









解法
跟编译原理相关的解释在这里
几个坑:
- 记得合并同类项
- 记得去掉系数为0的项
- 次数相同的项字典序较小的在前面
解法一:自顶向下
这里要注意,由于我们把语法改成非左递归了,但是减号是左结合的,所以要把term的值传给下一个expr让它计算
class Solution(object):
def basicCalculatorIV(self, exp, evalvars, evalints):
"""
:type expression: str
:type evalvars: List[str]
:type evalints: List[int]
:rtype: List[str]
"""
import re
dic = dict(zip(evalvars, evalints))
times = {"": 0}
num = r"(?P<NUM>[0-9]+)"
var = r"(?P<VAR>[a-z]+)"
plus = r"(?P<PLUS>\+)"
sub = r"(?P<SUB>\-)"
multi = r"(?P<MULTI>\*)"
left = r"(?P<LEFT>\()"
right = r"(?P<RIGHT>\))"
pattern = re.compile("|".join([num,var,plus,sub,multi,left,right]))
def genToken(s):
for a in pattern.finditer(s):
yield filter(lambda x:x[1],a.groupdict().items())[0]
# ```
# expr->term {'+'|'-'} expr | term
# term->item '*' term | item
# item->var | num | '(' expr ')'
# ```
tokens = list(genToken(exp))
n = len(tokens)
self.i = 0
def add(a, b, isadd):
# print a,b,"+" if isadd else '-'
ak = set(a.keys())
for k in ak:
if isadd:
a[k] += b.get(k, 0)
else:
a[k] -= b.get(k, 0)
if a[k] == 0:
a.pop(k)
for k in b:
if k not in ak:
if isadd:
a[k] = b[k]
else:
a[k] = -b[k]
# print a
return a
def multi(a, b):
res = {}
for k1, k2 in itertools.product(a.iterkeys(), b.iterkeys()):
if k1 == "":
nk = k2
elif k2=="":
nk = k1
else:
nk = "*".join(sorted(k1.split('*') + k2.split('*')))
res[nk] = res.get(nk,0) + a[k1] * b[k2]
times[nk] = times[k1] + times[k2]
return res
def item():
t, token = tokens[self.i]
if t=='NUM':
self.i += 1
return {"":int(token)}
if t=='VAR':
self.i += 1
if token in dic:
return {"":dic[token]}
times[token] = 1
return {token:1}
self.i += 1
res = expr({},True)
self.i += 1
return res
def term():
now = item()
while self.i<n:
t, token = tokens[self.i]
if t == 'MULTI':
self.i += 1
now = multi(now, term())
else:break
return now
def expr(now,isadd):
now = add(now,term(),isadd)
if self.i<n:
t, token = tokens[self.i]
if t=='PLUS' or t=='SUB':
self.i += 1
return expr(now,token=='+')
return now
res = expr({},True)
return map(lambda x: "%d%s" % (res[x], ("*%s"%x) if len(x) else ""), sorted(filter(lambda x:res[x]!=0,res.keys()),key=lambda x: (-times[x],x)))
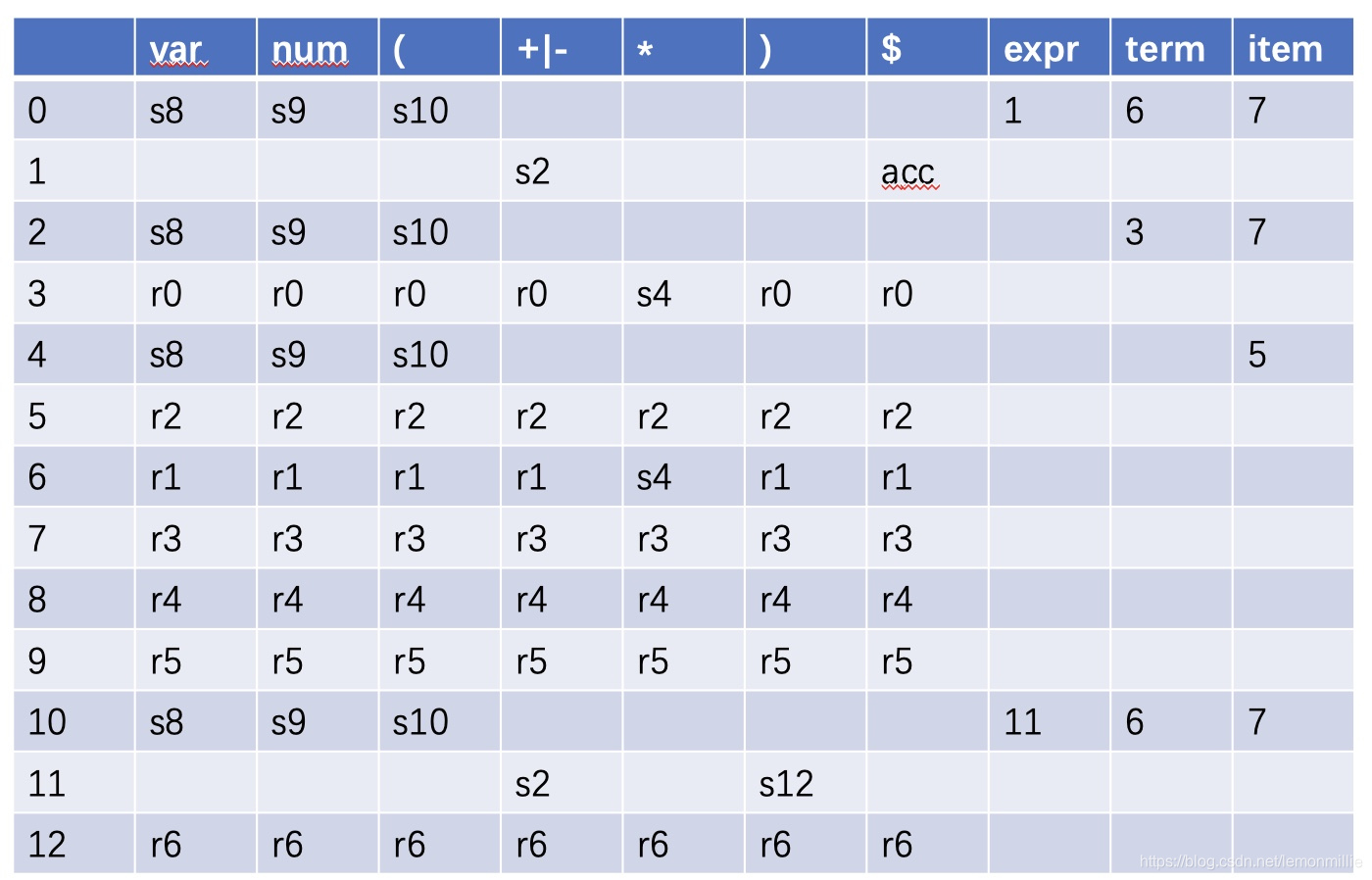
解法二:自底向上
语法分析表为:
0: expr->expr {'+'|'-'} term
1: expr->term
2: term->term '*' item
3: term->item
4: item->var
5: item->num
6: item->'(' expr ')'
class Solution(object):
def basicCalculatorIV(self, exp, evalvars, evalints):
"""
:type expression: str
:type evalvars: List[str]
:type evalints: List[int]
:rtype: List[str]
"""
import re
from collections import defaultdict
dic = dict(zip(evalvars, evalints))
times = {"": 0}
num = r"(?P<NUM>[0-9]+)"
var = r"(?P<VAR>[a-z]+)"
plus = r"(?P<PLUS>\+)"
sub = r"(?P<SUB>\-)"
multi = r"(?P<MULTI>\*)"
left = r"(?P<LEFT>\()"
right = r"(?P<RIGHT>\))"
pattern = re.compile("|".join([num,var,plus,sub,multi,left,right]))
def genToken(s):
for a in pattern.finditer(s):
yield filter(lambda x:x[1],a.groupdict().items())[0]
# ```
# expr->term {'+'|'-'} expr | term
# term->item '*' term | item
# item->var | num | '(' expr ')'
# ```
tokens = list(genToken(exp))
n = len(tokens)
self.i = 0
def add(a, b, isadd):
# print a,b,"+" if isadd else '-'
ak = set(a.keys())
for k in ak:
if isadd:
a[k] += b.get(k, 0)
else:
a[k] -= b.get(k, 0)
if a[k] == 0:
a.pop(k)
for k in b:
if k not in ak:
if isadd:
a[k] = b[k]
else:
a[k] = -b[k]
# print a
return a
def multi(a, b):
res = {}
for k1, k2 in itertools.product(a.iterkeys(), b.iterkeys()):
if k1 == "":
nk = k2
elif k2=="":
nk = k1
else:
nk = "*".join(sorted(k1.split('*') + k2.split('*')))
res[nk] = res.get(nk,0) + a[k1] * b[k2]
times[nk] = times[k1] + times[k2]
return res
stack = [['$',0]]
def r0():
b,_ = stack.pop()
opt,_ = stack.pop()
a,_ = stack.pop()
stack.append([add(a,b,opt=='+'),SLR[stack[-1][1]]['expr']])
def r1():
stack[-1][1] = SLR[stack[-2][1]]['expr']
def r2():
b, _ = stack.pop()
stack.pop()
a, _ = stack.pop()
stack.append([multi(a, b), SLR[stack[-1][1]]['term']])
def r3():
stack[-1][1] = SLR[stack[-2][1]]['term']
def r4():
t,_ = stack.pop()
if t in dic:
t = {"": dic[t]}
else:
times[t] = 1
t = {t: 1}
stack.append([t,SLR[stack[-1][1]]['item']])
def r5():
t, _ = stack.pop()
stack.append([{"":int(t)}, SLR[stack[-1][1]]['item']])
def r6():
stack.pop()
t,_ = stack.pop()
stack.pop()
stack.append([t,SLR[stack[-1][1]]['item']])
SLR = [
{'VAR':8,'NUM':9,'LEFT':10,'expr':1,'term':6,'item':7},
{'PLUS':2,'SUB':2,'$':0},
{'VAR':8,'NUM':9,'LEFT':10,'term':3,'item':7},
defaultdict(lambda:r0),
{'VAR':8,'NUM':9,'LEFT':10,'item':5},
defaultdict(lambda: r2),
defaultdict(lambda: r1),
defaultdict(lambda: r3),
defaultdict(lambda: r4),
defaultdict(lambda: r5),
{'VAR': 8, 'NUM': 9, 'LEFT': 10, 'expr': 11, 'term': 6, 'item': 7},
{'PLUS': 2, 'SUB': 2, 'RIGHT': 12},
defaultdict(lambda: r6),
]
SLR[3]['MULTI'] = 4
SLR[6]['MULTI'] = 4
for t,token in genToken(exp):
while not isinstance(SLR[stack[-1][1]][t],int):
SLR[stack[-1][1]][t]()
stack.append([token,SLR[stack[-1][1]][t]])
else:
while not isinstance(SLR[stack[-1][1]]['$'],int):
SLR[stack[-1][1]]['$']()
res = stack[-1][0]
return map(lambda x: "%d%s" % (res[x], ("*%s"%x) if len(x) else ""), sorted(filter(lambda x:res[x]!=0,res.keys()),key=lambda x: (-times[x],x)))
emm……不是很快

















 2226
2226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









