







 本文深入剖析了QEMU中VIRTIO设备的创建流程,从命令行参数到设备实例化,再到VIRTIO控制面的初始化。接着,详细阐述了VIRTIO设备如何通过VHOST-USER接口与主机进行交互,包括设备创建、控制面协商和数据面启动。最后,探讨了VHOST-USER框架设计,展示了VHOST如何接收QEMU消息并启动数据传输。
本文深入剖析了QEMU中VIRTIO设备的创建流程,从命令行参数到设备实例化,再到VIRTIO控制面的初始化。接着,详细阐述了VIRTIO设备如何通过VHOST-USER接口与主机进行交互,包括设备创建、控制面协商和数据面启动。最后,探讨了VHOST-USER框架设计,展示了VHOST如何接收QEMU消息并启动数据传输。
VIRTIO设备的前端是GUEST的内核驱动,后端由QEMU或者DPU实现。不论是原来的QEMU-VIRTIO框架还是现在的DPU,VIRTIO的控制面和数据面都是相对独立的设计。本文主要针对QEMU的VIRTIO后端进行分析。
控制面负责GUEST前端和VIRTIO设备的协商流程,主要用于前后端的feature协商匹配、向GUEST提供后端设备信息、建立前后端之间的数据通道。等控制面协商完成后,数据面启动前后端的数据交互流程;后面的流程中控制面负责一些配置信息的下发和通知,比如block设备capacity配置、net设备mac地址动态修改等。
QEMU负责设备控制面的实现,而数据面由VHOST框架接管。VHOST又分为用户态的vhost-user和内核态的vhost-kernel路径,前者是由用户态的dpdk接管数据路径,将数据从用户态OVS协议栈转发,后者是由内核态的vhost驱动接管数据路径,将数据从内核协议栈发送出去。本文主要针对vhost-user路径,以net设备为例进行描述。
一、QEMU后端驱动
如果要顺利的看懂QEMU后端VIRTIO驱动框架,需要具备QEMU的QOM基础知识,在这个基础上将数据结构、初始化流程理清楚,就可以更快的上手。如果只是对VIRTIO相关的设计感兴趣,可直接看下一章原理性的内容。
QEMU设备管理是非常重要的部分,后来引入了专门的设备树管理机制。而其参照了C++的类、继承的一些概念,但又不是完全一致,对于非科班出身的作者阅读起来有些吃力。因为框架相关的代码中时常使用内部数据指针cast的一些宏定义,非常影响可读性。
1、VIRTIO设备创建流程
从实际的命令行示例入手,查看设备是如何创建的。
1、virtio-net-pci设备命令行
首先从QEMU的命令行入手,创建一个使用virtio设备的虚拟机,可使用如下命令行:
gdb --args ./x86_64-softmmu/qemu-system-x86_64 \
-machine accel=kvm -cpu host -smp sockets=2,cores=2,threads=1 -m 3072M \
-object memory-backend-file,id=mem,size=3072M,mem-path=/dev/hugepages,share=on \
-hda /home/kvm/disk/vm0.img -mem-prealloc -numa node,memdev=mem \
-vnc 0.0.0.0:00 -monitor stdio --enable-kvm \
-netdev type=tap,id=eth0,ifname=tap30,script=no,downscript=no
-device e1000,netdev=eth0,mac=12:03:04:05:06:08 \
-chardev socket,id=char1,path=/tmp/vhostsock0,server \
-netdev type=vhost-user,id=mynet3,chardev=char1,vhostforce,queues=$QNUM
-device virtio-net-pci,netdev=mynet3,id=net1,mac=00:00:00:00:00:03,disable-legacy=on其中,创建一个虚拟硬件设备,都是通过-device来实现的,上面的命令行中创建了一个virtio-net-pci设备
-device virtio-net-pci,netdev=mynet3,id=net1,mac=00:00:00:00:00:03,disable-legacy=on这个硬件设备的构造依赖于qemu框架里的netdev设备(并不会独立的对guest呈现)
-netdev type=vhost-user,id=mynet3,chardev=char1,vhostforce,queues=$QNUM上面的netdev设备又依赖于qemu框架里的字符设备(同样不会独立的对guest呈现)
-chardev socket,id=char1,path=/tmp/vhostsock0,server2、命令行解析处理
QEMU的命令行解析在main函数进行,解析后按照qemu标准格式存储到本地。然后通过qemu_find_opts(“”)接口可以获取本地结构体中具有相应关键字的所有命令列表,对解析后的命令列表使用qemu_opts_foreach依次执行处理函数。
常用的用法,比如netdev的处理,qemu_find_opts找到所有的netdev的命令列表,qemu_opts_foreach则对列表里的所有元素依次执行net_init_netdev,初始化相应的netdev结构。
int net_init_clients(Error **errp)
{
QTAILQ_INIT(&net_clients);
if (qemu_opts_foreach(qemu_find_opts("netdev"),
net_init_netdev, NULL, errp)) {
return -1;
}
return 0;
}net_init_netdev初始化函数中,根据type=vhost-user,执行相应的net_init_vhost_user函数进行初始化,并为每个队列创建一个NetClientState结构,用于后续socket通信。
对于"-device"参数的处理也是采用同样的方式,依次执行device_init_func,初始化相应的DeviceState结构。
if (qemu_opts_foreach(qemu_find_opts("device"),
device_init_func, NULL, NULL)) {
exit(1);
}-device后跟的第一个参数qemu称为driver,其实就是根据不同的设备类型(我们的场景为“virtio-net-pci")匹配不同的处理。而device采用的是通用的设备类,根据驱动的名字在device_init_func函数里调用qdev_device_add()接口,然后匹配到相应的DeviceClass(就是virtio-net-pci对应的DeviceClass)。
匹配到DeviceClass后,调用class里的instance_init接口,创建相应的实例,即DeviceState。
备注:看到了DeviceClass和DeviceState,这个是QEMU设备管理框架里的重要元素。在QEMU设备管理框架中,
1)Class后缀表示一类方法实现,是相应设备类型的一类实现,对于同一设备类型的多个设备是通用的,不管创建几个virtio-pci-net设备,只需要一份VirtioPciClass。
2)State后缀表示具体的instance实体,每创建一个设备都要实例化一个instance结构。创建和初始化这个结构是由object_new()接口完成的,初始化还会调用相应的类定义的instance_init()接口。
Breakpoint 2, virtio_net_pci_instance_init (obj=0x5555575b8740) at hw/virtio/virtio-pci.c:3364
3364 {
(gdb) bt
#0 0x0000555555ab0c10 in virtio_net_pci_instance_init (obj=0x5555575b8740) at hw/virtio/virtio-pci.c:3364
#1 0x0000555555b270bf in object_initialize_with_type (data=data@entry=0x5555575b8740, size=<optimized out>, type=type@entry=0x5555563c3070) at qom/object.c:384
#2 0x0000555555b271e1 in object_new_with_type (type=0x5555563c3070) at qom/object.c:546
#3 0x0000555555b27385 in object_new (typename=typename@entry=0x5555563d2310 "virtio-net-pci") at qom/object.c:556
#4 0x000055555593b5c5 in qdev_device_add (opts=0x5555563d22a0, errp=errp@entry=0x7fffffffddd0) at qdev-monitor.c:625
#5 0x000055555593db17 in device_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at vl.c:2289
#6 0x0000555555c1ab6a in qemu_opts_foreach (list=<optimized out>, func=func@entry=0x55555593daf0 <device_init_func>, opaque=opaque@entry=0x0, errp=errp@entry=0x0) at util/qemu-option.c:1106
#7 0x00005555557d85d6 in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at vl.c:4593
3、设备实例初始化
在qdev_device_add函数中,首先会调用object_new,创建object(object是所有instance实例的根结构),最终是通过调用每个virtio-pci-net相应DeviceClass里的instance_init创建实例。
static void virtio_net_pci_instance_init(Object *obj)
{
VirtIONetPCI *dev = VIRTIO_NET_PCI(obj);
virtio_instance_init_common(obj, &dev->vdev, sizeof(dev->vdev),
TYPE_VIRTIO_NET);
object_property_add_alias(obj, "bootindex", OBJECT(&dev->vdev),
"bootindex");
}VirtioNetPci结构体中包含其父类的实例VirtIOPCIProxy,其拥有的设备框架自定义的结构是VirtIONet的实例。对于netdev来说,它也利用了qemu的class和device框架,但netdev不像-device一样通过框架的qdev_device_add接口调用object_new完成。他的数据空间跟随在virtio_net_pci的自定义结构里,然后通过virtio_instance_init_com接口显式的调用object_initialize()函数实现“virtio-net-device”的instance初始化。
struct VirtIONetPCI {
VirtIOPCIProxy parent_obj; //virtio-pci类<----继承pci-device<----继承device
VirtIONet vdev; //virtio-net<----继承virtio-device<----继承device
};4、virtio-net-pci设备realize流程
qdev_device_add接口中,还会调用realize接口,前面的instance_init只是实例的简单初始化,真实的设备相关的具体初始化动作都是从设备realize之后进行的。也就是相应class的realize接口。
首先在qdev_device_add()接口中,置位设备的realized属性,进而调用每一层class的realize函数。大家想一下,类似于内核驱动,设备肯定按照协议的分层从下向上识别的,先识别pci设备,然后是virtio,进而识别到virtio-net设备。所以qemu的识别过程也是这样,从最底层的realize层层调用至上层的realize接口。
参照VirtIO的Class结构,整个realize的流程整理如下:
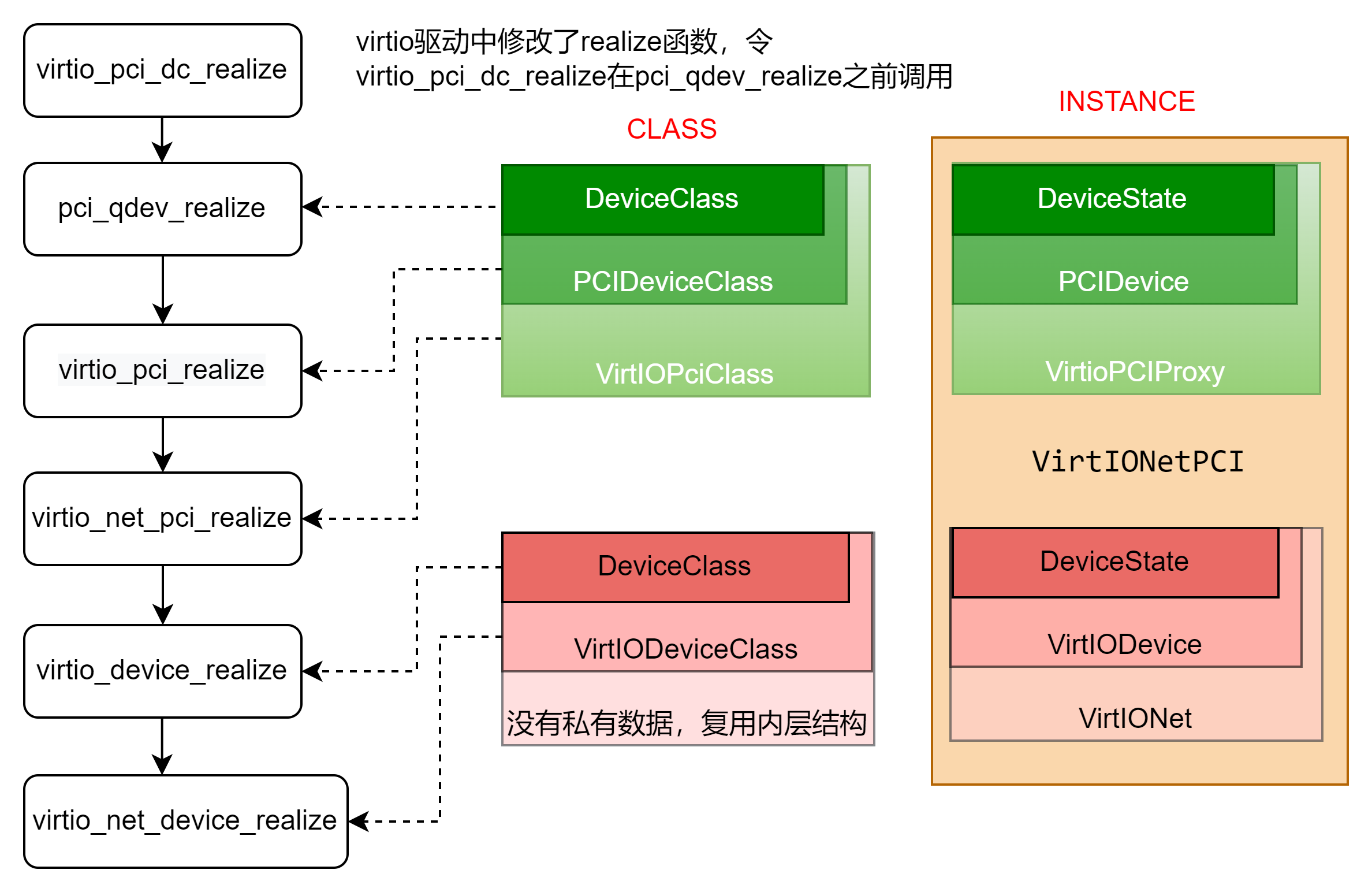
在初始化的过程中,对数据结构进行一一初始化。
在pci设备的realize之前插入virtio_pci_dc_realize函数的原因是,如果是modern模式的pci设备必须是pci-express协议,所以需要置位PCIDevice里的pcie-capability标识,强行令pci设备为pcie类型。然后再进行pci层的设备初始化,初始化一个pcie设备。
virtio_pci_realize接口对VirtioPCIProxy数据结构进行了初始化,是virtio+pci需要的初始化。所以初始化了virtio设备的bar空间以及需要的pcie-capability。
virtio_net_pci_realize接口主要是触发VirtIONet里的VirtIODevice的realize流程,这才是virtio设备的realize流程(virtio_device_realize接口)。
virtio_device_realize接口实现调用了virtio_net_device_realize,对于特定virtio设备(net类型)的初始化都是在这里进行的。所以这部分是对VirtIONet及其包裹的VirtIODevice数据结构进行初始化,包括VirtIODevice结构里的vq指针就是在这里根据队列个数动态申请空间的。
virtio_device_realize接口还执行了virtio_bus_device_plugged接口,这是virtio总线上的virtio设备的plugged接口,这部分内容脱离了virtio-pci框架,进入到更上层的virtio框架。但virtio_bus派生了virtio_pci_bus,virtio_pci_bus将继承的virtio_bus的接口都设置成了自己的接口。所以最终还是调用了virtio-pci下的virtio_pci_device_plugged函数。
virtio_pci_device_plugged接口是最核心的初始化接口,modern模式初始化pci设备的bar空间读写操作接口,因为分多块读写,所以还引入了memory_region,然后添加相应的capability;legacy模式初始化pci的bar空间读写操作接口。
至此virtio设备的初始化流程完成,等待与host的接口操作。
2、VIRTIO设备实现
上一节结合qemu的设备框架模型,分析了qemu从命令行到virtio设备创建的处理流程。现在设备创建出来了,是如何与host进行交互和操作的。本节主要讲述这部分内容,明确一点,所有的数据和操作接口都会汇聚到一个结构体,设备创建过程中的instance实例就承载了我们这个设备的所有数据和ops,所以分析这个VirtIONetPCI结构及其衍生辐射的其他数据就可以了。
struct VirtIONetPCI {
VirtIOPCIProxy parent_obj; //VIRTIO-PCI数据
VirtIONet vdev; //VIRTIO-NET数据
};对于VirtIOPCIProxy,选取比较重要的部分摘抄如下:
struct VirtIOPCIProxy {
PCIDevice pci_dev;
MemoryRegion bar;
struct {
VirtIOPCIRegion common;
VirtIOPCIRegion isr;
VirtIOPCIRegion device;
VirtIOPCIRegion notify;
};
MemoryRegion modern_bar;
MemoryRegion io_bar;
uint32_t msix_bar_idx;
bool disable_modern;
uint32_t nvectors;
uint32_t guest_features[2];
VirtIOPCIQueue vqs[VIRTIO_QUEUE_MAX];
VirtIOIRQFD *vector_irqfd;
};其实控制面主要就是用于协商操作,而这部分操作是通过bar空间的读写实现的。所以对virtio-pci来说,bar空间的读写操作接口是主线的流程,其余的数据结构都是围绕这组读写操作接口展开。
对于legacy设备,bar0用于virtio设备协商的空间。bar0在VirtIOPCIProxy中对应的是bar结构。bar0的读写接口对应virtio_pci_config_ops。
memory_region_init_io(&proxy->bar, OBJECT(proxy),
&virtio_pci_config_ops,
proxy, "virtio-pci", size);
static const MemoryRegionOps virtio_pci_config_ops = {
.read = virtio_pci_config_read,
.write = virtio_pci_config_write,
.impl = {
.min_access_size = 1,
.max_access_size = 4,
},
.endianness = DEVICE_LITTLE_ENDIAN,
};对于modern设备,采用了更灵活的方式,将virtio设备协商的空间分成4个(common、isr、device、notify)区间,每个区间的bar index和bar内offset由pci设备的capability指定。VIRTIO前端驱动解析capability识别不同的区间,进而与设备同步地址区间。
memory_region_init_io(&proxy->common.mr, OBJECT(proxy),
&common_ops,
proxy,
"virtio-pci-common",
proxy->common.size);
memory_region_init_io(&proxy->isr.mr, OBJECT(proxy),
&isr_ops,
proxy,
"virtio-pci-isr",
proxy->isr.size);
memory_region_init_io(&proxy->device.mr, OBJECT(proxy),
&device_ops,
virtio_bus_get_device(&proxy->bus),
"virtio-pci-device",
proxy->device.size);
memory_region_init_io(&proxy->notify.mr, OBJECT(proxy),
¬ify_ops,
virtio_bus_get_device(&proxy->bus),
"virtio-pci-notify",
proxy->notify.size);如上述代码所示,common区间、isr区间、device区间、notify区间的操作接口分别是common_ops、isr_ops、device_ops、notify_ops。
注册完上述ops后,GUEST对设备的bar空间进行访问,会进入相应的操作接口。
VIRTIO控制面的初始化流程具体可以参见协议或者作者其他文章,文中主要是对代码的实现框架梳理,摘抄legacy模式的write接口部分内容示例说明。后端设备根据前端驱动写入的地址和数据进行相应的处理。
static void virtio_ioport_write(void *opaque, uint32_t addr, uint32_t val)
{
VirtIOPCIProxy *proxy = opaque;
VirtIODevice *vdev = virtio_bus_get_device(&proxy->bus);
hwaddr pa;
switch (addr) {
case VIRTIO_PCI_GUEST_FEATURES:
/* Guest does not negotiate properly? We have to assume nothing. */
if (val & (1 << VIRTIO_F_BAD_FEATURE)) {
val = virtio_bus_get_vdev_bad_features(&proxy->bus);
}
virtio_set_features(vdev, val);
break;
case VIRTIO_PCI_QUEUE_PFN:
pa = (hwaddr)val << VIRTIO_PCI_QUEUE_ADDR_SHIFT;
if (pa == 0) {
virtio_pci_reset(DEVICE(proxy));
}
else
virtio_queue_set_addr(vdev, vdev->queue_sel, pa);
break;
case VIRTIO_PCI_QUEUE_NOTIFY:
if (val < VIRTIO_QUEUE_MAX) {
virtio_queue_notify(vdev, val);
}
break;
case VIRTIO_PCI_STATUS:
if (!(val & VIRTIO_CONFIG_S_DRIVER_OK)) {
virtio_pci_stop_ioeventfd(proxy);
}
virtio_set_status(vdev, val & 0xFF);
if (val & VIRTIO_CONFIG_S_DRIVER_OK) {
virtio_pci_start_ioeventfd(proxy);
}
if (vdev->status == 0) {
virtio_pci_reset(DEVICE(proxy));
}
break;
default:
error_report("%s: unexpected address 0x%x value 0x%x",
__func__, addr, val);
break;
}
}VIRTIO_PCI_QUEUE_PFN字段是写入queue地址的,对于legacy模式,avail/used ring以及descriptor的空间连续,所以传入连续空间的首地址即可,实际传入的是页帧号。virtio_queue_set_addr接口负责将前端驱动传入的GPA记录到VirtioDevice->vq结构。
重点关注一下VIRTIO_PCI_STATUS,该位置置位VIRTIO_CONFIG_S_DRIVER_OK,说明前端驱动操作完成,可启动virtio-net设备的数据面操作。所以这个位置很重要,在virtio_set_status()接口中,会启动数据面的一系列操作,包括对VHOST的配置也是由这里触发。
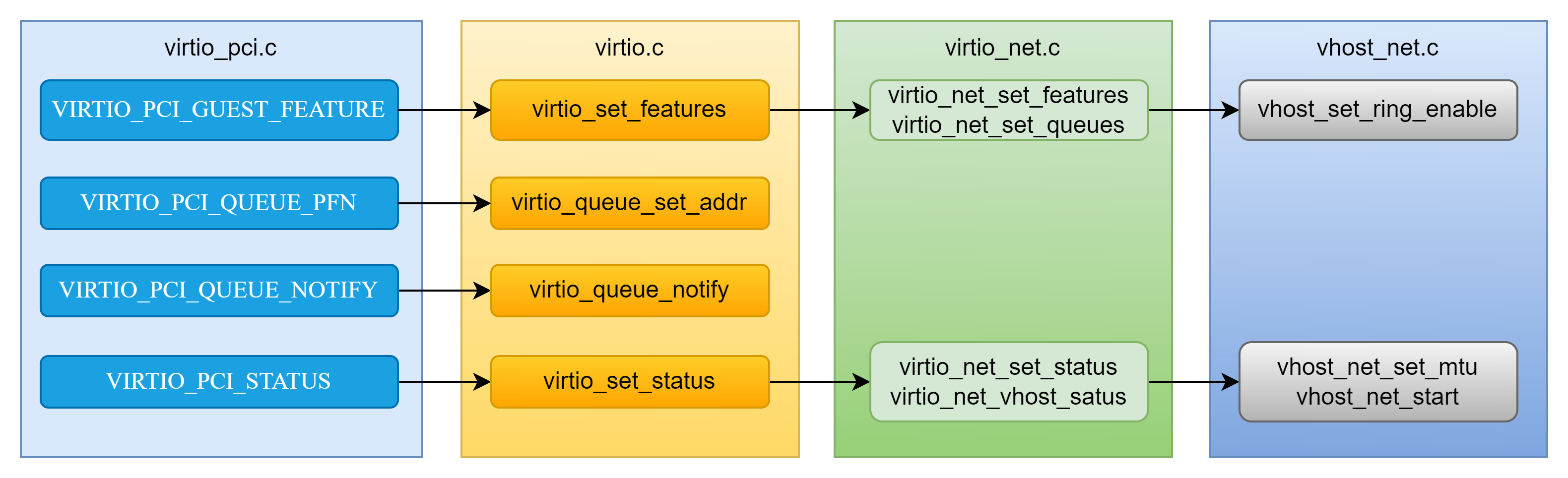
上图中就是从pcie---->virtio---->virtio-net----->vhost_net的调用关系。在设备初始化完成后,后续的操作都是由guest操作bar空间来触发,尤其是流程的推动都是对bar空间的写操作触发的。比如VIRTIO_COFNIG_S_DRIVER_OK的写入。
二、QEMU与VHOST接口描述
前一节末尾已经看到了pci-->virtio--->virtio-net---->vhost_net的调用关系。本节首先对QEMU里VHOST的部分进行介绍。
1、vhost-user类型netdev设备创建
上一章描述了virtio-net-pci设备的创建过程,本节就不再对设备的创建流程进行详细分析。在1.1节我们知道指定vhost设备的命令行如下,是根据type=vhost-user定义:
-netdev type=vhost-user,id=mynet3,chardev=char1,vhostforce,queues=$QNUM设备的命令行处理流程是统一的,也是在main函数里首先会解析命令行参数到本地的数组,然后进入标准的设备创建流程(具体可见1.2节):
if (qemu_opts_foreach(qemu_find_opts("netdev"),
net_init_netdev, NULL, errp)) {
return -1;
}所以netdev的设备创建入口就是net_init_netdev函数,在net_init_netdev函数里,根据type=vhost-user类型,执行net_init_vhost_user()接口创建设备。
该接口首先执行net_vhost_claim_chardev(),匹配其依赖的chardev,也就是命令行中的char1,找到相应的Chardev*设备。
然后调用net_vhost_user_init()接口进行真实的初始化操作。最终,vhost-user类型的netdev设备生成的结构实体是什么呢?
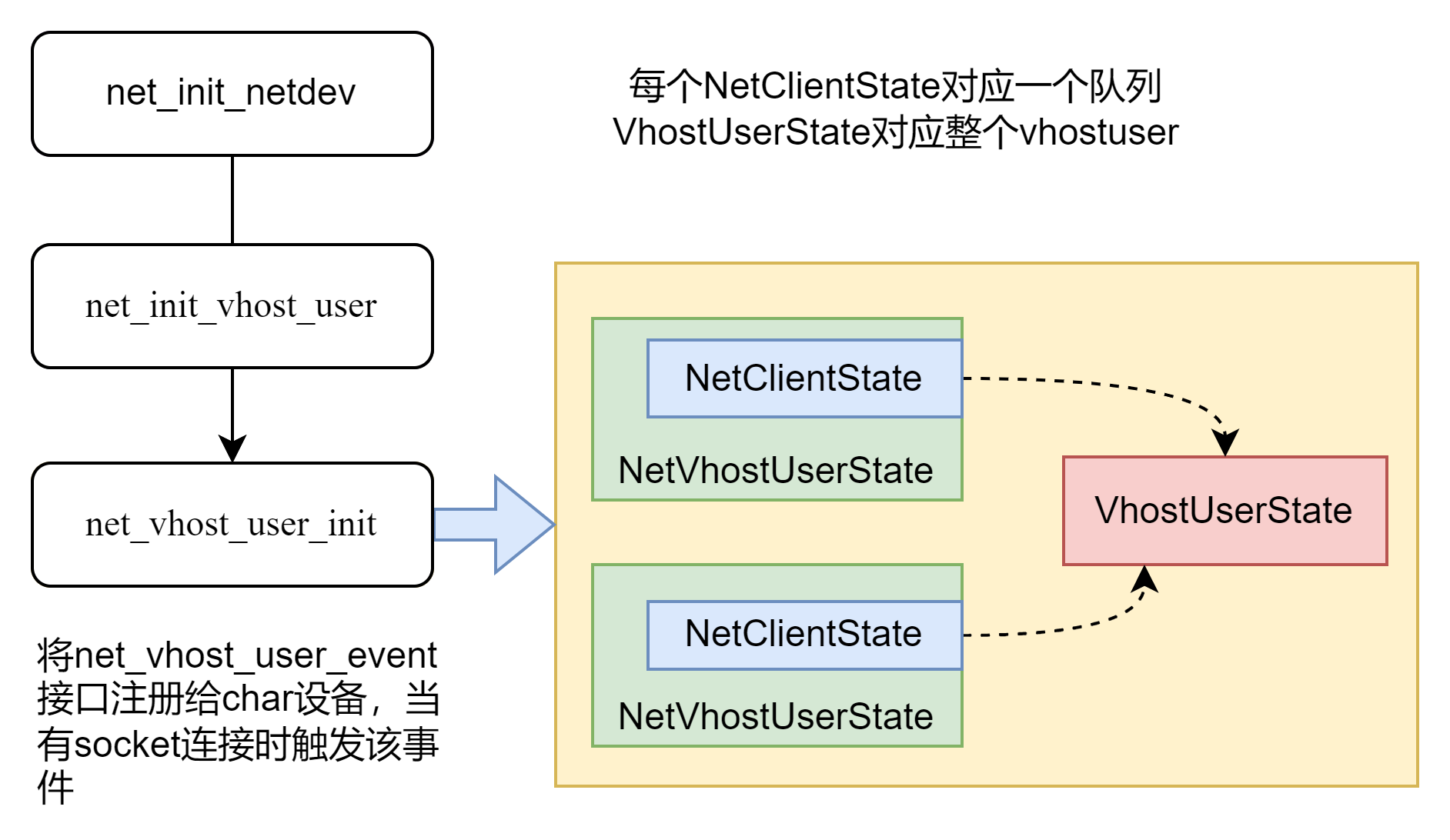
最终NetClientState被挂载到了全局变量net_clients链表中。另外,还有一组数据结构是在检测到vhost后端socket连接之后创建的。socket连接之后会调用上图中的事件处理函数net_vhost_user_event,进而调用vhost_user_start()接口。
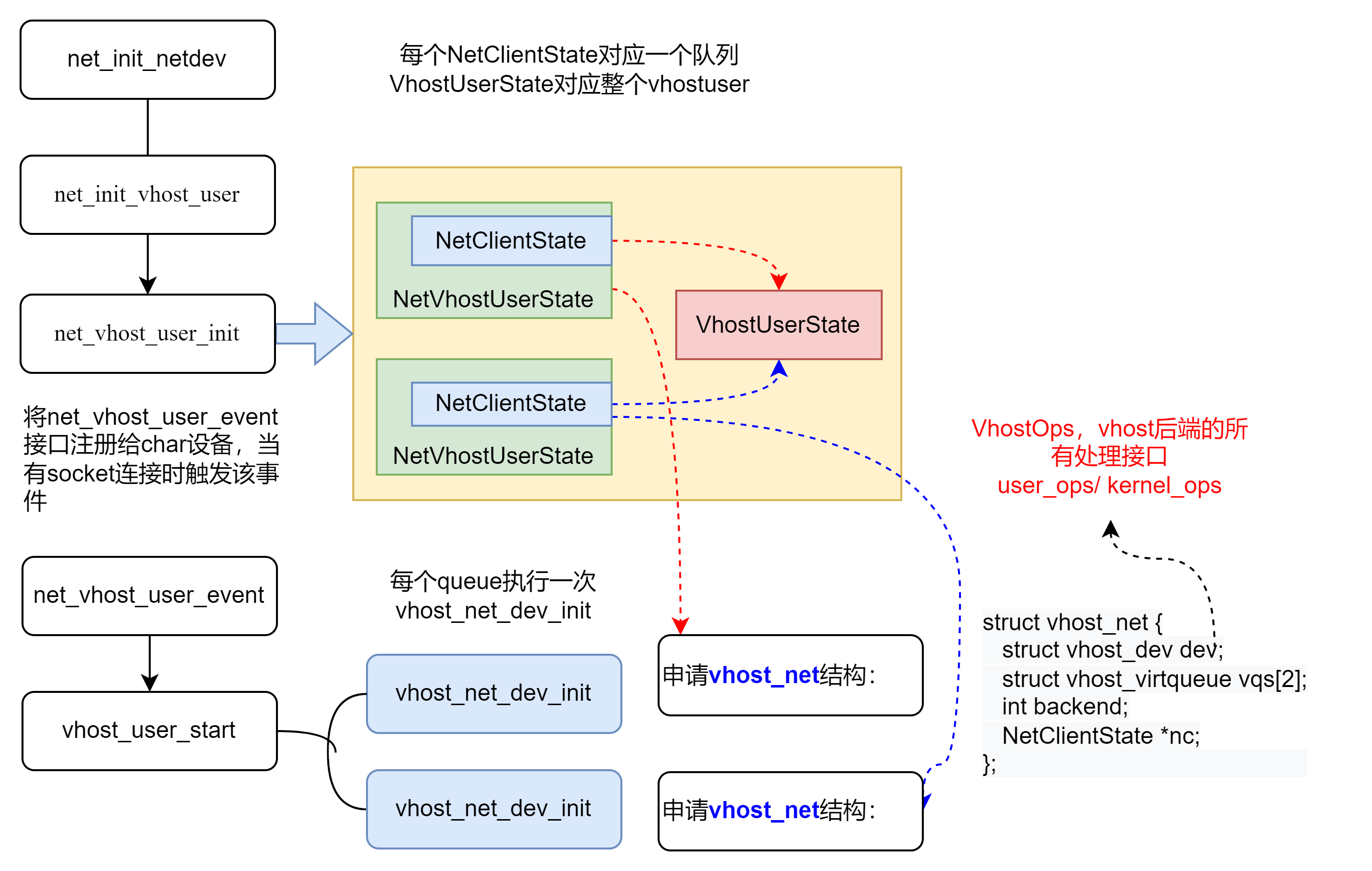
上面就是vhost-user的net设备申请的数据结构和框架,其中vhost_net中vhost_dev结构有一个重要的vhost_ops指针,对后端的接口都在这里。前面提到过vhost的后端有用户态和内核态两种,所以VhostOps的实现也有两种,因为我们指定了vhost_user类型的后端,实际vhost_ops会初始化为user_ops。VhostOps是与后端类型相关的不同的处理方式。
2、QEMU与VHOST通信
qemu与vhost的通信是通过socket的方式。具体的实现都在vhost-user的backend接口里,以VhostOps的封装形式提供给virtio_net层使用。
1、通信接口
上一章最后提到,VIRTIO_PCI_STATUS标识控制面协商的状态,当VIRTIO_CONFIG_S_DRIVER_OK置位时,说明控制面协商完成,此时启动数据面的传输。所以VHOST层面的交互是从这个状态启动的。而该状态通过virtio_set_status()接口调用到virtio_net_set_status()和virtio_net_vhost_status(),判断是第一次VIRTIO_CONFIG_S_DRIVER_OK标识置位,则此时认为需要启动数据面了,会调用vhost_net_start()接口启动与VHOST后端的交互,对于数据面来说,最主要的是队列相关的信息。如下图示。
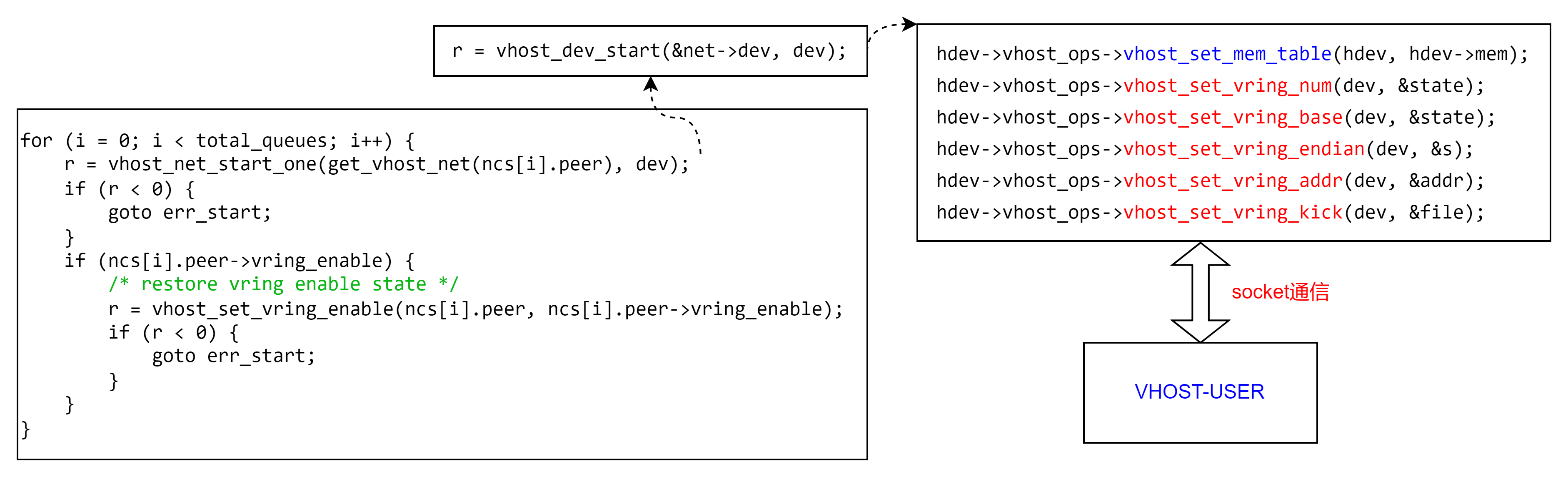
其实VhostOps里的每个接口根据名字都可以直观的推断出实现的作用,比如
vhost_set_vring_num是设置队列的大小,
vhost_set_vring_addr是设置ring的基地址(GPA),
vhost_set_vring_base设置last_avail_index,
vhost_set_vring_kick是设置队列kick需要的eventfd信息。
这里重点说一下vhost_set_mem_table接口,我们知道qemu里获取的guest的地址都是GUEST地址空间的,一般是GPA,那么qemu在创建虚拟机的时候是知道GPA到HVA的映射关系的,所以根据GPA可以轻松获得HVA,进而操作进程地址空间的VA即可。但作为独立的进程,VHOST-USER拥有独立的地址空间,是不可以使用QEMU进程的VA的。所以QEMU需要将自己记录的一组或多组[GPA,HVA,size,memfd]通知给VHOST-USER。VHOST_USER收到这几个信息后将这片内存空间通过mmap映射到本地进程的地址空间,然后一并记录到记录到本地的memory table。
mmap_addr = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE,
MAP_SHARED | populate, reg->fd, 0);对于为何可以使用qemu里的文件句柄fd,具体原理没有深究,看起来内核是允许这样一种共想文件句柄的方式的。注意需要在qemu的命令行里指定memory share=on的方式就可以。
-object memory-backend-file,id=mem,size=3072M,mem-path=/dev/hugepages,share=on等后续接收到vring address的配置时,VHOST-USER就通过传入的GPA,查表找到memory table里的表项,获取自有进程空间的VA,就可以访问真实的地址空间了。
2、数据通信格式
具体的数据通信格式来说,QEMU与VHOST-USER的消息通过socket的方式,QEMU和VHOST-USER一个作为client,另一个作为server。socket文件路径是在qemu命令行里传入的。
数据通信的格式是固定的,都是一个标准的header后面跟着payload。
typedef struct {
VhostUserRequest request;
uint32_t flags;
uint32_t size; /* the following payload size */
} QEMU_PACKED VhostUserHeader;
typedef union {
uint64_t u64;
struct vhost_vring_state state;
struct vhost_vring_addr addr;
VhostUserMemory memory;
VhostUserLog log;
struct vhost_iotlb_msg iotlb;
VhostUserConfig config;
VhostUserCryptoSession session;
VhostUserVringArea area;
} VhostUserPayload;
typedef struct VhostUserMsg {
VhostUserHeader hdr;
VhostUserPayload payload;
} QEMU_PACKED VhostUserMsg;其中request字段是一个union类型,标识具体的命令类型,所有的命令类型见下图。
typedef enum VhostUserRequest {
VHOST_USER_NONE = 0,
VHOST_USER_GET_FEATURES = 1,
VHOST_USER_SET_FEATURES = 2,
VHOST_USER_SET_OWNER = 3,
VHOST_USER_RESET_OWNER = 4,
VHOST_USER_SET_MEM_TABLE = 5,
VHOST_USER_SET_LOG_BASE = 6,
VHOST_USER_SET_LOG_FD = 7,
VHOST_USER_SET_VRING_NUM = 8,
VHOST_USER_SET_VRING_ADDR = 9,
VHOST_USER_SET_VRING_BASE = 10,
VHOST_USER_GET_VRING_BASE = 11,
VHOST_USER_SET_VRING_KICK = 12,
VHOST_USER_SET_VRING_CALL = 13,
VHOST_USER_SET_VRING_ERR = 14,
VHOST_USER_GET_PROTOCOL_FEATURES = 15,
VHOST_USER_SET_PROTOCOL_FEATURES = 16,
VHOST_USER_GET_QUEUE_NUM = 17,
VHOST_USER_SET_VRING_ENABLE = 18,
VHOST_USER_SEND_RARP = 19,
VHOST_USER_NET_SET_MTU = 20,
VHOST_USER_SET_SLAVE_REQ_FD = 21,
VHOST_USER_IOTLB_MSG = 22,
VHOST_USER_SET_VRING_ENDIAN = 23,
VHOST_USER_GET_CONFIG = 24,
VHOST_USER_SET_CONFIG = 25,
VHOST_USER_CREATE_CRYPTO_SESSION = 26,
VHOST_USER_CLOSE_CRYPTO_SESSION = 27,
VHOST_USER_POSTCOPY_ADVISE = 28,
VHOST_USER_POSTCOPY_LISTEN = 29,
VHOST_USER_POSTCOPY_END = 30,
VHOST_USER_MAX
} VhostUserRequest;三、VHOST-USER框架设计
VHOST-USER是DPDK一个重要的功能,主要的代码在lib/librte_vhost下。
VHOST的框架还是比较直接的,整体看起来DPDK的代码框架比QEMU的简洁很多,更加容易理解。DPDK主要是作为一个接口库使用,所以lib下面也是对外提供操作接口,供调用方使用。
1、VHOST初始化流程
VHOST模块初始化流程的关键接口有三个:
1、rte_vhost_driver_register(const char *path, uint64_t flags)
1)申请并初始化vhost_user_socket结构,vsocket指针存入全局数组vhost_user.vsockets[]中;
2)打开path对应的socket文件,fd存入vsocket->socket_fd中。
2、rte_vhost_driver_callback_register(const char *path, struct vhost_device_ops const * const ops)
1)注册vhost_device_ops到vsocket->ops中。
3、rte_vhost_driver_start(const char *path)
根据VHOST是client或者server,选择vhost_user_start_client()/vhost_user_start_server()两种路径,看一下vhost作为client的路径。vhost_user_start_client():
1)vhost_user_connect_nonblock,连接socket;
2)vhost_user_add_connection(int fd, struct vhost_user_socket *vsocket)
a、申请vhost_user_connection结构体;
b、申请virtio_net结构体,存储到全局数组vhost_devices,返回其在数组中的索引vid;
c、conn配置,conn->fd =fd; conn->vsocket=vsocket; conn->vid =vid;
d、注册socket接口的处理函数
fdset_add(&vhost_user.fdset, fd, vhost_user_read_cb, NULL, conn);
整个初始化流程到这里就结束了,后面就开始等待qemu的消息,对应的消息处理函数就是vhost_user_read_cb函数。
2、VHOST与QEMU通信流程
初始化流程创建了vsocket结构(与qemu的socket实体),创建了virtio_net结构(设备实体),并注册了socket消息的处理函数,后面就可以监听socket的信息,作为qemu的后端完善和建立整个流程。作为virtio设备的backend,vhost在初始化完成后,所有的动作都是由前端的socket消息触发的。
所有的消息处理函数以MSG的request请求类型字段作为索引,记录在vhost_message_handlers数组中。具体的处理不详细描述,主要就是将接收到的信息记录到本地,供数据面启动后使用。
本文贴一篇实际的VHOST和QEMU通信的数据流日志,1queue pair。
VHOST_CONFIG: /tmp/vhostsock0: connected
VHOST_CONFIG: new device, handle is 0
VHOST_CONFIG: read message VHOST_USER_GET_FEATURES
VHOST_CONFIG: read message VHOST_USER_GET_PROTOCOL_FEATURES
VHOST_CONFIG: read message VHOST_USER_SET_PROTOCOL_FEATURES
VHOST_CONFIG: negotiated Vhost-user protocol features: 0xcbf
VHOST_CONFIG: read message VHOST_USER_GET_QUEUE_NUM
VHOST_CONFIG: read message VHOST_USER_SET_SLAVE_REQ_FD
VHOST_CONFIG: read message VHOST_USER_SET_OWNER
VHOST_CONFIG: read message VHOST_USER_GET_FEATURES
VHOST_CONFIG: read message VHOST_USER_SET_VRING_CALL
VHOST_CONFIG: vring call idx:0 file:53
VHOST_CONFIG: read message VHOST_USER_SET_VRING_CALL
VHOST_CONFIG: vring call idx:1 file:54
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 0
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 1
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 0
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 1
VHOST_CONFIG: read message VHOST_USER_SET_FEATURES
VHOST_CONFIG: negotiated Virtio features: 0x140408002
VHOST_CONFIG: read message VHOST_USER_SET_MEM_TABLE
VHOST_CONFIG: guest memory region 0, size: 0xc0000000
guest physical addr: 0x0
guest virtual addr: 0x7fff00000000
host virtual addr: 0x2aaac0000000
mmap addr : 0x2aaac0000000
mmap size : 0xc0000000
mmap align: 0x40000000
mmap off : 0x0
VHOST_CONFIG: read message VHOST_USER_SET_VRING_NUM
VHOST_CONFIG: read message VHOST_USER_SET_VRING_BASE
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ADDR
VHOST_CONFIG: reallocate vq from 0 to 1 node
VHOST_CONFIG: reallocate dev from 0 to 1 node
VHOST_CONFIG: read message VHOST_USER_SET_VRING_KICK
VHOST_CONFIG: vring kick idx:0 file:56
VHOST_CONFIG: read message VHOST_USER_SET_VRING_CALL
VHOST_CONFIG: vring call idx:0 file:57
VHOST_CONFIG: read message VHOST_USER_SET_VRING_NUM
VHOST_CONFIG: read message VHOST_USER_SET_VRING_BASE
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ADDR
VHOST_CONFIG: reallocate vq from 0 to 1 node
VHOST_CONFIG: read message VHOST_USER_SET_VRING_KICK
VHOST_CONFIG: vring kick idx:1 file:53
VHOST_CONFIG: virtio is now ready for processing.
VHOST_DATA: (0) device has been added to data core 1
VHOST_CONFIG: read message VHOST_USER_SET_VRING_CALL
VHOST_CONFIG: vring call idx:1 file:58
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 0
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 1
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 0
VHOST_CONFIG: read message VHOST_USER_SET_VRING_ENABLE
VHOST_CONFIG: set queue enable: 1 to qp idx: 1
VHOST_DATA: liufeng TX virtio_dev_tx_split: dev(0) queue_id(1), soc_queue(1)
从上面的日志中找到一条消息“virtio is now ready for processing”,说明从这里开始VHOST启动数据面的收发。查看上面的日志,是在两个队列的地址信息配置完成之后。对应到QEMU的流程,就是QEMU里的VIRTIO设备device_status的VIRTIO_CONFIG_S_DRIVER_OK状态标志置位时,调用virtio_net_start()接口做了这个动作。
至此,整个数据通道完全建立。
一般的使用场景是在OVS添加一个端口,关联到刚刚分析的VHOST-USER(指定与qemu的socket-path),实现对GUEST网口的数据收发。VHOST-USER作为client的场景,可以使用如下的命令行建立一个端口。
ovs-vsctl add-port br0 vhost-client-1 \
-- set Interface vhost-client-1 type=dpdkvhostuserclient \
options:vhost-server-path=$VHOST_USER_SOCKET_PATH

















 2242
2242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









