







- Set UID
当 s这个标志出现在档案拥有者的 x 权限上时,例如刚刚提到的 /usr/bin/passwd这个档案的权限状态:『-rwsr-xr-x』,此时就被称为 Set UID,简称为 SUID的特殊权限。 那么SUID的权限对于一个档案的特殊功能是什么呢?基本上SUID有这样的限制与功能:
- SUID权限仅对二进制程序(binary program)有效;
- 执行者对于该程序需要具有 x 的可执行权限;
- 本权限仅在执行该程序的过程中有效 (run-time);
- 执行者将具有该程序拥有者 (owner) 的权限。
讲这么硬的东西你可能对于 SUID 还是没有概念,没关系,我们举个例子来说明好了。 我们的 Linux 系统中,所有账号的密码都记录在 /etc/shadow 这个档案里面,这个档案的权限为:『-r-------- 1 root root』,意思是这个档案仅有root可读且仅有root可以强制写入而已。既然这个档案仅有 root 可以修改,那么mine 这个一般账号使用者能否自行修改自己的密码呢?你可以使用你自己的账号输入『passwd』这个指令来看看,嘿嘿!一般用户当然可以修改自己的密码了!
/etc/shadow就不能让 mine 这个一般账户去存取的,为什么 mine 还能够修改这个档案内的密码呢?这就是 SUID的功能啦!藉由上述的功能说明,我们可以知道
- mine对于 /usr/bin/passwd 这个程序来说是具有 x 权限的,表示 mine 能执行 passwd;
- passwd的拥有者是 root 这个账号;
- mine执行 passwd 的过程中,会『暂时』获得 root 的权限;
- /etc/shadow就可以被 mine 所执行的 passwd 所修改。
但如果mine 使用 cat去读取 /etc/shadow 时,他能够读取吗?因为 cat不具有 SUID 的权限,所以 mine 执行 『cat /etc/shadow』 时,是不能读取 /etc/shadow的。我们用一张示意图来说明如下:
图4.4.1、SUID程序执行的过程示意图
 另外,SUID仅可用在binary program 上, 不能够用在 shell script上面!这是因为 shell script 只是将很多的 binary执行档叫进来执行而已!所以 SUID 的权限部分,还是得要看 shell script呼叫进来的程序的设定, 而不是 shell script 本身。当然,SUID对于目录也是无效的~这点要特别留意。
另外,SUID仅可用在binary program 上, 不能够用在 shell script上面!这是因为 shell script 只是将很多的 binary执行档叫进来执行而已!所以 SUID 的权限部分,还是得要看 shell script呼叫进来的程序的设定, 而不是 shell script 本身。当然,SUID对于目录也是无效的~这点要特别留意。
- Set GID
当 s标志在档案拥有者的 x 项目为 SUID,那 s在群组的 x 时则称为 Set GID, SGID啰!是这样没错!举例来说,你可以用底下的指令来观察到具有 SGID 权限的档案喔:
| [root@www ~]# /usr/bin/locate -rwx--s--x 1 root slocate 23856 Mar 152008 /usr/bin/locate |
与 SUID不同的是,SGID 可以针对档案或目录来设定!如果是对档案来说, SGID有如下的功能:
- SGID对二进制程序有用;
- 程序执行者对于该程序来说,需具备 x 的权限;
- 执行者在执行的过程中将会获得该程序群组的支持!
举例来说,上面的 /usr/bin/locate这个程序可以去搜寻 /var/lib/mlocate/mlocate.db 这个档案的内容 (详细说明会在下节讲述),mlocate.db的权限如下:
| [root@www ~]# ll /usr/bin/locate /var/lib/mlocate/mlocate.db -rwx--s--x 1 root slocate 23856 Mar 15 2008 /usr/bin/locate -rw-r----- 1 root slocate 3175776 Sep 28 04:02 /var/lib/mlocate/mlocate.db |
-
1.操作系统内核模式:
1) 整体式的单内核模式,代码结构紧凑,执行速度快,层次结构性不强。
2) 层次式的微内核模式。
0.11版本的内核采用第一种模式。单内核模式能粗略的分为三个层次:
a 调用服务的主程式层。
b 执行系统调用的服务层
c 支持系统调用的底层函数

2.linux内核系统体系结构:
linux内核主要由5个模块构成:进程控制模块,内存管理模块,文件系统模块,进程间通信模块和网络接口模块。这几个模块的相互关系如下图,虚线和虚线框表示在该版本中还未实现的:
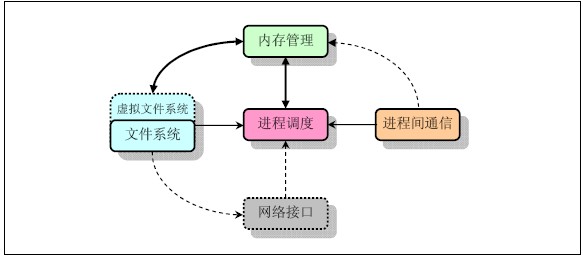
能看到所有的模块都和进程调度有关,他们都需要依靠进程调度程式来挂起(暂停)或重新运行他们的进程。
下图是内核结构图:
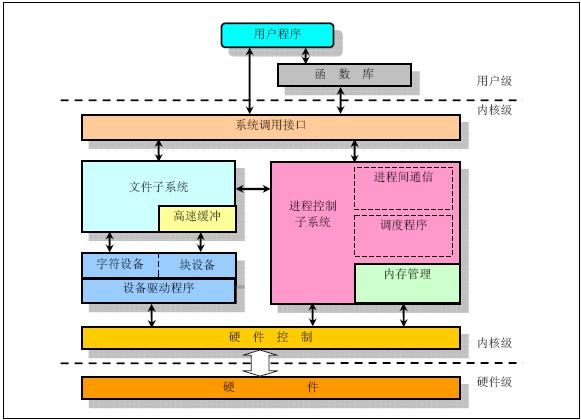
3.中断机制:
该版本是针对80X86 PC,采用两片8259A中断控制器实现管理15级中断向量IRQ0-IRQ15。在新版本的linux中,他已支持多种不同ic硬件平台,而且对于一般的应用程式研发人员这部分能不必过多的去研究,对于嵌入式研发人员来说,目前绝大多数的应用和嵌入式领域的IC都基本上有移植好的代码可供参考,我们只需要根据自己的硬件平台做一些修改就让linux跑起来。如果想深入了解X86的中断机制能看看微机原理之类的书籍。
对于linux内核,中断信号分为两类:硬件中断和软件中断(异常),每个中断有0-255之间的数来标识。对于Intel,int0-in31(0x00-0x1f)是作为软件中断,也称之为异常,因为这些中断的产生是在CPU执行指令时检测到而产生的,分为故障(fault)和陷阱(traps)两类。中断int32-int255(0x20-0xff)能由用户自己定义。int32-int47对应硬件中断请求信号IRQ0-IRQ15。并把程式编程发出系统调用(system_call)中断设置为int28(0x80)。
4.系统定时:
1) 我们人需要脉搏维持生命,操作系统相同需要脉搏来作为系统的时钟节拍,称之为一个系统滴答。
2) linux 0.11内核中, 每隔10ms就发出一个时钟中断(IRQ0)信号。
3) 每个滴答就会调用一次时钟中断处理程式timer_interrrupt,该处理程式主要通过jiffies变量来累计系统自启动以来经过的时钟滴答数。每发生一次中断该值就增1。
4) do_timer()函数根据CPL判断当前进程运行在内核态还是用户态,并相应的将内核态或用户态的时间统计值stime或utime增1。
5) do_timer()判断当前进程的时间片是否用完( 6) 在内核态工作的进程在被中断时,do_timer会即时退出。这样的处理方式决定了linux系统在内核态运行时不被调度程式转换。内核态程式是不可抢占的,但处于用户态程式中运行时则是能被抢占的。
5.linux进程控制:
1) linux 0.11版本,系统最多能有64个进程存在,不过在新版内核中好象能有4090g个(有待查阅)。
2) 第一个进程是“手工”创建的。其余的都是进程使用系统调用fork函数创建。
3) 每个进程中的代码和数据部分分别对应一个执行文件中的代码段,数据段。
4) linux系统中,一个进程能在内核态(kernel mode)或用户态下执行。linux内核堆栈和用户堆栈是分开的。用户堆栈用于在用户态下临时保存调用函数的参数,局部变量等。内核堆栈则含有内核程式执行函数调用的信息。
5.1 任务数据结构:
1) 内核程式通过 进程表对进程进行管理,每个进程在进程表中占有一项,他是个task_struct任务结构指针。有的书上称进程控制块PCB(process control block)或进程描述符PD(process discriptor)。结构体如下:
struct task_struct {
/* these are hardcoded - don’t touch */
long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
long signal;
struct sigaction sigaction[32];
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;
unsigned long start_code,end_code,end_data,brk,start_stack;
long pid,father,pgrp,session,leader;
unsigned short uid,euid,suid;
unsigned short gid,egid,sgid;
long alarm;
long utime,stime,cutime,cstime,start_time;
unsigned short used_math;
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;
struct m_inode * pwd;
struct m_inode * root;
struct m_inode * executable;
unsigned long close_on_exec;
struct file * filp[NR_OPEN];
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];
/* tss for this task */
struct tss_struct tss;
};
2) 当一个进程在执行时,CPU的所有寄存器中的值,进程的状态及堆栈中的内容被称为该进程的上下文。当内核需要转换(switch)至另一个进程时,需要保存当前进程的的所有状态,即上下文,以便在再次执行该进程时进行恢复。
5.2 进程运行状态:
1) 运行状态(TASK_RUNNING)。
2) 可中断睡眠状态(TASK_INTERRUPTIBLE)。当系统产生了一个中断或释放了进程正在等待的资源,或进程收到一个信号,都能唤醒进程转换到就绪状态(运行状态)。
3) 不可中断睡眠状态(TASK_UNINTERRUPTIBLE)。处于该状态的进程只能被wake_up()函数明确唤醒时才能进入就绪状态。
4) 暂停状态(TASK_STOPPED)。当进程收到信号SIGSTOP,SIGTSTP,SIGTTIN或SIGTTOU时就会进入暂停状态。发送SIGCONT就会让进程进入运行状态。该版本中未实现。
5) 僵死状态(TASK_ZOMBIE)。当该进程已停止运行,但其父进程还没有询问其状态时,则称该进程处于僵死状态。
6) 只有当进程从“内核运行态”转移到“睡眠状态”时,内核才会进行进程转换。
7) 在内核态下运行的进程不能被其他进程抢占,而且一个进程不能改动另一个进程的状态。
8) 为了避免进程转换时造成内核数据错误,内核在执行代码时会禁止一切中断。
5.3 进程初始化:
1) 在 boot目录下的汇编代码即引导程式将内核从磁盘上加载到内存中, 并让系统在保护模式下运行,之后便进入系 统初始化程式init/main.c,该程式代码如下:
void main(void) /* This really IS void, no error here. */
{ /* The startup routine assumes (well, ...) this */
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them
*/
ROOT_DEV = ORIG_ROOT_DEV;
drive_info = DRIVE_INFO;
memory_end = (1 16*1024*1024)
memory_end = 16*1024*1024;
if (memory_end > 12*1024*1024)
buffer_memory_end = 4*1024*1024;
else if (memory_end > 6*1024*1024)
buffer_memory_end = 2*1024*1024;
else
buffer_memory_end = 1*1024*1024;
main_memory_start = buffer_memory_end;
#ifdef RAMDISK
main_memory_start += rd_init(main_memory_start, RAMDISK*1024);
#endif
mem_init(main_memory_start,memory_end);
trap_init();
blk_dev_init();
chr_dev_init();
tty_init();
time_init();
sched_init();
buffer_init(buffer_memory_end);
hd_init();
floppy_init();
sti();
move_to_user_mode();
if (!fork()) { /* we count on this going ok */
init();
}
2) 从代码中能看出, mem_init之前都是对系统物理内存的初始化。之后便是对系统的中断(trap_init),块设备(blk_dev_init),字符设备(chr_dev_init),进程管理(sched_init),硬盘初始化(hd_init),软盘初始化(floppy_init)等, 然后开中断sti。
3) move_to_user_mode()将系统“手工”从内核态(特权级0)移动到用户态(特权级3)的任务0中运行。 内核的初始化代码也即是任务0的代码,只是在移动到任务0之前系统正以内核态特权级0运行,在移动之后便继续执行原来的代码指令流。
4) 调用fork函数创建新的进程时,需要复制任务0的任务数据结构,包括用户堆栈指针,因此需求在任务0的用户态堆栈在创建新的进程1前保持“干净”状态。
5.4 创建新进程:
1) linux创建新的进程都是通过调用fork函数实现的,所有进程都是通过复制进程0得到的,都是进程0的子进程。
2) fork函数代码如下:
_sys_fork:
call _find_empty_process
testl %eax,%eax
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
call _copy_process
addl $20,%esp
1: ret
其中的find_empty_process,copy_process在fork.c中实现。
3) 为了防止这个未建立完的新进程被调度器执行,会在请求页内存后将进程状态设置为TASK_UNINTTERUPTIBLE,在做一系列任务堆栈数据后,最后再将进程状态设置成可运行状态并返回新进程号。
5.5 进程调度:
1) linux进程是抢占式的,被抢占的进程仍然处于TASK_RUNNING状态,只是暂时不被CPU执行。
2) 进程的抢占发生在进程处于用户态执行阶段,在内核态执行时是不能被抢占的。
3) linux 0.11中采用基于 优先级排队的调度策略。
4) 调度程式:schedule函数首先扫描任务数组,通过比较每个就绪态(TASK_RUNNING)任务的运行时间来确定当前哪个进程运行的时间最少。哪个的值最大就表示那个进程运行的时间不长,于是就选中该进程,并使用任务转换函数转换至该进程。
5) 每个任务的需要运行的时间片值counter = counter/2 + priority(优先权值)。
6) 如果没有所有进程可运行,系统就会选择进程0运行,进程0调度pause()把自己置为可中断睡眠状态并再次调用schedule(),其实schedule()并不在意进程0当前的状态,只要系统空闲就调度进程0。
7) 任务转换:任务的转换主要就是通过宏定义的汇编程式switch_to实现,主要就是对当前任务的任务状态段TSS和新任务的任务状态段进行保存和恢复。原理如下图:
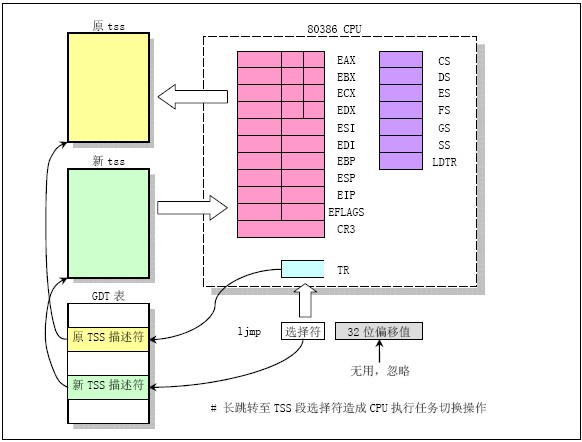
5.6 进程中止:
1) 当一个进程结束了运行或在半途中终止了运行,那么内核就需要释放该进程所占有的系统资源。
2) 当一个用户程式调用exit()系统调用后,就会执行内核函数d0_exit(),并做一系列的资源释放工作,再最后并调用schedule函数去执行其他进程。
3) 在进程终止时,他的任务数据结构仍然保留着,因为其父进程还需要使用其中的信息。
4) 在子进程执行期间,父进程会使用wait()或waitpid()函数等待其子进程的结束。当等待的子进程被终止并处于僵死状态时,父进程就会把子进程运行所使用的时间累加到自己的进程中,最终释放已终止的子进程任务数据结构所占用的内存页面,并置空子进程在任务数组中占用的指针项。
6. linux内核对内存的使用方法:
1) linux 0.11中,内存被划分为如下几块:
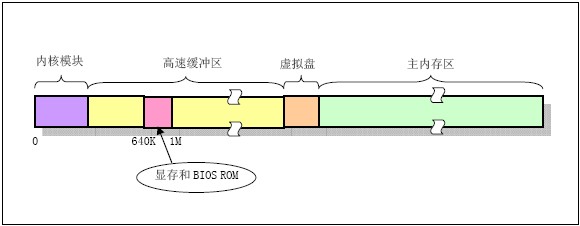
Linux内核程式占据在物理内存的开始部分,接下来是硬盘等块设备使用的高速缓冲区部分。内存的最后部分是供所有程式能随时申请和使用的主内存区。
2) 在intel CPU中,提供了两种内存管理(变换)系统:内存分段系统(Segmentation System)和分页系统(Paging System)。分页是可选的。linux同时采用了这两种管理机制。
3) linux 0.11中三种地址概念:a.程式(进程)的逻辑地址。b.CPU的线性地址。c.实际物理地址。a和b一起便映射到实际的物理地址C。
(1)逻辑地址:有程式产生的和段相关的偏移地址部分,在intel保护模式下就是指程式执行代码段限长内的偏移地址。
(2)线性地址:是逻辑地址到物理地址变换的中间层。段中的偏移地址加上相应段段基地址就生成了一个线性地址。
(3)物理地址:指的是出目前cpu外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。
4) 虚拟内存:在linux 0.11内核中,给每个程式(进程)都划分了总容量为64MB的虚拟内存空间,程式的逻辑地址范围为0x0000000到0x4000000。
5) 虚拟地址空间分配图:
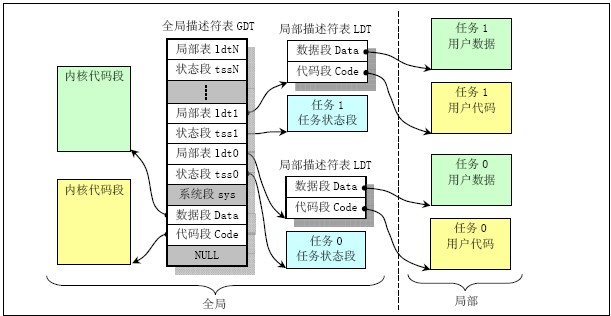
6) 内存分页管理原理:则此时线性地址只是个中间结果,还需要使用分页机制进行变换,再最终映射到实际的物理内存地址。将主内存区域划分成4096字节为一页内存页面,程式申请使用内存时,就以内存页为单位进行分配。
7) CPU能提供多达4G的线性地址空间,对于linux 0.11内核,系统设置全局描述表GDT中的段描述符项数最大为256,其中2项空闲,2项系统使用,每个进程使用两项,因此系统最多能容纳(256-4)/2 + 1=127个任务,虚拟地址范围是((256-4)/2)*64MB约等于8G。
8) linux 0.11中人工定义最多NR_TASKS=64任务,每个进程虚拟地址范围是64M,并且各个进程的虚拟地址起始位置是(任务号-1)*64MB。因此所使用的虚拟地址空间范围是64MB*64=4G。
9) 线性地址空间使用示意图:
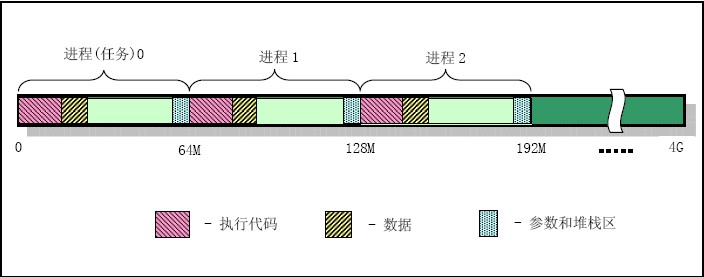
7.linux系统中堆栈的使用方法:
1) linux 0.11中共使用四种堆栈:a.系统初始化时使用的临时堆栈;b.供内核程式自己使用的堆栈(内核堆栈),只有一个,位于系统地址空间固定位置,也是任务0的用户态堆栈;c.每个任务通过系统调用,执行内核程式时使用的堆栈,称为内核堆栈;d.任务在用户态执行的堆栈,位于任务地址空间的末端。
7.1 初始化阶段:
1) 代码调用:bootsect.s->setup.s->head.s(进入内核保护模式)。
2) 进入保护模式时的内核使用的堆栈示意图:
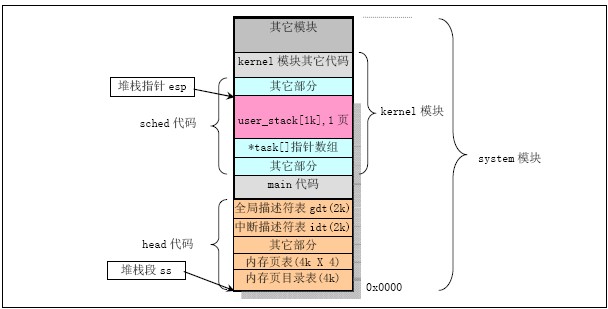
3) 在main.c中,在执行move_user_mode()之前,系统一直使用上述堆栈。而在执行过move_user_mode()之后,main.c的代码被“转换”成任务0中执行。在调用fork函数后,main中的init函数是在任务1中执行,并使用任务1的堆栈,而main本身则在被“转换”成为任务0后,仍然使用上述内核程式自己的堆栈作为任务0的用户态堆栈。
7.2 任务的堆栈:
1) 每个任务有两个堆栈:内核态堆栈,非常小(4096-任务数据结构)字节,大约3KB;用户态堆栈,能在64MB中延伸;
2) 在用户态运行时:
a.每个任务(除任务0)都有自己的64MB空间。
b.当一个任务被创建时,他的用户态堆栈指针被设置在其地址空间的末端,从 线性地址空间使用示意图中能看出。
c.其内核态堆栈则被设置成位于其任务数据结构所在页面的末段,从上面的堆栈示意图能看出,应用程式在用户态一直使用该堆栈。
d.由于linux使用写复制功能(Copy on Write),因此在进程创建后,若该进程及其父进程没有使用堆栈,则两者共享同一堆栈对应的物理内存页面。
3) 在内核态运行时:
a.从上面的堆栈示意图能看出,每个任务及其自己的内核堆栈,和每个任务的任务数据结构(task_struct)放在同一内存页面。
b.fork函数在调用copy_process时,设置任务数据结构p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;其中p是任务的数据结构指针,tss段是task_struct中的一个字段,值得注意的是该任务的内核态堆栈值tss.ss0也被设置成0x10(内核数据段)。tss.esp0是指向保存task_struct结构页面的末端。
c.进程的内核态堆栈图如下:
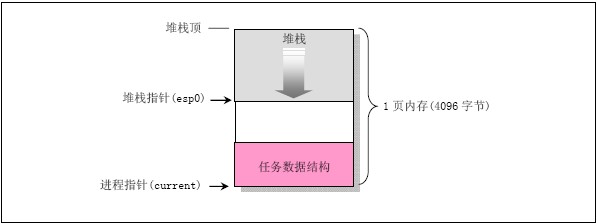
d.每当任务执行内核程式而需要使用其内核时,CPU就会利用TSS结构把他的内核态堆栈设置成由这两个值构成。在任务转换时,老任务的内核堆栈指针(esp0)不会被保存。对CPU来讲,这两个值是只读的,因此每当一个任务进入内核态执行时,其内核态堆栈总是空的。
7.3 任务内核态堆栈和用户态堆栈之间的转换:
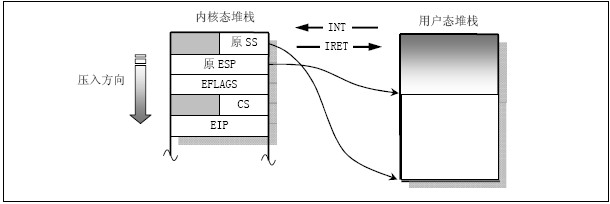
1) 任务调用系统调用时就会进入内核,执行内核代码。此是内核代码就会使用该任务的内核态堆栈进行操作。转换过程中会涉及堆栈状态保存和恢复,如下图:
8.linux内核原始码的目录结构:
















 4910
4910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









