






Database DDL操作
DDL
Data Definition Language(即数据的定义语言)
create/delete/alter等操作,与关系型数据库中的DDL非常类似,几乎是一样的
官网:https://cwiki.apache.org/confluence/display/Hive/Home
DDL:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
官网的介绍:

Hive中的一张表就对应HDFS上的一个目录:/user/hive/warehouse/xxx
创建数据库
- 语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];- 操作:
hive>create database hive;
hdfs上对应的目录:/user/hive/warehouse/hive.db问题一:Hive中,默认的default数据库在hdfs上没有显示,为什么?
emp表的路径:/user/hive/warehouse/emp
由于没有指定相应的数据库,因此emp表默认是default数据库的
default数据库在HDFS上默认是没有的,不需要的
因为 /user/hive/warehouse/ 后面跟的就是default
比如:
/user/hive/warehouse/a
/user/hive/warehouse/dept
/user/hive/warehouse/emp
这些均是default数据库所管辖的
只有当自己手动去创建一个数据库时,HDFS上才会去创建一个xxx.db的文件夹创建数据库的时候建议的写法
hive>create database if not exists hive;- 创建数据库的其它写法
hive>create database hive2 LOCATION "/zhaotao/directory"; 此时hdfs上的目录:/zhaotao/directory 并没有创建相关文件夹

hive>use hive2;
hive>create table a(id int);此时hdfs上的目录:/ruoze/directory/a 此时创建了与表对应的文件夹

问题二为什么没有创建对应的hive2.db文件夹**
原理和默认目录/user/hive/warehouse/ 下不创建default,但是会创建hive.db一样
/ruoze/directory/xxx 目录下的文件夹都是属于hive2数据库所管辖的创建数据库的其它写法(写上相关注释;使用键值对形式):**
hive>create database hive3 COMMENT 'it is my database'
WITH DBPROPERTIES('creator'='ruoze','date'='2018-08-08'); 查看数据库
hive>show databases;查hive开头的(使用模糊匹配的方式)
hive>show databases like 'hive*';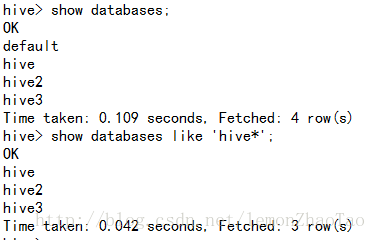
查看数据库的结构
hive>desc database hive2;
hive>desc database hive3;- 查看更详细的信息:
该操作可以查看刚刚创建的hive3数据库 所定义的信息 键值对
hive>desc database extended hive3; 
- 去MySQL查看元数据信息
mysql>mysql
mysql>select * from DBS \G;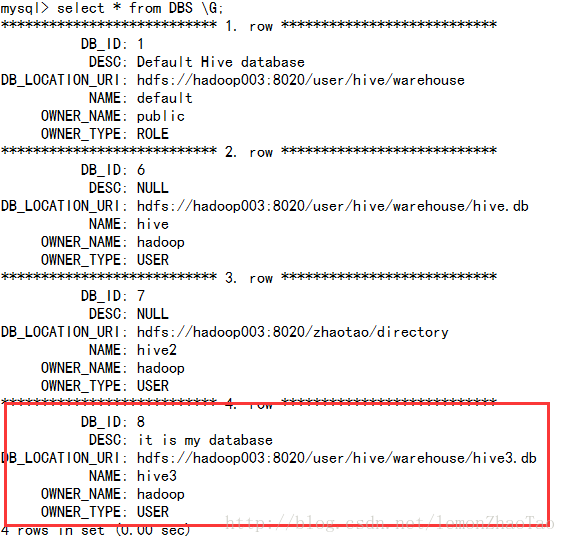
在这个表中,可以查看到hive3数据库的信息
mysql>select * from DATABASE_PARAMS \G;
【重点】
每当我们使用了一个hive中ql时,一定要知道这条语句对应元数据信息是怎么存储的
修改数据库
语法:
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; hive>alter database hive3 set DBPROPERTIES("edited-by"="J");修改完之后,再去看
mysql>select * from DATABASE_PARAMS \G;
删除数据库
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];hive>drop database hive3;发现对应的元数据信息被删除了
mysql>select * from DBS \G;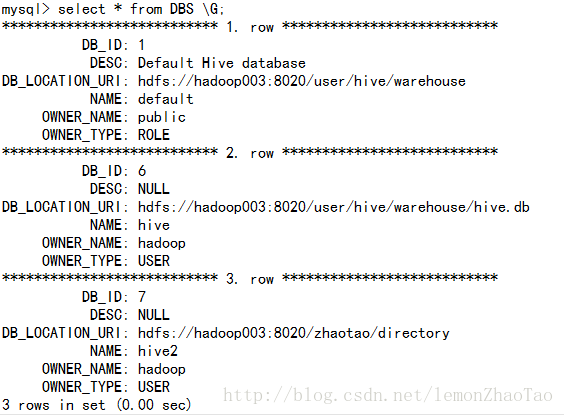
删除失败 因为该数据库中还有其它表存在,因此不能直接删除
hive>drop database hive2; 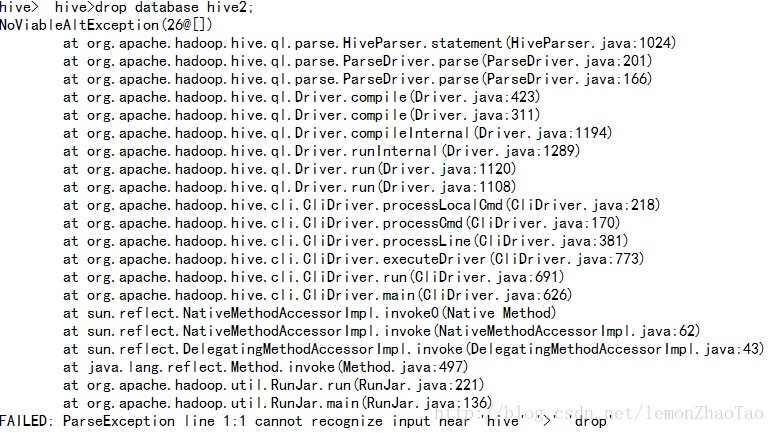
删除成功 cascade级联
工作中不建议删除数据库,尤其是加了cascade级联
hive>drop database hive2 cascade; 
操作总结
本质上,操作与关系型数据库没有差别
Hive基本数据类型&分隔符
网址
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types几种常用的数据类型:
string、int、bigint、float、double、boolean、date timestamp
注:放到越后面的优先级越低分隔符
\n (行与行之间 相当于回车换行)
^A 与 \001(表示的是同一个 在Hive中,列与列之间的分隔符不是Tab也不是空格键)
【注意】一般情况下,在创建表的时候直接指定分隔符:\t或者, 进行使用
Table DDL操作
Hive 表的创建
网址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
hive中的表其实对应的就是hdfs上的一个文件夹
同理,hive中的数据库也是对应一个文件夹
相关操作
语法:
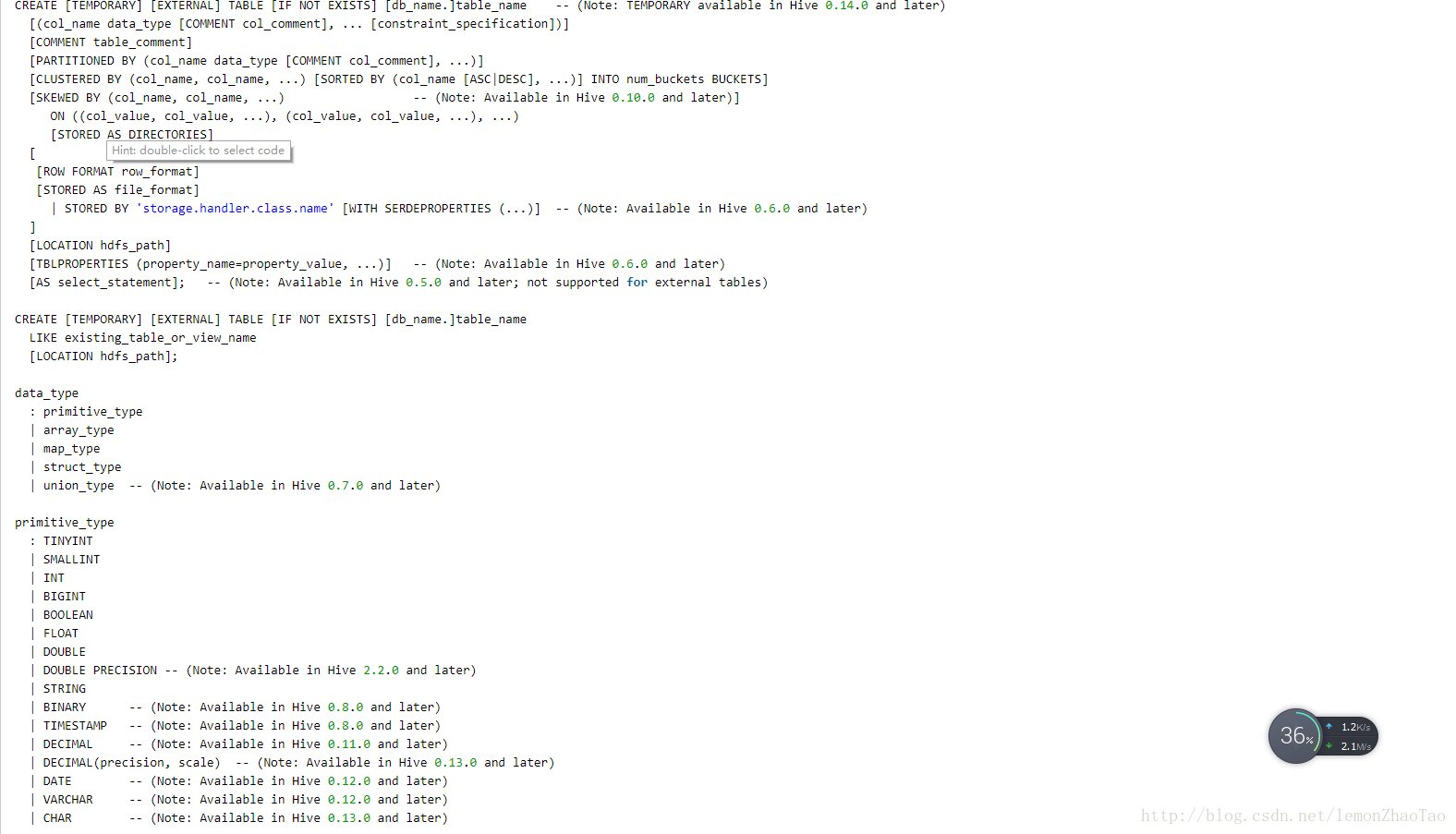
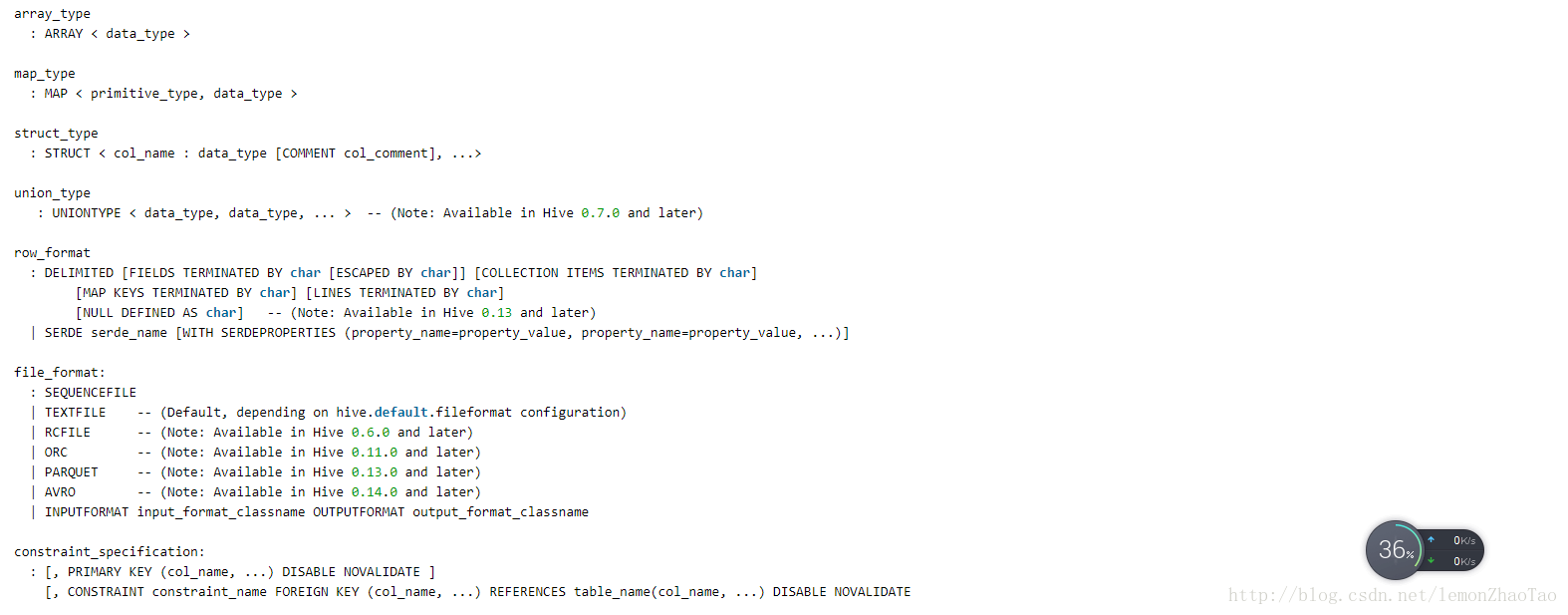
hive>create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)row format delimited fields terminated by '\t'; 字段之间的分隔符采用’\t’ 官网解释:[FIELDS TERMINATED BY char [ESCAPED BY char]]
hive>create table emp2 as select * from emp;官网解释:[AS select_statement]; 从已有的表中的数据,进行创建表
这是要跑MapReduce 作业的
hive>select * from emp2;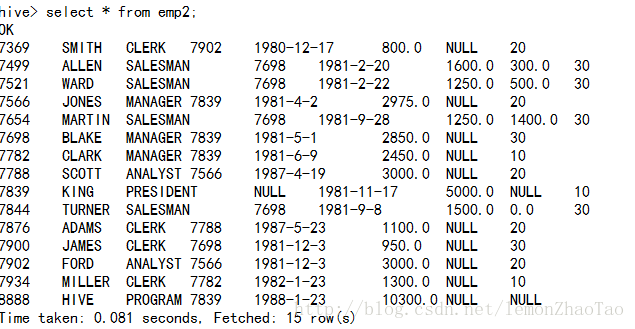
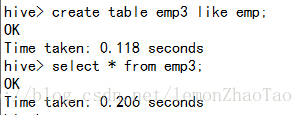
hive>create table emp3 like emp;官网解释:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
注意:like只拷贝表结构不拷贝表数据
查看表结构
hive>desc emp3;
hive>desc extended emp3;推荐使用这种,格式化查看
hive>desc formatted emp3;
修改表名
语法:
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
table_properties:
: (property_name = property_value, property_name = property_value, ... )hive>alter table emp2 rename to emp2_bak;修改表名之后,hdfs上对应的目录为:/user/hive/warehouse/emp2_bak
表名被修改之后,hdfs对应的目录也被修改了

删除表
语法:
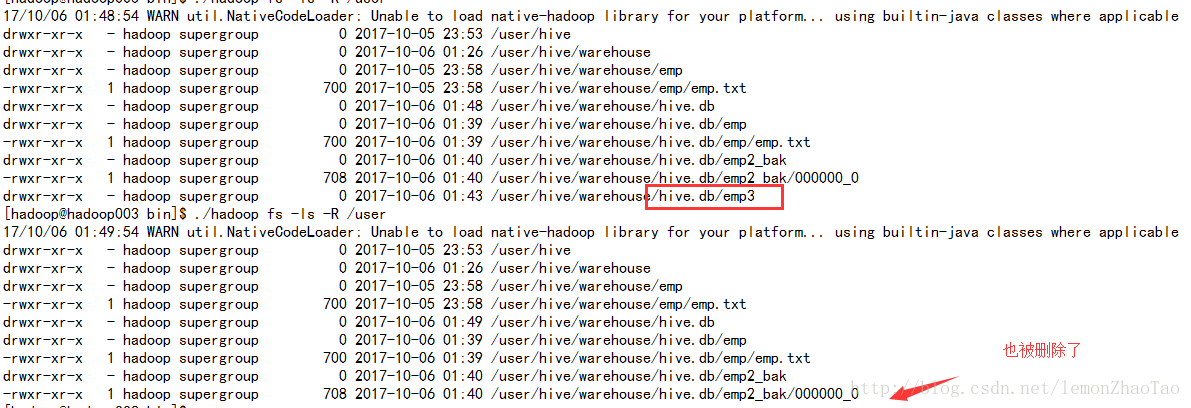
DROP TABLE [IF EXISTS] table_name [PURGE];???? -- (Note: PURGE available in Hive 0.14.0 and later)hive>drop table emp3;hdfs上对应的emp3文件夹也被删除了
Truncate Table操作
语法:
TRUNCATE TABLE table_name [PARTITION partition_spec];
partition_spec:
: (partition_column = partition_col_value, partition_column = partition_col_value, ...)hive>Truncate Table emp2_bak;
hive>select * from emp2_bak; 查不出数据了,没有数据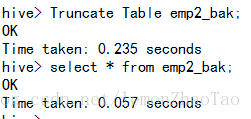
Truncate操作不删除表结构,但是表中的数据没有了
内部表和外部表的区别
面试的时候,经常会被问到:有什么区别,分别在什么场景下进行使用?
相关介绍:
Managed and External Tables 内部和外部表
Hive里面有两类数据:
1. data 数据存放在HDFS上的
2. metadata 元数据存放在mysql上的
内部表
hive.metastore.warehouse.dir=/user/hive/warehouse ##在hive-site中配置
If a managed table or partition is dropped, the data and metadata associated with that table or partition are deleted.drop table ==> data + metadata drop
外部表
An external table describes the metadata / schema on external files. External table files can be accessed and managed by processes outside of Hivecreate table + location 可以存放在任意的地方,在创建的时候通过location参数进行指定
drop table ==> metadata drop + data not drop
实验:
- 内部表的实验:
创建内部表
hive>create table emp_managed as select * from emp;查看表结构
hive>desc formatted emp_managed; hdfs路径:/user/hive/warehouse/emp_managed
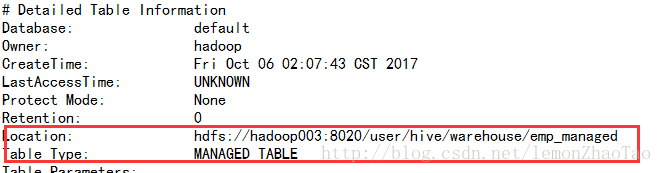
TBL_TYPE为MANAGED_TABLE,代表为内部表
mysql>select * from TBLS \G; 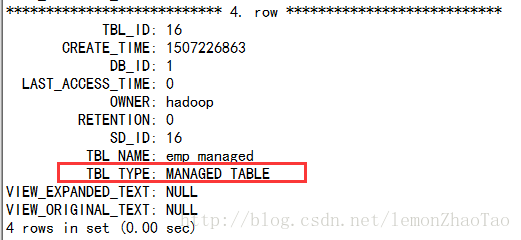
hive>drop table emp_managed;hdfs上没有 /user/hive/warehouse/emp_managed 路径了 data数据没有了
mysql里也没有元数据了
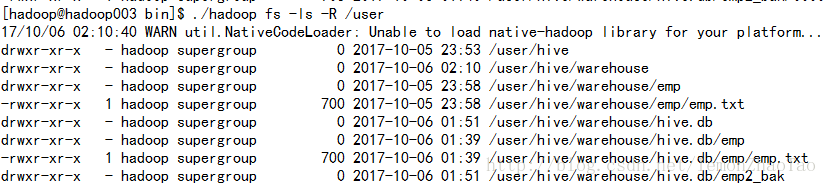

注意:不带EXTERNAL不一定不是外部表,因为外部表可以通过属性进行设置
TBLPROPERTIES (“EXTERNAL”=”TRUE”)
- 外部表的实验:
hive>create EXTERNAL table emp_external(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)row format delimited fields terminated by '\t'
location '/hive_external/emp/';TBL_TYPE为EXTERNAL_TABLE
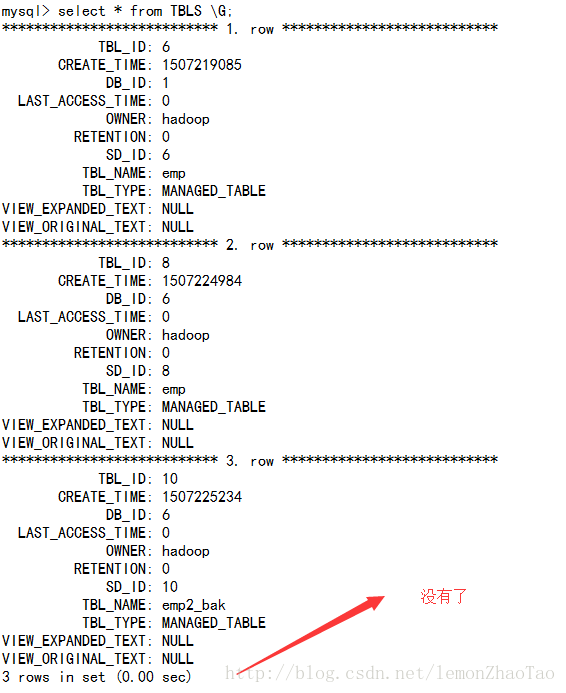
mysql>select * from TBLS \G;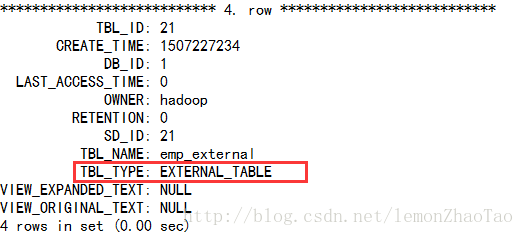
没有数据
hive>select * from emp_external; 
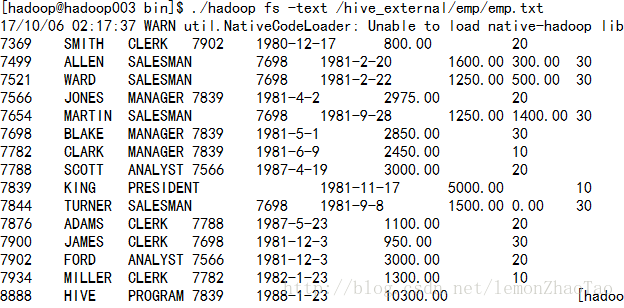
将本地的数据拷贝到hdfs上去
$>hadoop fs -put /opt/data/emp.txt /hive_external/emp/ 可以查出数据
hive>select * from emp_external;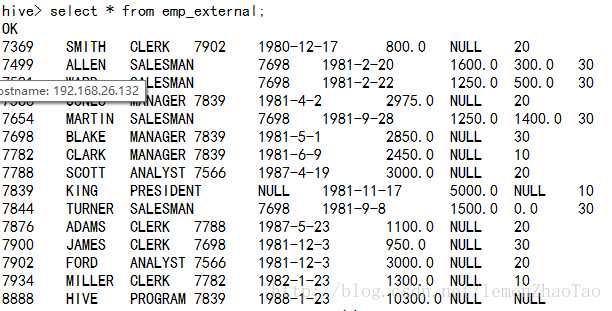
hive>drop table emp_external;hdfs上的/hive_external/emp/emp.txt还有
mysql上的元数据被删除了
问题:外部表在什么地方使用呢?
建议:对于一些原始的日志文件,建议使用外部表
就算干掉,也只是元数据没有了,但是hdfs上的数据还是存在
这样子,数据安全性较好
Hive DDL其他
TBLPROPERTIES
查看表的创建语句:
hive>show create table emp;
存储格式(Storage Formats) 重要,后面会展开讲:
创建表的时候,可以自己指定;不指定,会有默认的值
[STORED AS file_format]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classnamePartitioned Tables
后面的文章中会展开讲,其在工作中十分重要















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









