






好处 & 工作机制
使用HiveServer2的好处:
1. HiveServer2不用直接将HDFS和Metastore暴漏给用户(对比于使用hive-cli方式)
2. 通过HA机制(从Hive 0.14开始引入该机制),解决了负载均衡和并发的问题
3. 可以在Client端通过JDBC的方式,发起操作,与数据进行交互
配置HA之前,HiveServer2的工作机制:
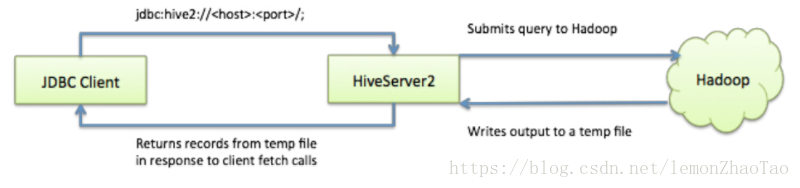
对于这种情况,如果遇到Client端的并发比较少,就不会出事,但是一旦并发上去,一个HiveServer2实例挂掉了,那么就会导致所有的应用链接失效
对此,Hive在0.14开始,引入了HA机制,通过Zookeeper来实现HiveServer2的HA功能;Client端可以通过指定一个NameSpace去连接HiveServer2(这点与Hadoop HA类似),而不是通过指定某一个固定的ip:portt去连接:
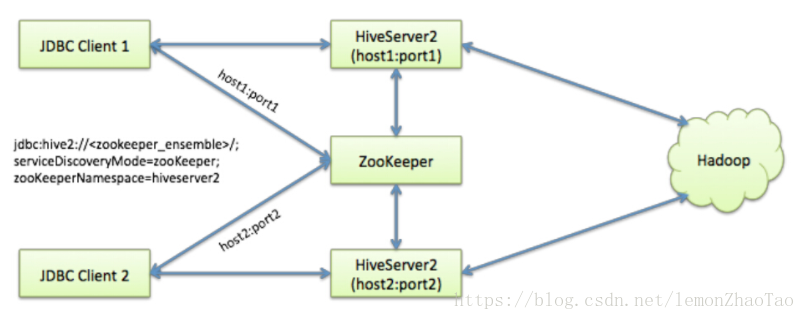
HA配置实现
编辑每台机器上的hive-site.xml文件如下:
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value> zkNode1:2181,zkNode2:2181,zkNode3:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value> //两个HiveServer2实例的端口号要一致
</property>注:Zookeeper自己去配置
启动HiveServer2
分别在2台机器上启动HiveServer2,可以发现在zk中,这2个都注册上来了
JDBC连接串解读
JDBC连接的URL格式为:
jdbc:hive2://<zookeeper quorum>/<dbName>;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
其中:
<zookeeper quorum> 为Zookeeper的集群链接串,如zkNode1:2181,zkNode2:2181,zkNode3:2181
<dbName>为Hive数据库,默认为default
serviceDiscoveryMode=zooKeeper指定模式为zooKeeper
zooKeeperNamespace=hiveserver2指定ZK中的NameSpace,即参数hive.server2.zookeeper.namespace所定义,这里定义的为hiveserver2_zk














 1900
1900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









