






数据结构
String
set k v get k del k strlen k incr article incrby article 3 decr article decyby article #value字符串操作 getrange name 0 -1 getrange name 0 1 setrange name 0 x # SETEX 是一个原子性(atomic)操作,设置值和设置生存时间两个动作会在同一时间内完成 SETEX pro 10 华为 等价于 set pro 华为 expire pro 10 #在分布式系统里面可以使用如下命令实现分布式锁 setnx(set if not exist) 如果返回1:设置成功 如果返回0:设置失败
List
K string
V List
list特点:有序、可重复
存 lpush num 1 2 3 4 5 rpush num2 1 2 3 4 5 查 lrange num 0 -1 lrange num2 0 -1 #根据下标获取元素 LINDEX key index 弹出(获取数据的同时将数据从list中删除) lpop rpop 大小 LLEN key #队列:先进先出 lpush num3 1 2 3 #左边推进去 rpop num3 1 #右边取出来 或者 rpush num4 1 2 3 lpop num4 #栈:先进后出 lpush num5 1 2 3 lpop num5 或者 rpush num6 1 2 3 rpop num6 #list的长度 llen num5
Set
K string
V Set
set特点:无序,不可重复
存 sadd ips '192.168.22.1' '192.168.22.2' '192.168.22.2' 查 smembers ips 查看某个元素在集合中是否存在 SISMEMBER key member 删 srem ips '192.168.22.1' 大小 scard ips #获取set的长度 #随机 sadd nums 3 4 5 0 9 8 9 0 8 6 srandmember nums 3 #随机并移除 spop rands 3 交集 redis 127.0.0.1:6379> SADD myset "hello" (integer) 1 redis 127.0.0.1:6379> SADD myset "foo" (integer) 1 redis 127.0.0.1:6379> SADD myset "bar" (integer) redis 127.0.0.1:6379> SADD myset2 "hello" (integer) 1 redis 127.0.0.1:6379> SADD myset2 "world" (integer) 1 redis 127.0.0.1:6379> SINTER myset myset2 1) "hello" 并集 redis> SADD key1 "a" (integer) 1 redis> SADD key1 "b" (integer) 1 redis> SADD key1 "c" (integer) 1 redis> SADD key2 "c" (integer) 1 redis> SADD key2 "d" (integer) 1 redis> SADD key2 "e" (integer) 1 redis> SUNION key1 key2 1) "a" 2) "c" 3) "b" 4) "e" 5) "d" redis>
Hash
K string
V Hash
hash特点:hash的key不能重复,如果重复就覆盖
存
hset person name 'jack'
hset person age 40
取
hget person name
hget person age
存多个
hmset person name 'rose' age 12
大小
hlen person
判断k是否存在
hexists person age
hkeys person
hvals person
person "{'name':'zhangsan'}" string
name jack
age 12
person:hash()
#hash可以大大减少redis中的K 同时hash结构特别适合存放对象
person :
name 'jack'
age '18'
hget person age
4.5:Zset(Sorted set)
K String
V ZSet
zset特点:有序,不可重复,通过score来进行排序,score必须是数字
通过score进行排序 zadd hot 300 '华为met10' 10 '苹果10' 19 '小米' zrange hot 0 -1 zrevrange hot 0 -1 #分数范围过滤 zrangebyscore hot 11 100 zrangebyscore hot 10 100 limit 0 1 #删除 zrem hot '小米' zcard hot #查看集合的元素个数
五:其他指令
#########################key相关指令############## keys parttern 127.0.0.1:6379> keys art* 1) "article2" 2) "artile1" 127.0.0.1:6379> #如果存在返回1,否则返回0 exists key del key #给key设置过期时间 expire key seconds #查看key的剩余时间 -1:表示没有过期时间 >0 表示剩余的时间 -2:过期,数据被回收 ttl key #不设置过期时间,让它常驻内存 persist key ################db相关的指令########################## Redis有16个db 分别为0,1,...,15【redis的默认数据库为0】 #切换数据库 select index #清空数据库 flushdb #清空所有的数据库 flushall #数据库的数据总条数 dbsize #最近一次保存数据的时间戳 lastsave
基于springboot
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-pool2 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.8.0</version> </dependency>
配置
spring:
redis:
host: 192.168.25.102
port: 6379
password: 123456
lettuce:
pool: #配置redis的连接池
min-idle: 8
max-active: 12
测试
package com.qf;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.*;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
@RunWith(SpringRunner.class)
public class RedisTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void testString(){
BoundValueOperations<String, String> oper = stringRedisTemplate.boundValueOps("name");
oper.set("rose");
String name = oper.get();
System.out.println(name);
}
@Test
public void testList(){
BoundListOperations<String, String> operations = stringRedisTemplate.boundListOps("persons");
operations.rightPush("张飞");
operations.rightPush("宋江");
operations.rightPush("曹操");
String s = operations.rightPop();
System.out.println(s);
String s1 = operations.rightPop();
System.out.println(s1);
}
@Test
public void testHash(){
BoundHashOperations<String, Object, Object> operations = stringRedisTemplate.boundHashOps("student");
operations.put("name","jack");
operations.put("age","18");
System.out.println(operations.get("name"));
operations.keys().forEach(System.out::println);
operations.values().forEach(System.out::println);
}
@Test
public void testSet(){
BoundSetOperations<String, String> operations = stringRedisTemplate.boundSetOps("nums");
operations.add("1","2","2","3");
operations.members().forEach(System.out::println);
}
@Test
public void testZset(){
BoundZSetOperations<String, String> operations = stringRedisTemplate.boundZSetOps("hot");
operations.add("华为",100);
operations.add("小米",10);
operations.add("苹果",200);
operations.range(0,-1).forEach(System.out::println);
operations.reverseRange(0,-1).forEach(System.out::println);
}
}持久化
RDB(Redis Databases):内存中的数据集快照写入磁盘,也就是 Snapshot 快照,恢复时是将快照文件直接读到内存里。
Redis会单独fork一个子进程进行持久化工作,该子进程先将数据写入一个临时文件,等待持久化完毕,再将临时文件覆盖替换上此持久化好的文件,整个过程主进程是不会进行任何的IO操作,确保了极高的性能,而且当进行大规模数据恢复的时候RDB性能也非常高. 但是RDB有缺点,没法保证数据不丢失
AOF(Append Of File):以日志的形式记录每个写操作(命令),当redis重启时,加载aof文件,将修改命令执行一遍。
将Redis所有的写操作命令记录下来(读操作不记录),以文件追加的方式存放起来,当Redis重启恢复数据时,将操作日志从头到尾执行一遍,恢复数据
aof默认是关闭的,如果要开启aof必须要配置
AOF重写
由于AOF持久化是Redis不断将写命令记录到 AOF 文件中,随着Redis不断的进行,AOF 的文件会越来越大,文件越大,占用服务器内存越大以及 AOF 恢复要求时间越长。为了解决这个问题,Redis新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。可以使用命令 bgrewriteaof 来重新。
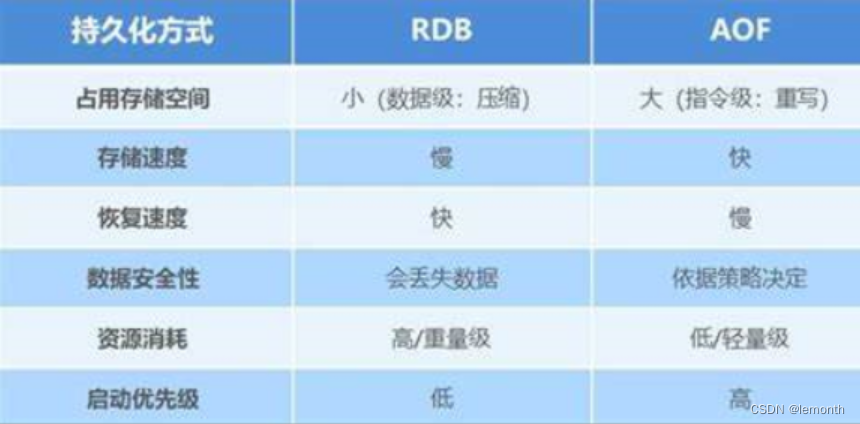
RDB对比AOF
缓存击穿
某一个热点key,在失效的一瞬间,持续的高并发访问击破缓存直接访问数据库,导致数据库造的周期性压力(极端情况下导致数据库宕机)
缓存击穿解决办法:
加锁(分布式锁),两次判断
@Override
public List<TbCategory> selectAll() {
//判断redis中是否命中
BoundValueOperations<String, String> operations = stringRedisTemplate.boundValueOps("mtl:index:cat");
String catListJson = operations.get();
if(StringUtils.isEmpty(catListJson)){
List<TbCategory> categories =new ArrayList<>();
synchronized (this) {
String catListJsonAgain = operations.get();
if(StringUtils.isEmpty(catListJsonAgain)){
//get from db
System.out.println("get from db");
categories = categoryMapper.findAll();
//cache to redis
operations.set(JSONUtil.toJsonStr(categories));
}else{
//
System.out.println("get from redis");
categories = JSONUtil.toList(catListJsonAgain, TbCategory.class);
}
}
return categories;
}else{
System.out.println("get from redis");
//catListJson反序列化
List<TbCategory> categories = JSONUtil.toList(catListJson, TbCategory.class);
return categories;
}
}缓存穿透
非法访问、数据库并不存在,缓存也无法命中,请求都会到数据库,从而可能压垮数据源
数据库中没有,同时Redis中也没有
方案1:缓存空值
存在大量的垃圾数据
@Override
public List<TbBrand> selectBrandsByCatId(String catId) {
synchronized (this) {
BoundHashOperations<String, Object, Object> operations = stringRedisTemplate.boundHashOps("mtl:index:brands");
Object brandListJson = operations.get(catId);
if(StringUtils.isEmpty(brandListJson)){
System.out.println("brand get from db");
List<TbBrand> brandsByCatId = brandMapper.findBrandsByCatId(catId);
operations.put(catId, JSONUtil.toJsonStr(brandsByCatId));
return brandsByCatId;
}else{
System.out.println("brand get from redis");
List<TbBrand> tbBrands = JSONUtil.toList((String) brandListJson, TbBrand.class);
return tbBrands;
}
}
}
方案2:布隆过滤
@Bean
public RedissonClient redissonClient(){
//构造redisson客户端,并放入IOC容器中
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redissonClient = Redisson.create(config);
RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter("spuIds");
//初始化
bloomFilter.tryInit(100000000L,0.03);
//初始化数据
bloomFilter.add("1");
bloomFilter.add("2");
bloomFilter.add("3");
bloomFilter.add("4");
bloomFilter.add("5");
return redissonClient;
}
@Override
public List<TbBrand> selectBrandsByCatId(String catId) {
synchronized (this) {
//判断用户传参是否合法
if(!boomFilter.contains(catId)){//非法访问
return new ArrayList<>();
}
BoundHashOperations<String, Object, Object> operations = stringRedisTemplate.boundHashOps("mtl:index:brands");
Object brandListJson = operations.get(catId);
if(StringUtils.isEmpty(brandListJson)){
System.out.println("brand get from db");
List<TbBrand> brandsByCatId = brandMapper.findBrandsByCatId(catId);
operations.put(catId, JSONUtil.toJsonStr(brandsByCatId));
return brandsByCatId;
}else{
System.out.println("brand get from redis");
List<TbBrand> tbBrands = JSONUtil.toList((String) brandListJson, TbBrand.class);
return tbBrands;
}
}
}
缓存雪崩
缓存雪崩是缓存击穿的"大面积"版,缓存击穿是数据库缓存到Redis内的热点数据失效导致大量并发查询穿过redis直接击打到底层数据库,而缓存雪崩是指Redis中大量的key几乎同时过期,然后大量并发查询穿过redis击打到底层数据库上,此时数据库层的负载压力会骤增,我们称这种现象为"缓存雪崩"。事实上缓存雪崩相比于缓存击穿更容易发生,对于大多数公司来讲,同时超大并发量访问同一个过时key的场景的确太少见了,而大量key同时过期,大量用户访问这些key的几率相比缓存击穿来说明显更大。
解决方案
在可接受的时间范围内随机设置key的过期时间,分散key的过期时间,以防止大量的key在同一时刻过期;
延长热点key的过期时间或者设置永不过期,这一点和缓存击穿中的方案一样;
14.4:缓存预热
缓存预热如字面意思,当系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库,如果并发大的话,很有可能在上线当天就会宕机,因此我们需要在上线前先将数据库内的热点数据缓存至Redis内再提供出去使用,这种操作就成为"缓存预热"。
解决方案:
缓存预热的实现方式有很多,比较通用的方式是写个批任务,在启动项目时或定时去触发将底层数据库内的热点数据加载到缓存内。
14.5:缓存更新/缓存同步
缓存服务(Redis)和数据服务(底层数据库)是相互独立且异构的系统,在更新缓存或更新数据的时候无法做到原子性的同时更新两边的数据,因此在并发读写或第二步操作异常时会遇到各种数据不一致的问题。如何解决并发场景下更新操作的双写一致是缓存系统的一个重要知识点。
解决方案:
使用canal实现数据双写一致性?
14.6:缓存降级
Redis服务不可用,或者网络抖动,导致服务不稳定
解决方案
使用Sentinel熔断降级策略进行服务熔断降级
说一下Redis中的watch命令
很多时候,要确保事务中的数据没有被其他客户端修改才执行该事务。Redis提供了watch命令来解决这类问题,这是一种乐观锁的机制。
Redis中,sexnx命令的返回值是什么,如何使用该命令实现分布式锁?
当返回1时表示设置值成果,当返回0时表示设置值失败(key已存在)。
一般我们不建议直接使用setnx命令来实现分布式锁,因为为了避免出现死锁,我们要给锁设置一个自动过期时间。而setnx命令和设置过期时间的命令不是原子的,可能加锁成果而设置过期时间失败,依然存在死锁的隐患。对于这种情况,Redis改进了set命令,给它增加了nx选项,启用该选项时set命令的效果就会setnx一样了。
采用Redis实现分布式锁,就是在Redis里存一份代表锁的数据,通常用字符串即可。采用改进后的setnx命令(即set...nx...命令)实现分布式锁的思路,
Redis的主从同步是如何实现的?
从2.8版本开始,Redis使用psync命令完成主从数据同步,同步过程分为全量复制和部分复制。全量复制一般用于初次复制的场景,部分复制则用于处理因网络中断等原因造成数据丢失的场景。psync命令需要以下参数的支持:
-
复制偏移量:
-
积压缓冲区:。
-
主节点运行ID:
说一说Redis的缓存淘汰策略
默认淘汰册罗,内存满了直接返回错误
淘滩最近用的少的 lru 分为两种一个所有的key中进行淘汰,设置过期时间中使用淘汰
请介绍一下Redis的过期策略
Redis支持如下两种过期策略:
惰性删除:客户端访问一个key的时候,Redis会先检查它的过期时间,如果发现过期就立刻删除这个key。
定期删除:Redis会将设置了过期时间的key放到一个独立的字典中,并对该字典进行每秒10次的过期扫描,
缓存更新/缓存同步
缓存服务(Redis)和数据服务(底层数据库)是相互独立且异构的系统,在更新缓存或更新数据的时候无法做到原子性的同时更新两边的数据,因此在并发读写或第二步操作异常时会遇到各种数据不一致的问题。如何解决并发场景下更新操作的双写一致是缓存系统的一个重要知识点。
解决方案:
使用canal实现数据双写一致性?
为什么删除数据后内存还是很高
因为内存碎片,将内存整理一下,
为什么会出现内存碎片
Redis提供了多种的内存分配策略,比如libc、jemalloc、tcmalloc,默认使用jemalloc。
jemalloc这种分配策略并不是按需分配,而是固定大小分配,比如8字节、32字节....2KB、4KB等
判断存在内存碎片?
这个对于运维人员来说很重要,一旦出现Redis运行缓慢或者阻塞了,一定需要先判断内存的占用情况,而不是重启Redis。
INFO memory # Memory used_memory:1073741736 #实际使用的内存大小 used_memory_human:1024.00M #人类有好的方式 used_memory_rss:1997159792 #操作系统实际内存分配 used_memory_rss_human:1.86G … mem_fragmentation_ratio:1.86 ##碎片率 mem_fragmentation_ratio这个指标很清楚的展示了当前内存的碎片率,比如Redis申请了1000字节,但是操作系统实际分配的内存1800个字节,则mem_fragmentation_ratio=1800/1000=1.8
.如何清理内存碎片?
Redis提供了参数配置,可以控制清除内存碎片的时机,命令如下:
config set activedefrag yes
以上命令启动自动清理,但是具体什么时候清理,还要受以下两个参数的影响:
-
active-defrag-ignore-bytes 400mb:如果内存碎片达到了400mb,开始清理(自定义) -
active-defrag-threshold-lower 20:内存碎片空间占操作系统分配给 Redis 的总空间比例达到20%时,开始清理(自定义)
Redis6的新特性
Redis 6.0 新特性-多线程
1:严格来讲从Redis4.0之后并不是单线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 key 的删除等等
2:Redis多线程主要解决网络IO瓶颈,并不是解决CPU瓶颈
Redis6.0默认是否开启了多线程?
Redis6.0的多线程默认是禁用的,只使用主线程。如需开启需要修改redis.conf配置文件:
io-threads-do-reads yes 
4.Redis6.0多线程开启时,线程数如何设置?
开启多线程后,还需要设置线程数,否则是不生效的。同样修改redis.conf配置文件  关于线程数的设置,官方有一个建议:4核的机器建议设置为2或3个线程,8核的建议设置为6个线程,线程数一定要小于机器核数。还需要注意的是,线程数并不是越大越好,官方认为超过了8个基本就没什么意义了。
关于线程数的设置,官方有一个建议:4核的机器建议设置为2或3个线程,8核的建议设置为6个线程,线程数一定要小于机器核数。还需要注意的是,线程数并不是越大越好,官方认为超过了8个基本就没什么意义了。
redis6新特性-acl
Redis6之前Redis就只有一个用户(default)权限最高,通过配置文件的requirepass配置
Redis6版本推出了ACL(Access Control List)访问控制权限的功能,基于此功能,我们可以设置多个用户,为了保证向下兼容,Redis6保留了default用户和使用requirepass的方式给default用户设置密码,默认情况下default用户拥有Redis最大权限,我们使用redis-cli连接时如果没有指定用户名,用户也是默认default
ACL常用命令
ACL whoami
ACL list
ACL setuser allen on >123456 +@all ~*
AUTH allen mypasswd
#只能创建以lakers为前缀的key
ACL setuser james on >123456 +@all ~lakers*
#不拥有set权限
ACL setuser james -SET
ACL DELUSER james














 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









