型给它们的不同参数个数和参数类型给它们的不同参数个数和参数类型来决定具体使用哪个方法, 这就是多态性。
3) 重载的时候,方法名要一样,但是参数类型和个数不一样,返回值类型可以相同也可以不相同。无法以返回型别作为重载函数的区分标准。
重写:
1) 父类与子类之间的多态性,对父类的函数进行重新定义。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding)。在Java中,子类可继承父类中的方法,而不需要重新编写相同的方法。但有时子类并不想原封不动地继承父类的方法,而是想作一定的修改,这就需要采用方法的重写。方法重写又称方法覆盖。
2) 若子类中的方法与父类中的某一方法具有相同的方法名、返回类型和参数表,则新方法将覆盖原有的方法。如需父类中原有的方法,可使用super关键字,该关键字引用了当前类的父类。
3) 子类函数的访问修饰权限不能少于父类的;















 1604
1604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









