







由于小甲鱼最新版python已更新至函数,且新版的逻辑脉络更清晰,课后测试习题使用新版试题
字符串的各种方法大合集 https://fishc.com.cn/thread-183975-1-3.html
第027讲:字符串(I)| 课后测试题及答案
- 大小写字母换来换去
capitalize()、casefold()、title()、swapcase()、upper()、lower() - 左中右对齐
center(width, fillchar=’ ‘)、ljust(width, fillchar=’ ‘)、rjust(width, fillchar=’ ')、zfill(width)
问答题:
0. casefold() 和 lower() 两个方法都是将所有的字母变成小写,那它们有什么区别呢?
根据官方文档的提示,lower() 只能处理英文字母,而 casefold() 除了英语外,还可以处理更多其他语言的字符,比如德语……
1. 请问下面代码执行的结果是?
>>> "-520".zfill(10)
-000000520
2. 请问 “-520”.zfill(10) 和 “-520”.rjust(10, “0”) 的执行结果一样吗?
不一样
-520".zfill(10) -> -000000520
-520".rjust(10, “0”) -> 000000-520
3. 请问下面代码执行的结果是?
>>> "-520".center(6, "0").zfill(10)
-520".center(6, “0”) -> 0-5200
-520".center(6, “0”).zfill(10) -> 00000-5200
4. 请问下面代码执行的结果是?
>>> "I love FishC".swapcase()[::-1]
“I love FishC”.swapcase() -> “i LOVE fISHc”
“I love FishC”.swapcase()[::-1] -> “cHSIf EVOL i”
5. 请使用一行代码来检测列表中的每个元素是否为回文数,并返回一个结果为回文数构成的列表
提供的列表:[“123”, “33211”, “12321”, “13531”, “112233”]
返回的结果:[‘12321’, ‘13531’]
>>>x = ["123", "33211", "12321", "13531", "112233"]
>>>[each for each in x if each == each[::-1]]
['12321', '13531']
动动手:
0. 请按照以下规则整理一个给定的字符串 s。
一个整理好的字符串中,两个相邻字符 s[j] 和 s[j+1],其中 0 <= j <= s.length - 2,要满足如下条件:
若 s[j] 是小写字符,则 s[j+1] 不可以是相同的大写字符
若 s[j] 是大写字符,则 s[j+1] 不可以是相同的小写字符
如果 s[j] 和 s[j+1] 满足以上两个条件,则将它们一并删除
举例:
整理前:“FishCcCode”
整理后:“FishCcCode” -> “FishCode”
整理前:“AbBaACc”
整理后:“AbBaACc” -> “AaACc” -> “AaA” -> “A”
整理前:“AABaAbCc”
整理后:“AABaAbCc” -> “AABbCc” -> “AACc” -> “AA”
请按要求整理好字符串,并将结果打印到屏幕上。
提示:将字符串逐个读取,整理后放到一个列表中,最后将列表中的元素挨个打印即可。
# 这个代码与例子有出入,例子中不是严格按自左向右执行
pre_code = input("请输入一个待处理字符串:")
flag = True
list_pre_code = [each for each in pre_code]
lens = len(list_pre_code)
while flag:
l = lens
j = 0
while j < lens - 1:
if list_pre_code[j].islower():
if list_pre_code[j] == list_pre_code[j+1].lower():
list_pre_code = list_pre_code[:j] + list_pre_code[j+2:]
lens -= 2
print(''.join(list_pre_code))
j = 0
continue
elif list_pre_code[j].isupper():
if list_pre_code[j] == list_pre_code[j+1].upper():
list_pre_code = list_pre_code[:j] + list_pre_code[j+2:]
lens -= 2
print(''.join(list_pre_code))
j = 0
continue
j += 1
if l == lens:
flag = False
小甲鱼代码:
严格执行,也与例子不符
s = input("请输入一个字符串:")
# AbBaACc
res = []
for each in s:
if res and res[-1].lower() == each.lower() and res[-1] != each:
res.pop()
else:
res.append(each)
for each in res:
print(each, end='')
'''解析:这里比较难理解的应该是判断部分,它是先判断列表是否为空;
如果不为空,则将列表中最后一个元素(即上一轮迭代放进去的字符)拿出来比对,
大家都转换成小写,如果一样,那么说明它是同一个字母(此时可能是一个大写一个小写,
两个都是大写,或者两个都是小写 3 种可能性);最后判断如果两者不相同,
则说明是同一个字母的大小写。'''
1. 给定的字符串 s 是按照如下规则存放的:它的偶数下标为小写英文字母,奇数下标为正整数。
题目要求:编写代码,将奇数下标的数字转换为相对于上一个字母偏移后的字母。
比如 s = “a1b2c3” 转换后的结果是 “abbdcf”(a1 -> ab,b2 -> bd,c3 -> cf);s = “x7y8z9” 转换后的结果是 “xeygzi”(遇到最后字母 z ,则从 a 继续计算偏移)
提示:你可能会用到 chr() 和 ord() 这两个函数。
# 可以完美实现
s = input("请输入符合要求的字符串(偶数下标为小写英文字母,奇数下标为正整数):")
res = []
for each in s:
if s.index(each) % 2 == 0:
res.append(each)
else:
res.append(chr(ord(res[-1]) + int(each) % 26))
print(''.join(res))
小甲鱼代码:
s = input("请按规则输入一个字符串:")
length = len(s)
res = []
# 获取字母 a 的编码值
base = ord('a')
# 从第一个元素开始,每次迭代跳过一个元素
for i in range(0, length, 2):
# ord(s[i]) - base 操作得到一个字母的偏移值,比如 b 就是 1
# 跟 26 求余数的作用是防止溢出,循环计算偏移
shift = chr((ord(s[i]) - base + int(s[i+1])) % 26 + base)
print(s[i]+shift, end="")
第028讲:字符串(II)| 课后测试题及答案
-
查找
count(sub[, start[, end]])、find(sub[, start[, end]])、rfind(sub[, start[, end]])、index(sub[, start[, end]])、rindex(sub[, start[, end]]) -
替换
expandtabs([tabsize=8])、replace(old, new, count=-1)、translate(table)
expandtabs([tabsize=8]) 返回一个使用空格替换制表符的新字符串,如果没有指定 tabsize 参数,那么默认 1 个制表符 = 8 个空格
translate(table) 方法,这个是返回一个根据 table 参数(用于指定一个转换规则的表格)转换后的新字符串。需要使用 str.maketrans(x[, y[, z]]) 方法制定一个包含转换规则的表格。
>>> table = str.maketrans("ABCDEFG", "1234567")
>>> "I love FishC.com".translate(table)
'I love 6ish3.com'
这个 str.maketrans() 方法还支持第三个参数,表示将其指定的字符串忽略:
>>> "I love FishC.com".translate(str.maketrans("ABCDEFG", "1234567", "love"))
'I 6ish3.cm'
问答题:
0. 请问下面代码打印的结果是什么?
>>> str1 = "xxxxx"
>>> str1.count("xx")
2
解析:count(sub[, start[, end]]) 方法是返回 sub 在字符串中不重叠的出现次数。什么叫“不重叠”呢?就是一个元素不能被重复匹配。OGt;j`?u|
还不理解的童鞋请看小甲鱼下面的图示就一目了然了。
1. 字符串的 find() 方法和 index() 方法同样是返回查找对象的下标值,那么它们之间的区别是?
两个方法的区别主要在于当找不到查找对象时,返回的结果不一样。
find() 方法返回 -1 表示;index() 方法抛出异常(ValueError: substring not found)
2. 请问下面代码返回的值是什么?
>>> x = "上海自来水来自海上"
>>> x.rindex("来水来")
3
rindex() 和 rfind() 方法都是从右往左搜索,从左往右匹配。
我的补充:返回的下表依旧是正序的下标,且是子字符串最左边元素的下标
3. 请问下面代码执行的结果是 A 还是 B 抑或是 C 呢(为了你可以更容易地计数,下面使用 * 表示空格)?
print(x)
print(x.expandtabs(2))
print(x.expandtabs(5))
print(x.expandtabs(10))
A:
Hello****FishC
Hello**ishC
Hello*****FishC
Hello**********FishC
B:
Hello***FishC
Hello*FishC
Hello*****FishC
Hello*****FishC
C:
Hello***FishC
Hello*FishC
Hello*****FishC
Hello**********FishC
B
解析:是不是难以置信?是不是匪夷所思?如果是,那么说明你对制表键(tab)的理解可能不是很充分。
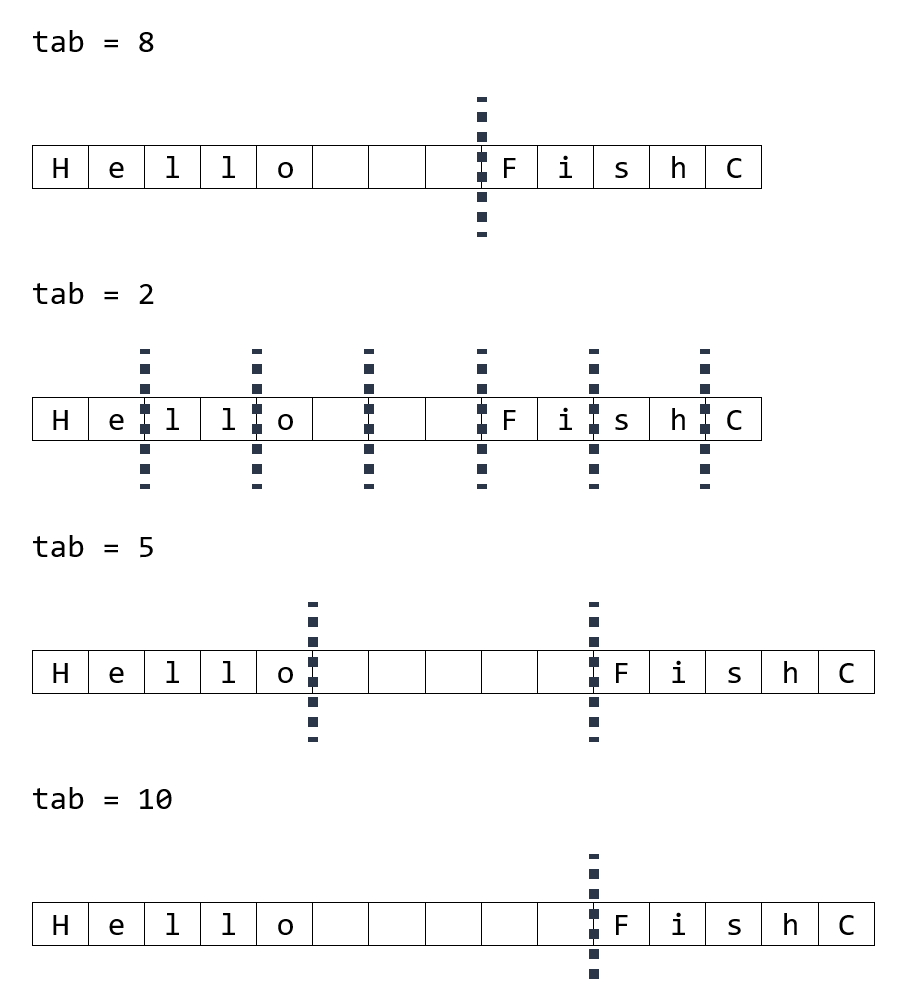
自我补充:完全不懂啥意思,实验结果感觉都一样(原字符串如果是“Hello\tFishC”才可以达到题目效果)
4. 请问下面代码打印的结果是什么?
>>> "I love FishC.com".translate(str.maketrans("ABCDEFG", "12345678"))
答:报错。
解析:str.maketrans() 方法要求两个构成映射关系的参数必须是等长的。另外,也必须是参数的类型也必须是字符串才行哦。
5. 请问下面代码打印的结果是什么?
>>> "I love FishC.com".translate(str.maketrans("love", "1234", "love"))
‘I FishC.com’
解析:嗯,这道题要考的是,str.maketrans() 方法是先执行替换还是先执行忽略操作。事实证明,如果传入了第 3 个参数,那么它是先忽略掉 ‘l’、‘o’、‘v’、‘e’ 4 个字符,然后再执行替换操作
动动手:
0. 用户输入两个版本号 v1 和 v2,请编写代码比较它们,找出较新的版本
科普:
版本号是由一个或多个修订号组成,各个修订号之间由点号(.)连接,每个修订号由多位数字组成,例如 1.2.33 和 0.0.11 都是有效的版本号。
从左到右的顺序依次比较它们的修订号,点号(.)左侧的值要比右侧的权重大,即 0.1 要比 0.0.99 大
程序实现如下(请务必确保实现截图效果):
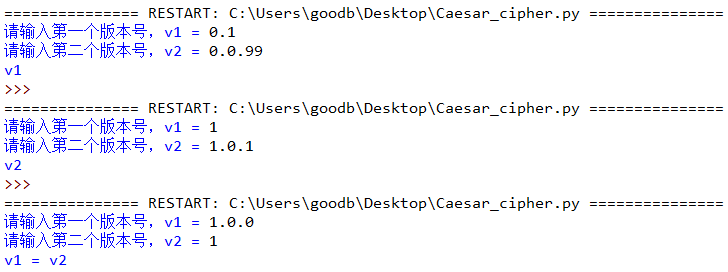
# 我的答案
temp1 = input("请输入第一个版本号:")
temp2 = input("请输入第二个版本号: ")
list1 = temp1.split(".")
list2 = temp2.split(".")
flag = True
i = 0
print(list1, list2) # 检查版本号是否正确存入列表
#1.以最短的列表为基准,从左向右比较
while flag and i < min(len(list1), len(list2)):
if int(list1[i]) > int(list2[i]):
print("v1")
flag = False
elif int(list1[i]) < int(list2[i]):
print("v2")
flag = False
else:
i += 1
#2.如果没有得到结果,说明在最短基准内没有比较出结果,需要比较最短长度以外的部分
j = min(len(list1), len(list2))
while flag:
if j == len(list1):
for k in range(j, len(list2)):
if int(list2[k]) != 0: # 如果较长列表有一个不是0,说明较长的别表版本新
print("v2")
flag = False
break
elif k == (len(list2) - 1): # 没有得到结果,且已经走到长列表末尾,说明是全0
print("v1 = v2") #这里的elif语句有判断主要是为了只输出一次v1=v2
flag = False
elif j == len(list2):
for k in range(j, len(list1)):
if int(list1[k]) != 0:
print("v1")
flag = False
break
elif k == (len(list1) - 1):
print("v1 = v2")
flag = False
小甲鱼代码
v1 = input("请输入第一个版本号,v1 = ")
v2 = input("请输入第二个版本号,v2 = ")
n, m = len(v1), len(v2)
i, j = 0, 0
while i < n or j < m:
x = 0
while i < n and v1[i] != '.':
x = x * 10 + int(v1[i])
i += 1
i += 1
y = 0
while j < m and v2[j] != '.':
y = y * 10 + int(v2[j])
j += 1
j += 1
if x > y:
print("v1")
break
elif x < y:
print("v2")
break
if x == y:
print("v1 = v2")
1. 编写一个加密程序,其实现原理是通过替换指定的字符进行加密,附加要求是实现密文逆向检测。
程序实现如下(请务必确保实现截图效果):
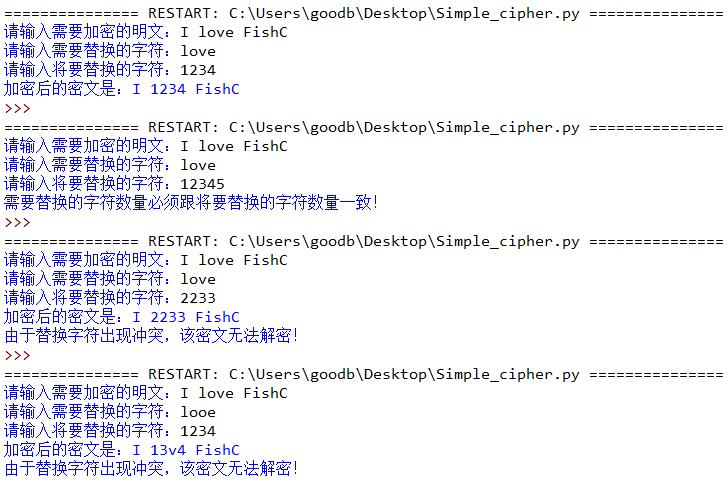
小甲鱼代码
plain = input("请输入需要加密的明文:")
x = input("请输入需要替换的字符:")
y = input("请输入将要替换的字符:")
# 加密的代码
if len(x) != len(y):
print("需要替换的字符数量必须跟将要替换的字符数量一致!")
else:
cipher = plain.translate(str.maketrans(x, y))
print("加密后的密文是:" + cipher)
# 检测冲突的代码
# flag 变量标志是否退出检测(只要找到一个冲突,就可以直接退出)
flag = 0
# 如果 x 中存在相同的字符,那么 y 对应下标的字符也应该是相同的
for each in x:
if x.count(each) > 1 and flag == 0:
i = x.find(each)
last = y[i]
while i != -1:
if last != y[i]:
print("由于替换字符出现冲突,该密文无法解密!")
flag = -1
break
i = x.find(each, i+1)
# 如果 y 中存在相同的字符,那么 x 对应下标的字符也应该是相同的
for each in y:
if y.count(each) > 1 and flag == 0:
i = y.find(each)
last = x[i]
while i != -1:
if last != x[i]:
print("由于替换字符出现冲突,该密文无法解密!")
flag = -1
break
i = y.find(each, i+1)
第029讲:字符串(III)| 课后测试题及答案
- 判断
startswith(prefix[,start[,end]]) 、endswith(suffix[,start[,end]])、isupper()、islower()、istitle()、isalpha()、isascii()、isspace()、isprintable()、isdecimal()、isdigit()、isnumeric()、isalnum()、isidentifier()
问答题:
0. 请问下面代码执行的结果是?
>>> x = "我爱Pyhon"
>>> x.startwith(["你", "我", "她"])
答:会报错。
解析:startswith(prefix[, start[, end]]) 方法的 prefix 参数支持字符串或者元组(如果是提供多个备选字符串,那么使用元组包裹)
1. 请问下面代码执行的结果是?
>>> "I love FishC\s".isprintable()
答:True。
解析:你一定以为 \s 是一个转义字符,所以应该打印 False 对不对?上当啦,\s 不是转义字符
2. isdecimal()、isdigit() 和 isnumeric() 这 3 个方法都是判断数字的,那么请问这其中哪一个方法 “最严格”,哪一个又是 “最宽松” 的呢?
答:isdecimal() 方法是最严格的,只有真正意义上的数字才能得到 True;isnumeric() 方法是最宽松的,罗马数字、中文数字都不在话下。
解析:一般都是用于判断输入是否合法,能否进行下一步的运算,所以 isdecimal() 方法最严谨,使用的频率也相对会更多一些。
isdecimal()最严格,必须是十进制数字
isdigit()次之,可以是诸如“2²”这样的数字
isnumeric()最宽松,甚至可以是汉字的“一二三”
3. 请问下面代码执行的结果是?
>>> "一二三四五上山打老虎".isalnum()
答:True。
解析:isalnum() 方法则是集大成者,只要 isalpha()、isdecimal()、isdigit() 或者 isnumeric() 任意一个方法返回 True,结果都为 True
这是因为 isalpha() 方法判断的 “字母” 是 Unicode 编码中定义的字母,不止是 26 个英文字母哈o
4. 请使用一行代码判断 s 字符串中,是否所有字符都是英文字母?
答:x.isalpha() and x.isascii()
解析:请看上一题的解析,由于 isalpha() 方法判断的字母是 Unicode 编码中定义的字母,所以像 “FishC小甲鱼” 这样的字符串它也会返回 True,显然不符合题意。
因此,我们要进一步判断它是否为 ASCII 编码,这样就稳了~
5. 请问下面代码执行的结果是?
>>> "一二三木头人".isidentifier()
答:True。
解析:由于对 Unicode 编码的支持,Python 是可以使用中文作为合法标识符的。
动动手:
0. 给定一个字符串 text 和字符串列表 words,返回 words 中每个单词在 text 中的位置(要求最终的位置从小到大进行排序)。
举例:
text:“I love FishC and FishC love me”
words:“FishC”
输出:[[7, 11], [17, 21]]
text:“I love FishC and FishC love me”
words:“FishC love”
输出:[[2, 5], [7, 11], [17, 21], [23, 26]]
text:“FCFCF”
words:“FCF FC”
输出:[[0, 1], [0, 2], [2, 3], [2, 4]]
程序实现如下:
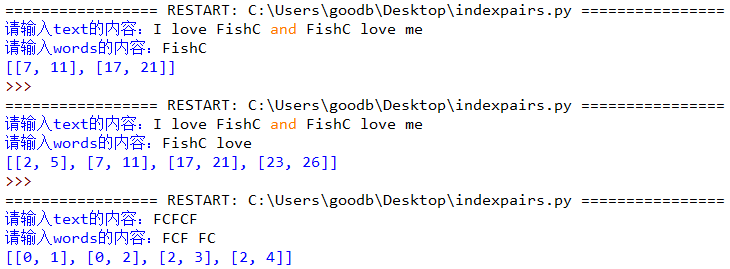
小甲鱼代码
text = input("请输入text的内容:")
words = input("请输入words的内容:")
words = words.split()
result = []
for each in words:
temp = text.find(each)
while temp != -1:
result.append([temp,temp+len(each)-1])
temp = text.find(each, temp+1)
print(sorted(result))
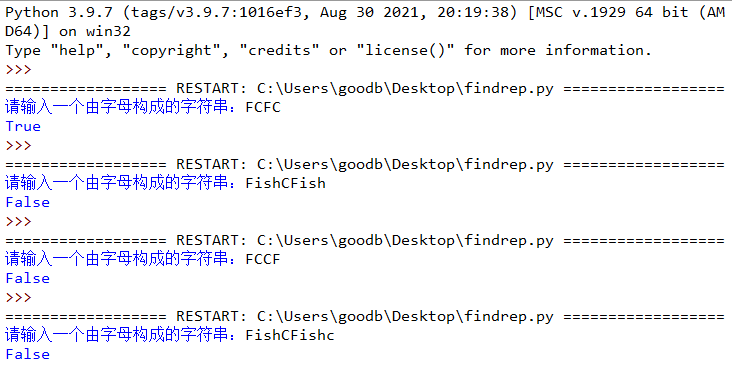
1. 编写一个程序,判断输入的字符串是否由多个子字符串重复多次构成。
举例:
输入:“FCFC”
输出:True
输入:“FishCFish”
输出:False
输入:“FCCF”
输出:False
输入:“FishCFishc”
输出:False
程序实现如下:
提示:
如果一个长度为 n 的字符串 s 可以由它的一个长度为 i 的子串 s’ 重复多次构成,那么必须要满足以下条件:
- n 一定是 i 的倍数
- s‘ 一定是 s 的前缀子字符串
- n 除以 i 的结果必定是 s’ 在 s 中出现的次数
小甲鱼代码
s = input("请输入一个由字母构成的字符串:")
n = len(s)
for i in range(1, n//2+1):
# 如果子字符串的长度为i,则n必须可以被i整除才行
if n % i == 0:
# 如果子字符串的长度为i,则i到i*2之间是一个重复的子字符串
if s.startswith(s[i:i*2]) and s.count(s[i:i*2]) == n/i:
print(True)
break
# for...else的用法,小甲鱼希望大家还没有忘记哦^o^
else:
print(False)
第030讲:字符串(IV)| 课后测试题及答案
- 截取
strip(chars = None)、lstrip(chars = None)、rstrip(chars = None)、removeprefix(prefix)、removesuffix(suffix) - 拆分
partition(sep)、rpartition(sep)、split(sep=None,maxsplit=-1)、rsplit(sep=None,maxsplit=-1)、splitlines(keepends=False) - 拼接
join(iterable)
问答题:
0. 请问下面三行代码的执行结果分别是什么?

答:
>>> "www.ilovefishc.com".lstrip("wcom.")
'ilovefishc.com'
>>> "www.ilovefishc.com".rstrip("wcom.")
'www.ilovefish'
>>> "www.ilovefishc.com".strip("wcom.")
'ilovefish'
1. 请问下面代码打印的内容是什么?
>>> "www.ilovefishc.com".removeprefix("w.")
答:
>>> "www.ilovefishc.com".removeprefix("w.")
'www.ilovefishc.com'
解析:区别于上一题,removeprefix(prefix) 和 removesuffix(suffix) 这两个方法是以字符串为单位的。
2. split() 方法常常被应用于对数据的解析处理,那么考考大家,如果要从字符串 “https://ilovefishc.com/html5/index.html” 中提取出 “ilovefishc.com”,使用 split() 方法应该如何实现呢?
>>> "https://ilovefishc.com/html5/index.html".split('//')[1].split('/')[0]
'ilovefishc.com'
3. 如果要求按换行符来分割字符串,小甲鱼推荐使用 splitlines() 方法,而非 split("\n"),你觉得小甲鱼的依据是什么?
答:相比起 split("\n") 来说,splitlines() 方法显得更加“智能”,它可以自动判断不同系统的换行符(比如 Linux 系统下的换行符是 “\n”;Mac 是 “\r”;而 Windows 则是 “\r\n”)。另外,splitlines() 方法还可以通过 keepends 参数来指定在结果中保留换行字符。`
4. 下面代码使用加号运算符(+)进行字符串拼接,现在看起来有点太 low 了,请将它改为使用 join() 方法来拼接吧~
>>> s = "I" + " " + "love" + " " + "FishC"
>>> s
'I love FishC'
答:
>>> s = " ".join(["I", "love", "FishC"])
>>> s
'I love FishC'
- 请问下面代码打印的内容是什么?
>>> print(",\n".join("FishC"))
答:
F,
i,
s,
h,
C
动动手:
- 编写一个生成凯撒密码的程序
科普:
凯撒密码最早由古罗马军事统帅盖乌斯·尤利乌斯·凯撒在军队中用来传递加密信息,故称凯撒密码。
原理:
凯撒密码是一种通过位移加密的方法,对 26 个(大小写)字母进行位移加密,比如下方是正向位移 6 位的字母对比表:
明文字母表如下
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
密文字母表如下
GHIJKLMNOPQRSTUVWXYZABCDEFghijklmnopqrstuvwxyzabcdef
所以,如果给定加密的明文是:
I love FishC
那么程序加密后输出的密文便是:
O rubk LoynI
程序实现如下:

小甲鱼代码
plain = list(input("请输入需要加密的明文(只支持英文字母):"))
key = int(input("请输入移动的位数:"))
base_A = ord('A')
base_a = ord('a')
cipher = []
for each in plain:
if each == ' ':
cipher.append(' ')
else:
if each.isupper():
base = base_A
else:
base = base_a
cipher.append(chr((ord(each) - base + key) % 26 + base))
print(''.join(cipher))
- 给定一个字符串数组 words,只返回可以使用在美式键盘同一行的字母打印出来的单词,键盘布局如下图所示。

美式键盘中:
- 第一行由字符 “qwertyuiop” 组成
- 第二行由字符 “asdfghjkl” 组成
- 第三行由字符 “zxcvbnm” 组成
举例:
输入:words = [“Twitter”, “TOTO”, “FishC”, “Python”, “ASL”]
输出:[‘Twitter’, ‘TOTO’, ‘ASL’]
小甲鱼代码
words = ["Twitter", "TOTO", "FishC", "Python", "ASL"]
res = []
for i in words:
# 由于单词存在大小写,所以这里统一先转换为小写字母
j = i.lower()
# 灵活运用 strip() 方法,判断 j 是否所有字符都在键盘的同一行内
if j.strip("qwertyuiop") == '' or j.strip("asdfghjkl") == '' or j.strip("zxcvbnm") == '':
res.append(i)
print(res)
第031讲:字符串(V)| 课后测试题及答案
:[[fill]align][sign][#][0][width][group.option][.precision][type]
问答题:
0. 请问下面代码会打印什么内容?
"{}, {}, {}".format("苹果", "香蕉", "梨")
答:
>>> "{}, {}, {}".format("苹果", "香蕉", "梨")
'苹果, 香蕉, 梨'
解析:在字符串中,格式化字符串的套路就是使用一对花括号({})来表示替换字段,就在原字符串中先占一个坑的意思,然后真正的内容被放在了 format() 方法的参数中。
1. 请问下面代码会打印什么内容?
"{1}看到{0}就很激动!".format("小甲鱼", "漂亮的小姐姐")
答:‘漂亮的小姐姐看到小甲鱼就很激动!’
解析:可以在花括号({})中添加一个数字,表示使用第几个参数。
2. 请问下面代码会打印什么内容?
>>> "我叫{name},我爱{0}。喜爱{0}的人,运气都不会太差^o^".format(name="小甲鱼", "python")
答:报错。
这里有个小细节需要大家注意一下,就是使用关键字进行索引的话,它必须放在位置索引的后面,否则就会报错(其实在后面我们讲解到自定义函数的时候,也会提到这个规则)。
3. 请问下面代码会打印什么内容?
>>> "{{0}}".format(1)
答:’{0}’
在花括号外边套一层花括号,外层是对内层起到“注释“的作用,
所谓”注释“,就是剥夺了花括号的特殊功能,使它变会一个正经的字符串。
4. 请问下面代码会打印什么内容?
>>> "{{{0}}}".format(1)
答:’{1}’
这里稍微有一丢丢小复杂了,由于存在 3 层花括号包裹,我们必须逐层给它剥开。
首先最外层注释了倒数第二层,那么最终结果将保留一个花括号。
接着,内部剩下的 {0},则正常解析,获取 format() 的第一个参数。
5. 请问下面代码会打印什么内容?
>>> "{{{{{{0}}}}}}".format(1)
答:’{{{0}}}’
解析:
数一下,这里存在 6 层花括号包裹,所以不难想象,每 2 层进行一次注释,得到的就是 3 对失去了特殊功能的花括号,所以剩下一个 0 也自然是正经的字符串。
动动手:
0. 请编写一个程序,统计字符串中的单词个数(“单词”以空格进行分隔)
举例:
输入:(空字符串)
输出:0
输入:Python
输出:1
输入:I love FishC
输出:3
小甲鱼代码
s = input("请输入测试字符串:")
print(len(s.split()))
1. 请编写一个程序,将用户输入的字符串重新格式化,使得字母和数字相互分隔(即一个字母一个数字相互间隔)
举例:
输入:FishC1314
输出:F1i3s1h4C
输入:FishC520
输出:字符串中数字和字母的数量不满足重新格式化的条件
输入:Python6543210
输出:6P5y4t3h2o1n
小甲鱼代码:
s = input("请输入测试字符串:")
str09 = []
strAZ = []
# 将数字和字母进行归类存放
for each in s:
if each.isdecimal():
str09.append(each)
else:
strAZ.append(each)
len09 = len(str09)
lenAZ = len(strAZ)
# 如果两个容器的元素个数相差 1 个以上,则不满足重新格式化的条件
if abs(len09 - lenAZ) > 1:
print("字符串中数字和字母的数量不满足重新格式化的条件。")
else:
if len09 > lenAZ:
shorter = strAZ
longer = str09
else:
shorter = str09
longer = strAZ
result = []
for i in range(len(shorter)):
result.append(longer[i])
result.append(shorter[i])
# 由于 longer 是有可能等于 shorter 的,就不必执行下面这一步
if len(longer) > len(shorter):
result.append(longer[-1])
print("".join(result))
第032讲:字符串(VI)| 课后测试题及答案
问答题:
0. 用 f-string,最需要注意的是什么?
答:兼容性。
解析:如果是在正式开发,请务必先了解你的代码将在什么版本的 Python 上运行!这很重要,在 Python3.6 之前,f-string 是不被支持的。
1. 请问下面代码会打印什么内容?
f"{{1 + 2}}"
答:’{1 + 2}’
解析:在花括号外边套一层花括号,外层是对内层起到“注释“的作用。
所谓”注释“,就是剥夺了花括号的特殊功能,使它变会一个正经的字符串。
2. 请问下面代码会打印什么内容?
f"{{{1 + 2}}}"
答:’{3}’
解析:这里外面的两层大括号由于“注释”的作用,失去了特殊功能……
不过此时还剩下 {1+2},这个可就要正常解析了。
- 请将下面 format() 格式化字符串修改为 f-string 的格式?
"{:.{prec}f}".format(3.1415, prec=2)
>>> f"{3.1415:.2f}"
'3.14'
- 请问下面代码会打印什么内容?
>>> f"{520:.2}"
答:会报错。
解析:因为整数不允许被设置“精度”选项,如果非要这么做,可以加一个 ‘f’(即 f"{520:.2f}"),表示将参数以小数的形式输出。
- 请将下面 format() 格式化字符串修改为 f-string 的格式?
>>> "{:{fill}{align}{width}.{prec}{ty}}".format(3.1415, fill='$', align='^', width=10, prec=2, ty='f')
答: f"{3.1415:$^10.2f}"
动动手:
0. 相信大家对于压缩和解压缩的操作并不陌生,但对其内部的实现原理,你又知道多少呢?
接下来请大家跟着题目的提示,一起来实现字符串的压缩和解压缩吧。
利用字符重复出现的次数,编写一个程序,实现基本的字符串压缩功能。比如,字符串 FFiiiisshCCCCCC 压缩后变成 F2i4s2h1C6(15字符 -> 10字符,66% 压缩率)。
这种朴素的压缩算法并不总是理想的,比如 FFishCC 压缩后反而变长了 F2i1s1h1C2,这可就不是我们想要的了,所以对于重复次数小于 3 的字符,我们的程序应该选择不对其进行压缩。
好了,大家开始写代码吧~
程序实现如图所示:

s = input("请输入待压缩字符串:")
ch = s[0]
result = ''
count = 0
for each in s:
if each == ch:
count += 1
else:
if count > 2:
result += ch + str(count)
if count == 2:
result += ch + ch
if count == 1:
result += ch
ch = each
count = 1
result += ch + str(count)
print(f"压缩后的字符串:{result}")
print(f"压缩率为:{len(result)/len(s)*100:.2f}%")
- 请大家编写一个解压程序,将上一题压缩后的字符串进行解压缩。
程序实现如图所示:
s = input("请输入待解压字符串:")
ch = s[0]
result = ''
for each in s:
if each.isdecimal():
for i in range(int(each)-1):
result += ch
else:
result += each
ch = each
print(f"解压后的字符串:{result}")

















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









