







1.替换操作
●替换操作可以同步作用于Series和DataFrame中
df = DataFrame(data=np.random.randint(0,100,size=(5,6)))
Out[241]:
0 1 2 3 4 5
0 57 33 53 6 32 54
1 11 68 31 27 48 77
2 13 80 80 8 50 46
3 23 55 35 4 44 89
4 10 20 13 10 95 39
●单值替换
■普通替换:替换所有符合要求的元素:o. replace=15,value=‘e’
■按列指定单值替换: to replace={列标签: 替换值} value=‘value’
#单值替换
df.replace(to_replace=6,value='six')
Out[243]:
0 1 2 3 4 5
0 57 33 53 six 32 54
1 11 68 31 27 48 77
2 13 80 80 8 50 46
3 23 55 35 4 44 89
4 10 20 13 10 95 39
●多值替换
■列表替换: to. replace=0 value=0
■字典替换(推荐) to. replace={to. replace:value,to replace:value}
#多值替换
df.replace(to_replace={6:'six',9:'nine'})
Out[244]:
0 1 2 3 4 5
0 57 33 53 six 32 54
1 11 68 31 27 48 77
2 13 80 80 8 50 46
3 23 55 35 4 44 89
4 10 20 13 10 95 39
#指定列的替换(将第二列的31替换成‘33311’)
df.replace(to_replace={2:31},value='33311')
Out[245]:
0 1 2 3 4 5
0 57 33 53 6 32 54
1 11 68 33311 27 48 77
2 13 80 80 8 50 46
3 23 55 35 4 44 89
4 10 20 13 10 95 39
2.映射
●概念:创建一个映射关系列表,把values元素和-个特定的标签或者字符串绑定(给一 个元素值提供不同的表现形式)
●创建一个df, 两列分别是姓名和薪资,然后给其名字起对应的英文名
from pandas import DataFrame,Series
dic = {'name':['张三','李四','王二麻子'],'salary':[15000,20000,22000]}
df = DataFrame(data=dic)
df
Out[253]:
name salary
0 张三 15000
1 李四 20000
2 王二麻子 22000
1.map只是Series的函数,只能由Series调用
#映射关系表
dic_net = {'张三':'tom','李四':'jerry','王二麻子':'jacky'}
df['e_name']=df['name'].map(dic_net)
df
Out[257]:
name salary e_name
0 张三 15000 tom
1 李四 20000 jerry
2 王二麻子 22000 jacky
2.map既能映射,还能充当运算工具
#超过2000的部分缴纳20%的税,计算税后薪资
def after_sal(s):
...: if s <= 20000:
...: return s
...: else :
...: return s - (s-20000)*0.2
...: df['after_sal'] = df['salary'].map(after_sal)
...: df
Out[269]:
name salary e_name after_sal
0 张三 15000 tom 15000.0
1 李四 20000 jerry 20000.0
2 王二麻子 22000 jacky 21600.0
3.DataFrame中的apply操作:将df中的运算作用到DataFrame的行或列中
df = DataFrame(data=np.random.randint(0,10,size=(5,3)))
df
Out[273]:
0 1 2
0 1 1 3
1 8 5 4
2 5 7 1
3 4 3 4
4 3 3 2
def my_add(value):
...: return value+10
...: df.apply(my_add,axis=1)
Out[276]:
0 1 2
0 11 11 13
1 18 15 14
2 15 17 11
3 14 13 14
4 13 13 12
4.applymap操作:将df中的运算作用到DataFrame的每个元素
def my_add(value):
...: return value+1000
...: df.applymap(my_add)
Out[279]:
0 1 2
0 1001 1001 1003
1 1008 1005 1004
2 1005 1007 1001
3 1004 1003 1004
4 1003 1003 1002
3.排序实现的随机抽样
take()
np.random.pemitation()
df = DataFrame(data=np.random.randint(0,100,size=(100,3)),columns=['A','B','C'])
df
Out[282]:
A B C
0 4 50 47
1 70 60 6
2 10 26 51
3 20 91 88
4 2 53 26
.. .. .. ..
95 70 44 37
96 37 7 99
97 76 11 37
98 78 49 34
99 2 81 28
[100 rows x 3 columns]
#将原始数据打乱(索引打乱)
#注意:indices只能作用于隐式索引
df.take(indices=[1,0,2],axis=1)#打乱列索引
#打乱行索引
random_df = df.take(indices[1,0,2],axis=1).take(indices=np.random.permutation(100),axis=0)
random_df
Out[285]:
B A C
85 93 14 26
79 79 68 58
71 30 10 98
80 25 59 74
76 78 46 62
.. .. .. ..
93 22 60 80
12 17 84 66
94 12 25 86
32 75 30 62
65 36 19 34
[100 rows x 3 columns]
#随机抽样——对random_df切片
4.数据的分类处理
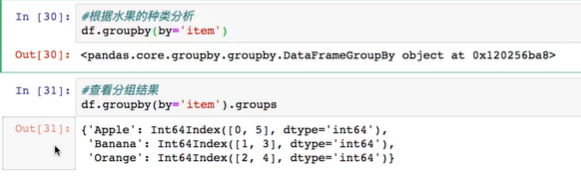
标题数据分组处理的核心:
- groupby()函数
- groups属性查看分组情况
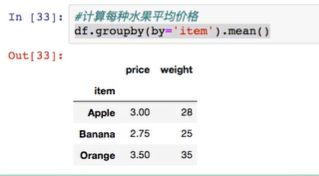
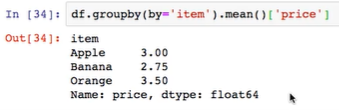
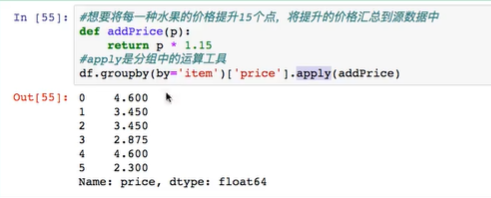
求水果平均价格,并汇总到原数据中(分组计算,映射聚合):
step1:

以上不推荐,
推荐写法:
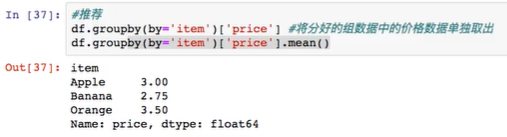
step2:


5.高级数据聚合

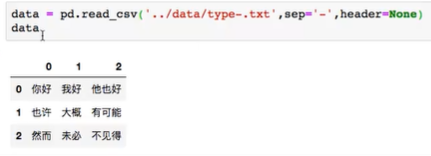
6.数据加载
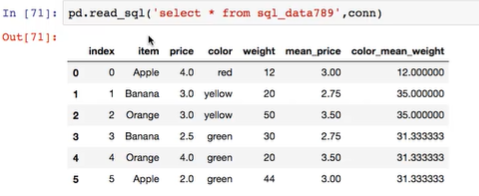
7.读取sql数据库中的数值

8.透视表
●透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大
功能,而在pandas中它被称作pivot. table。
●透视表的优点:
■灵活性高,可以随意定制你的分析计算要求
■脉络清晰易于理解数据
■操作性强,报表神器
import pandas as pd
import numpy as np
df = pd.read_csv('./data/透视表-篮球赛.csv',encoding='utf8')
df
对手 胜负 主客场 命中 投篮数 投篮命中率 3分命中率 篮板 助攻 得分
0 勇士 胜 客 10 23 0.435 0.444 6 11 27
1 国王 胜 客 8 21 0.381 0.286 3 9 27
2 小牛 胜 主 10 19 0.526 0.462 3 7 29
3 灰熊 负 主 8 20 0.400 0.250 5 8 22
4 76人 胜 客 10 20 0.500 0.250 3 13 27
5 黄蜂 胜 客 8 18 0.444 0.400 10 11 27
6 灰熊 负 客 6 19 0.316 0.222 4 8 20
7 76人 负 主 8 21 0.381 0.429 4 7 29
8 尼克斯 胜 客 9 23 0.391 0.353 5 9 31
9 老鹰 胜 客 8 15 0.533 0.545 3 11 29
10 爵士 胜 主 19 25 0.760 0.875 2 13 56
11 骑士 胜 主 8 21 0.381 0.429 11 13 35
12 灰熊 胜 主 11 25 0.440 0.429 4 8 38
13 步行者 胜 客 9 21 0.429 0.250 5 15 26
14 猛龙 负 主 8 25 0.320 0.273 6 11 38
15 太阳 胜 客 12 22 0.545 0.545 2 7 48
16 灰熊 胜 客 9 20 0.450 0.500 5 7 29
17 掘金 胜 主 6 16 0.375 0.143 8 9 21
18 尼克斯 胜 主 12 27 0.444 0.385 2 10 37
19 篮网 胜 主 13 20 0.650 0.615 10 8 37
20 步行者 胜 主 8 22 0.364 0.333 8 10 29
21 湖人 胜 客 13 22 0.591 0.444 4 9 36
22 爵士 胜 客 8 19 0.421 0.333 5 3 29
23 开拓者 胜 客 16 29 0.552 0.571 8 3 48
24 鹈鹕 胜 主 8 16 0.500 0.400 1 17 26
pivot_table有四个最重要的参数index. values. columns. aggfunc
1.index参数: 分类汇总的分类条件
——每个pivot _table必须拥有一个index.如果想查看哈登对阵每个队伍的得分则需要对每一个队进行分类并计算其各类得分的平均值:
#对阵同一对手在不同主客场下的数据,分类条件为对手和主客场
df.pivot_table(index=['对手','主客场'])
3分命中率 助攻 命中 得分 投篮命中率 投篮数 篮板
对手 主客场
76人 主 0.4290 7.0 8.0 29.0 0.381 21.0 4.0
客 0.2500 13.0 10.0 27.0 0.500 20.0 3.0
勇士 客 0.4440 11.0 10.0 27.0 0.435 23.0 6.0
国王 客 0.2860 9.0 8.0 27.0 0.381 21.0 3.0
太阳 客 0.5450 7.0 12.0 48.0 0.545 22.0 2.0
小牛 主 0.4620 7.0 10.0 29.0 0.526 19.0 3.0
尼克斯 主 0.3850 10.0 12.0 37.0 0.444 27.0 2.0
客 0.3530 9.0 9.0 31.0 0.391 23.0 5.0
开拓者 客 0.5710 3.0 16.0 48.0 0.552 29.0 8.0
掘金 主 0.1430 9.0 6.0 21.0 0.375 16.0 8.0
步行者 主 0.3330 10.0 8.0 29.0 0.364 22.0 8.0
客 0.2500 15.0 9.0 26.0 0.429 21.0 5.0
湖人 客 0.4440 9.0 13.0 36.0 0.591 22.0 4.0
灰熊 主 0.3395 8.0 9.5 30.0 0.420 22.5 4.5
客 0.3610 7.5 7.5 24.5 0.383 19.5 4.5
爵士 主 0.8750 13.0 19.0 56.0 0.760 25.0 2.0
客 0.3330 3.0 8.0 29.0 0.421 19.0 5.0
猛龙 主 0.2730 11.0 8.0 38.0 0.320 25.0 6.0
篮网 主 0.6150 8.0 13.0 37.0 0.650 20.0 10.0
老鹰 客 0.5450 11.0 8.0 29.0 0.533 15.0 3.0
骑士 主 0.4290 13.0 8.0 35.0 0.381 21.0 11.0
鹈鹕 主 0.4000 17.0 8.0 26.0 0.500 16.0 1.0
黄蜂 客 0.4000 11.0 8.0 27.0 0.444 18.0 10.0
2.values参数:需要对计算的数据进行筛选
如果我们只需要哈登在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
df.pivot_table(index=['主客场','胜负'],values =['得分','篮板','助攻'])
Out[25]:
助攻 得分 篮板
主客场 胜负
主 胜 10.555556 34.222222 5.444444
负 8.666667 29.666667 5.000000
客 胜 9.000000 32.000000 4.916667
负 8.000000 20.000000 4.000000
3.Aggfunc参数:设置我们对数据聚合时进行的函数操作
当我们未设置aggfunc时,它默认aggfunc='mean’计算均值。
#还想获得james harden在主客场和不同胜负情况下的总得分、总篮板、总助攻时:
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'],aggfunc='sum')
Out[26]:
助攻 得分 篮板
主客场 胜负
主 胜 95 308 49
负 26 89 15
客 胜 108 384 59
负 8 20 4
4.Columns:可以设置列层次字段
对values字段进行分类
#获取所有队主客场的总得分
df.pivot_table(index='主客场',values='得分',aggfunc='sum')
Out[27]:
得分
主客场
主 397
客 404
#获取每个队主客场的总得分(在总得分的基础上又进行了对手的分类)
df.pivot_table(index='主客场',values='得分',columns='对手',aggfunc='sum',fill_value=0)
Out[28]:
对手 76人 勇士 国王 太阳 小牛 尼克斯 开拓者 掘金 步行者 湖人 灰熊 爵士 猛龙 篮网 老鹰 骑士 鹈鹕 黄蜂
主客场
主 29 0 0 0 29 37 0 21 29 0 60 56 38 37 0 35 26 0
客 27 27 27 48 0 31 48 0 26 36 49 29 0 0 29 0 0 27
9.交叉表
-
是一种用于计算分组的特殊透视图,对数据进行汇总
-
pd.crosstab(index,colums)
-
index:分组数据,交叉表的行索引
-
columns:交叉表的列索引
.
0import pandas as pd from pandas import DataFrame df = DataFrame({'sex':['man','man','women','women','man','women','man','women','women'], 'age':[15,23,25,17,35,57,24,31,22], 'smoke':[True,False,False,True,True,False,False,True,False], 'height':[168,179,181,166,173,178,188,190,160]}) df sex age smoke height 0 man 15 True 168 1 man 23 False 179 2 women 25 False 181 3 women 17 True 166 4 man 35 True 173 5 women 57 False 178 6 man 24 False 188 7 women 31 True 190 8 women 22 False 160 求出各个性别抽烟的人数 pd.crosstab(df.smoke,df.sex) sex man women smoke False 2 3 True 2 2 求出各个年龄段抽烟人情况 pd.crosstab(df.age,df.smoke) smoke False True age 15 0 1 17 0 1 22 1 0 23 1 0 24 1 0 25 1 0 31 0 1 35 0 1 57 1 0















 3665
3665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









